本文主要是介绍数据可视化(七):Pandas香港酒店数据高级分析,涉及相关系数,协方差,数据离散化,透视表等精美可视化展示,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Tips:"分享是快乐的源泉💧,在我的博客里,不仅有知识的海洋🌊,还有满满的正能量加持💪,快来和我一起分享这份快乐吧😊!
喜欢我的博客的话,记得点个红心❤️和小关小注哦!您的支持是我创作的动力!数据源存放在我的资源下载区啦!
数据可视化(七):Pandas香港酒店数据高级分析,涉及相关系数,协方差,数据离散化,透视表等精美可视化展示
目录
- 数据可视化(七):Pandas香港酒店数据高级分析,涉及相关系数,协方差,数据离散化,透视表等精美可视化展示
- 一、基本数据处理:读取“香港酒店数据”,按要求解决以下问题。
- 1. 按照数据的内容,重新设置数据的索引,重新设置列名称为'名字','类型','城市','地区','地点','评分','评分人数','价格'。
- 2. 查看所有类型为“商务出行”的酒店。
- 3. 查看所有类型为“浪漫情侣”,地区在湾仔的酒店。
- 4. 查看所有地址在观塘或者油尖旺,评分大于4的酒店。
- 5. 查看类型缺失的数据。
- 6. 用“其他”填充类型和地区。
- 7. 用评分均值填充缺失值。
- 8. 删除价格和评分人数的缺失值。
- 9. 保存到“酒店数据1.xlsx”
- 二、复杂数据处理:读取上一题的“酒店数据1.xlsx”数据,按要求解决以下问题。
- 1. 读取数据。读取上一题目保存的“酒店数据1.xlsx”。
- 2. 查看“评分”的格式,并分别进行升序和降序排序。
- 3. 对酒店按照价格进行排名,计算“油尖旺”地区的均价。
- 4. 对酒店数据进行描述性统计,并求所有价格的均值方差,最大最小值,中值。
- 5. 计算评分和价格之间的的相关系数,协方差。
- 6. 按照评分降序排序,评分相同时按价格升序排序。
- 7. 计算评分小于3分的酒店数量和占比。
- 8. 计算酒店评分大于等于4分的酒店的价格均值。
- 9. 计算出每个地区的酒店占总酒店数量的比例。
- 10. 找出酒店评分人数排名前20的酒店,并计算他们的价格均值。
- 11. 查看酒店分布的类型数量和地区数量,并统计各个类型和地区包含的酒店数量。
- 12. 用数据透视表,计算每个类型的酒店的评分人数总数量。
- 13. 用数据透视表,计算每个类型的酒店价格的均值和标准差。
- 14. 用数据透视表,计算每个地区酒店价格和评分的最大值和最小值。
- 15. 用数据透视表,计算每个地区和类型的酒店的评分的均值和标准差。
- 16. 将“类型”和“名字”设置为层次化索引,并交换索引的位置。然后将层次化索引取消。
- 17. 将数据集转置,获取转置后的index和columns。
- 18. 用Groupby方法来计算每个地区的评分人数的总和以及均值。
- 19. 用Grouby方法计算每个类型的平均价格,最高价和最低价。
- 20. 数据离散化,按照价格将酒店分为3个等级,0-500为C,500-1000为B,大于1000为A,列名设置为“价格等级”。
- 21. 获取评分均值最高和最低的地区的数据,分别使用append和concat方法将获取的两个数据集合并。
- 22. 数据离散化,按照评分人数将酒店平均分为3个等级,三个等级的酒店数量尽量保持一致。评分人数最多的为A,最少的为C。列名设置为“热门等级”。
- 23. 选出评分人数为A,价格也为A的酒店数据,计算其平均评分。
- 24. 取价格最高的5个酒店的数据,使用stack和unstack方法实现dataframe和Series之间的转换。
- 25. 纵向拆分数据集,分为df1和df2,df1包含名字,类型,城市,地区,df2包含名字,地点,评分,评分人数,价格,价格等级,热门等级。
- 26. 将df2按照价格进行排序,重新设置df2的索引。索引值等于价格排名。
- 27. 使用merge方法将df1和df2合并。
- 28. 将合并后的数据集保存数据到“酒店数据2.xlsx”。
- 三、数据可视化:完成以下可视化问题。
- 1. 画出 𝑦=𝑥^2+2𝑥+1在区间[-5,3]的函数图像。
- 2. 在同一张图中创建两个子图,分别画出 s i n ( x ) sin(x) sin(x)和 c o s ( x ) cos(x) cos(x)在[-3.14,3.14]上的函数图像。设置线条宽度为2.5。
- 3. 读取保存的“酒店数据2”数据,画出每个地区酒店数量的柱状图,柱状颜色为红色。
- 4. 画出每个价格等级酒店数量的柱状图。
- 5. 画出各个价格等级占比的饼图。
- 6. 画出酒店评分的直方图。
- 7. 画出每个热门等级酒店评分均值的柱状图。(按照评分均值从小到大排序。)
- 8. 画出油尖旺地区,评分的箱线图。
- 9. 选出平均价格前5的地区,画出这些地区的评分的箱线图。
- 10. 将前面两个题目的图像(箱线图)旋转90度。
- 11. 绘制一个评分,评分人数和价格之间的相关系数图
一、基本数据处理:读取“香港酒店数据”,按要求解决以下问题。
assets/香港酒店数据
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inlineplt.rcParams['font.sans-serif'] = ['Arial Unicode MS'] # SimHei.ttf
plt.rcParams['axes.unicode_minus'] = False import warnings
warnings.filterwarnings('ignore')
df = pd.read_excel('香港酒店数据.xlsx', index_col=0)
df.head()
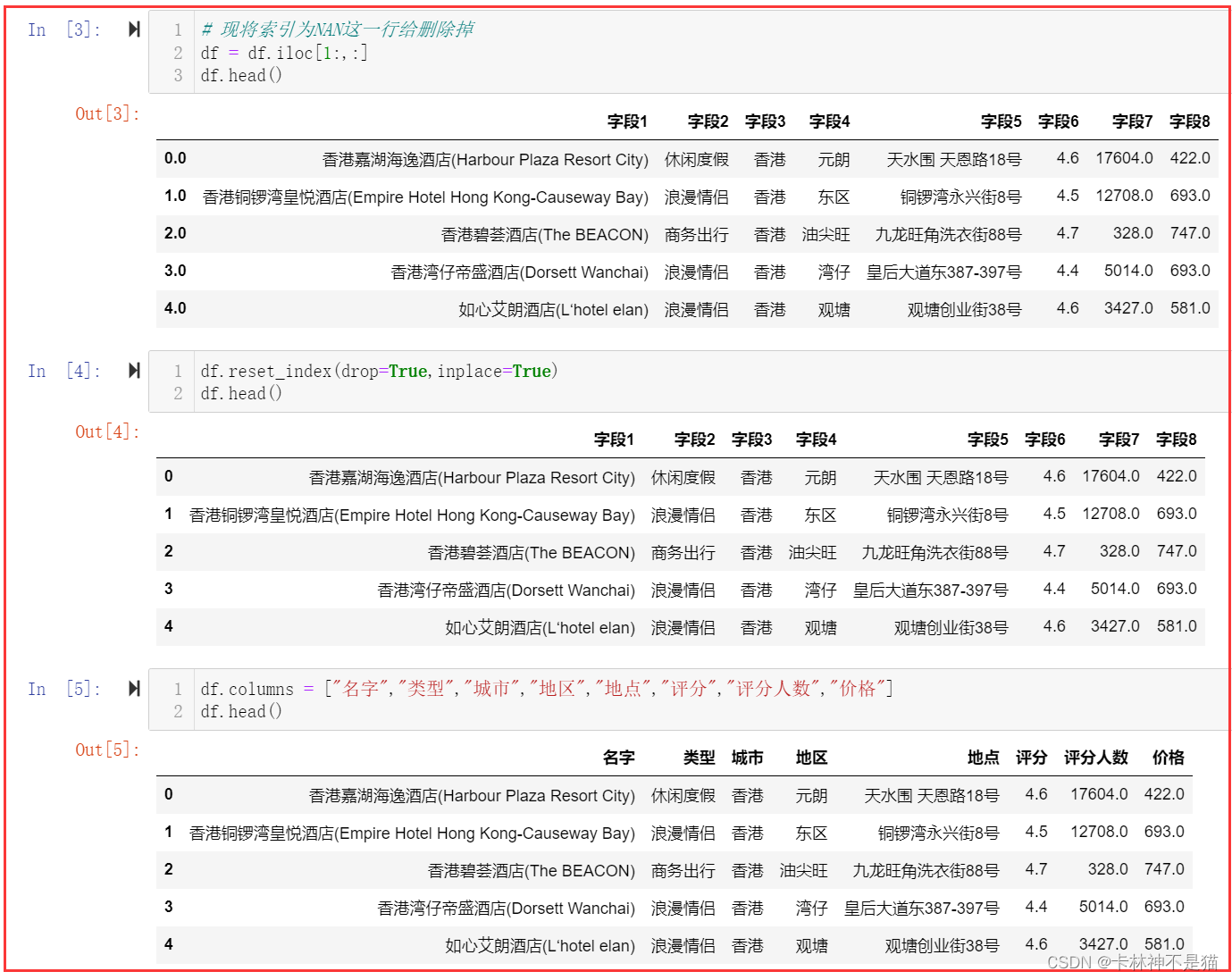
1. 按照数据的内容,重新设置数据的索引,重新设置列名称为’名字’,‘类型’,‘城市’,‘地区’,‘地点’,‘评分’,‘评分人数’,‘价格’。
# 现将索引为NAN这一行给删除掉
df = df.iloc[1:,:]
df.head()df.reset_index(drop=True,inplace=True)
df.head()df.columns = ["名字","类型","城市","地区","地点","评分","评分人数","价格"]
df.head()
2. 查看所有类型为“商务出行”的酒店。
df.query("类型=='商务出行'").reset_index(drop=True)

3. 查看所有类型为“浪漫情侣”,地区在湾仔的酒店。
df.query("类型 == '浪漫情侣' & 地区 == '湾仔'").reset_index(drop=True)

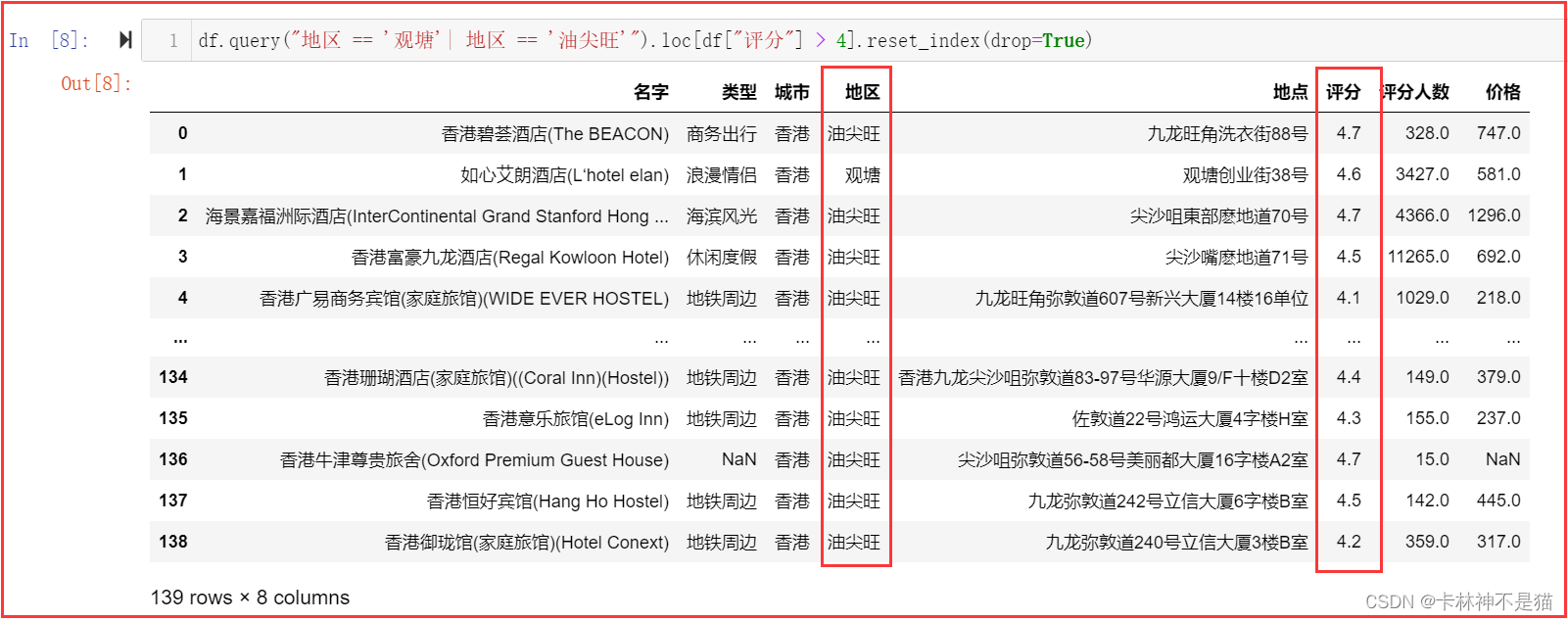
4. 查看所有地址在观塘或者油尖旺,评分大于4的酒店。
df.query("地区 == '观塘'| 地区 == '油尖旺'").loc[df["评分"] > 4].reset_index(drop=True)
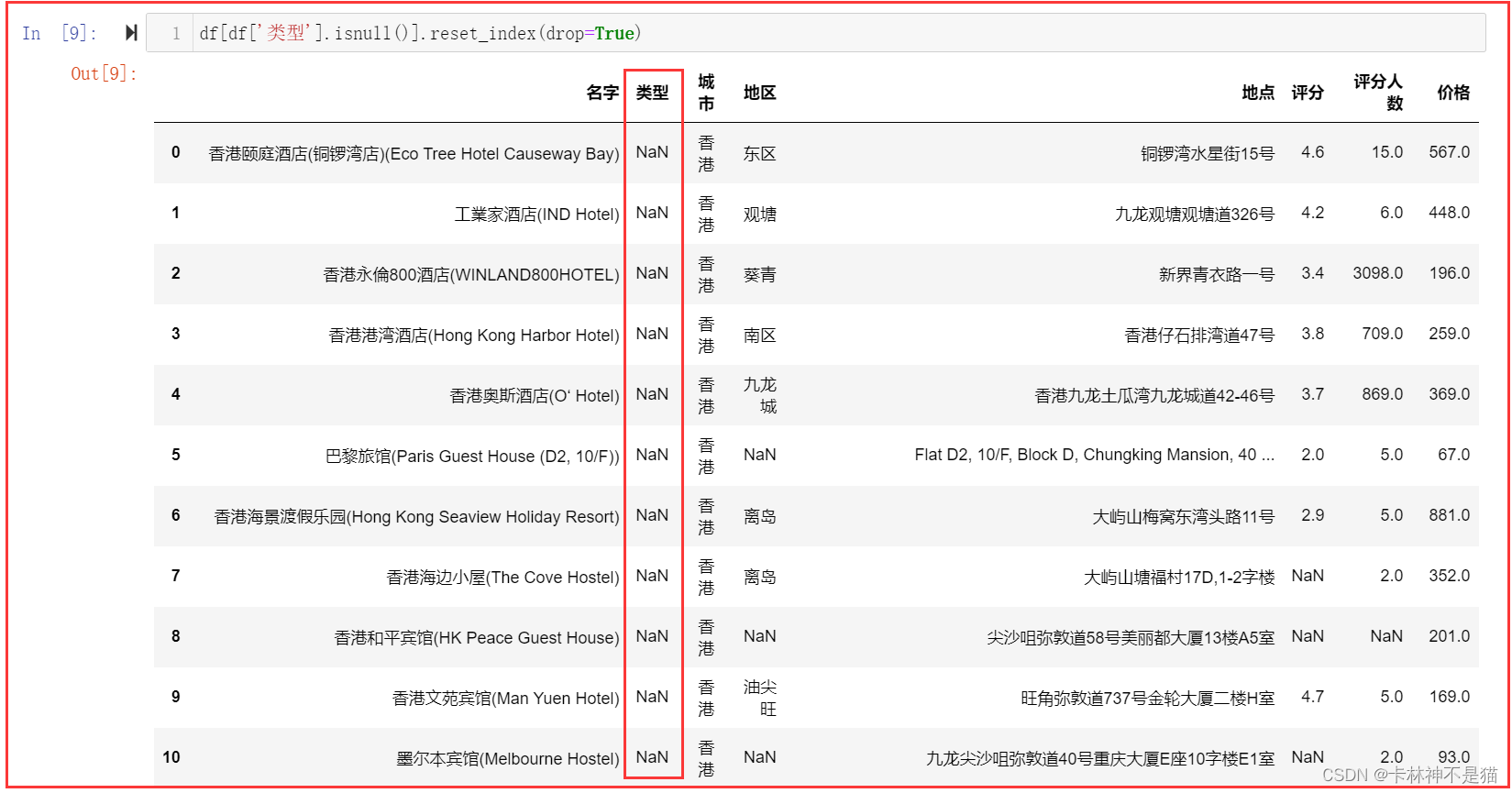
5. 查看类型缺失的数据。
df[df['类型'].isnull()].reset_index(drop=True)
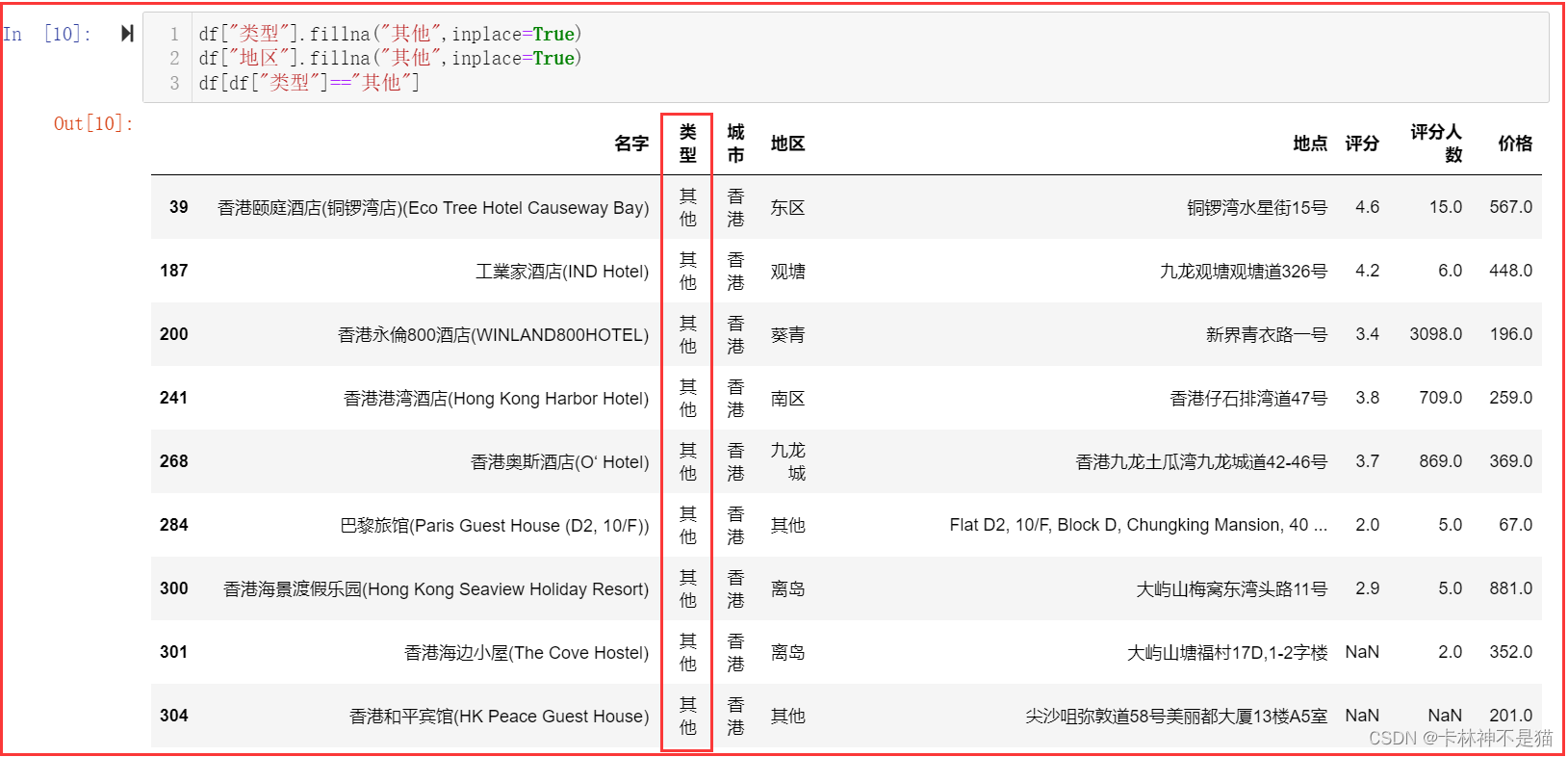
6. 用“其他”填充类型和地区。
df["类型"].fillna("其他",inplace=True)
df["地区"].fillna("其他",inplace=True)
df[df["类型"]=="其他"]
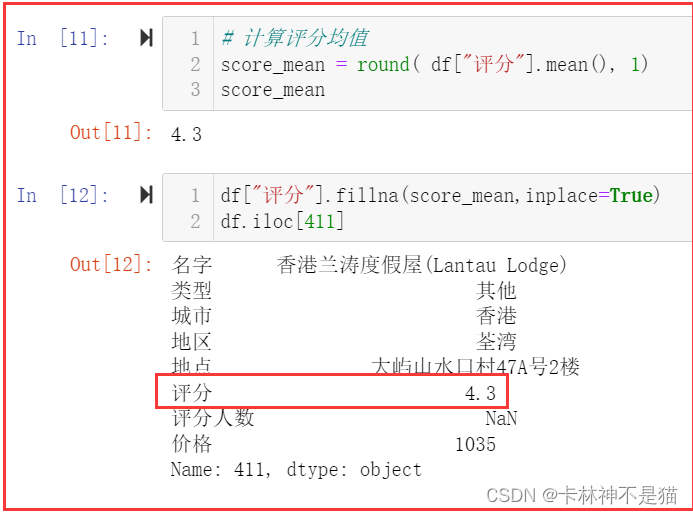
7. 用评分均值填充缺失值。
# 计算评分均值
score_mean = round( df["评分"].mean(), 1)
score_meandf["评分"].fillna(score_mean,inplace=True)
df.iloc[411]
8. 删除价格和评分人数的缺失值。
df.dropna(subset=['价格', '评分人数'], inplace=True)
# 显示清理后的DataFrame的前五行
df.head()

9. 保存到“酒店数据1.xlsx”
df = df.reset_index(drop=True)
df.to_excel(fr"../data/酒店数据1.xlsx",index=False)
二、复杂数据处理:读取上一题的“酒店数据1.xlsx”数据,按要求解决以下问题。
1. 读取数据。读取上一题目保存的“酒店数据1.xlsx”。
df = pd.read_excel(fr"../data/酒店数据1.xlsx")
df.head()

2. 查看“评分”的格式,并分别进行升序和降序排序。
df["评分"].dtype# 升序排序
df_r = df.sort_values(by="评分",ascending=True).reset_index(drop=True)
df_r.head()# 降序排序
df_d = df.sort_values(by="评分",ascending=False).reset_index(drop=True)
df_d.head()

3. 对酒店按照价格进行排名,计算“油尖旺”地区的均价。
df.dtypes# 筛选出位于“油尖旺”地区的酒店
oil_jian_wang_hotels = df[df['地区'] == '油尖旺']
# 计算“油尖旺”地区的酒店均价
average_price_oil_jian_wang = oil_jian_wang_hotels['价格'].mean()
average_price_oil_jian_wangsorted_hotels = df.sort_values(by='价格', ascending=False).reset_index(drop=True) # 显示排序后的酒店列表(例如,显示前10名)
print("按价格降序排序的酒店:")
sorted_hotels[['名字', '价格']].head(10)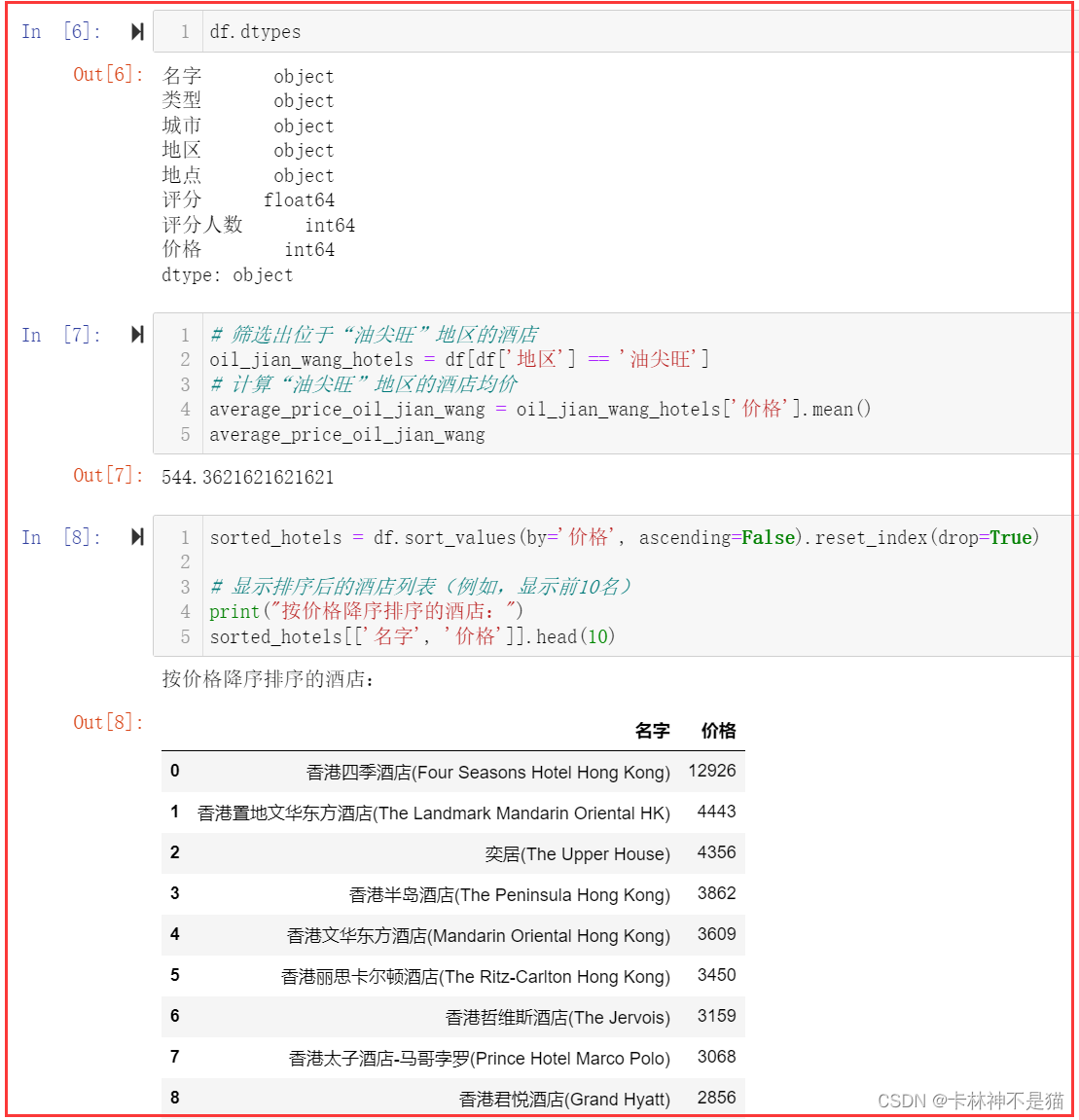
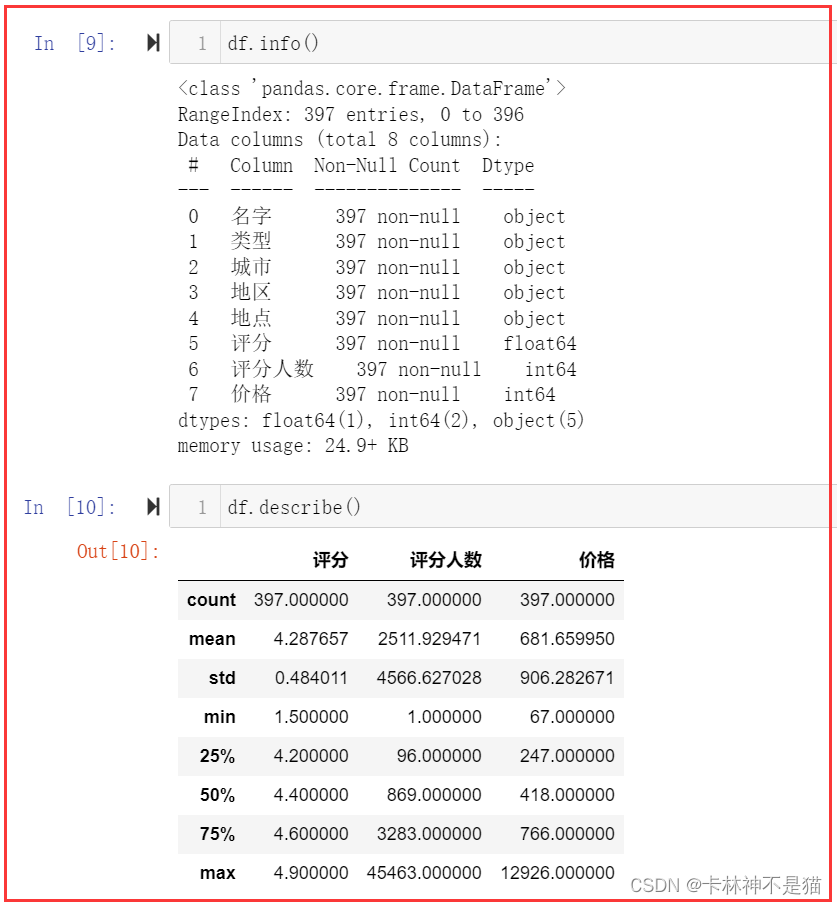
4. 对酒店数据进行描述性统计,并求所有价格的均值方差,最大最小值,中值。
df.info()df.describe()
5. 计算评分和价格之间的的相关系数,协方差。
# 计算评分和价格之间的相关系数
correlation = df['评分'].corr(df['价格'])
print(f"评分和价格之间的相关系数为:{correlation:.4f}") # 计算评分和价格之间的协方差
covariance = df['评分'].cov(df['价格'])
print(f"评分和价格之间的协方差为:{covariance:.2f}")

6. 按照评分降序排序,评分相同时按价格升序排序。
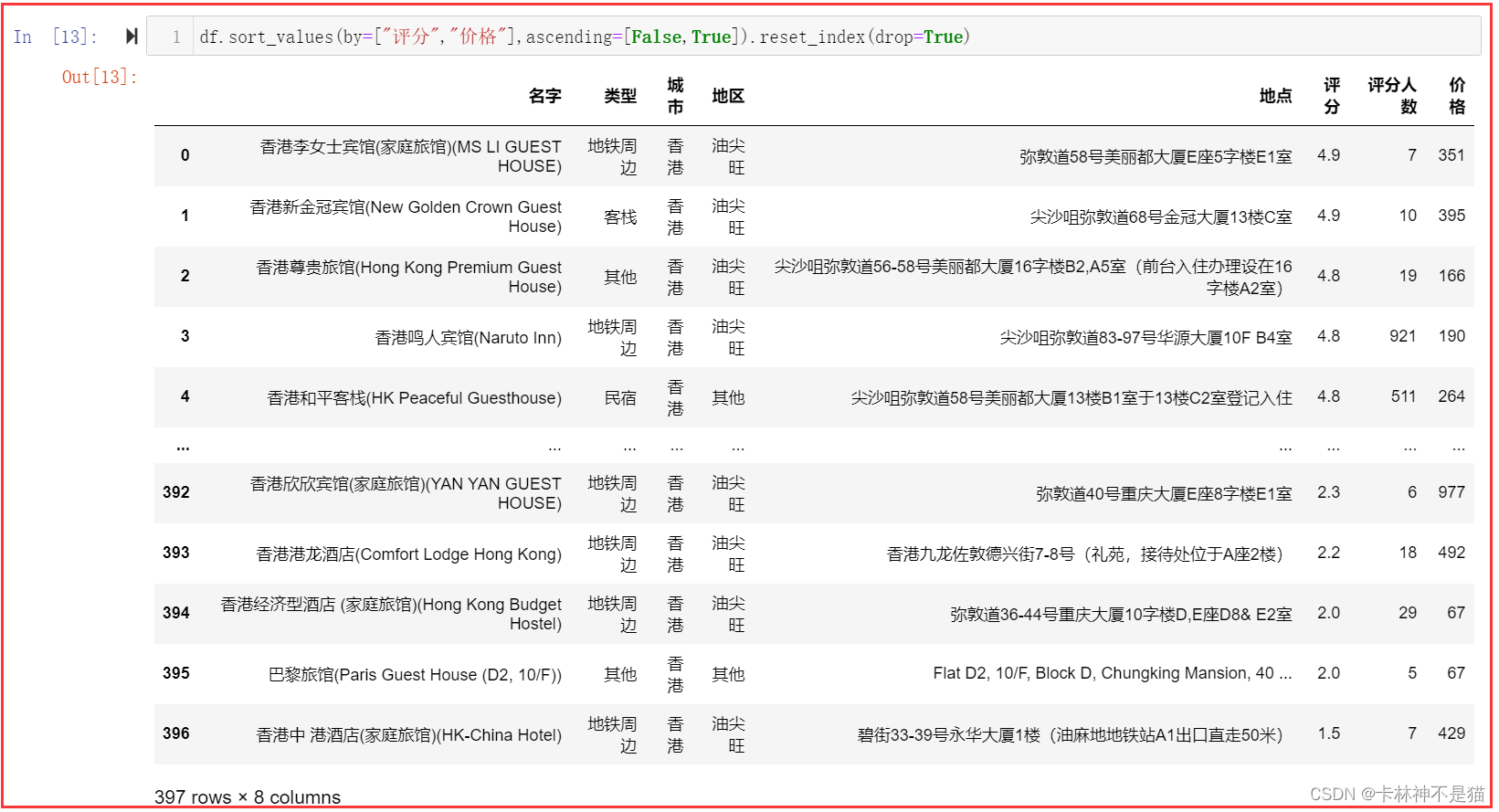
df.sort_values(by=["评分","价格"],ascending=[False,True]).reset_index(drop=True)
7. 计算评分小于3分的酒店数量和占比。
df.query("评分 < 3")["名字"].count()df.query("评分 < 3")["名字"].count() / df["名字"].count()

8. 计算酒店评分大于等于4分的酒店的价格均值。
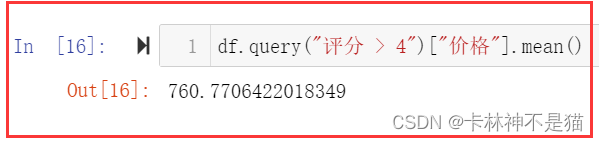
df.query("评分 > 4")["价格"].mean()
9. 计算出每个地区的酒店占总酒店数量的比例。
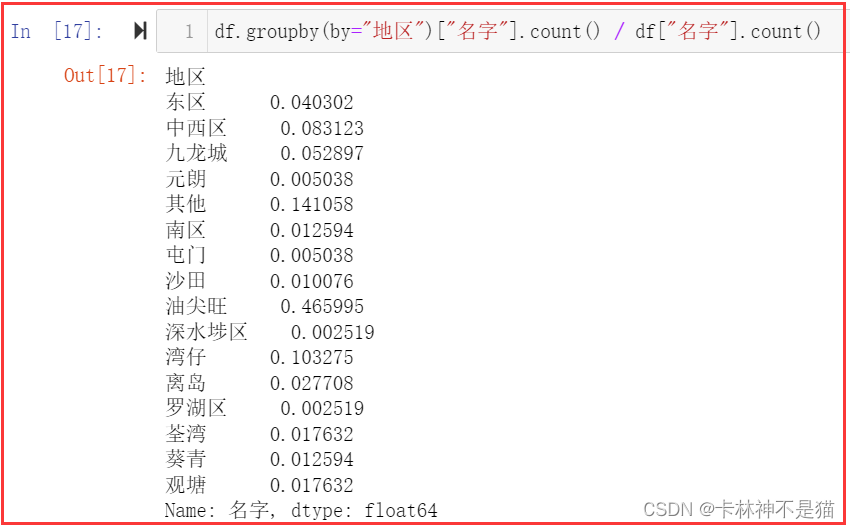
df.groupby(by="地区")["名字"].count() / df["名字"].count()
10. 找出酒店评分人数排名前20的酒店,并计算他们的价格均值。
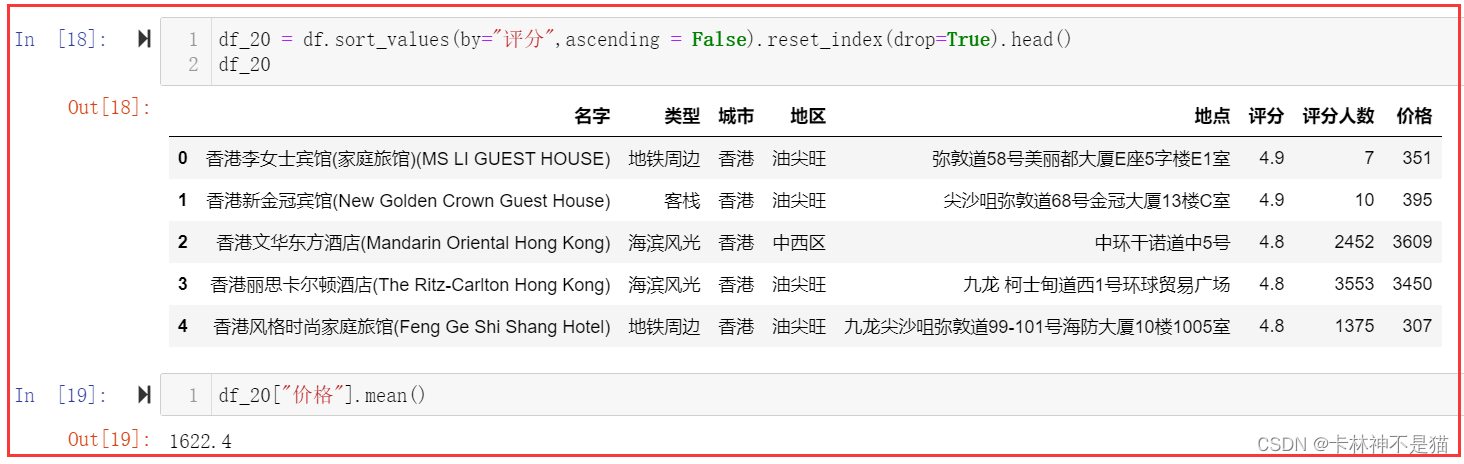
df_20 = df.sort_values(by="评分",ascending = False).reset_index(drop=True).head()
df_20df_20["价格"].mean()
11. 查看酒店分布的类型数量和地区数量,并统计各个类型和地区包含的酒店数量。
# 类型数量
df["类型"].unique().size# 地区
df["地区"].unique().sizedf.groupby(by="类型")["名字"].count()df.groupby(by="地区")["名字"].count()

12. 用数据透视表,计算每个类型的酒店的评分人数总数量。
# 使用pivot_table计算每个类型的酒店的评分人数总数量
pivot_table = df.pivot_table(index='类型', values='评分', aggfunc='count') # 重命名列名以使其更具描述性
pivot_table.columns = ['评分人数'] # 显示数据透视表
pivot_table

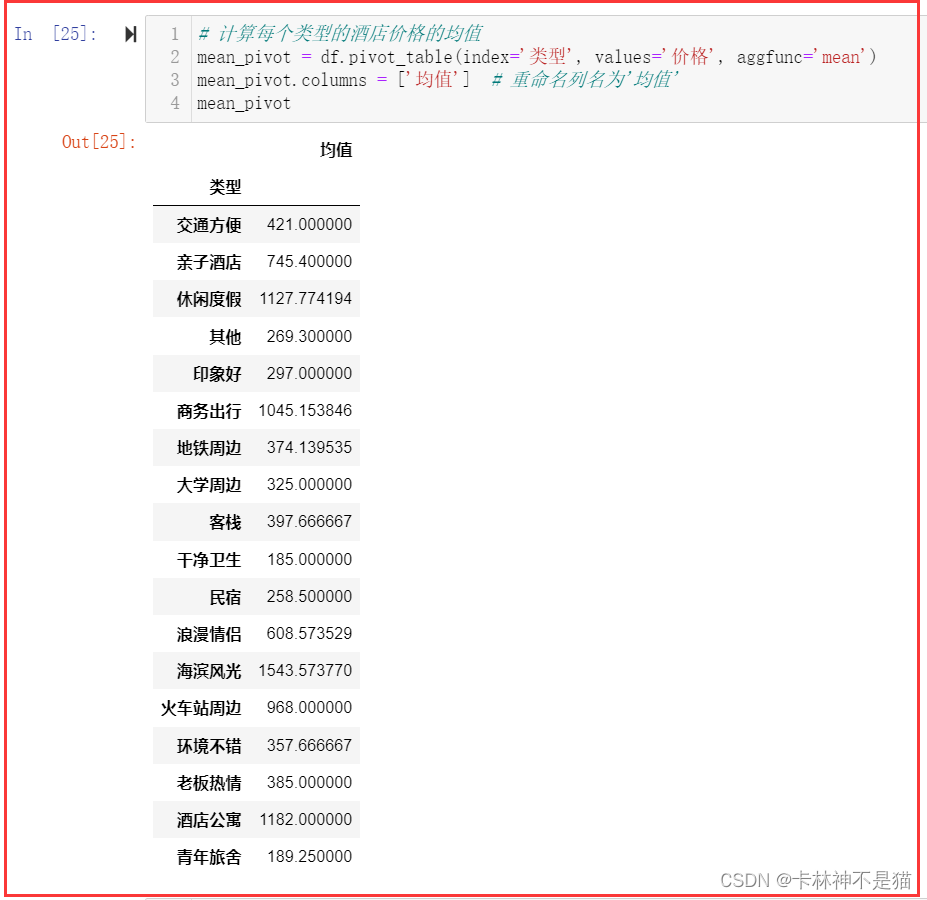
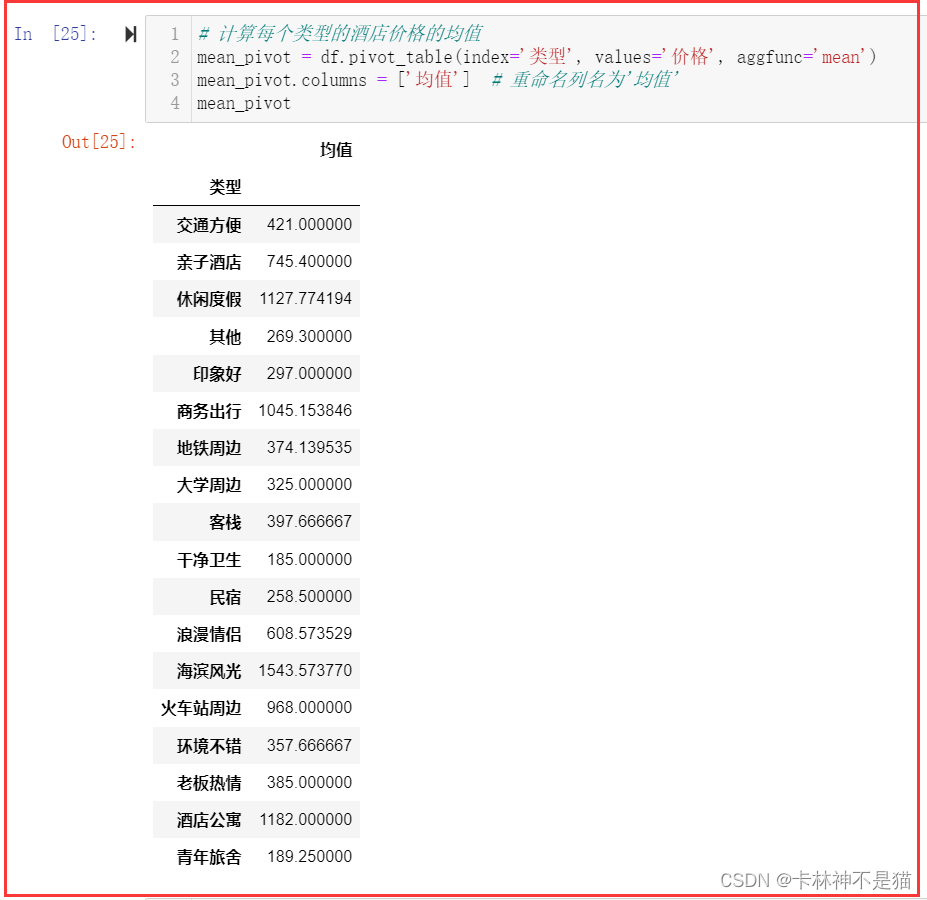
13. 用数据透视表,计算每个类型的酒店价格的均值和标准差。
# 计算每个类型的酒店价格的均值
mean_pivot = df.pivot_table(index='类型', values='价格', aggfunc='mean')
mean_pivot.columns = ['均值'] # 重命名列名为'均值'
mean_pivot# 计算每个类型的酒店价格的标准差
# 标准差是需要两个数据点,一个数据点就会计算不出来std_pivot = df.pivot_table(index='类型', values='价格', aggfunc='std')
std_pivot.columns = ['标准差'] # 重命名列名为'标准差'
std_pivot# 将均值和标准差合并到一个DataFrame中
result = mean_pivot.join(std_pivot)
result
14. 用数据透视表,计算每个地区酒店价格和评分的最大值和最小值。
# 使用pivot_table计算每个地区的酒店价格和评分的最大值和最小值
pivot_table = df.pivot_table( index='地区', values=['价格', '评分'], aggfunc={'价格': ['max', 'min'], '评分': ['max', 'min']}
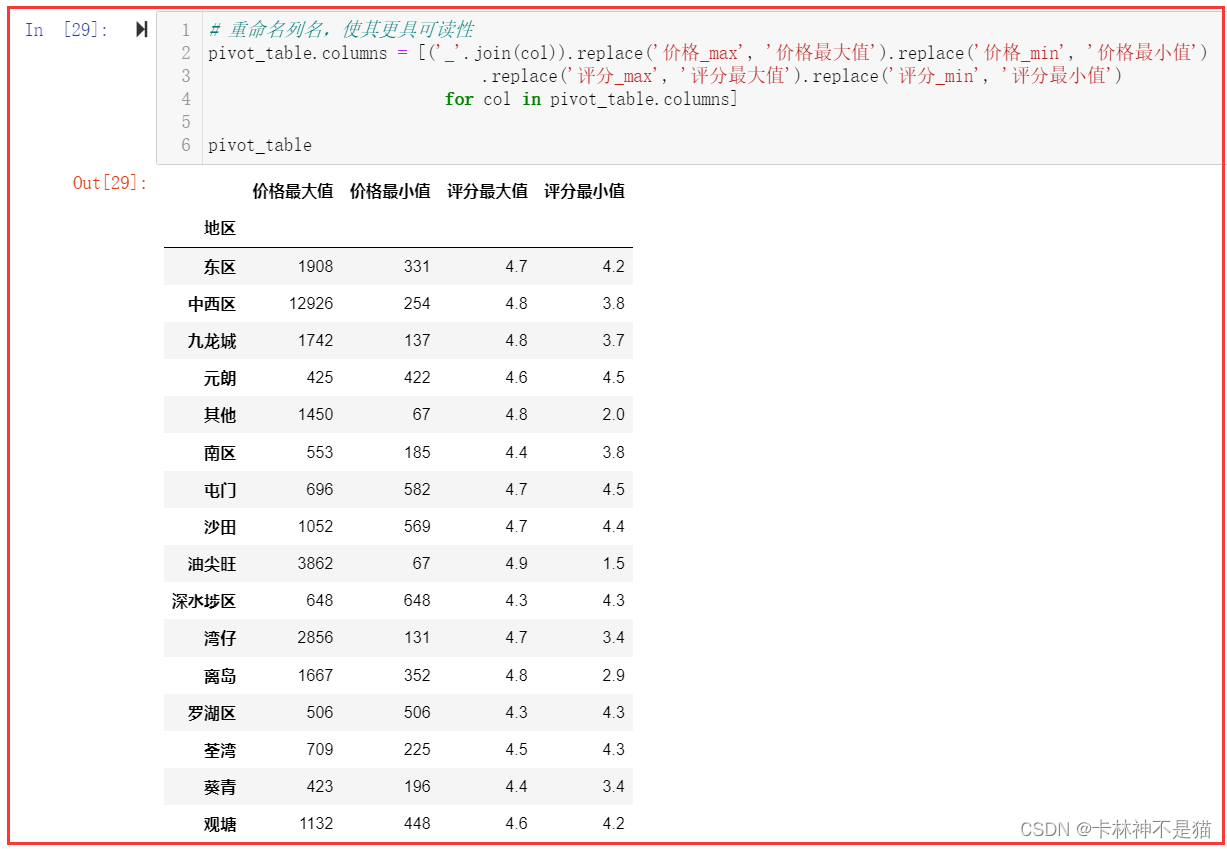
) pivot_table# 重命名列名,使其更具可读性
pivot_table.columns = [('_'.join(col)).replace('价格_max', '价格最大值').replace('价格_min', '价格最小值') .replace('评分_max', '评分最大值').replace('评分_min', '评分最小值') for col in pivot_table.columns] pivot_table


15. 用数据透视表,计算每个地区和类型的酒店的评分的均值和标准差。
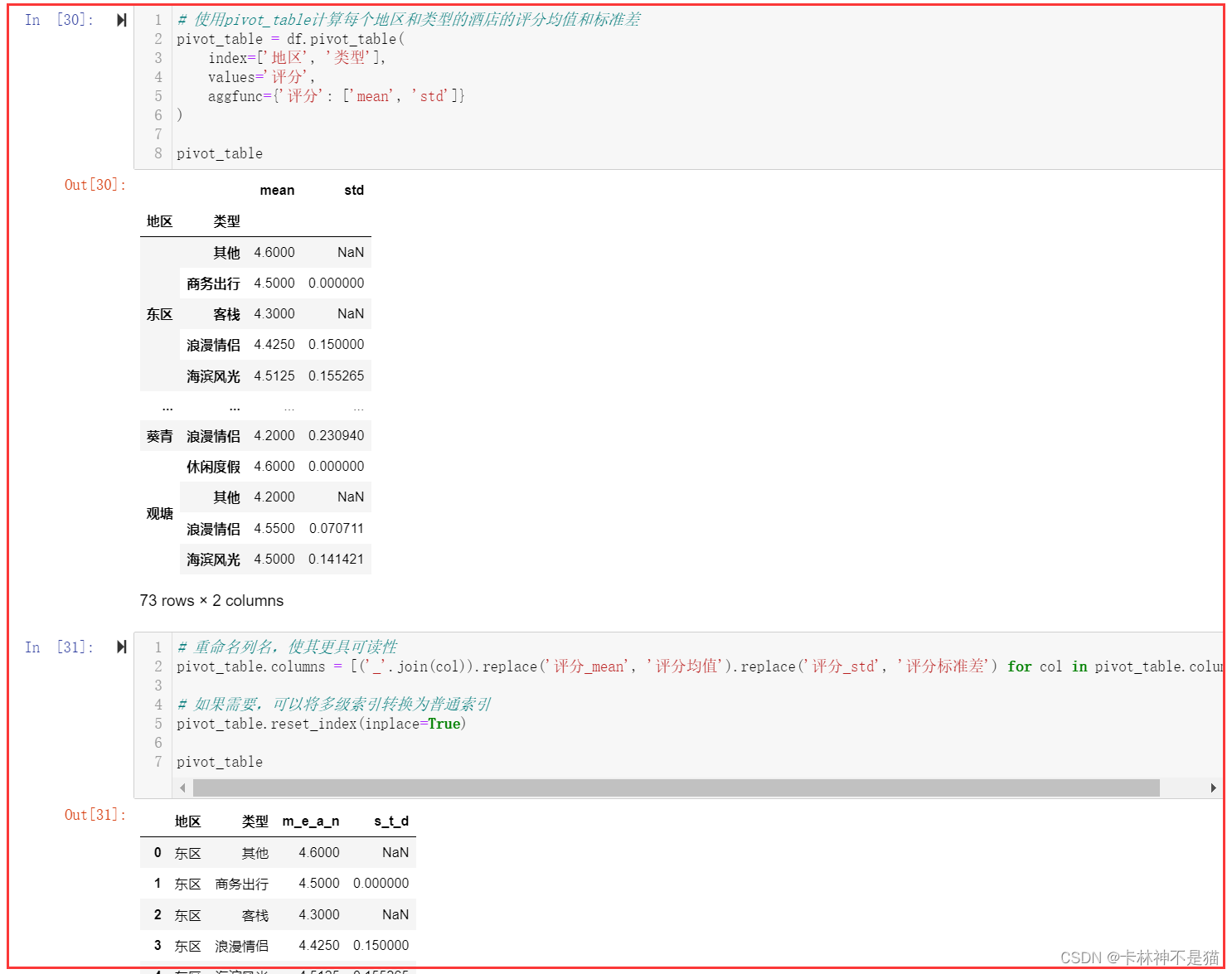
# 使用pivot_table计算每个地区和类型的酒店的评分均值和标准差
pivot_table = df.pivot_table( index=['地区', '类型'], values='评分', aggfunc={'评分': ['mean', 'std']}
) pivot_table# 重命名列名,使其更具可读性
pivot_table.columns = [('_'.join(col)).replace('评分_mean', '评分均值').replace('评分_std', '评分标准差') for col in pivot_table.columns] # 如果需要,可以将多级索引转换为普通索引
pivot_table.reset_index(inplace=True) pivot_table
16. 将“类型”和“名字”设置为层次化索引,并交换索引的位置。然后将层次化索引取消。
# 设置层次化索引,先按“类型”再按“名字”
df_hierarchical = df.set_index(['类型', '名字'])
df_hierarchical# 交换索引的位置,先按“名字”再按“类型”
df_swapped = df_hierarchical.swaplevel(0, 1)
df_swapped# 取消层次化索引,将其转换为普通列
df_reset = df_swapped.reset_index()
df_reset

17. 将数据集转置,获取转置后的index和columns。
# 数据集转置
df.T.head()# 获取index
df.T.index# 获取columns
df.T.columns
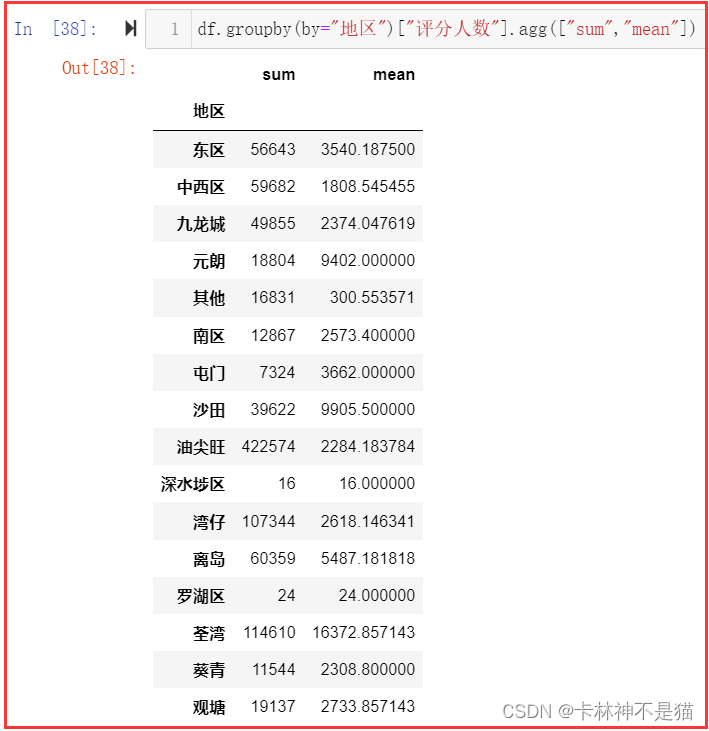
18. 用Groupby方法来计算每个地区的评分人数的总和以及均值。
df.groupby(by="地区")["评分人数"].agg(["sum","mean"])
19. 用Grouby方法计算每个类型的平均价格,最高价和最低价。
df.groupby(by="类型")["价格"].agg(["max","min"])
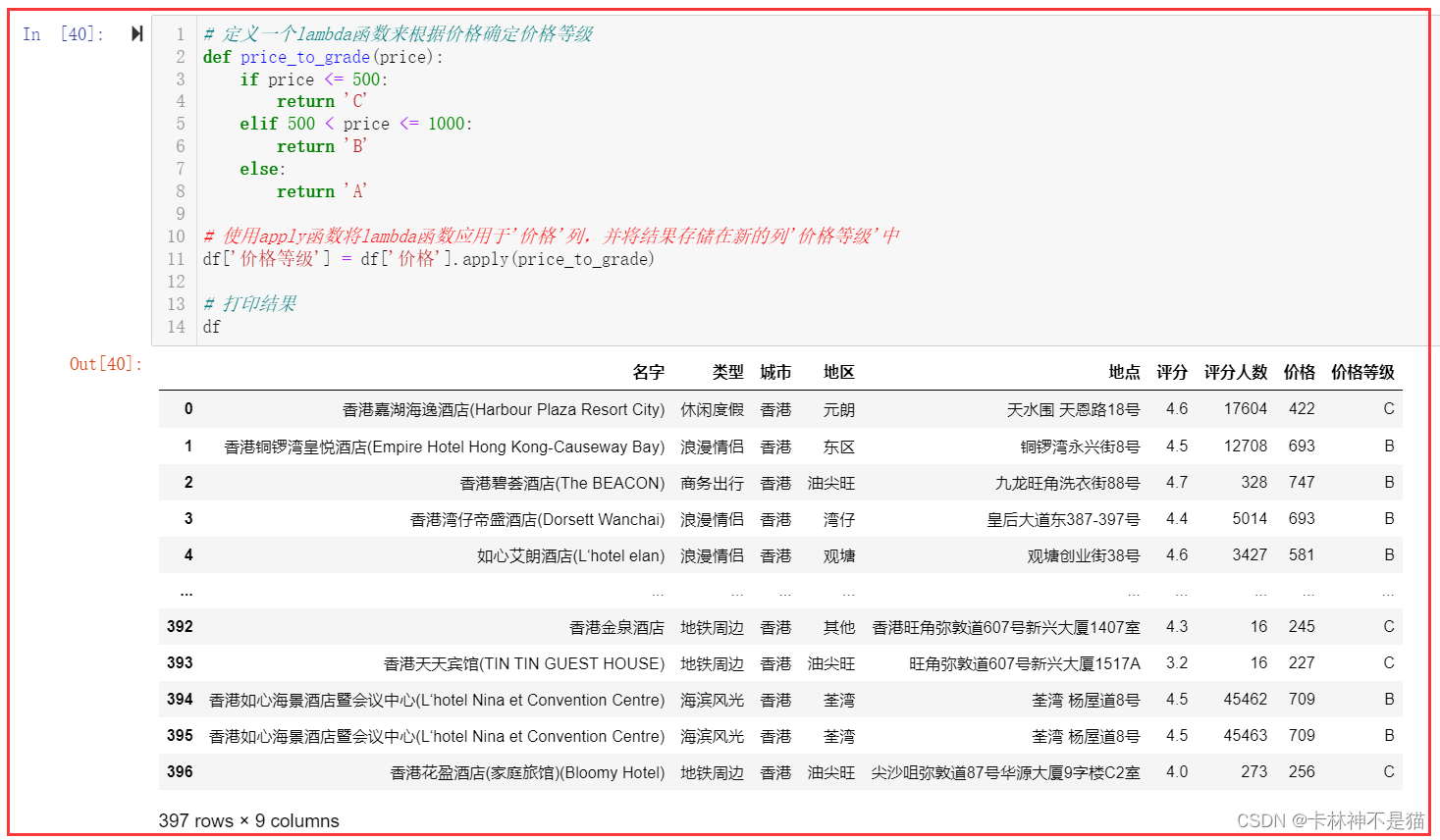
20. 数据离散化,按照价格将酒店分为3个等级,0-500为C,500-1000为B,大于1000为A,列名设置为“价格等级”。
# 定义一个lambda函数来根据价格确定价格等级
def price_to_grade(price): if price <= 500: return 'C' elif 500 < price <= 1000: return 'B' else: return 'A' # 使用apply函数将lambda函数应用于'价格'列,并将结果存储在新的列'价格等级'中
df['价格等级'] = df['价格'].apply(price_to_grade) # 打印结果
df
21. 获取评分均值最高和最低的地区的数据,分别使用append和concat方法将获取的两个数据集合并。
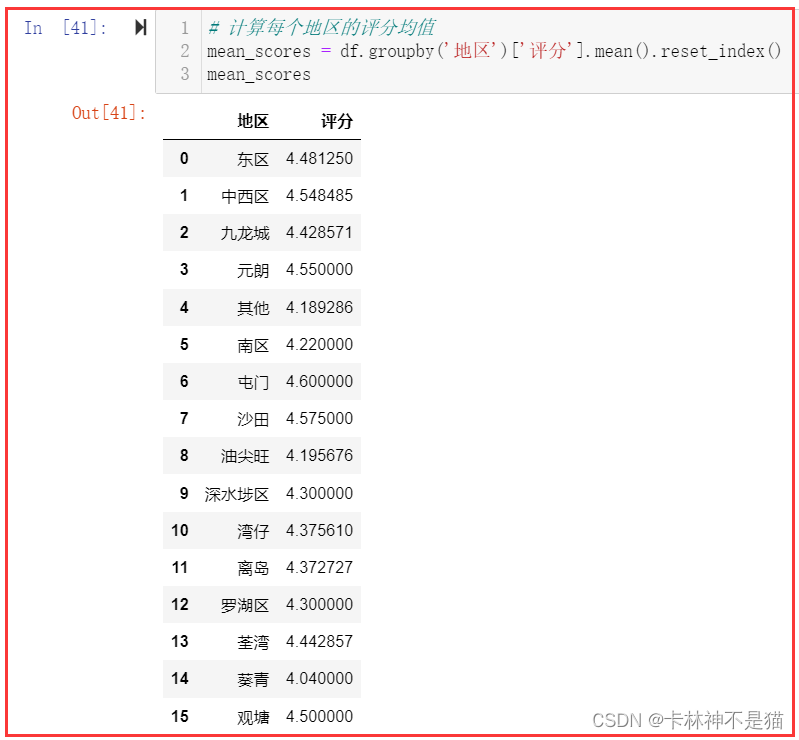
# 计算每个地区的评分均值
mean_scores = df.groupby('地区')['评分'].mean().reset_index()
mean_scores# 找出评分均值最高和最低的地区
max_score_area = mean_scores.loc[mean_scores['评分'].idxmax()]
min_score_area = mean_scores.loc[mean_scores['评分'].idxmin()] # 提取评分均值最高和最低地区的数据
max_score_data = df[df['地区'] == max_score_area['地区']]
min_score_data = df[df['地区'] == min_score_area['地区']] # 使用append方法合并数据集
combined_with_append = max_score_data.append(min_score_data, ignore_index=True) # 使用concat方法合并数据集(需要先创建列表)
combined_list = [max_score_data, min_score_data]
combined_with_concat = pd.concat(combined_list, ignore_index=True) # 打印结果
print("使用append方法合并的数据集:")
display(combined_with_append)
print("\n使用concat方法合并的数据集:")
display(combined_with_concat)

22. 数据离散化,按照评分人数将酒店平均分为3个等级,三个等级的酒店数量尽量保持一致。评分人数最多的为A,最少的为C。列名设置为“热门等级”。
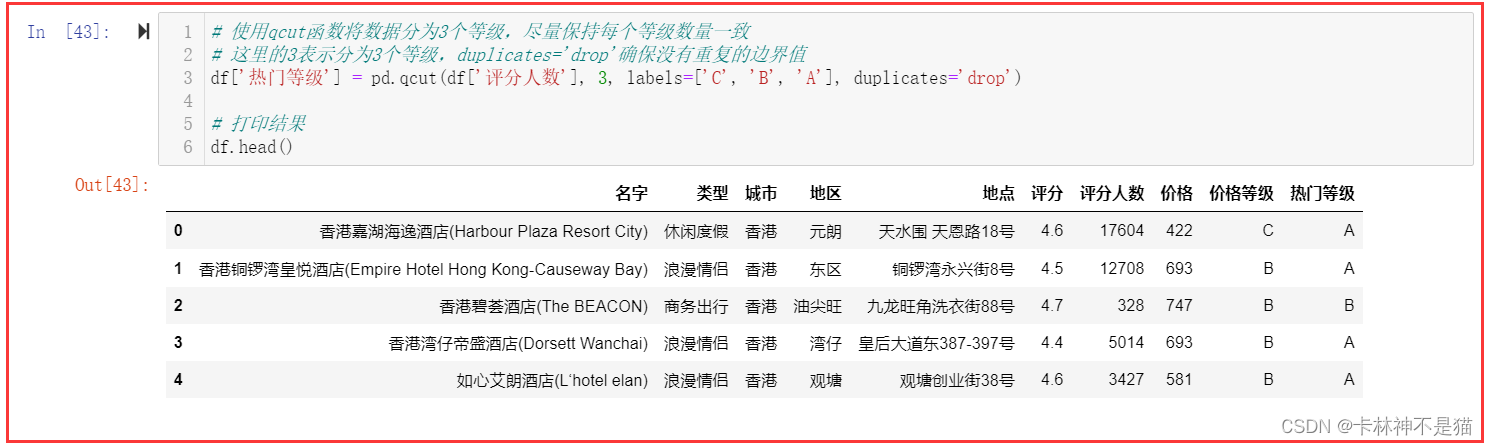
# 使用qcut函数将数据分为3个等级,尽量保持每个等级数量一致
# 这里的3表示分为3个等级,duplicates='drop'确保没有重复的边界值
df['热门等级'] = pd.qcut(df['评分人数'], 3, labels=['C', 'B', 'A'], duplicates='drop') # 打印结果
df.head()
23. 选出评分人数为A,价格也为A的酒店数据,计算其平均评分。
# 筛选数据
df_select = df.query("热门等级 == 'A' & 价格等级 == 'A'")# 计算均值
df_reset["评分"].mean()

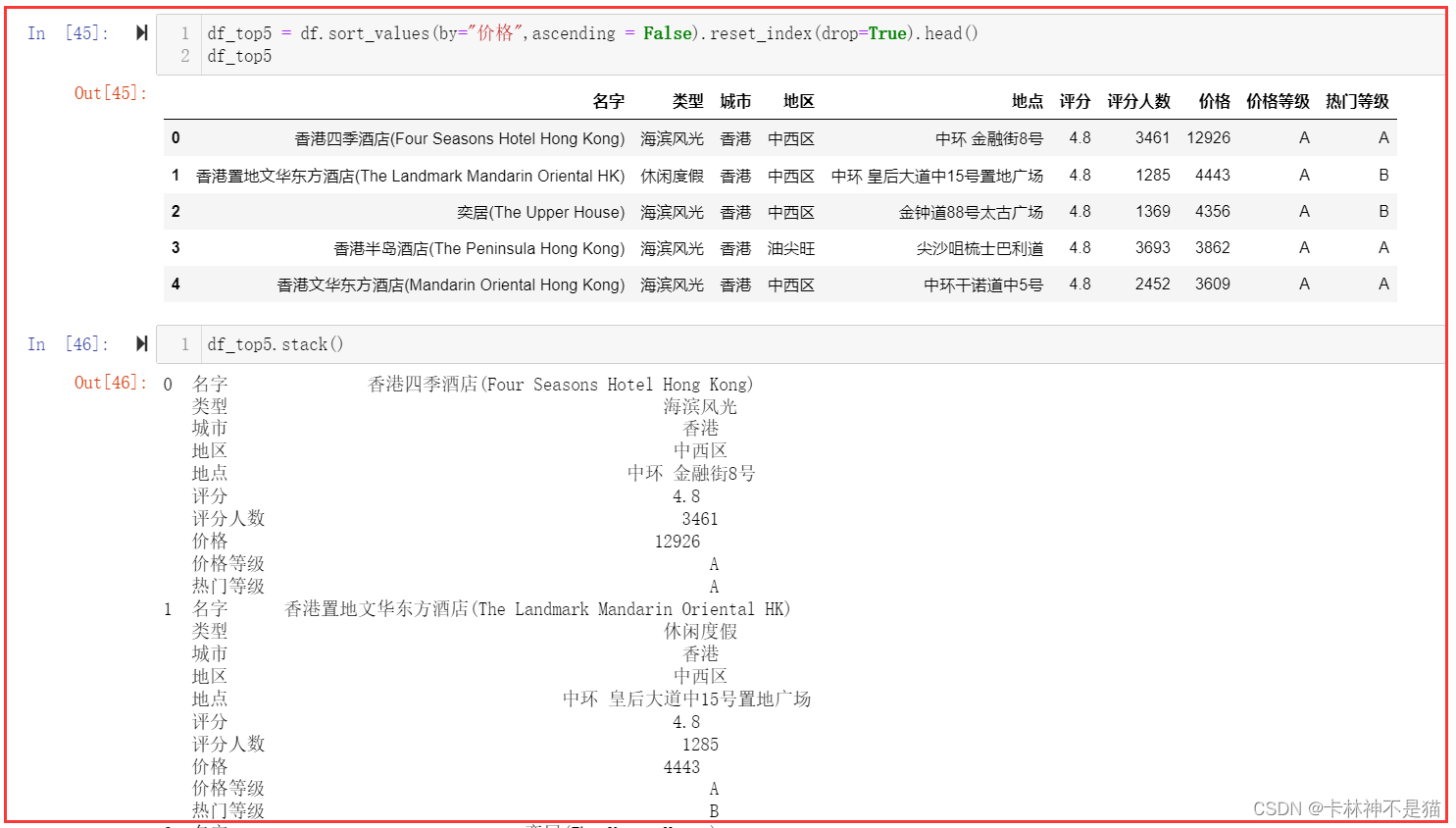
24. 取价格最高的5个酒店的数据,使用stack和unstack方法实现dataframe和Series之间的转换。
df_top5 = df.sort_values(by="价格",ascending = False).reset_index(drop=True).head()
df_top5df_top5.stack()df_top5.unstack()

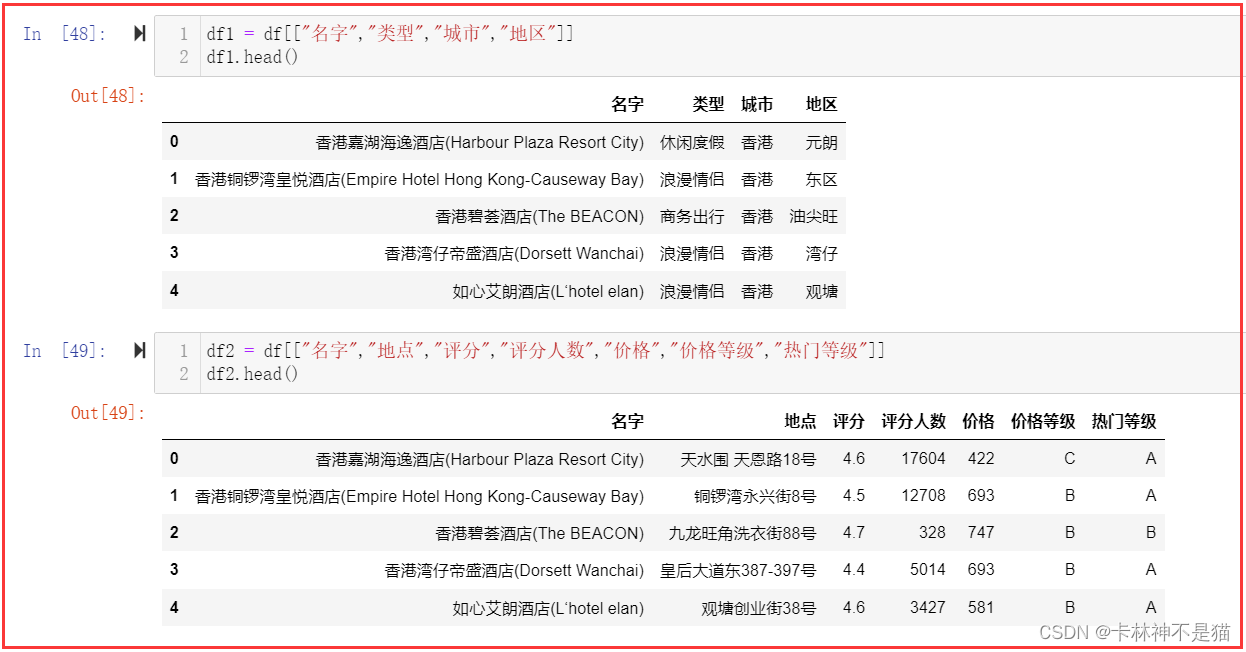
25. 纵向拆分数据集,分为df1和df2,df1包含名字,类型,城市,地区,df2包含名字,地点,评分,评分人数,价格,价格等级,热门等级。
df1 = df[["名字","类型","城市","地区"]]
df1.head()df2 = df[["名字","地点","评分","评分人数","价格","价格等级","热门等级"]]
df2.head()
26. 将df2按照价格进行排序,重新设置df2的索引。索引值等于价格排名。
df2.sort_values(by="价格",ascending=False).reset_index(drop=True)

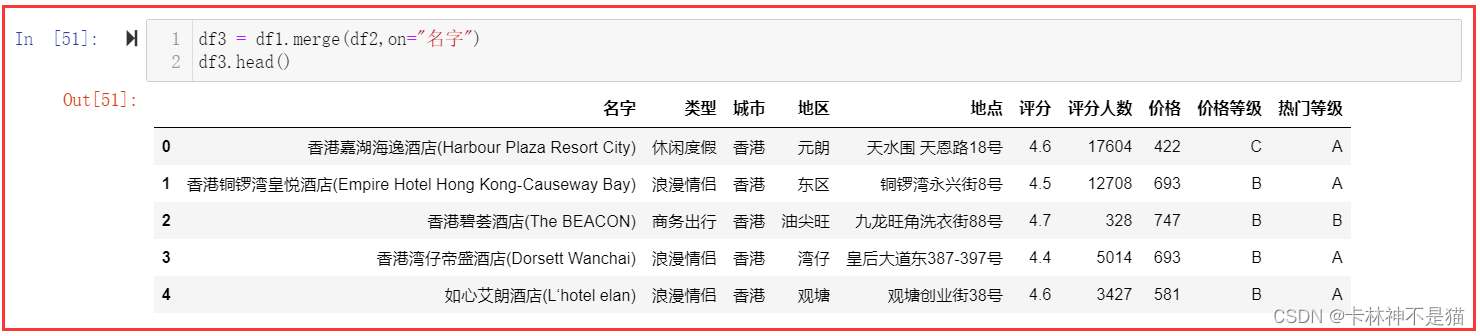
27. 使用merge方法将df1和df2合并。
df3 = df1.merge(df2,on="名字")
df3.head()
28. 将合并后的数据集保存数据到“酒店数据2.xlsx”。
df3 = df3.reset_index(drop=True)
df3.to_excel(fr"../data/酒店数据2.xlsx",index=False)
三、数据可视化:完成以下可视化问题。
1. 画出 𝑦=𝑥^2+2𝑥+1在区间[-5,3]的函数图像。
import matplotlib.pyplot as plt
import numpy as np # 创建一个x值数组,范围从-5到3,包含50个点
x = np.linspace(-5, 3, 50) # 计算对应的y值
y = x**2 + 2*x + 1 # 创建一个新的图形
plt.figure() # 画出函数图像
plt.plot(x, y) # 设置x轴和y轴的标签
plt.xlabel('x')
plt.ylabel('y') # 设置图形的标题
plt.title('y = x^2 + 2x + 1') # 显示图形
plt.show()

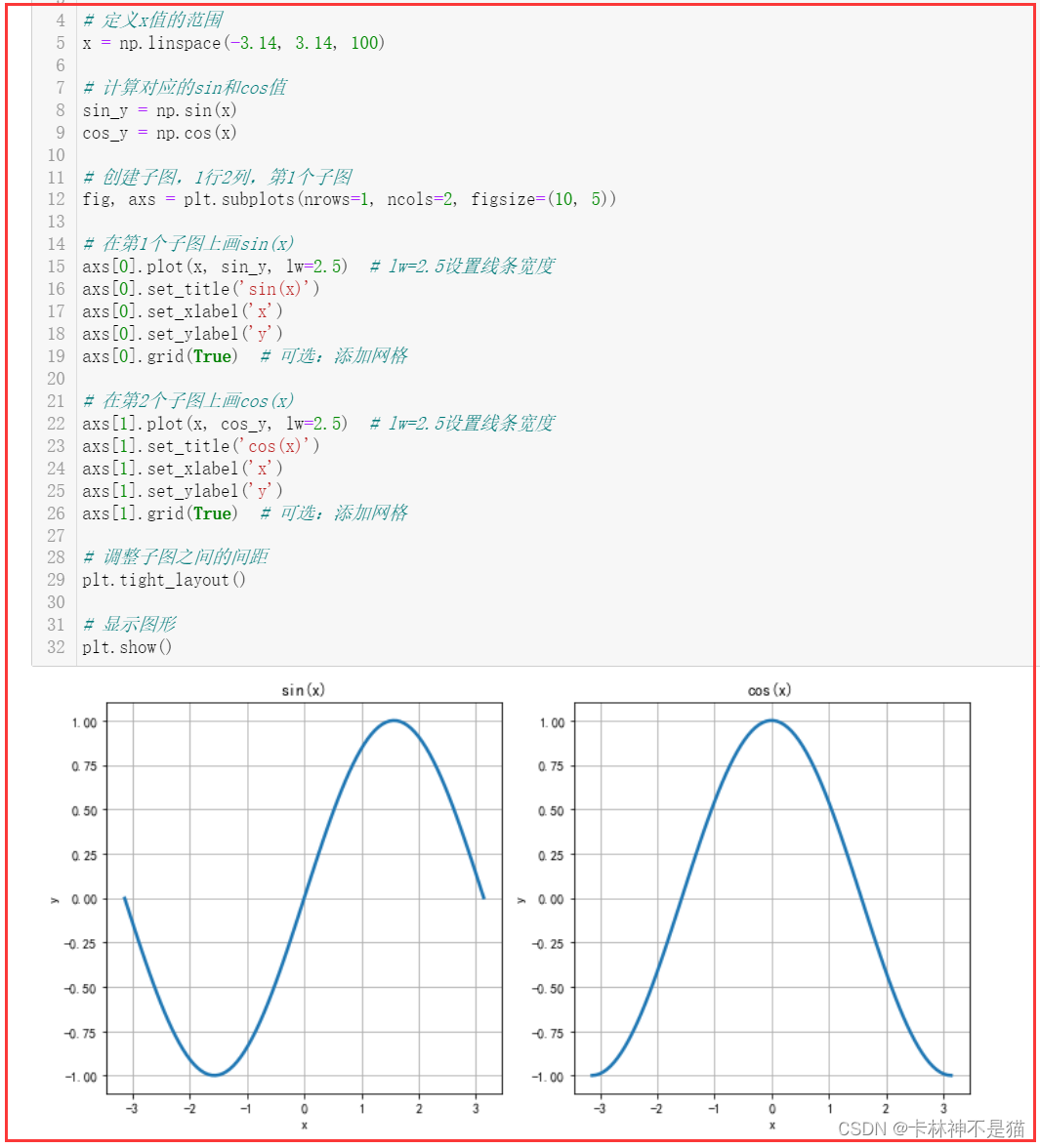
2. 在同一张图中创建两个子图,分别画出 s i n ( x ) sin(x) sin(x)和 c o s ( x ) cos(x) cos(x)在[-3.14,3.14]上的函数图像。设置线条宽度为2.5。
import matplotlib.pyplot as plt
import numpy as np # 定义x值的范围
x = np.linspace(-3.14, 3.14, 100) # 计算对应的sin和cos值
sin_y = np.sin(x)
cos_y = np.cos(x) # 创建子图,1行2列,第1个子图
fig, axs = plt.subplots(nrows=1, ncols=2, figsize=(10, 5)) # 在第1个子图上画sin(x)
axs[0].plot(x, sin_y, lw=2.5) # lw=2.5设置线条宽度
axs[0].set_title('sin(x)')
axs[0].set_xlabel('x')
axs[0].set_ylabel('y')
axs[0].grid(True) # 可选:添加网格 # 在第2个子图上画cos(x)
axs[1].plot(x, cos_y, lw=2.5) # lw=2.5设置线条宽度
axs[1].set_title('cos(x)')
axs[1].set_xlabel('x')
axs[1].set_ylabel('y')
axs[1].grid(True) # 可选:添加网格 # 调整子图之间的间距
plt.tight_layout() # 显示图形
plt.show()
3. 读取保存的“酒店数据2”数据,画出每个地区酒店数量的柱状图,柱状颜色为红色。
df = pd.read_excel(fr"../data/酒店数据2.xlsx")
df.head()# 计算每个地区的酒店数量
hotel_counts = df['地区'].value_counts() # 设置图像大小
plt.figure(figsize=(12, 6)) # 你可以根据需要调整宽度和高度 # 绘制柱状图,设置柱状颜色为红色
plt.bar(hotel_counts.index, hotel_counts.values, color='red') # 旋转x轴标签45度,使得标签之间有足够的空间
plt.xticks(rotation=45, ha='right') # 设置图表标题和坐标轴标签
plt.title('每个地区酒店数量')
plt.xlabel('地区')
plt.ylabel('酒店数量') # 显示图表
plt.tight_layout() # 调整子图参数,使之填充整个图像区域
plt.show()

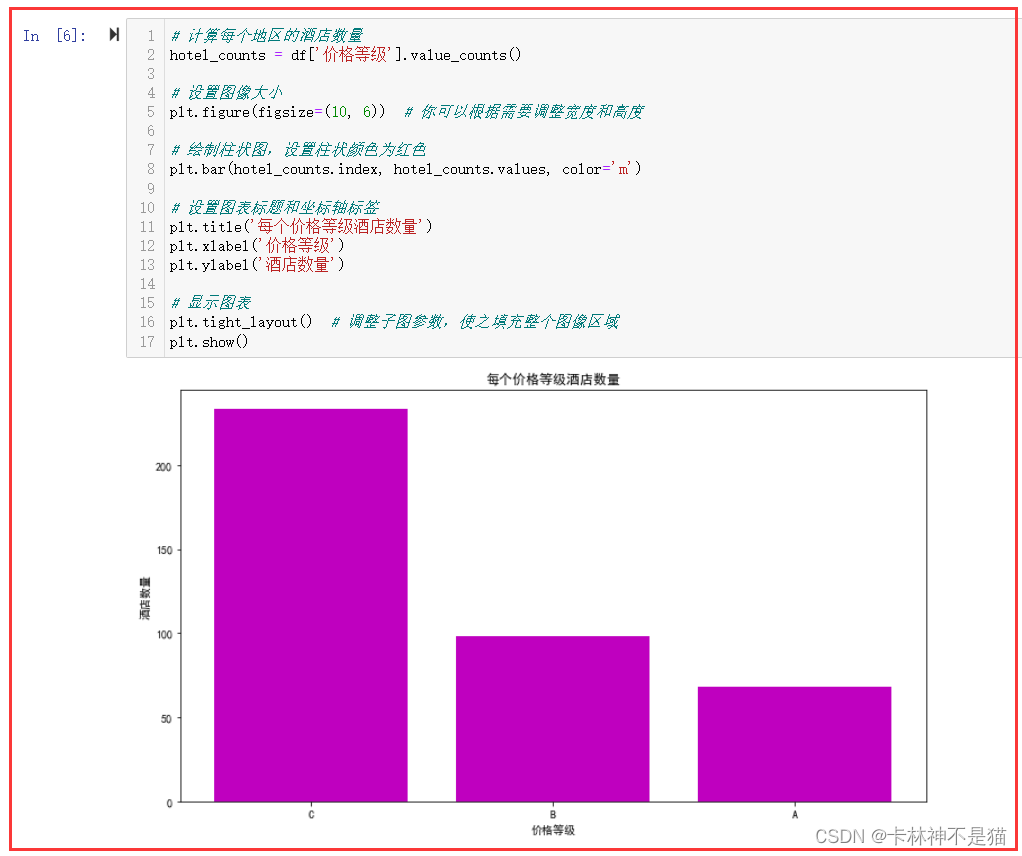
4. 画出每个价格等级酒店数量的柱状图。
# 计算每个地区的酒店数量
hotel_counts = df['价格等级'].value_counts() # 设置图像大小
plt.figure(figsize=(10, 6)) # 你可以根据需要调整宽度和高度 # 绘制柱状图,设置柱状颜色为红色
plt.bar(hotel_counts.index, hotel_counts.values, color='m') # 设置图表标题和坐标轴标签
plt.title('每个价格等级酒店数量')
plt.xlabel('价格等级')
plt.ylabel('酒店数量') # 显示图表
plt.tight_layout() # 调整子图参数,使之填充整个图像区域
plt.show()
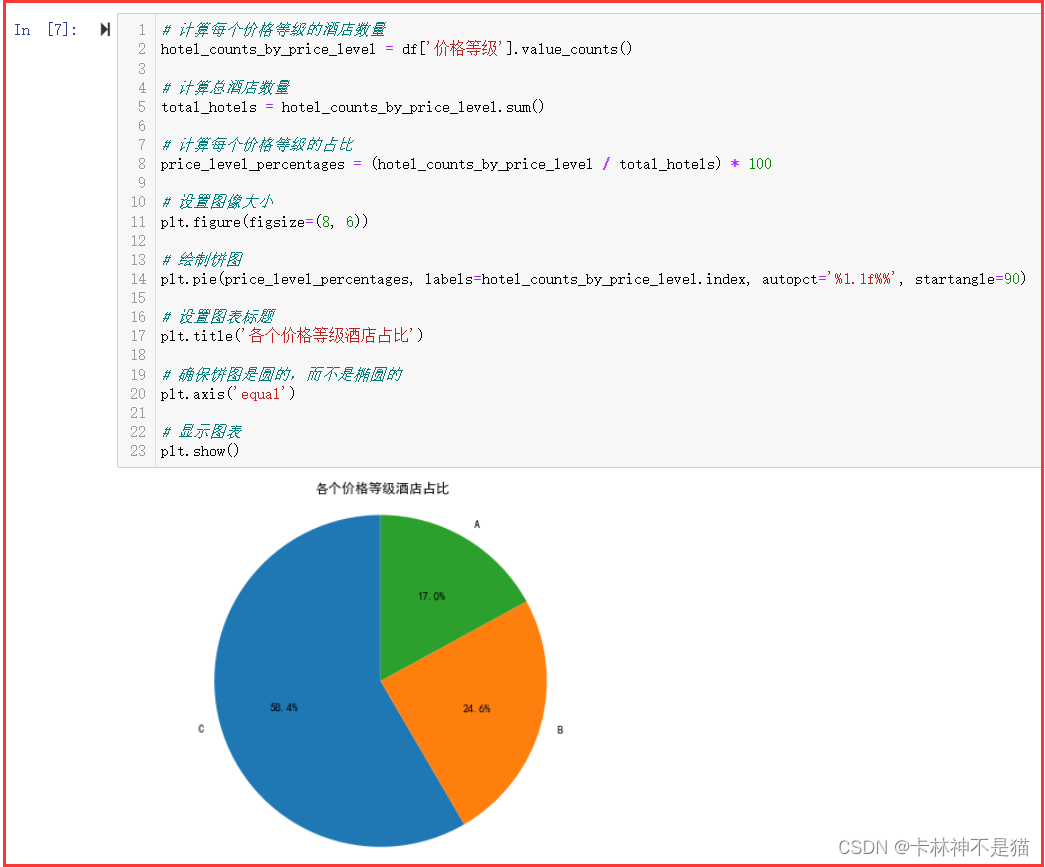
5. 画出各个价格等级占比的饼图。
# 计算每个价格等级的酒店数量
hotel_counts_by_price_level = df['价格等级'].value_counts() # 计算总酒店数量
total_hotels = hotel_counts_by_price_level.sum() # 计算每个价格等级的占比
price_level_percentages = (hotel_counts_by_price_level / total_hotels) * 100 # 设置图像大小
plt.figure(figsize=(8, 6)) # 绘制饼图
plt.pie(price_level_percentages, labels=hotel_counts_by_price_level.index, autopct='%1.1f%%', startangle=90) # 设置图表标题
plt.title('各个价格等级酒店占比') # 确保饼图是圆的,而不是椭圆的
plt.axis('equal') # 显示图表
plt.show()
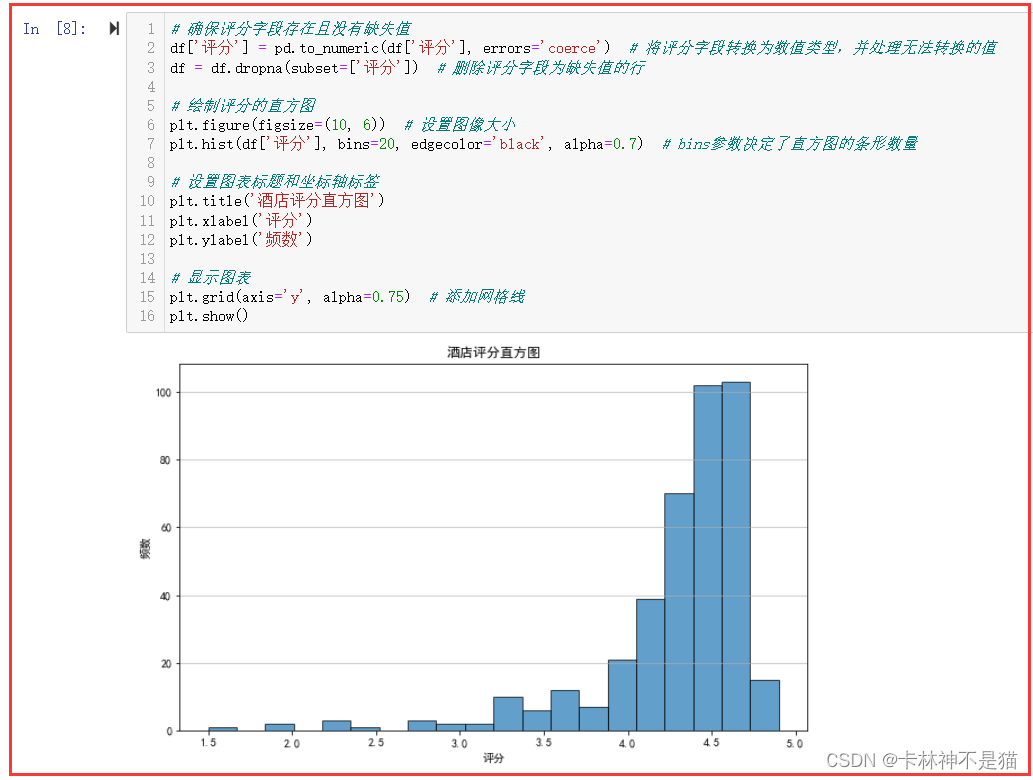
6. 画出酒店评分的直方图。
# 确保评分字段存在且没有缺失值
df['评分'] = pd.to_numeric(df['评分'], errors='coerce') # 将评分字段转换为数值类型,并处理无法转换的值
df = df.dropna(subset=['评分']) # 删除评分字段为缺失值的行 # 绘制评分的直方图
plt.figure(figsize=(10, 6)) # 设置图像大小
plt.hist(df['评分'], bins=20, edgecolor='black', alpha=0.7) # bins参数决定了直方图的条形数量 # 设置图表标题和坐标轴标签
plt.title('酒店评分直方图')
plt.xlabel('评分')
plt.ylabel('频数') # 显示图表
plt.grid(axis='y', alpha=0.75) # 添加网格线
plt.show()
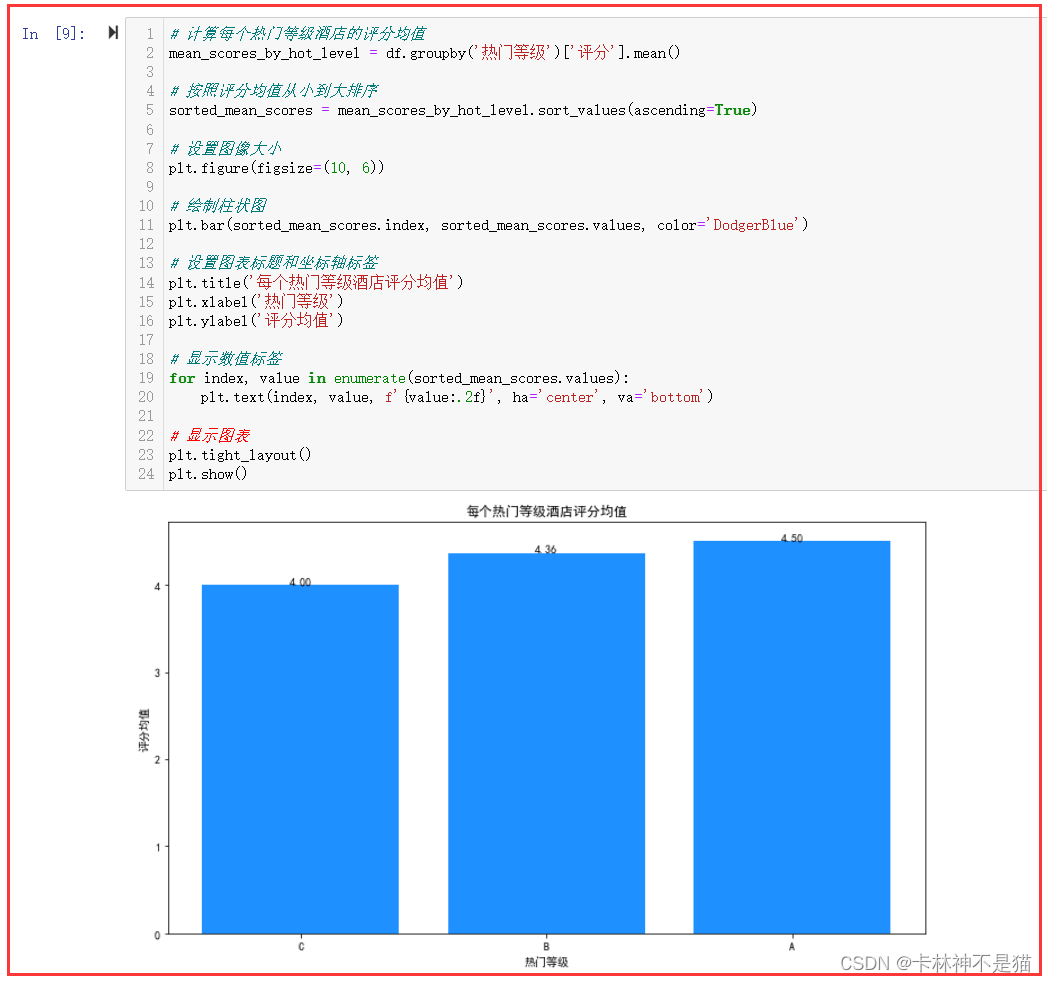
7. 画出每个热门等级酒店评分均值的柱状图。(按照评分均值从小到大排序。)
# 计算每个热门等级酒店的评分均值
mean_scores_by_hot_level = df.groupby('热门等级')['评分'].mean() # 按照评分均值从小到大排序
sorted_mean_scores = mean_scores_by_hot_level.sort_values(ascending=True) # 设置图像大小
plt.figure(figsize=(10, 6)) # 绘制柱状图
plt.bar(sorted_mean_scores.index, sorted_mean_scores.values, color='DodgerBlue') # 设置图表标题和坐标轴标签
plt.title('每个热门等级酒店评分均值')
plt.xlabel('热门等级')
plt.ylabel('评分均值') # 显示数值标签
for index, value in enumerate(sorted_mean_scores.values): plt.text(index, value, f'{value:.2f}', ha='center', va='bottom') # 显示图表
plt.tight_layout()
plt.show()
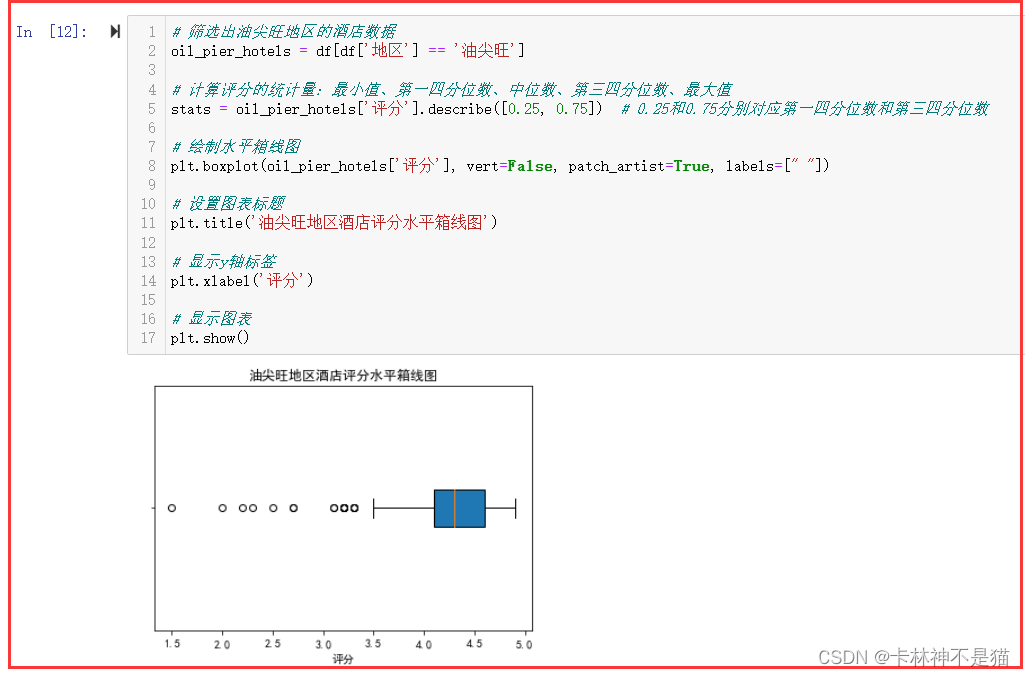
8. 画出油尖旺地区,评分的箱线图。
# 筛选出油尖旺地区的酒店数据
oil_pier_hotels = df[df['地区'] == '油尖旺'] # 计算评分的统计量:最小值、第一四分位数、中位数、第三四分位数、最大值
stats = oil_pier_hotels['评分'].describe([0.25, 0.75]) # 0.25和0.75分别对应第一四分位数和第三四分位数 # 绘制箱线图
plt.boxplot(oil_pier_hotels['评分'], patch_artist=True, labels=['油尖旺地区评分']) # 设置图表标题
plt.title('油尖旺地区酒店评分箱线图') # 显示图表
plt.show()

9. 选出平均价格前5的地区,画出这些地区的评分的箱线图。
from matplotlib.patches import Patch # 计算每个地区的平均价格
avg_prices_by_area = df.groupby('地区')['价格'].mean() # 按照平均价格从高到低排序,并选择前5个地区
top_5_areas = avg_prices_by_area.nlargest(5).index # 初始化一个空列表来存储代理艺术家
proxies = [] # 绘制这些地区的评分箱线图
plt.figure(figsize=(10, 8)) # 对每个地区绘制箱线图
for i, area in enumerate(top_5_areas): area_data = df[df['地区'] == area] plt.boxplot(area_data['评分'].values, positions=[i], patch_artist=True) proxies.append(Patch(color=plt.gca().artists[i].get_facecolor(), label=area)) # 设置图表标题和坐标轴标签
plt.title('平均价格前5地区的酒店评分箱线图')
plt.xlabel('地区')
plt.ylabel('评分')
plt.xticks(range(len(top_5_areas)), top_5_areas) # 设置x轴刻度标签 # 添加图例
plt.legend(handles=proxies, loc='best') # 显示图表
plt.show()

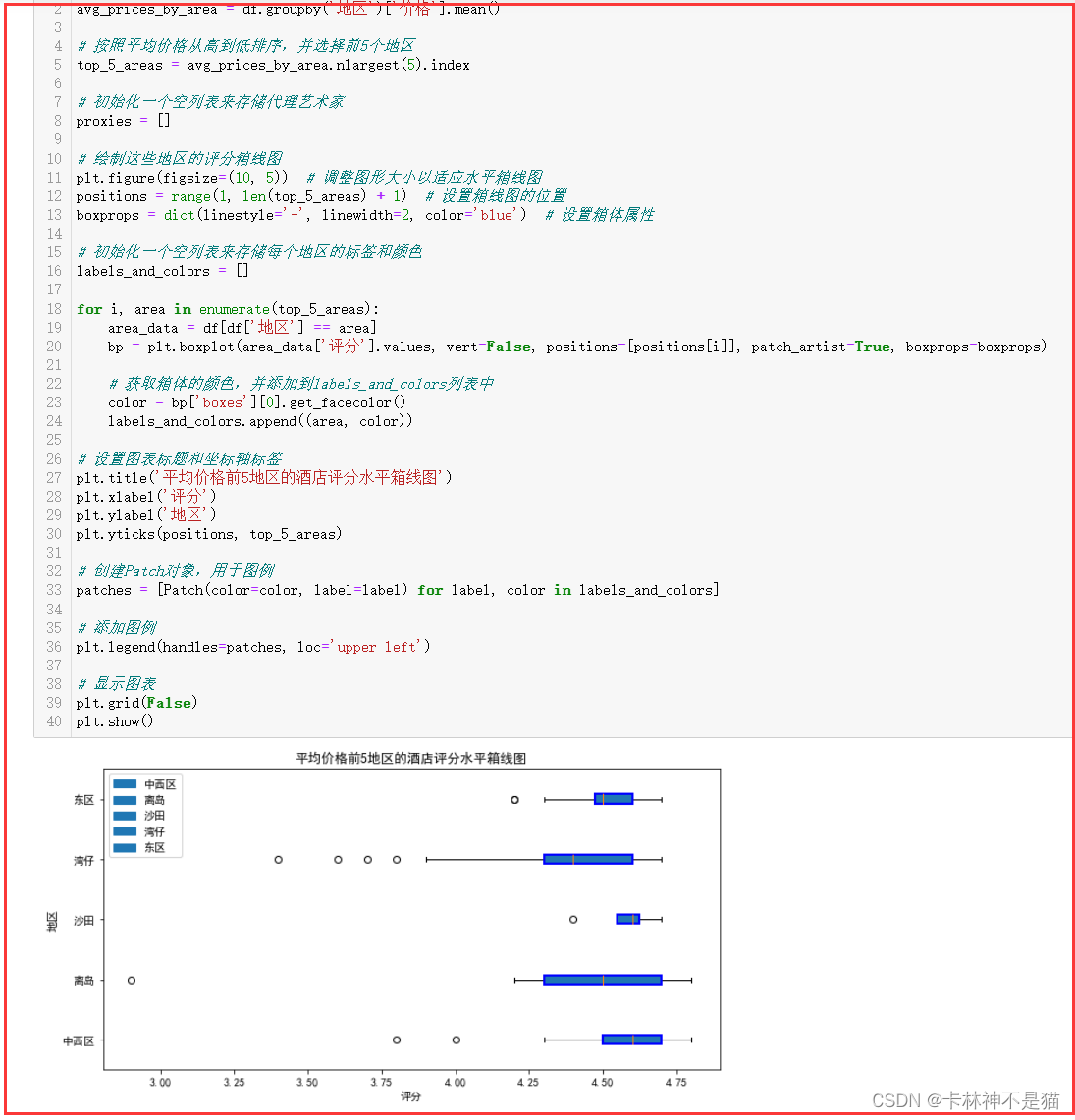
10. 将前面两个题目的图像(箱线图)旋转90度。
# 筛选出油尖旺地区的酒店数据
oil_pier_hotels = df[df['地区'] == '油尖旺'] # 计算评分的统计量:最小值、第一四分位数、中位数、第三四分位数、最大值
stats = oil_pier_hotels['评分'].describe([0.25, 0.75]) # 0.25和0.75分别对应第一四分位数和第三四分位数 # 绘制水平箱线图
plt.boxplot(oil_pier_hotels['评分'], vert=False, patch_artist=True, labels=[" "]) # 设置图表标题
plt.title('油尖旺地区酒店评分水平箱线图') # 显示y轴标签
plt.xlabel('评分') # 显示图表
plt.show()
# 计算每个地区的平均价格
avg_prices_by_area = df.groupby('地区')['价格'].mean() # 按照平均价格从高到低排序,并选择前5个地区
top_5_areas = avg_prices_by_area.nlargest(5).index # 初始化一个空列表来存储代理艺术家
proxies = [] # 绘制这些地区的评分箱线图
plt.figure(figsize=(10, 5)) # 调整图形大小以适应水平箱线图
positions = range(1, len(top_5_areas) + 1) # 设置箱线图的位置
boxprops = dict(linestyle='-', linewidth=2, color='blue') # 设置箱体属性 # 初始化一个空列表来存储每个地区的标签和颜色
labels_and_colors = [] for i, area in enumerate(top_5_areas): area_data = df[df['地区'] == area] bp = plt.boxplot(area_data['评分'].values, vert=False, positions=[positions[i]], patch_artist=True, boxprops=boxprops) # 获取箱体的颜色,并添加到labels_and_colors列表中 color = bp['boxes'][0].get_facecolor() labels_and_colors.append((area, color)) # 设置图表标题和坐标轴标签
plt.title('平均价格前5地区的酒店评分水平箱线图')
plt.xlabel('评分')
plt.ylabel('地区')
plt.yticks(positions, top_5_areas) # 创建Patch对象,用于图例
patches = [Patch(color=color, label=label) for label, color in labels_and_colors] # 添加图例
plt.legend(handles=patches, loc='upper left') # 显示图表
plt.grid(False)
plt.show()
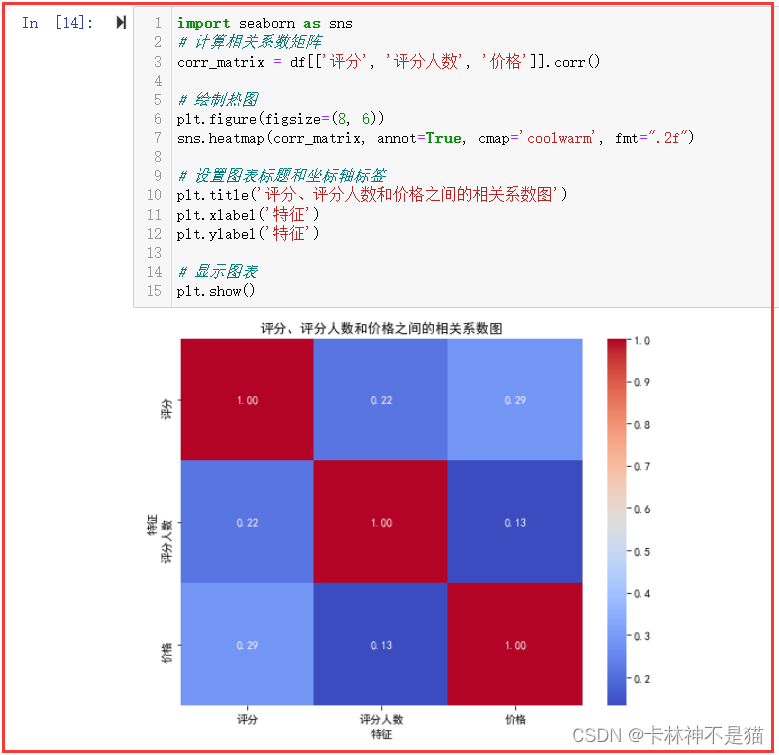
11. 绘制一个评分,评分人数和价格之间的相关系数图
import seaborn as sns
# 计算相关系数矩阵
corr_matrix = df[['评分', '评分人数', '价格']].corr() # 绘制热图
plt.figure(figsize=(8, 6))
sns.heatmap(corr_matrix, annot=True, cmap='coolwarm', fmt=".2f") # 设置图表标题和坐标轴标签
plt.title('评分、评分人数和价格之间的相关系数图')
plt.xlabel('特征')
plt.ylabel('特征') # 显示图表
plt.show()
这篇关于数据可视化(七):Pandas香港酒店数据高级分析,涉及相关系数,协方差,数据离散化,透视表等精美可视化展示的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






