top专题

PostgreSQL 17即将发布,新功能Top 3
按照计划,PostgreSQL 17 即将在 2024 年 9 月 26 日发布,目前已经发布了第一个 RC 版本,新版本的功能增强可以参考 Release Notes。 本文给大家分享其中 3 个重大的新增功能。 MERGE 语句增强 MERGE 语句是 PostgreSQL 15 增加的一个新功能,它可以在单个语句中实现 INSERT、UPDATE 以及 DELETE 操作,非常适合数据

AIGC与数据分析融合,引领商业智能新变革(TOP企业实践)
AIGC与数据分析融合,引领商业智能新变革(TOP企业实践) 前言AIGC与数据分析融合 前言 在当今数字化时代,数据已成为企业发展的核心资产,而如何从海量数据中挖掘出有价值的信息,成为了企业面临的重要挑战。随着人工智能技术的飞速发展,AIGC(人工智能生成内容)与数据分析的融合为企业提供了新的解决方案。 阿里巴巴作为全球领先的科技公司,一直致力于探索和应用前沿技术,以提升企业

linux top命令介绍以及使用
文章目录 介绍 `top` 命令1. `top` 的基本功能2. 如何启动 `top`3. `top` 的输出解释系统概况任务和 CPU 使用情况内存和交换空间进程信息 4. 常用操作 总结查看逻辑CPU的个数查看系统运行时间 介绍 top 命令 top 是一个在类 Unix 系统中广泛使用的命令行工具,用于实时显示系统的资源使用情况。它提供了有关 CPU、内存、进程等的详细
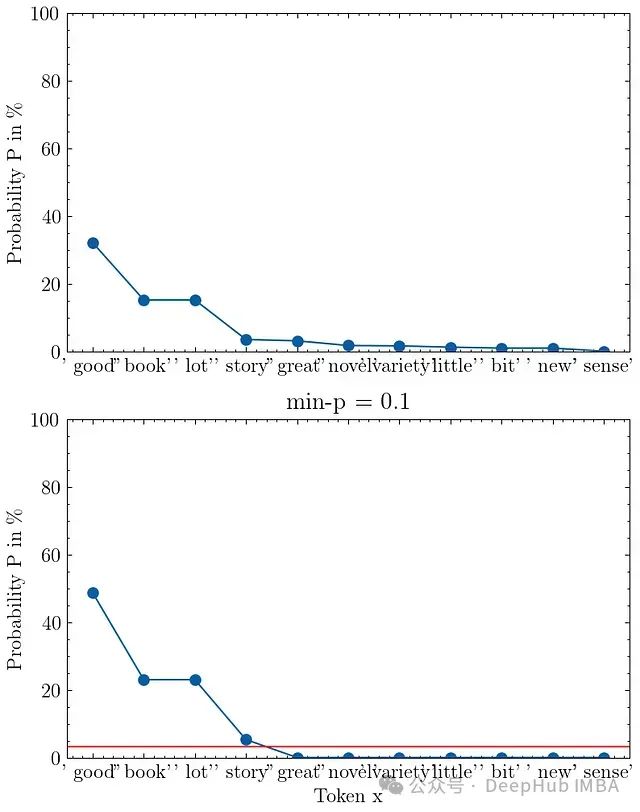
优化采样参数提升大语言模型响应质量:深入分析温度、top_p、top_k和min_p的随机解码策略
当向大语言模型(LLM)提出查询时,模型会为其词汇表中的每个可能标记输出概率值。从这个概率分布中采样一个标记后,我们可以将该标记附加到输入提示中,使LLM能够继续输出下一个标记的概率。这个采样过程可以通过诸如 temperature 和 top_p 等参数进行精确控制。但是你是否曾深入思考过temperature和top_p参数的具体作用? 本文将详细解析并可视化定义LLM输出行为的
[LeetCode] 692. Top K Frequent Words
题:https://leetcode.com/problems/top-k-frequent-words/ 题目大意 对于 string[] words,输出 出现频率前k高的 word,顺序 为 word 出现的频率 由高到低 ,频率相同的 word 按 字符排序。 思路 其实是对words中的所有word进行一个排序。 排序有两个规则: 1.word 在 words中出现的次数。 2.

系统设计:Top K Problem (Heavy Hitters)
System Design Interview - Top K Problem (Heavy Hitters) https://www.youtube.com/watch?v=kx-XDoPjoHw&t=1068s
【高校科研前沿】三峡大学黄进副教授等人在环境科学Top期刊JCP发文:人类活动如何在气候变化下影响和降低生态敏感性:以中国长江经济带为例
文章简介 论文名称:How human activities affect and reduce ecological sensitivity under climate change: Case study of the Yangtze River Economic Belt, China(人类活动如何在气候变化下影响和降低生态敏感性:以中国长江经济带为例) 第一作者及单位
Js中window.parent ,window.top,window.self详解
在应用有frameset或者iframe的页面时,parent是父窗口,top是最顶级父窗口(有的窗口中套了好几层frameset或者iframe),self是当前窗口, opener是用open方法打开当前窗口的那个窗口。 window.self 功能:是对当前窗口自身的引用。它和window属性是等价的。 语法:window.self 注:window、self、windo

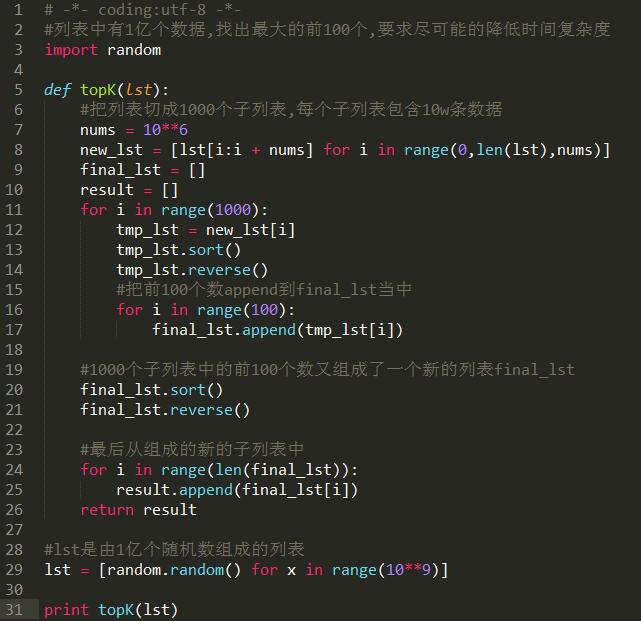
海量数据取top K问题
一个列表中有1亿个数据,需要取出其中最大的前100个数据,如何尽可能的降低时间复杂度? 最容易想到的方法是先对这1亿个数据排序,然后取出最大的100个数据,这样的话时间复杂度就是O(nlogn),显然方法不合适。 可以考虑的方法如下: 1.把这个列表截取成1000个子列表; 2.然后分别找出这1000个子列表中的最大的100个数据; 3.把这1000个子列表中的100个数据全部放到一个新

微派(V-TOP)第五届企业微信营销培训取得圆满成功
12月19日电通东派成功举办了第五届微派(V-TOP)企业微信营销培训,这是2013年最后一次培训,随着微信营销的不断成长,企业主们热情高涨,到会的企业代表一届比一届多,此次《企业微信营销实战演练》培训会取得圆满成功。 培训现场 会后产品演示 培训会后,现场的企业主和嘉宾获邀在现场进行了新版本系统新增功能的试用体验!对新版本的功能和体验都给予了极高的评价,很

微派(V-TOP)教你为自己的微信账号加把安全锁
任何精彩的在线生活都需要一个安全的网络环境支撑,微信不仅将腾讯体系自有安全保障体系移到微信端,还在原基础上完善了保护机制,针对微信自配了独有的帐号保护体系。下面微派将教大家如何为自己的微信账号加把锁。 绑定手机,启用帐号保护 想要安全使用微信,建议开启“帐号保护”,将微信帐号与本人手机号进行绑定。 1.在微信“我”的栏目里进入“个人信息”,点击“我的帐号”; 2.在“手机号”一

问题解决:除非另外还指定了 TOP 或 FOR XML,否则,ORDER BY 子句在视图、内联函数、派生表、子查询和公用表表达式中无效
文章目录 问题场景问题环境问题原因解决方案结果总结随缘求赞 问题场景 因为项目需要,需要在公共框架里面引入sqlserver方言类。而在实现sqlserver方言类之后,调用方言类的方法的时候,发现一个错误 错误提示如下: >[错误] 脚本行:1-10 --------------------------------------Id 1033, Level 15, State

升咖!IEEE系列-2区TOP“水刊”,国人主编,又严又快,毕业就看这篇!
本期解析的是一本来自IEEE旗下关于地球科学领域的期刊,该刊在去年成功由中科院3区晋升为中科院2区TOP刊,主编为中国地质大学的李军教授,可以说对国人很友好! 该刊论述了地球观测和遥感中日益增长的应用领域,并为 IEEE 地球科学和遥感学会正在主办的迅速扩大的特刊提供了一个场所。 《IEEE Journal of Selected Topics in Applied Ear

堆排序-TOP-K问题(C语言数据结构)
前言: 学习堆及堆排序,认识到堆的内部原理,这时候就应该运用在实体场景。 例如:全校有2000人,如何帅选出成绩最好的前10名。 帅选出全球前100所最具潜力的公司等等。 TOP-K问题: 如何创造出多个数据? 在32位机器上整型占4个字节,电脑一般自带内存是8GB或者16GB,也就是最多存储

这个TOP 100 AI应用榜单,包含了所有你需要的使用场景(一)
大家好,我是木易,一个持续关注AI领域的互联网技术产品经理,国内Top2本科,美国Top10 CS研究生,MBA。我坚信AI是普通人变强的“外挂”,专注于分享AI全维度知识,包括但不限于AI科普,AI工具测评,AI效率提升,AI行业洞察。关注我,AI之路不迷路,2024我们一起变强。 第一部分:TOP 50 AI Web端应用 1. ChatGPT 所属公司:OpenAI主要功

python定时器爬取豆瓣音乐Top榜歌名
python定时器爬取豆瓣音乐Top榜歌名 作者:vpoet 日期:大约在夏季 注:这些小demo都是前段时间为了学python写的,现在贴出来纯粹是为了和大家分享一下 #coding=utf-8import urllib import urllib2 import re import time def SaveTop20Music(currtime):r

Top Level Meeting
NLP: ACL EMNLP NAA CV CVPR ECCV ICCV Machine learning and data mining ICML KDD NIPS AI AAAI IJCAI
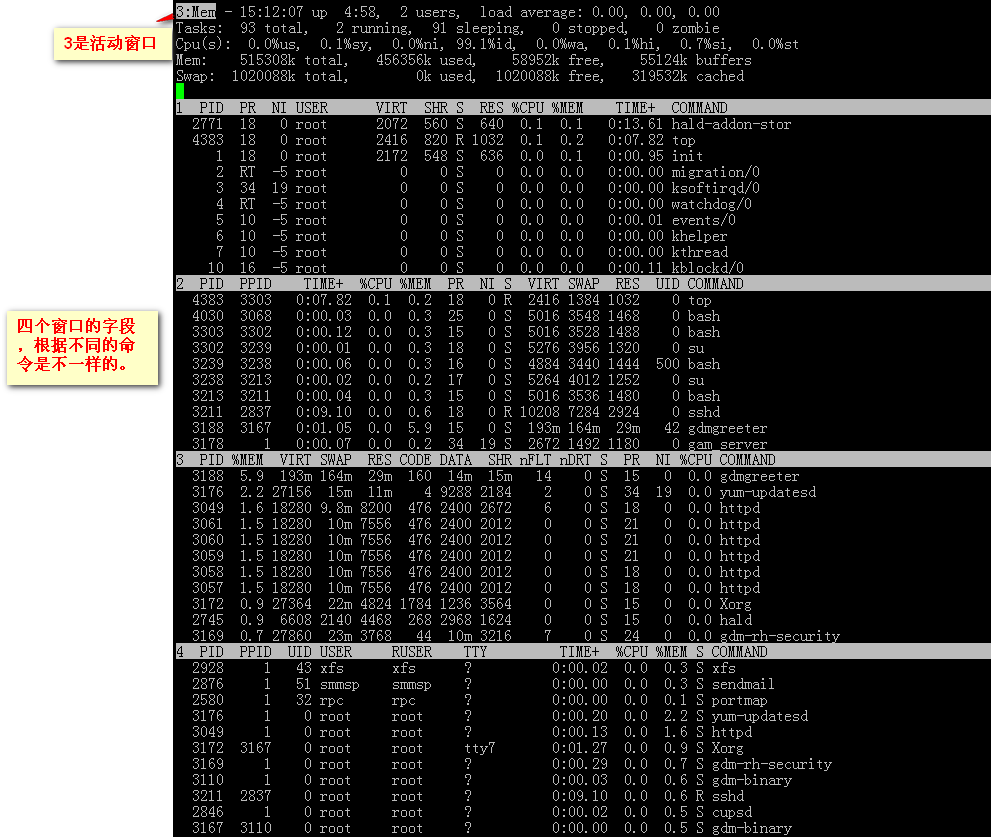
linux命令---top
1. 进程信息区的一些说明: 详细的说明: 序号 列名 含义 a PID 进程id b PPID 父进程id c RUSER Real user name d UID 进程所有者的用户id e USER 进程所有者的用户名 f GROUP 进程所有者的组名 g TTY 启动进程的终端名。不是从终端启动的进程则显示为 ? h PR 优先级 i NI nice值。负值表示

盒模型使用margin相关技巧及解决margin-top塌陷问题
仅供学习,转载请注明出处 margin相关技巧 1、设置元素水平居中: margin:x auto; 2、margin负值让元素位移及边框合并 练习 1、制作一个600*100的盒子,边框1像素黑色,距离浏览器顶部100px,水平居中。 2、制作下面的菜单效果: 实现代码如下: <!DOCTYPE html><html><head><title></ti

算法10—海量数据处理之top k算法
第一部分:Top K 算法详解 问题描述 百度面试题: 搜索引擎会通过日志文件把用户每次检索使用的所有检索串都记录下来,每个查询串的长度为1-255字节。 假设目前有一千万个记录(这些查询串的重复度比较高,虽然总数是1千万,但如果除去重复后,不超过3百万个。一个查询串的重复度越高,说明查询它的用户越多,也就是越热门。),请你统计最热门的10个查询串,要求使用的内存不能超过1G。
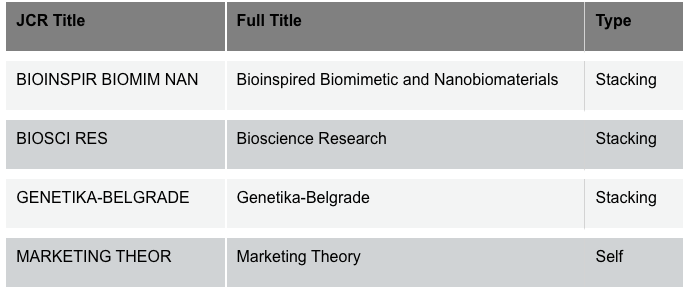
警惕!最新17本期刊(含2本Top)被“镇压”,无影响因子无分区,这是被踢了吗?
本周投稿推荐 SSCI • 中科院2区,6.0-7.0(录用友好) EI • 各领域沾边均可(2天录用) CNKI • 7天录用-检索(急录友好) SCI&EI • 4区生物医学类,0.5-1.0(录用率99%) • 1区工程类,6.0-7.0(进展超顺) • IEEE(TOP),7.5-8.0(实力强刊) 本期解析 1、2023JCR于昨天已经正式发布,其中有17本期

【Linux 杂记】TOP命令
top命令用于动态显示系统中正在运行的进程的详细信息,以及系统的整体资源使用情况。以下是其主要输出解释: Header 表头信息: top:当前时间和运行时间。Tasks:进程统计信息,如总进程数、运行中、睡眠中等。CPU(s):CPU使用情况,包括总体利用率和每个CPU核心的使用率。Mem:内存使用情况,包括总内存、已使用、空闲、缓存等。Swap:交换空间使用情况,类似free命令的输出。

DS:堆的应用——两种算法和TOP-K问题
欢迎来到Harper.Lee的学习世界!博主主页传送门:Harper.Lee的博客主页想要一起进步的uu可以来后台找我哦! 一、堆的排序 1.1 向上调整——建小堆 1.1.1 代码实现 //时间复杂度:O(N*logN)//空间复杂度:O(logN)for (int i = 1; i < n; i++){AdjustUp(a, i);} 1.1.2 复杂度分析 1.

10亿个数中找出最大的10000个数之top K问题
方法一、先拿10000个数建堆,然后一次添加剩余元素,如果大于堆顶的数(10000中最小的),将这个数替换堆顶,并调整结构使之仍然是一个最小堆,这样,遍历完后,堆中的10000个数就是所需的最大的10000个。建堆时间复杂度是O(mlogm),算法的时间复杂度为O(nmlogm)(n为10亿,m为10000)。 方法二(优化的方法):可以把所有10亿个数据分组存放,比如分别放