建堆专题

6.1.数据结构-c/c++模拟实现堆上篇(向下,上调整算法,建堆,增删数据)
目录 一.堆(Heap)的基本介绍 二.堆的常用操作(以小根堆为例) 三.实现代码 3.1 堆结构定义 3.2 向下调整算法* 3.3 初始化堆* 3.4 销毁堆 3.4 向上调整算法* 3.5 插入数据 3.6 删除数据 3.7 返回堆顶数据 四.下篇内容 1.堆排序 2.TopK问题 一.堆(Heap)的基本介绍 了解堆之前我们要简

【探索数据结构与算法】向上调整建堆与向下调整建堆的时间复杂度
一.前言 堆排序是一种优于冒泡排序的算法, 那么在进行堆排序之前, 我们需要先创建堆, 那么这个建堆的时间复杂度是多少呢? 二.下调整算法建堆 因为堆是完全二叉树,而满二叉树也是完全二叉树,此处为了简化使用满二叉树来证明(时间复杂度本来看的就是近似值,多几个结点不影响最终结果): 假设高度为h的二叉树, 结点的个数为N, 可以计算出高度h与结点个数之间的关系如下图所示: 向下调

关于堆排序建堆时间复杂度的证明
建堆的过程,看起来外面一层循环O(n),里面是个logn的调整函数,时间复杂度貌似是nlogn的,但是仔细分析,其实质是O(n)的。 证明如下: 首先,对于高度为h的完全二叉树,其第i层的元素个数为2^(i-1),对于堆的每一层,调整的深度都不一样,每层的元素的调整深度小于等于h-i,假设每层调整的深度是h-i,欲构建的堆是个完全二叉树,那么对于每层来说: 最后一层不用调整; 倒数第二层的
数据结构和算法|堆排序系列问题(一)|堆、建堆和Top-K问题
在这里不再描述大顶堆和小顶堆的含义,只剖析原理层面。 主要内容来自:Hello算法 文章目录 1.堆的实现1.1 堆的存储与表示过程1.2 访问堆顶元素1.4元素出堆 2.⭐️建堆2.1 方法一:借助入堆操作实现2.2 ⭐️方法二:通过遍历堆化实现 应用:Top-K问题⭐️方法一:遍历选择方法二:排序⭐️方法三:堆 1.堆的实现 1.1 堆的存储与表示过程 完全二叉树非常

调整法建堆过程的优化
用调整法建堆,并在如下几个方面进行优化:(a)递归函数改成while循环;(b)减少比较次数;(c)减少交换次数; 源代码如下: #include <string>#include <fstream>#include <stdlib.h>#include <iostream>#include <sys/time.h>using namespace std;#

用调整法和插入法建堆的Python实现,不同建堆方式对堆排序性能的影响
建堆的方式大体有两种,一种是插入法,一种是调整法,其中以调整法比较常见。由于他们的建堆的思路不同,所以两种方法建堆结果可能不一样。 插入法建堆是将数组1中的元素逐个插入到数组2中建立一个堆。以小根堆为例,每插入一个关键字就与其父节点的关键字比较大小,如果父节点的关键字较大则交换,然后依次自底地向上调整使之符合小根堆的特性。在某棵已插入根节点的子树中,当插入左节点时
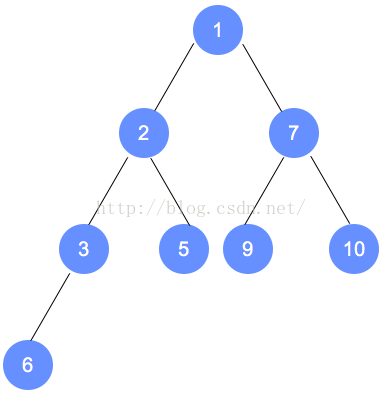
数据结构 小顶堆建堆过程 构建过程
【一】简介 最小堆是一棵完全二叉树,非叶子结点的值不大于左孩子和右孩子的值。本文以图解的方式,说明最小堆的构建、插入、删除的过程。搞懂最小堆的相应知识后,最大堆与此类似。最小堆示例: 【二】最小堆的操作 最小堆的构建: 初始数组为:9,3,7,6,5,1,10,2 按照完全二叉树,将数字依次填入。 填入完成后,从最后一个非叶子结点(本示例为数

堆(最小堆、最大堆、建堆、插入)
堆是一种特殊的数据结构,是一种完全二叉树,分为最大堆(根节点的值大于孩子节点)和最小堆(根节点小于孩子节点) 不失一般性,只讨论最小堆的情况。 1、插入 只需要将节点插在二叉树的最后一个叶子结点位置,然后比较它对它父亲节点的大小,如果大则停止;如果小则交换位置,然后对父亲节点递归该过程直至根节点。复杂度为O(log(n))。 一般来说,插入的位置可以不是最后一个叶子节点,可以
堆排序建堆的时间复杂度
建堆的过程,看起来外面一层循环O(n),里面是个logn的调整函数,时间复杂度貌似是nlogn的,但是仔细分析,其实质是O(n)的。 证明如下: 首先,对于高度为h的完全二叉树,其第i层的元素个数为2^(i-1),对于堆的每一层,调整的深度都不一样,每层的元素的调整深度小于等于h-i,假设每层调整的深度是h-i,欲构建的堆是个完全二叉树,那么对于每层来说: 最后一层不用调整;

建堆的时间复杂度计算
目录 公式及结果 原理解释 公式推导 公式及结果 以最坏情况来计算建堆的时间复杂度,假设该堆为满二叉树,堆高为h。i为第i层,设第i层高度为hi,第i层结点数位ni,堆的复杂度为 i = 1 ,直到 i = h-1 结束。将 1 到 h - 1 的 n1*h1 +..... ni*hi 相加。 t(n) = O

<<数据结构>>向上调整建堆和向下调整建堆的分析(特殊情况,时间复杂度分析,两种建堆方法对比,动图)
今天,我来讲讲建堆算法中使用向上调整和向下调整。 目录 建堆的应用向上调整建堆向下调整建堆向下调整建堆和向上调整建堆的选择 建堆的应用 在数据结构模拟堆中,我们可能会通过输入数组的元素来进行建堆或者在堆排序中,我们也需要建堆,那么建堆就有两种方法,一种从倒数第二层最右侧的父节点开始进行向下调整,直到把所有父节点都向下调整完;另外一种是从最后一个结点开始向上调整

数据结构中的堆--堆的定义、调整堆、建堆、自定义堆
一、堆的定义 1.结构特点 堆(数据结构)和Java语言中提到的堆没有一点关系。 逻辑上:完全二叉树 物理上:数组 堆是一种顺序存储结构(采用数组方式存储),仅仅是利用完全二叉树的顺序结构的特点进行分析。 2.结点下标计算公式(根节点从0开始) 已知二叉树根结点的下标是root,那么它左孩子的下标left=2*root+1,右孩子的下标right=

大顶堆、小顶堆及其建堆过程、堆排序
定义 按照堆的特点可以把堆分为大顶堆和小顶堆。 大顶堆:每个结点的值都大于或等于其左右孩子结点的值; 小顶堆:每个结点的值都小于或等于其左右孩子结点的值。 (堆的这种特性非常的有用,堆常常被当做优先队列使用,因为可以快速的访问到“最重要”的元素) 我们用简单的公式来描述一下堆的定义就是: 大顶堆:arr[i] >= arr[2i+1] && arr[i] >= arr[2i+2]
c 语言 堆的解析(自我理解)!!!堆排序,建堆
1.堆是什么? 首先先看一个图片 小顶堆的意思就是顶 的元素最小,两个子节点的元素要大于父节点。大顶堆同理。 小顶堆就像是一个金字塔。第一层很小,然后后面是依次增大,就像社会人才金字塔图一样。 大顶堆就可以想做,每个人的财富拥有值的金字塔图,上层人的钱很多,而底层的人钱最少。 其次关于堆,其实堆在通常情况下是一个完全二叉树 (只有最底层的节点没有充满的二叉树,全充满的也属于完全二叉树

堆排序(建堆及向下调整)
首先,堆排序顾名思义,它的数据存储的像一个堆一样,那么想一下,像堆的数据类型都有什么? 树形结构! 所以,堆排序的存储就是通过一颗完全二叉树实现的,可以理解成满了,但没完全满 为什么这样说,原因很简单,它的n-1层组成的二叉树必须是满二叉树,但是叶子结点组成的第n层可以不满,但是有一个前提条件 假设根节点编号为1,两个子节点为2,3,那么2和3的子节点空余的顺序必须有序,就是说,4,5,