相关系数专题

偏相关系数 - sas 实现
目的: 测试单变量与目标变量的线性关系, 在排除其他变量影响的条件下的 相关性。 求偏相关系数的sas 实现: ods graphics on;proc corr data=fish1 plots=scatter(alpha=0.2 0.3);var height weight;partial length weight;run;ods graphics off; 求

数学建模--皮尔逊相关系数、斯皮尔曼相关系数
目录 1.总体的皮尔逊相关系数 2.样本的皮尔逊相关系数 3.对于皮尔逊相关系数的认识 4.描述性统计以及corr函数 编辑 5.数据导入实际操作 6.引入假设性检验 6.1简单认识 6.2具体步骤 7.p值判断法 8.检验正态分布 8.1jb检验 8.2威尔克检验:针对于p值进行检验 9.两个求解方法的总结 1.总体的皮尔逊相关系数 我们首先要知道这个

平方Pearson相关系数(SPCC)相关公式的推导
1、PCC及SPCC的定义 最近推导了维纳滤波的公式,其中最重要的是当然是最小平方误差准则(MSE)。但是在很多实际应用中,参考信号是不可知的,因此MSE准则不具有实际意义。为了解决这个问题,我们需要寻找另一个准则替代MSE成为新的代价函数。这就是皮尔逊相关系数(Pearson Correlation Coefficient, PCC)的来历。通过研究发现,相较于MSE,PCC具有许多吸引人的优

Python相关系数导图
🎯要点 量化变量和特征关联绘图对比皮尔逊相关系数、斯皮尔曼氏秩和肯德尔秩汽车性价比相关性矩阵热图大流行病与资产波动城镇化模型预测交通量宝可梦类别特征非线性依赖性捕捉向量加权皮尔逊相关系数量化图像相似性 Python皮尔逊-斯皮尔曼-肯德尔 皮尔逊相关系数 在统计学中,皮尔逊相关系数 是一种用于测量两组数据之间线性相关性的相关系数。它是两个变量的协方差与其标准差乘积的比率;因此,它本质上
【JAVA实现】基于皮尔逊相关系数的相似度
以下解释摘自于网上, 简单易懂特地摘抄过来 原链接 皮尔逊相关系数理解有两个角度 1. 按照高中数学水平来理解, 它很简单, 可以看做将两组数据首先做Z分数处理之后, 然后两组数据的乘积和除以样本数Z分数一般代表正态分布中, 数据偏离中心点的距离.等于变量减掉平均数再除以标准差.(就是高考的标准分类似的处理)标准差则等于变量减掉平均数的平方和,再除以样本数,最后再开方. 所以, 根据这

【图像隐藏】基于奇异值分解SVD实现数字水印嵌入提取,相关系数NC附Matlab代码
以下是使用奇异值分解(SVD)实现数字水印嵌入和提取的相关系数(NC)的Matlab代码示例: matlab % 数字水印嵌入 function watermarked_image = embed_watermark(original_image, watermark, strength) % 将原始图像进行SVD分解 [U, S, V] = svd(double(original_image

Python量化交易学习——Part5:通过相关系数选择对收益率影响比重大的因子(1)
上一节中我们学习了如何通过单因子策略进行股票交易,在实际的股市中,因子(也就是指标)数量往往非常之多,比如市盈率/市净率/净资产收益率等,在使用这些因子的过程中,我们会发现有的因子与收益率为正相关,有的因子为负相关,而有些因子几乎完全无关。 所以我们可以通过计算不同因子与收益率的相关系数,得到可以指导我们进行操作的因子。相关系数最大值为1,当相关系数大于0.5时,就可以认为该指标是有效指标,当相关
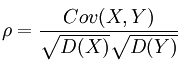
协方差和相关系数的概念和含义
1.协方差: 在概率论中,两个随机变量 X 与 Y 之间相互关系,大致有下列3种情况: 当 X, Y 的联合分布像上图那样时,我们可以看出,大致上有: X 越大 Y 也越大, X 越小 Y 也越小,这种情况,我们称为“正相关”。 当X, Y 的联合分布像上图那样时,我们可以看出,大致上有:X 越大Y 反而越小,X 越小 Y 反而越大,这种情况,我们称为“负相关”。

原创未发表!24年新算法SBOA优化TVFEMD实现分解+四种熵值+频谱图+参数变化图+相关系数图!
声明:文章是从本人公众号中复制而来,因此,想最新最快了解各类智能优化算法及其改进的朋友,可关注我的公众号:强盛机器学习,不定期会有很多免费代码分享~ 目录 数据介绍 优化流程 创新点 使用TVFEMD的创新点在于: 使用蛇鹭优化算法SBOA创新点在于: 参考文献 结果展示 完整代码 今天为大家带来一期蛇鹭优

数据分析的几个数值P值、T值和R值(相关系数)中位数、众数、 方差、 标准差、 协方差、 置信区间
统计学中包含了多个基本概念和数值,以下是关于P值、T值和R值(相关系数)的简要解释,以及其他一些常见的统计学数值: P值(P value): P值是用来判定假设检验结果的一个参数。它表示在原假设为真时,比所得到的样本观察结果更极端的结果出现的概率。如果P值很小,说明原假设情况的发生的概率很小,而如果出现了,根据小概率原理,我们就有理由拒绝原假设。P值越小,拒绝原假设的理由越充分。 T值(T-

AI笔记: 数学基础之数字特征-标准差、协方差、相关系数、中心矩、原点矩、峰度、偏度
标准差 标准差(Standard Deviation)是离均值平方的算术平均数的平方根,用符号 σ \sigma σ 表示,其实标准差就是方差的算术平方根标准差和方差都是测量离散趋势的最重要、最常见的指标。标准差和方差的不同点自傲与,标准差和变量的计算单位是相同的,比方差清楚,因此在很多分析的时候使用的是标准差 σ = D ( X )
数据可视化(七):Pandas香港酒店数据高级分析,涉及相关系数,协方差,数据离散化,透视表等精美可视化展示
Tips:"分享是快乐的源泉💧,在我的博客里,不仅有知识的海洋🌊,还有满满的正能量加持💪,快来和我一起分享这份快乐吧😊! 喜欢我的博客的话,记得点个红心❤️和小关小注哦!您的支持是我创作的动力!数据源存放在我的资源下载区啦! 数据可视化(七):Pandas香港酒店数据高级分析,涉及相关系数,协方差,数据离散化,透视表等精美可视化展示 目录 数据可视化(七):Pandas香
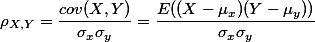
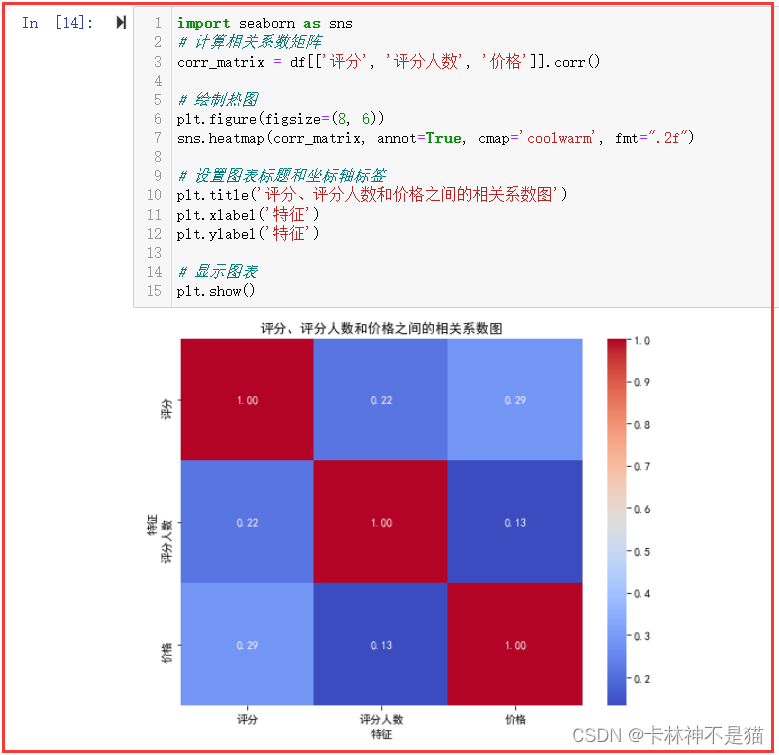
数据分析进阶 - 相关分析(皮尔逊相关系数)
相关分析 相关分析是研究两个或两个以上处于同等地位的随机变量间的相关关系的统计分析方法。通过对不同特征或数据间的关系进行分析,发现其中关键影响及驱动因素。在实际的工作应用中,常常用于特征的发现与选择。针对不同数据类型的变量,需要选用不同的检验方法,具体如下表所示 变量个数变量类型检验方法两个均为连续变量皮尔逊相关系数、简单线性回归两个均为有序分类变量Mantel-Haenszel 趋势检验、

协方差(covariance)和相关系数(correlation coefficient)
相关系数和协方差实际上是相同的概念,都是用来描述两个随机变量之间的相似程度的。这篇文章将详细说明协方差和相关系数的相关知识。 首先声明,此篇的内容是来自"马同学高等数学"微信公众号的内容。 1、事物之间的关系 事物之间有两种关系,有关系和没关系。 1.1 、有关系 据专家表示,要买房的人越多(下图的城镇化率可以简单理解为进城买房的人数),房价就越高(数据来源):
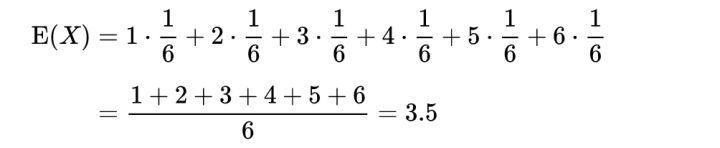
数学期望,方差,标准差,样本方差,协方差,相关系数概念扫盲
数学期望 在概率论和统计学中,数学期望(mean)(或均值,亦简称期望)是试验中每次可能结果的概率乘以其结果的总和,是最基本的数学特征之一。它反映随机变量平均取值的大小。 再举个例子理解一下数学期望: 方差 概率论中方差用来度量随机变量和其数学期望(即均值)之间的偏离程度。统计中的方差(样本方差)是每个样本值与全体样本值的平均数之差的平方值的平均数。在许多实际问题中,研究方差即偏

【图像检测】基于matlab GUI比值+归一化+相关系数遥感图像【含Matlab源码 737期】
✅博主简介:热爱科研的Matlab仿真开发者,修心和技术同步精进,Matlab项目合作可私信。 🍎个人主页:海神之光 🏆代码获取方式: 海神之光Matlab王者学习之路—代码获取方式 ⛳️座右铭:行百里者,半于九十。 更多Matlab仿真内容点击👇 Matlab图像处理(进阶版) 路径规划(Matlab) 神经网络预测与分类(Matlab) 优化求解(Matlab) 语音处理(Matlab

【Python】豆瓣电影TOP250数据规律分析(Pearson相关系数、折线图、条形图、直方图)
1、数据集预览 部分数据说明: 豆瓣排名num 评分rating_num 评分人数comment_num 电影时长movie_duration 2、查看电影数据集基本数据信息 import numpy as npimport pandas as pdimport matplotlib.pyplot as pltdata = pd.read_csv('电影排名.csv') #读取数据#


皮尔森相关系数不能用于度量类别型变量关系
一直纠结皮尔森相关系数能不能用于类别型或有序型变量的相关性检测,之前教学时候用的数据都是连续型的,看到这篇文章的介绍,点击打开链接其中提到: “必须假设数据是成对地从正态分布中取得的。” 更加确定了,类别型变量本身就是离散型的变量。 统计学中的分布有(摘抄网上资源): 一常用离散类型分布:1二项分布,2泊松分布,3几何分布,4负二项分布,5单点分布,6 对数分布,7超几
统计学中不同相关系数的比较
目录 相关系数的区别不同相关系数的比较1. Pearson 相关系数2. Kendall 秩相关系数3. Spearman 秩相关系数 总结 相关系数的区别 不同相关系数的比较 1. Pearson 相关系数 定义: 皮尔逊相关系数衡量的是两个变量之间的线性相关程度。其值介于-1和1之间,其中1表示完全正相关,-1表示完全负相关,0表示没有线性相关。使用场景: 当两个变
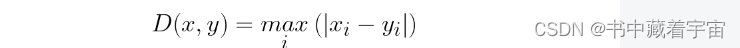
数据间的关系【欧几里得距离,哈曼顿距离,切比雪夫距离,余弦距离,相关系数距离,马氏距离】
数据间的各种距离 欧几里得距离代码 哈曼顿距离距离代码 切比雪夫距离代码 余弦距离距离代码 相关系数距离代码 马氏距离代码 数据表来源于:链接: link 欧几里得距离 代码 from scipy.spatial import distancedist1 = distance.cdist(me_data,me_data,'euclidean')print

风控建模 数据对照篇:WOE IV 回归系数 P值 相关系数 共线性指标 膨胀因子 KS AUC GINI PSI
最重要的事情开始都会讲:建模是始终服务于业务的,没有业务的评分卡就没有灵魂 每一个指标段对应的评价如下,就当做各位的参考表数据吧。希望可以对大家有帮助 第一部分 指标图表以及英文简介 第二部分 指标对应参考数据 需要说明的是,由于对应的目标客群不同,可能各个指标所提供标准不同,可能银行和小贷公司对于KS的标准不相同,银行相对严格,小贷公司可能包含其余的策略性规则,因此可能KS相对比较小
![[分类指标]准确率、精确率、召回率、F1值、ROC和AUC、MCC马修相关系数](https://img-blog.csdnimg.cn/direct/ec34e11aee0b42db8b8a119319207bb4.png)
[分类指标]准确率、精确率、召回率、F1值、ROC和AUC、MCC马修相关系数
准确率、精确率、召回率、F1值 定义: 1、准确率(Accuracy) 准确率是指分类正确的样本占总样本个数的比例。准确率是针对所有样本的统计量。它被定义为: 准确率能够清晰的判断我们模型的表现,但有一个严重的缺陷: 在正负样本不均衡的情况下,占比大的类别往往会成为影响 Accuracy 的最主要因素,此时的 Accuracy 并不能很好的反映模型的整体情况。 例如,一个测试集
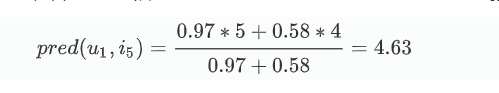
协同过滤算法之连续评分通过皮尔逊相关系数计算相似度原理及代码实现
文章目录 相关算法介绍余弦相似度皮尔逊(Pearson)相关系数 使用协同过滤推荐算法对用户进行评分预测协同过滤推荐算法数据集关于用户-物品评分矩阵代码及实现如何计算评分预测?总结 相关算法介绍 余弦相似度 度量的是两个向量之间的夹角, 用夹角的余弦值来度量相似的情况两个向量的夹角为0是,余弦值为1, 当夹角为90度是余弦值为0,为180度是余弦值为-1余弦相似度在度量文本
Matlab分析证券相关系数
本文演示使用matlab计算证券市场各支股票的相关系数。 代码如下: load stocklist_ss.mat %参见文章“Matlab抓取网页数据”%定义时间范围StartDate='01/01/2010';EndDate='07/23/2015';%下载价格数据ls=size(s,1);Prices=cell(ls,1);for i=1:lsStockName=s{i,1}