动手专题

动手学深度学习【数据操作+数据预处理】
import osos.makedirs(os.path.join('.', 'data'), exist_ok=True)data_file = os.path.join('.', 'data', 'house_tiny.csv')with open(data_file, 'w') as f:f.write('NumRooms,Alley,Price\n') # 列名f.write('NA

【动手学深度学习】04 数据操作 + 数据预处理(个人向笔记)
数据操作 N维数组是机器学习和神经网络的主要数据结构其中 2-d 矩阵中每一行表示每一行表示一个样本 当维度来到三维的时候则可以表示成一张图片,再加一维就可以变成多张图片,再加一维则可以变成一个视频 访问元素 冒号表示从冒号左边的元素到冒号右边的前一个元素(开区间),其中如果左边为空,那么表示从第一个开始,如果右边为空,那么表示访问到最后一个,如果两边都为空,则表示全部访问其中一行中我们指

小白入门LLM大模型最牛X教程------上交《动手学大模型应用开发》!
本项目是一个面向小白开发者的大模型应用开发教程,旨在结合个人知识库助手项目,通过一个课程完成大模型开发的重点入门,涵盖了大模型应用开发的方方面面,主要包括: 教程一共有七章内容: 《动手学大模型》是上海交大 更新的系列编程实践教程。从已经跟新的内容来看,侧重安全垂直方向。命名是向他们的学长李沐的《动手学深度学习》课程致敬。 感受下大纲、课件和教程风格: 微调与部署 提示学习与思维

动手学深度学习8.2. 文本预处理-笔记练习(PyTorch)
本节课程地址:代码_哔哩哔哩_bilibili 本节教材地址:8.2. 文本预处理 — 动手学深度学习 2.0.0 documentation (d2l.ai) 本节开源代码:...>d2l-zh>pytorch>chapter_multilayer-perceptrons>text-preprocessing.ipynb 文本预处理 对于序列数据处理问题,我们在 8.1节 中 评估了

自己动手写CPU_step6_算术运算指令
序 接上篇,本篇开始实现算数运算指令,包括加减乘除,加减比较好实现,乘除则需要考虑指令周期与其他指令的周期长度不一致问题,可能会导致流水线效率下降,本篇先实现简单的算术运算。 指令定义 `define EXE_ADD 6'b100000 // rs + rt -> rd(检查溢出)`define EXE_ADDU 6'b100001 // rs +

动手写汇编——函数调用过程的思考
c代码 在linux系统上,动手写一个demo.c小程序 #include <stdio.h>int func0(int a, int b){int t;t = a + b;return t;}int main(void){int t;t = func0(10, 20);printf("%d\n", t);return 0;} 该程序在func0函数中做了加法运算,并通过printf
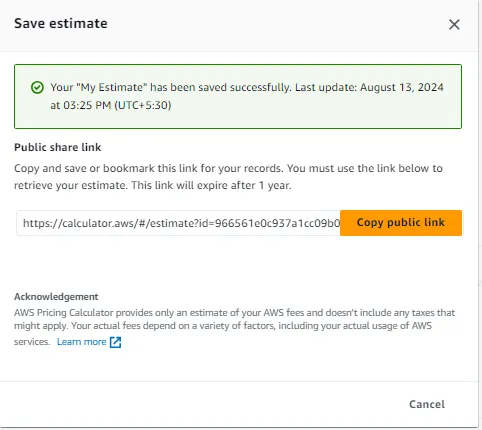
AWS-亚马逊网络服务(基础服务)-AWS 定价计算器-概述与动手部署:
让我们来概述并亲身实践如何使用 AWS 定价计算器来计算 概述: AWS 定价计算器是 Amazon Web Services (AWS) 提供的基于 Web 的工具,可帮助用户估算其特定用例的 AWS 服务成本。欢迎来到雲闪世界。 它允许客户建模他们的基础设施并根据他们打算使用的服务和资源预测每月的成本。 AWS 定价计算器的主要功能: 用户可以选择单个 AWS 服务,如 EC2
动手学深度学习(pytorch)学习记录21-读写文件(模型与参数)[学习记录]
目录 加载和保存张量加载和保存模型参数 保存模型的好处众多,涵盖了从开发到部署的整个机器学习生命周期。 节省资源:训练模型可能需要大量的时间和计算资源。保存模型可以避免重复训练,从而节省时间和计算资源。快速部署:一旦模型被训练并保存,它可以迅速部署到生产环境中,加速产品上市时间。版本控制:保存不同版本的模型有助于跟踪模型的迭代过程,便于比较和回滚到之前的版本。离线使用:保存的模
自己动手实现一个C++智能指针
C++没有提供垃圾回收机制,程序员需要小心翼翼的处理动态内存的分配使用和释放,稍有不慎就会引起悬垂指针内存泄露等问题,尤其在大型程序中出现这种问题往往让人苦不堪言。当然,垃圾回收机制并不是完全没有副作用,引入垃圾回收机制可能会增加程序时间和空间上的开销,同时C++作为一种设计之初就兼容C的语言,在底层开发中被大量使用,实现垃圾回收机制带来的复杂性可能会让C++失去在对性能追求极高的底层,游戏开发等
![动手学深度学习(pytorch)学习记录19-参数管理[学习记录]](https://i-blog.csdnimg.cn/direct/5ed2a19a09824d4f875122244aaf8969.png)
动手学深度学习(pytorch)学习记录19-参数管理[学习记录]
文章目录 参数访问目标参数一次性访问所有参数从嵌套块收集参数 参数初始化内置初始化自定义初始化 参数绑定延后初始化 本节内容: 访问参数,用于调试、诊断和可视化; 参数初始化; 在不同模型组件间共享参数; 延后初始化。 # 单隐藏层的多层感知机import torchfrom torch import nnnet = nn.Sequential(nn.Linear(4, 8)

李沐--动手学深度学习 ResNet
1.理论 2.残差块 import torchfrom torch import nnfrom torch.nn import functional as Ffrom d2l import torch as d2l#ResNet沿用了VGG完整的3*3卷积层设计.残差块的实现如下:#此代码生成两种类型的网络:#一种是当use_1x1conv=F

【转载 HadoopSpark 动手实践 2】Hadoop2.7.3 HDFS理论与动手实践
原文:http://www.cnblogs.com/licheng/p/6825089.html 简介 HDFS(Hadoop Distributed File System )Hadoop分布式文件系统。是根据google发表的论文翻版的。论文为GFS(Google File System)Google 文件系统(中文,英文)。 HDFS有很多特点: ① 保存多个副本

动手学深度学习7.7. 稠密连接网络(DenseNet)-笔记练习(PyTorch)
本节课程地址:本节无视频 本节教材地址:7.7. 稠密连接网络(DenseNet) — 动手学深度学习 2.0.0 documentation (d2l.ai) 本节开源代码:...>d2l-zh>pytorch>chapter_multilayer-perceptrons>densenet.ipynb 稠密连接网络(DenseNet) ResNet极大地改变了如何参数化深层网络中函数
![动手学深度学习(pytorch)学习记录15-正则化、权重衰减[学习记录]](https://i-blog.csdnimg.cn/direct/0f95ecb887cb4ea48b40a36df67ce36a.png)
动手学深度学习(pytorch)学习记录15-正则化、权重衰减[学习记录]
我们可以通过收集更多的训练数据来缓解过拟合,但这可能成本很高,耗时很多或完全失去控制,在短期内难以做到。 假设已经有了足够多的数据,接下来将重点放在正则化技术上。 权重衰减是使用最广泛的正则化技术之一,它通常也被称为L2正则化 技术方法:通过函数与零之间的距离来度量函数的复杂度; 如何精确测量这种‘距离’? 一个简单的方法是通过线性函数f(x)=w^(T) x 中权重向量的某个范数(如||w||

自己动手写SQL执行引擎
自己动手写SQL执行引擎 前言 在阅读了大量关于数据库的资料后,笔者情不自禁产生了一个造数据库轮子的想法。来验证一下自己对于数据库底层原理的掌握是否牢靠。在笔者的github中给这个database起名为Freedom。 整体结构 既然造轮子,那当然得从前端的网络协议交互到后端的文件存储全部给撸一遍。下面是Freedom实现的整体结构,里面包含了实现的大致模块: 最终存储结构当然是使用经典

上交2024最新-《动手学大模型》实战教程及ppt分享!
本课介绍 今天分享一个上海交大的免费的大模型课程,有相关教程文档和Slides,目前是2.2K星标,还是挺火的! 《动手学大模型》系列编程实践教程,由上海交通大学2024年春季《人工智能安全技术》课程(NIS3353)讲义拓展而来(教师:张倬胜),旨在提供大模型相关的入门编程参考。通过简单实践,帮助同学快速入门大模型,更好地开展课程设计或学术研究。。 课程目录 内容截图

动手学深度学习7.5 批量规范化-笔记练习(PyTorch)
本节课程地址:28 批量归一化【动手学深度学习v2】_哔哩哔哩_bilibili 本节教材地址:7.5. 批量规范化 — 动手学深度学习 2.0.0 documentation (d2l.ai) 本节开源代码:...>d2l-zh>pytorch>chapter_multilayer-perceptrons>batch-norm.ipynb 批量规范化 训练深层神经网络是十分困难的,特

自己动手写word2vec (一):主要概念和流程
转https://blog.csdn.net/u014595019/article/details/51884529 word2vec 是 Google 于 2013 年开源推出的一个用于获取词向量(word vector)的工具包,它简单、高效,因此引起了很多人的关注。我在看了@peghoty所写的《word2vec中的数学以后》(个人觉得这是很好的资料,各方面知识很全面,不像网上大部分有

动手学深度学习(Pytorch版)代码实践 -计算机视觉-37微调
37微调 import osimport torchimport torchvisionfrom torch import nnimport liliPytorch as lpimport matplotlib.pyplot as pltfrom d2l import torch as d2l# 获取数据集d2l.DATA_HUB['hotdog'] = (d2l.DATA_U

动手学深度学习(Pytorch版)代码实践 -计算机视觉-36图像增广
6 图片增广 import matplotlib.pyplot as pltimport numpy as npimport torch import torchvisionfrom d2l import torch as d2lfrom torch import nn from PIL import Imageimport liliPytorch as lpfrom tor

动手学深度学习(Pytorch版)代码实践 -卷积神经网络-27含并行连结的网络GoogLeNet
27含并行连结的网络GoogLeNet import torchfrom torch import nnfrom torch.nn import functional as Fimport liliPytorch as lpimport matplotlib.pyplot as pltclass Inception(nn.Module):# c1--c4是每条路径的输出通道数def

动手学深度学习(Pytorch版)代码实践 -卷积神经网络-28批量规范化
28批量规范化 """可持续加速深层网络的收敛速度"""import torchfrom torch import nnimport liliPytorch as lpimport matplotlib.pyplot as pltdef batch_norm(X, gamma, beta, moving_mean, moving_var, eps, momentum):"""实现一个具有

动手学深度学习(Pytorch版)代码实践 -卷积神经网络-23卷积神经网络LeNet
23卷积神经网络LeNet import torchfrom torch import nnimport liliPytorch as lpimport matplotlib.pyplot as plt# 定义一个卷积神经网络net = nn.Sequential(nn.Conv2d(1, 6, kernel_size=5, padding=2), # 卷积层1:输入通道数1,输出

动手学深度学习(Pytorch版)代码实践 -卷积神经网络-24深度卷积神经网络AlexNet
24深度卷积神经网络AlexNet import torchfrom torch import nnimport liliPytorch as lpimport liliPytorch as lpimport matplotlib.pyplot as pltdropout1 = 0.5#Alexnet架构net = nn.Sequential(nn.Conv2d(1, 96, k
动手学深度学习(Pytorch版)代码实践 -卷积神经网络-14模型构造
14模型构造 import torchfrom torch import nnfrom torch.nn import functional as F#通过实例化nn.Sequential来构建我们的模型, 层的执行顺序是作为参数传递的net1 = nn.Sequential(nn.Linear(20, 256), nn.ReLU(), nn.Linear(256,10))"""nn.
动手学深度学习(Pytorch版)代码实践 -卷积神经网络-16自定义层
16自定义层 import torchimport torch.nn.functional as Ffrom torch import nnclass CenteredLayer(nn.Module):def __init__(self):super().__init__()#从其输入中减去均值#X.mean() 计算的是整个张量的均值#希望计算特定维度上的均值,可以传递 dim 参数。#例