本文主要是介绍数据结构和算法|堆排序系列问题(一)|堆、建堆和Top-K问题,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
在这里不再描述大顶堆和小顶堆的含义,只剖析原理层面。
主要内容来自:Hello算法
文章目录
- 1.堆的实现
- 1.1 堆的存储与表示过程
- 1.2 访问堆顶元素
- 1.4元素出堆
- 2.⭐️建堆
- 2.1 方法一:借助入堆操作实现
- 2.2 ⭐️方法二:通过遍历堆化实现
- 应用:Top-K问题
- ⭐️方法一:遍历选择
- 方法二:排序
- ⭐️方法三:堆
1.堆的实现
1.1 堆的存储与表示过程
完全二叉树非常适合用数组来进行表示,而堆就是一颗完全二叉树,所以我们可以使用数组来存储堆。也就是说,堆的逻辑结构是一颗完全二叉树,它的物理结构(底层存储)是一个数组。
对于一个给定索引 i i i,其左子树和右子树索引分别为 2 i + 1 2i + 1 2i+1、 2 i + 2 2i + 2 2i+2,其父节点的索引为 ( i − 1 ) / 2 (i-1)/2 (i−1)/2(向下取整)。

封装索引的映射公式:
//获取左子节点的索引
int left(int i) {return 2 * i + 1;
}
//获取右子节点的索引
int right(int i) {return 2 * i + 2;
}
//获取父节点的索引
int parent(int i) {return (i - 1) / 2;
}
1.2 访问堆顶元素
堆顶元素即为二叉树的根结点,也就是列表的首元素 ```cpp //访问堆顶元素 int peek() { return maxHeap[0]; } ``` ## ⭐️1.3元素入堆 该环节非常重要。
对于一个给定元素 val ,
- 将其添加到堆底。添加到堆底后, val 可能大于堆中其他元素,所以我们需要恢复从出啊如结点到根结点的路径上的各个节点,这个操作就是堆化(heapify)
- 从入堆结点开始,从底到顶执行堆化。我们比较插入节点与其父节点的值,如果插入节点更大,则将它们交换。然后继续执行此操作,从底至顶修复堆中的各个节点,直至越过根节点或遇到无须交换的节点时结束。
动态流程可以查看文章:3. 元素入堆
我们应该分析一下入堆的时间复杂度,设节点总数为 n n n,则树的高度为 O ( l o g n ) O(logn) O(logn)。所以堆化操作的循环论述最多为 O ( l o g n ) O(logn) O(logn)
综上,元素入堆操作的时间复杂度为 O ( l o g n ) O(logn) O(logn)
void push(int val) {//添加节点minHeap是一个数组maxHeap.push_back(val);//从底至顶堆化siftUp(size() - 1);
}
//从节点i开始,从底至顶堆化操作
void siftUp(int i) {while (true) {//获取节点 i 的父节点int p = parent(i);//当“越过根节点”或“节点无须修复”时,结束堆化if (p < 0 || maxHeap[i] <= maxHeap[p]) break;//交换两个结点swap(maxHeap[i], maxHeap[p]);//循环向上堆化i = p;}
}
再次强调:元素入堆的时间复杂度为 O ( l o g n ) O(logn) O(logn)
1.4元素出堆
元素出堆和我们一般想的所谓直接直接弹出不同,因为如果直接弹出,那么我想想要修复堆结构变得极其困难。为了尽量减少元素索引的变动,我们这样操作出堆:
- 交换堆顶元素与堆底元素(交换根结点与最右叶子结点)。
- 交换完成后,将堆底从列表中删除(由于已经交换,因此实际上删除的是原来的堆顶元素)。
- 从根结点开始,从顶至底执行堆化操作(下溯)。
“从顶至底堆化”的操作方向与“从底至顶堆化”相反,我们将根节点的值与其两个子节点的值进行比较,将最大的子节点与根节点交换。然后循环执行此操作,直到越过叶节点或遇到无须交换的节点时结束。
具体流程可以看4. 堆顶元素出堆,流程极为详细。
时间复杂度分析,从顶至底的堆化,很明显时间复杂度仍然是O(logn)。
/* 元素出堆 */
void pop() {/* 从节点 i 开始,从顶至底堆化 */
void siftDown(int i) {
2.⭐️建堆
给定你任意一个列表,我们想要使用其所有元素来构建一个堆,这个过程被称为“建堆操作”。
2.1 方法一:借助入堆操作实现
首先我们维护一个空堆,然后依次对每个元素执行“入堆操作”,即现将元素添加至堆的尾部,然后“从底至顶”堆化即可。
至此我们可以维护一个真正的堆了,而且肯定是根结点最先被构建出来。
每当一个元素入堆,堆的长度就加一。由于节点是从顶到底依次被添加进二叉树的,因此堆是“自上而下”构建的。
设元素数量为 n n n,每个元素的入堆操作使用 O ( l o g n ) O(logn) O(logn)时间,所以整个建堆方法的时间复杂度为:
O ( n l o g n ) O(nlogn) O(nlogn)
2.2 ⭐️方法二:通过遍历堆化实现
这是一个更高效的建堆方法,共分为两步:
- 将列表所有元素原封不动添加到堆中,此时堆的性质尚未得到满足;
- 倒序遍历堆(层序遍历的倒序),依次对每个非叶节点执行“从顶至底堆化”
每当堆化一个结点后,以该节点为根结点的子树就形成了一个合法的子堆。
而由于是倒序遍历,因此堆是“自下而上”构建的。(之所以选择倒序遍历,是因为这样能够保证当前节点之下的子树已经是合法的子堆,这样堆化当前节点才是有效的。)
并且由于叶子结点没有子结点,因此他们天然就是合法的子堆,无须堆化。
/* 构造方法,根据输入列表建堆 */
MaxHeap(vector<int> nums) {//将列表元素原封不动添加进堆maxHeap = nums;//堆化出也节点以外的其他所有节点for (int i = parent(size() - 1); i >= 0; i--) {siftDown(i);}
}
时间复杂度分析:
- 假设完全二叉树的节点数量为 n n n,则叶节点数量为 ( n + 1 ) / 2 (n+1)/2 (n+1)/2。因此需要堆化的节点数量为 ( n − 1 ) / 2 (n-1)/2 (n−1)/2
- 从顶至底堆化的过程中,每个节点最多堆化到叶节点,因此最大迭代次数为二叉树高度 l o g n logn logn
将上述两者相乘,可得到建堆过程的时间复杂度为 O ( n l o g n ) O(nlogn) O(nlogn)。
但这只是一种粗略的估算,严格来说,我们应该进行详细的计算,基本的思想就是高度较高的节点堆化需要的迭代次数较多,较低节点堆化的迭代次数较少。
我们需要对各层的“节点数量X结点高度”求和,得到所有节点的堆化迭代次数的总和。
最终的结果是 O ( n ) O(n) O(n)
应用:Top-K问题
Question:
给定一个长度为n的无序数组nums,请返回数组中最大的k个元素。
⭐️方法一:遍历选择
暴力求解!我们进行 k 轮遍历,分别在每轮中提取第 1 、 2 、 . . . 、 k 1、2、...、k 1、2、...、k大的元素,时间复杂度为 O ( n k ) O(nk) O(nk)。
当然了,此方法只适用于 k < < n k << n k<<n 的情况,因为当 k k k与 n n n比较接近时,其时间复杂度趋向于 O ( n 2 ) O(n^2) O(n2),非常耗时:
当 k = n k=n k=n 时,我们可以得到完整的有序序列,此时等价于“选择排序”算法。

算法步骤如下:
- 初始化:指定一个变量来记录当前需要考虑的数组的结尾位置。
- 重复寻找最大值:遍历当前未处理的数组部分,找到最大元素。
- 交换元素: 将找到的最大元素与当前考虑的数组的最后一个元素交换。
- 调整考虑范围: 减少考虑数组范围的长度。
- 重复: 重复以上步骤 𝑘。
vector<int> topKsearch(vector<int>& nums, int k) {int n = nums.size();int end = n - 1 //初始化结束索引for (int i = 0; i < k; i++) {int maxIndex = 0;for (int j = 0; j <= end; j++) {if (nums[j] > nums[maxIndex]) maxIndex = j;} //交换最大元素到当前考虑的数组的末尾swap(nums[maxIndex], nums[end]);end--;}
}
方法二:排序
这个思路也比较简单,先对数组进行排序,然后返回最右边的k个 元素,时间复杂度为: O ( n l o g n ) O(nlogn) O(nlogn)
显然,该方法“超额”完成任务了,我们其实只需要找出最大的k个元素即可。
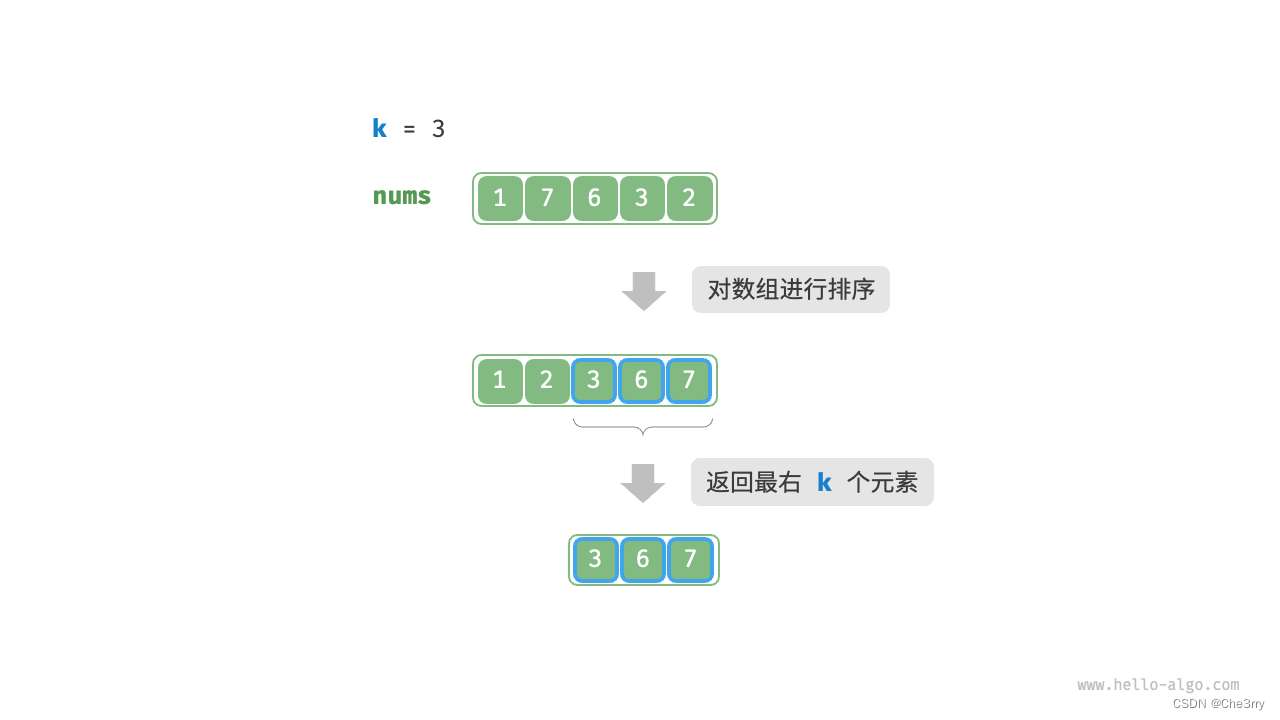
vector<int> topKsort(vector<int>& nums, int k) {sort(nums.begin(), nums.end(), greater<int>()); // 降序排序vector<int> result;for (int i = 0; i < k; i++) {result.push_back(nums[i]);}return result;
}
⭐️方法三:堆
堆天生就适合解决这样的Top-K问题。
- 初始化一个小顶堆,其顶堆元素最小;
- 现将数组的前 k k k个元素依次入堆,也就是说我们只维护大小为 k k k的堆;
- 从第 k + 1 k+1 k+1个元素开始,如果当前元素大于堆顶元素,则将堆顶元素出堆,并将当前元素入堆。
- 遍历整个nums后,堆中保存的就是最大的k个元素。
具体的实验流程可以看《Hello World》文章:方法三:堆
时间复杂度分析:
我们一共执行n次入堆和出堆,堆的最大长度为 k k k,所以时间复杂度为 O ( n l o g k ) O(nlogk) O(nlogk)。
该方法效率极高,当 k k k较小时,时间复杂度趋向于 O ( n l o g k ) O(nlogk) O(nlogk);当 k k k较大时,时间复杂度也不会超过 O ( n l o g n ) O(nlogn) O(nlogn)
此外,该方法适用于动态数据流的使用场景。在不断加入数据时,我们可以持续维护堆内的元素,从而实现最大的 k k k个元素的动态更新。
代码如下:
vector<int> topKHeap(vector<int> &nums, int k) {//初始化一个最小堆priority_queue<int, vector<int>, gereater<int>> heap;//先将前k个元素入堆for (int i = 0; i < k; i++) {heap.push(nums[i]);}//遍历整个数组,维护大小为k的小顶堆for (int i = k; i < nums.size(); i++) {//若当前元素大于堆顶元素,则将堆顶元素出堆、当前元素入堆if (nums[i] > heap.top()) {heap.pop();heap.push(nums[i]);}}//将堆中的元素收集到结果像两种vector<int> result;while (!heap.empty()) {result.push_back(heap.top());heap.pop();}return result;
}
这篇关于数据结构和算法|堆排序系列问题(一)|堆、建堆和Top-K问题的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







