下降专题

✨机器学习笔记(二)—— 线性回归、代价函数、梯度下降
1️⃣线性回归(linear regression) f w , b ( x ) = w x + b f_{w,b}(x) = wx + b fw,b(x)=wx+b 🎈A linear regression model predicting house prices: 如图是机器学习通过监督学习运用线性回归模型来预测房价的例子,当房屋大小为1250 f e e t 2 feet^

AI学习指南深度学习篇-带动量的随机梯度下降法的基本原理
AI学习指南深度学习篇——带动量的随机梯度下降法的基本原理 引言 在深度学习中,优化算法被广泛应用于训练神经网络模型。随机梯度下降法(SGD)是最常用的优化算法之一,但单独使用SGD在收敛速度和稳定性方面存在一些问题。为了应对这些挑战,动量法应运而生。本文将详细介绍动量法的原理,包括动量的概念、指数加权移动平均、参数更新等内容,最后通过实际示例展示动量如何帮助SGD在参数更新过程中平稳地前进。

AI学习指南深度学习篇-带动量的随机梯度下降法简介
AI学习指南深度学习篇 - 带动量的随机梯度下降法简介 引言 在深度学习的广阔领域中,优化算法扮演着至关重要的角色。它们不仅决定了模型训练的效率,还直接影响到模型的最终表现之一。随着神经网络模型的不断深化和复杂化,传统的优化算法在许多领域逐渐暴露出其不足之处。带动量的随机梯度下降法(Momentum SGD)应运而生,并被广泛应用于各类深度学习模型中。 在本篇文章中,我们将深入探讨带动量的随

AI学习指南深度学习篇-随机梯度下降法(Stochastic Gradient Descent,SGD)简介
AI学习指南深度学习篇-随机梯度下降法(Stochastic Gradient Descent,SGD)简介 在深度学习领域,优化算法是至关重要的一部分。其中,随机梯度下降法(Stochastic Gradient Descent,SGD)是最为常用且有效的优化算法之一。本篇将介绍SGD的背景和在深度学习中的重要性,解释SGD相对于传统梯度下降法的优势和适用场景,并提供详细的示例说明。 1.

随即近似与随机梯度下降
一、均值计算 方法1:是直接将采样数据相加再除以个数,但这样的方法运行效率较低,要将所有数据收集到一起后再求平均。 方法2:迭代法 二、随机近似法: Robbins-Monro算法(RM算法) g(w)是有界且递增的 ak的和等于无穷,并且ak平方和小于无穷。我们会发现在许多强化学习算法中,通常会选择 ak作为一个足够小的常数,因为 1/k 会越来越小导致算法效率较低

2.4梯度下降与量化策略优化
1. 梯度下降法的基本原理 欢迎来到“梯度下降”的世界!听上去有点像在爬山对吧?其实,这个算法的灵感确实来自爬山。想象你在一个山谷中迷路了,周围雾蒙蒙的,看不清楚路,只能摸着石头一步一步往下走。每走一步,你都选一个让你往更低的地方移动的方向,直到你走到了山谷的最低点——这就是梯度下降法的核心思想! 梯度的概念:多变量函数的变化方向 说到梯度,首先得明白它是个什么鬼。简单来说,梯度是一个向量,
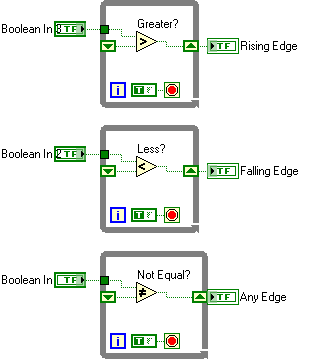
LabVIEW布尔值比较与信号状态上升沿下降沿检测
在 LabVIEW 编程中,布尔值的比较不仅是逻辑运算的重要组成部分,还广泛应用于信号的上升沿和下降沿检测。通过理解 True > False 这样的基本表达式,以及如何在程序中检测信号的状态变化,开发者可以有效地控制系统行为,并实时响应信号变化。 布尔值在 LabVIEW 中的数值表示 在 LabVIEW 中,布尔值有明确的数值对应: True:数值表示为 1。 False:数

Lasso回归的坐标下降法推导
Lasso回归的坐标下降法推导 目标函数 Lasso相当于带有L1正则化项的线性回归。先看下目标函数: 这个问题由于正则化项在零点处不可求导,所以使用非梯度下降法进行求解,如坐标下降法或最小角回归法。 坐标下降法 本文介绍坐标下降法。 坐标下降算法每次选择一个维度进行参数更新,维度的选择可以是随机的或者是按顺序。 当一轮更新结束后

坐标下降和块坐标下降法
坐标下降和块坐标下降法 坐标下降法(英语:coordinate descent)是一种非梯度优化算法。算法在每次迭代中,在当前点处沿一个坐标方向进行一维搜索以求得一个函数的局部极小值。在整个过程中循环使用不同的坐标方向。对于不可拆分的函数而言,算法可能无法在较小的迭代步数中求得最优解。为了加速收敛,可以采用一个适当的坐标系,例如通过主成分分析获得一个


梯度下降法求解线性回归
文章目录 线性回归损失函数平均绝对误差(MAE)均方误差(MSE) 最小二乘法最小二乘法代数推导最小二乘法矩阵推导 线性回归 Python 实现线性回归 scikit-learn 实现 梯度下降法梯度下降法的原理 梯度下降法求解线性回归 线性回归 线性回归,就是已知一系列x和y对应的点,通过求出 y = w x + b y=wx+b y=wx+b(线性,所以是一条直线)去拟合数据
poj 1836 Alignment( 最长上升(下降)子序列 )
http://poj.org/problem?id=1836 题意:给n个士兵的身高,要求每个士兵向左或向右能看向无穷远处(新队列呈三角形分布),最少要剔除几个士兵;思路:对数列分别顺序,逆序求最长上升子序列,然后枚举i和 j,使得以i结尾的上升子序列与以j开头的下降子序列的和最大; #include <stdio.h>#include <string.h>#include
一元线性回归梯度下降代码
#代价函数def compute_cost(x, y, w, b):m = x.shape[0] cost = 0for i in range(m):f_wb = w * x[i] + bcost = cost + (f_wb - y[i])**2total_cost = 1 / (2 * m) * costreturn total_cost#计算梯度函数def compute_gradien

第四章 梯度下降反向传播
第一章 深度学习和神经网络 第二章 Pytorch安装 第三章 PyTorch的使用 第四章 梯度下降 什么是梯度下降?偏导的计算反向传播算法计算图和反向传播神经网络中的反向传播神经网络的示意图神经网络的计算图 什么是梯度下降? 梯度是一个向量,学习的前进方向(变化最快的方向),简单理解就是一个导数,只不过这个导数对于二维的、一元的情况来讲它就是导数,对于多

5、梯度下降法,牛顿法,高斯-牛顿迭代法
1、梯度下降 2、牛顿法 3、高斯-牛顿迭代法 4、代码部分 1.梯度下降法代码 批量梯度下降法c++代码: /*需要参数为theta:theta0,theta1目标函数:y=theta0*x0+theta1*x1;*/#include <iostream>using namespace std;int main()

吴恩达谈AI未来:Agentic Workflow、推理成本下降与开源的优势
近年来,人工智能(AI)领域的发展势如破竹,然而随着技术的普及,市场也开始出现对AI泡沫的质疑声。2024年8月,AI领域的权威专家吴恩达(Andrew Ng)在与ARK Invest的对谈中,分享了他对AI产业发展的乐观看法,并重点讨论了Agentic Workflow的未来、训练与推理成本的下降,以及开源模型的优势。本文将详细解析吴恩达的访谈内容,展望AI领域未来的发展趋势。 一、AI发展未

机器学习----梯度下降法
回归(regression)、梯度下降(gradient descent) 发表于332 天前 ⁄ 技术, 科研 ⁄ 评论数 3 ⁄ 被围观 1152 次+ 本文由LeftNotEasy所有,发布于http://leftnoteasy.cnblogs.com。如果转载,请注明出处,在未经作者同意下将本文用于商业用途,将追究其法律责任。 前言: 上次写过一篇关于贝叶斯概率论的

神经网络算法 - 一文搞懂Gradient Descent(梯度下降)
本文将从梯度下降的本质、梯度下降的原理、梯度下降的算法 三个方面,带您一文搞懂梯度下降 Gradient Descent | GD。 梯度下降 机器学习“三板斧”:选择模型家族,定义损失函数量化预测误差,通过优化算法找到最小化损失的最优模型参数。 机器学习 vs 人类学习 定义一个函数集合(模型选择) 目标:确定一个合适的假设空间或模型家族。 示例:线性回归、逻辑回归、神
matlab实现梯度下降优化算法
梯度下降(Gradient Descent)是一种常用的优化算法,用于寻找函数的局部最小值。在机器学习领域,它常被用来优化模型的参数,比如线性回归、逻辑回归以及神经网络等模型的权重和偏置。 以下是一个简单的MATLAB实现梯度下降算法的示例,该示例将用于优化一个简单的二次函数 f(x)=ax2+bx+c 的最小值点。为了简化问题,我们假设 a=1,b=0,c=1,即函数为 f(x)=x2+1,其
07_LFM--梯度下降法--实现基于模型的协同过滤
07_LFM--梯度下降法--实现基于模型的协同过滤 LFM--梯度下降法--实现基于模型的协同过滤0.引入依赖1.数据准备2.算法的实现3.测试 LFM–梯度下降法–实现基于模型的协同过滤 0.引入依赖 import numpy as np # 数值计算、矩阵运算、向量运算import pandas as pd # 数值分析、科学计算 1.数据准备 # 定义评分矩
DP 水题 最长不下降子序列
题目描述 Description 给一个数组a1, a2 ... an,找到最长的不下降子序列ab1<=ab2<= .. <=abk,其中b1<b2<..bk。 输出长度即可。 输入描述 Input Description 第一行,一个整数N。 第二行 ,N个整数(N < = 5000) 输出描述 Output Description 输出K的极大值,即最

数学建模学习(116):全面解析梯度下降算法及其在机器学习中的应用与优化
文章目录 1.梯度下降简介1.1 梯度下降的数学原理1.2 学习率的选择 2 梯度下降变体3.梯度下降优化器3.1 动量法(Momentum)3.2 AdaGrad3.3 RMSprop3.4 Adam3.5 Python 使用不同优化器训练线性回归模型 4.案例:使用梯度下降优化加利福尼亚房价预测模型4.1. 数据准备4.2. 模型训练与优化4.3. 实验结果对比4.4. 结果分析4.5.

不用框架入门与进阶深度学习(3)−线性单元、梯度下降与回归任务
转自公众号-AI圈终身学习。 一个人是孤独的,一群人是强大的,欢迎关注。 写在前面 前文我们介绍了简单有效的感知器,用它实现了一个线性分类器,并在鸢尾花数据集上取得不错的效果。您肯定懂得AI领域做分类任务的基本原理了。 如果您觉得迷迷糊糊也很正常,因为我们没有讲感知器的更新规则算法-梯度下降。 如果单单讲个梯度下降,您可能会看睡着。所以,我们一起来动手做一个AI领域的基础任务-回
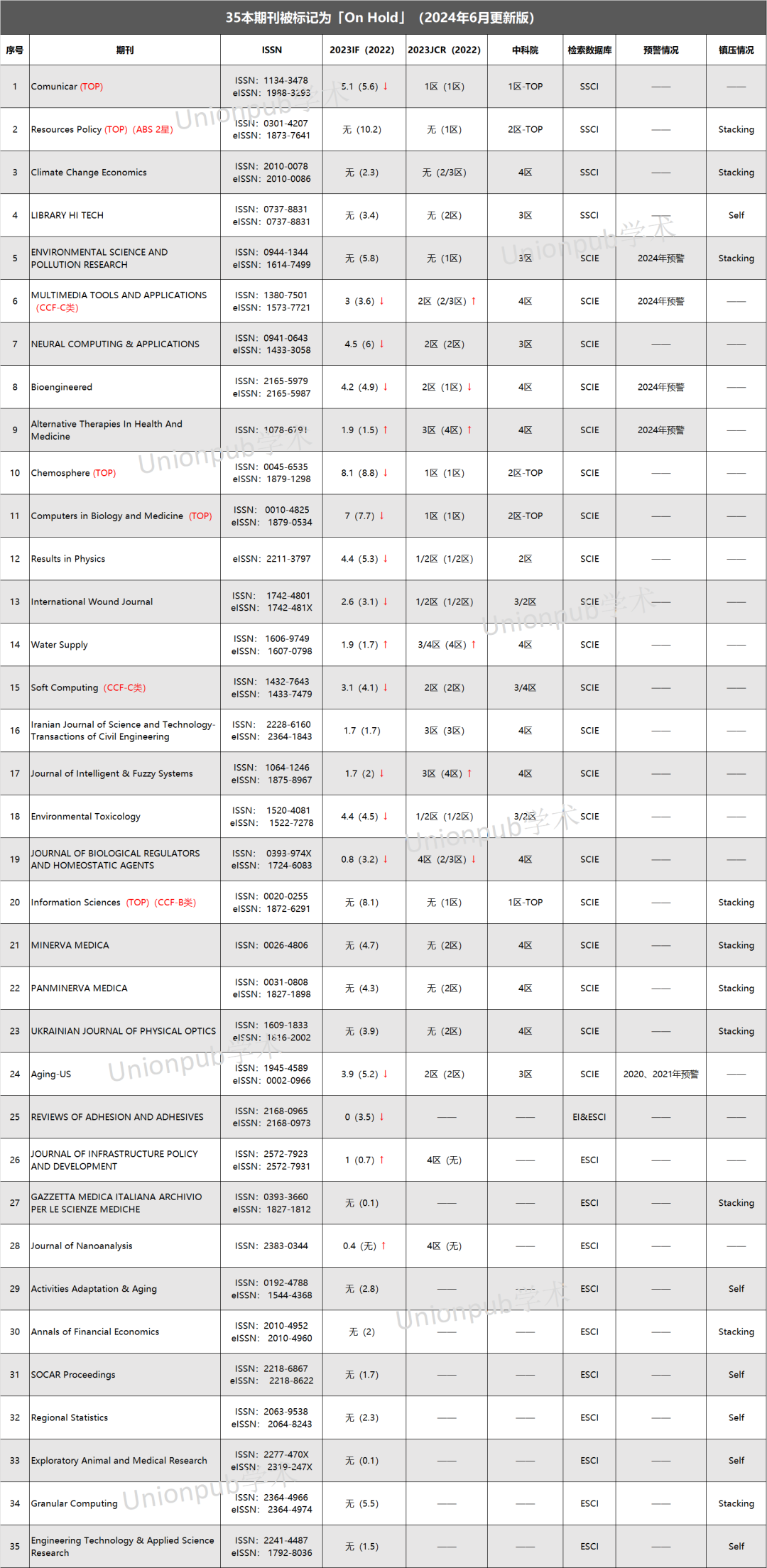
慎投!新增7本期刊被“On Hold“,14本影响因子下降!
本周投稿推荐 SSCI • 中科院2区,6.0-7.0(录用友好) EI • 各领域沾边均可(2天录用) CNKI • 7天录用-检索(急录友好) SCI&EI • 4区生物医学类,0.5-1.0(录用率99%) • 1区工程类,6.0-7.0(进展超顺) • IEEE(TOP),7.5-8.0(实力强刊) On Hold:新增7本期刊有风险 自科睿唯安发布最新影响因子

【Rust日报】 2019-05-26:切片索引检查导致的3倍性能下降问题一例
漫游 Tox-rs,第一部分 长文预警。Tox 是一个分布式的P2P,加密传输,易于使用的基于DHT的网络。 Tox 原来是个C项目,作者用Rust通过审视发现,实现里面有不少漏洞,易被攻击。所以他用Rust重写了它。就是上面那个项目地址。现在作者,开始整理这几年的工作,开始生成文档。 Read More 切片索引检查导致的3倍性能下降问题一例 作者发现下面这两片代码: pub fn

算法金 | 再见!!!梯度下降(多图)
大侠幸会,在下全网同名「算法金」 0 基础转 AI 上岸,多个算法赛 Top 「日更万日,让更多人享受智能乐趣」 接前天 李沐:用随机梯度下降来优化人生! 今天把达叔 6 脉神剑给佩奇了,上 吴恩达:机器学习的六个核心算法! ——梯度下降 1、 目标 梯度下降优化算法的概述,目的在于帮助读者理解不同算法的优缺点。 2、 开整 梯度下降法在优化神经网络中的应