堆排序专题

在Java中实现堆排序的步骤详解
《在Java中实现堆排序的步骤详解》堆排序是一种基于堆数据结构的排序算法,堆是一种特殊的完全二叉树,堆排序利用堆的性质通过一系列操作将数组元素按升序或降序排列,本文给大家介绍了如何在Java中实现堆排... 目录引言一、堆排序的基本原理二、堆排序的实现步骤三、堆排序的时间复杂度和空间复杂度四、堆排序的工作流

6.1.数据结构-c/c++堆详解下篇(堆排序,TopK问题)
上篇:6.1.数据结构-c/c++模拟实现堆上篇(向下,上调整算法,建堆,增删数据)-CSDN博客 本章重点 1.使用堆来完成堆排序 2.使用堆解决TopK问题 目录 一.堆排序 1.1 思路 1.2 代码 1.3 简单测试 二.TopK问题 2.1 思路(求最小): 2.2 C语言代码(手写堆) 2.3 C++代码(使用优先级队列 priority_queue)

6.2排序——选择排序与堆排序
本篇博客梳理选择排序,包括直接选择排序与堆排序 排序全部默认排成升序 一、直接选择排序 1.算法思想 每次遍历都选出最小的和最大的,放到序列最前面/最后面 2.具体操作 (1)单趟 每次遍历都选出最小的和最大的。遍历时,遇到更小的,更新min,遇到更大的,更新max (2)单趟变整体 每趟遍历完之后,begin++,end– 程序结构如下 while(begin<end){//

堆排序算法剖析(基于Java)
什么是堆结构? 堆排序的关键是构造堆结构,首先谈一下堆结构的定义,堆结构是一种树结构,准确地说是一个完全二叉树,完全二叉树的定义在这里就不多赘述了,百度知道。 按照排序顺序,堆结构可以分为两种: 1.按照从小到大的顺序排序,要求非叶节点的数据要大于或等于其左、右子节点的数据。 2.按照从大到小的顺序排序,要求非叶节点的数据要小于或等于其左、右子节点的数据。 本文以从小到大的顺序为例进行介

排序算法(动图详细讲解)(直接插入排序,希尔排序,堆排序,冒泡排序)
前言: 排序的方式有很多种,不同的排序思想是不一样的。 但是排序的时间复杂度和空间复杂度也都有区别。 例如: 最简单的冒泡排序,时间复杂度为O(N) 对排序的时间复杂度为O(N*logN)。 接下来就来仔细分析每种排序的思路,并写出代码。 插入排序: 基本思想: 直接插入排序是一种简

堆的建立、插入、出堆、堆化、topk问题、堆排序(C语言实现)
堆的建立、插入、出堆、堆化、topk问题、堆排序 使用数组来存储堆 堆顶为序号0,堆底为序号 size - 1 假设树为完全二叉树,当前节点和双亲节点的关系可以通过公式表达 // 小顶堆: 对 heaptifyUp 和 heaptifyDown 函数的逻辑进行一些调整。void initHeap(float **arr, int *size) { *arr = (float *)malloc

内部排序之三:堆排序
前言 堆排序、快速排序、归并排序(下篇会写这两种排序算法)的平均时间复杂度都为O(n*logn)。要弄清楚堆排序,就要先了解下二叉堆这种数据结构。本文不打算完全讲述二叉堆的所有操作,而是着重讲述堆排序中要用到的操作。比如我们建堆的时候可以采用堆的插入操作(将元素插入到适当的位置,使新的序列仍符合堆的定义)将元素一个一个地插入到堆中,但其实我们完全没必要这么做,我们有执行操作更少的方法,
算法-排序算法:堆排序(HeapSort )【O(nlogn)】
MyArray.java /*** 数组** @author* @version 2018/8/4*/public class MyArray<E> {private E[] arr;private int size;public MyArray(int capacity){arr = (E[])new Object[capacity];size = 0;}public MyArray() {


排序算法之堆排序详细解读(附带Java代码解读)
堆排序(Heap Sort)是一种基于比较的排序算法,它利用堆数据结构来排序元素。堆是一种特殊的完全二叉树,堆排序的基本思想是将数组构建成一个最大堆(或最小堆),然后通过交换根节点和堆的最后一个元素,将最大(或最小)元素移到数组的末尾。接着,调整堆,使其重新满足堆的性质,然后重复这一过程直到排序完成。 算法思想 构建最大堆:将无序数组构建成一个最大堆。最大堆的特性是每个节点的值都大于或等于其子

堆排序-TOP-K问题(C语言数据结构)
前言: 学习堆及堆排序,认识到堆的内部原理,这时候就应该运用在实体场景。 例如:全校有2000人,如何帅选出成绩最好的前10名。 帅选出全球前100所最具潜力的公司等等。 TOP-K问题: 如何创造出多个数据? 在32位机器上整型占4个字节,电脑一般自带内存是8GB或者16GB,也就是最多存储

【数据结构】二叉树的顺序结构,详细介绍堆以及堆的实现,堆排序
目录 1. 二叉树的顺序结构 2. 堆的概念及结构 3. 堆的实现 3.1 堆的结构 3.2 堆的初始化 3.3 堆的插入 3.4 堆的删除 3.5 获取堆顶数据 3.6 堆的判空 3.7 堆的数据个数 3.8 堆的销毁 4. 堆的应用 4.1 堆排序 4.1.1 向下调整建堆的时间复杂度 4.1.2 向上调整建堆的时间复杂度 4.2 TOP-K问题 5.

【算法】二叉树(满二叉树和完全二叉树)、堆(堆的向下调整)、堆排序、堆的内置模块heapq
1 二叉树 1.1 满二叉树和完全二叉树 1.2 堆的向下调整 2 堆排序 3 堆的内置模块 1 二叉树 二叉树是一种树形数据结构,其中每个节点最多有两个子节点,分别称为左子节点和右子节点。二叉树的常见类型包括:1. **普通二叉树**:任意一种二叉树,没有特定的性质约束。2. **完全二叉树**:除了最后一层,其他层的节点都是满的,且最后一层的节点尽可能向左排列。3. **满二叉树

选择排序(直接选择排序和堆排序)
一、直接选择排序 1.基本思想 每一次从待排序的数据元素中选出最小(或最大)的一个元素,存放在序列的起始位置,直到全部待排序的数据元素排完。 2.动图展示 3.思路讲解 ①在元素集合array[i]—array[n-1]中选择关键码最大(小)的数据元素。 ②若它不是这组元素中的最后一个(第一个)元素,则将它与这组元素中的最后一个(第一个)元素交换。 ③在剩余的array[i]—a
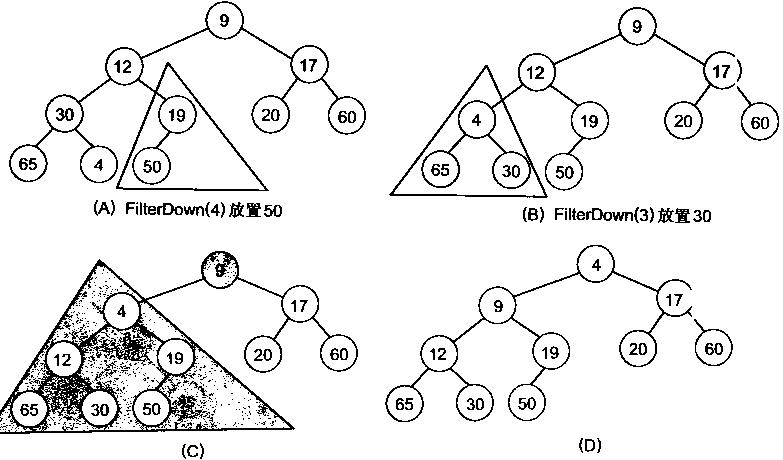


【数据结构】关于冒泡排序,选择排序,插入排序,希尔排序,堆排序你到底了解多少???(超详解)
前言: 🌟🌟Hello家人们,这期讲解排序算法的原理,希望你能帮到屏幕前的你。 🌈上期博客在这里:http://t.csdnimg.cn/I1Ssq 🌈感兴趣的小伙伴看一看小编主页:GGBondlctrl-CSDN博客 目录 📚️1.排序的概念和运用 1.1排序的概念 1.2排序的运用 1.3常见的排序算法 📚️2.常见排序算法的实现 2.1插入排序 2.2
常见的8种排序(含代码):插入排序、冒泡排序、希尔排序、快速排序、简单选择排序、归并排序、堆排序、基数排序
时间复杂度O(n^2) 1、插入排序 (Insertion Sort) 从第一个元素开始,该元素可以认为已经被排序;取出下一个元素,在已经排序的元素序列中从后向前扫描;如果该元素(已排序)大于新元素,将该元素移到下一位置;重复步骤,直到找到已排序的元素小于或者等于新元素的位置;将新元素插入到该位置后。 void insertionSort(int arr[], int n)
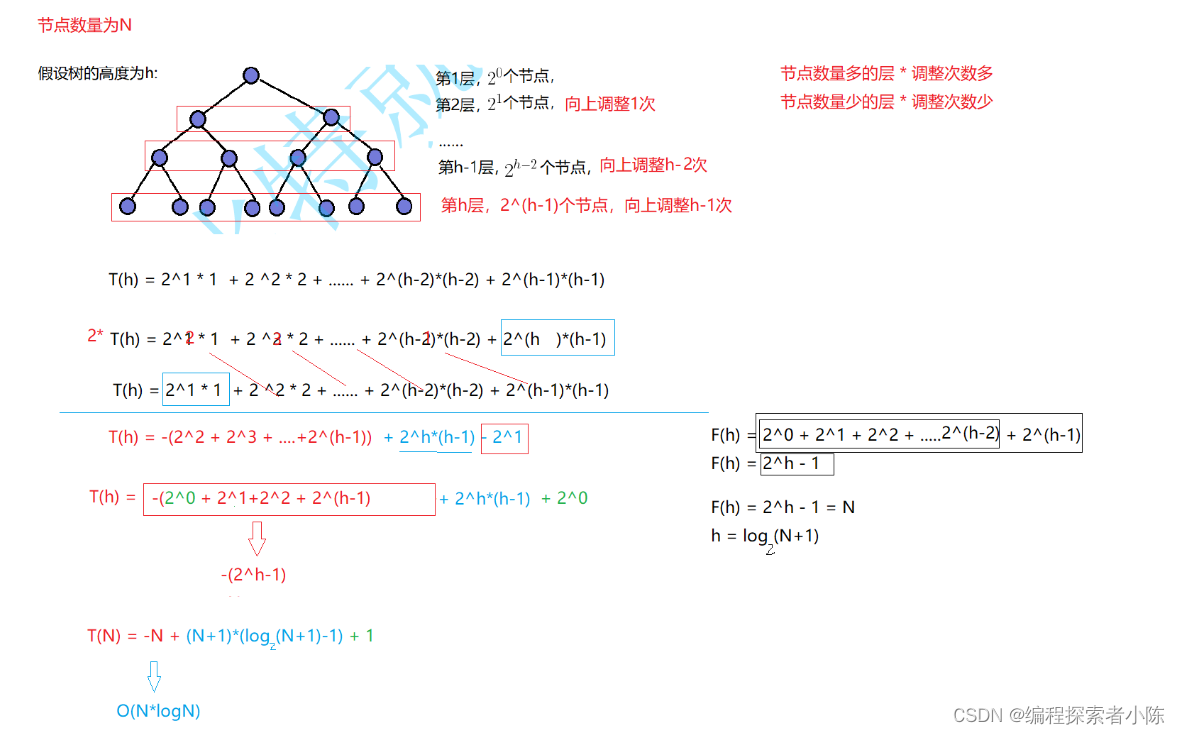
【数据结构】堆的实现和堆排序--TOP-K问题
前言: 堆是一种特殊的树形数据结构,常用于实现优先队列和堆排序。它基于完全二叉树,通常用数组表示。主要操作包括插入(通过上滤维护堆性质)和删除(通常删除堆顶元素,通过下滤恢复堆性质)。 堆排序是一种基于堆的排序算法。它首先将待排序序列构造成一个堆,然后不断将堆顶元素与末尾元素交换并重新调整堆,直至整个序列有序。堆排序的时间复杂度为O(nlogn),空间复杂度为O(1)。 在信息过载的时代,如