本文主要是介绍优化采样参数提升大语言模型响应质量:深入分析温度、top_p、top_k和min_p的随机解码策略,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
当向大语言模型(LLM)提出查询时,模型会为其词汇表中的每个可能标记输出概率值。从这个概率分布中采样一个标记后,我们可以将该标记附加到输入提示中,使LLM能够继续输出下一个标记的概率。这个采样过程可以通过诸如
temperature
和
top_p
等参数进行精确控制。但是你是否曾深入思考过temperature和top_p参数的具体作用?
本文将详细解析并可视化定义LLM输出行为的采样策略。通过深入理解这些参数的作用机制并根据具体应用场景进行调优,可以显著提升LLM生成输出的质量。
本文的介绍可以采用VLLM作为推理引擎,并使用微软最新发布的Phi-3.5-mini-instruct模型,结合AWQ量化技术,可以在配备NVIDIA GeForce RTX 2060 GPU的笔记本电脑中运行。

对数概率采样原理解析
LLM解码理论基础
LLM在有限的词汇表
V
上进行训练,该词汇表包含模型可识别和输出的所有可能标记
x
。一个标记可以是单词、字符或介于两者之间的任何语言单位。
LLM接收一系列标记
**x** = (x_1, x_2, x_3, ..., x_n)
作为输入提示,其中每个
x
都是
_V_
中的元素。
随后LLM基于输入提示输出下一个标记的概率分布
P
。从数学角度,这可表示为
P(x_t | x_1, x_2, x_3, ..., x_t-1)
。从这个分布中选择哪个标记是由我们决定的。在此过程中可以选择不同的采样策略和采样参数。

采样本质上是一种概率选择过程。选定下一个标记将其附加到输入提示中并重复这个循环。在LLM领域,这些概率分布通常用对数概率表示,称为logprobs。
如下图所示,对数函数在0到1之间的值域内恒为负。

上图为三种常用底数的对数函数图。
这就解释了为什么logprobs是负值。接近零的logprob对应极高的概率(接近100%),而绝对值较大的负logprob则表示接近0的概率。
使用OpenAI Python SDK获取Logprobs
以下是一个使用官方OpenAI Python客户端进行文本补全的Python脚本。通过设置这些参数,模型将尝试基于输入提示预测下一个标记。
fromopenaiimportOpenAIclient=OpenAI()completion=client.completions.create(model="jester6136/Phi-3.5-mini-instruct-awq",prompt="The quick brown fox jumps over the",logprobs=10,temperature=1.0,top_p=1.0,max_tokens=1)
下面展示了给定句子的标记概率分布。模型选择了
tokens=[' lazy']
作为下一个标记。我们还可以在
top_logprobs
列表中观察到前10个logprobs。
logprobs=completion.choices[0].logprobsprint(logsprobs)>>Logprobs(text_offset=[0],>> token_logprobs=[-0.0013972291490063071],>> tokens=[' lazy'],>> top_logprobs=[{' lazy': -0.0013972291490063071,>> ' sleep': -7.501397132873535,>> ' l': -9.095147132873535,>> ' log': -9.126397132873535,>> ' la': -9.220147132873535,>> ' le': -9.313897132873535,>> ' lay': -9.720147132873535,>> ' Laz': -9.938897132873535,>> ' dog': -9.970147132873535,>> ' ': -9.970147132873535}])
我们可以使用以下公式将logprobs转换为百分比概率:
importnumpyasnpprobability=100*np.exp(logprob)
转换所有logprobs后,可以观察到标记"lazy"有99.86%的概率被采样。这同时意味着有0.14%的概率会选择其他标记。

给定补全提示"The quick brown fox jumps over the"时,前10个标记的概率分布,温度参数设为1。
贪婪解码策略
最基本的采样策略是贪婪解码。该方法在每一步简单地选择概率最高的标记。
贪婪解码是一种确定性采样策略,因为它不涉及任何随机性。给定相同的概率分布,模型每次都会选择相同的下一个标记。
贪婪解码的主要缺点是生成的文本往往重复性高且创意性不足。这类似于在写作时总是选择最常见的词汇和最标准的表达方式。

贪婪解码的数学表达式 [1]
与确定性的贪婪解码相对的是随机解码。这种方法从分布中进行采样,以产生更具创意性的、基于概率的文本。随机解码是通常应用于LLM输出的方法。
温度参数
温度是LLM中最广为人知的参数之一。
OpenAI对温度参数给出了如下定义:
采样温度的取值范围在0到2之间。较高的值(如0.8)会使输出更加随机,而较低的值(如0.2)会使输出更加聚焦和确定。
在LLM输出下一个标记的概率分布后,我们可以通过温度参数调整其分布形状。温度
T
是一个控制下一个标记概率分布尖锐度或平滑度的参数。
从数学角度看,经温度缩放后的新概率分布
P_T
可以通过以下公式计算。
z_v
是LLM为标记
v
输出的logprob或logit,它被温度参数
T
除。
温度缩放公式本质上是一个带有额外缩放参数
T
的softmax函数。

温度缩放的数学公式 [1]
通过加入温度参数,可以从新的概率分布
P_T
中采样,而不是原始概率分布
P
。
下图展示了对**输入提示"1+1="**的四种不同概率分布。在这种情况下,下一个标记应该是2。
(注意:这些并非完整分布,仅绘制了部分值)。

微软Phi-3.5-mini-instruct LLM对输入提示"1+1="的四种不同概率分布图,展示了不同温度T参数的效果。
可以观察到,温度
T
越高,分布就越趋于平坦。这里的"平坦"意味着各个结果的概率趋于均等。
值得注意的是,在默认温度
T=1.0
下,明显的正确答案2只有约85%的概率被选中,这意味着如果进行足够多次的采样,得到不同答案的可能性并非微乎其微。
在温度
T=2.0
时,尽管标记"2"仍然是最可能的选择,但其概率已降至约5%。这意味着此时采样的标记几乎完全随机。所以在实际应用中很少有理由将温度设置得如此之高。
这里我们引用OpenAI文档所述,温度是一种调节输出随机性或聚焦度的方法。由于我们只是在调整概率分布,始终存在采样到完全不相关标记的非零概率,这可能导致事实性错误或语法混乱。
Top-k采样策略
Top-k采样策略简单地选取概率最高的
k
个标记,忽略其余标记。
当
k=1
时,top-k采样等同于贪婪解码。
更准确地说,top-k采样在概率最高的前k个标记之后截断概率分布。这意味着我们将词汇表
V
中不属于前k个标记的所有标记的概率设为零。
将非top-k标记的概率设为零后,需要对剩余的分布进行重新归一化,使其总和为1:

重新归一化概率分布的公式 [2]
以下是
k=4
的top-k采样可视化示例:

输入提示"My name is"的top-k采样可视化,k=4。上图显示模型的原始输出概率,下图展示top-k截断和重新归一化后的概率分布。
上图展示了模型的原始输出分布。红线将图分为左侧的top-k标记和右侧的其余部分。下图显示了截断和重新归一化后的新top-k分布
P_K
。
需要注意的是,top-k采样目前不是OpenAI API的标准参数,但在其他API中,如Anthropic的API,确实提供了
top_k
参数。
Top-k采样的一个主要问题是如何设置参数
k
。对于非常尖锐的分布,我们倾向于使用较小的
k
值,以避免在截断的词汇表中包含大量低概率标记。而对于较为平坦的分布,我们可能需要较大的
k
值,这样可以包含更多合理的标记可能性。
Top-p采样策略
Top-p采样,也称为核采样,是另一种通过从词汇表中剔除低概率标记来截断概率分布的随机解码方法。
我们还是引用OpenAI对top_p参数给出的定义:
这是一种替代温度采样的方法,称为核采样,模型考虑累积概率达到top_p的标记集合。例如,0.1意味着只考虑累积概率达到前10%的标记。
在top-p采样中,我们为标记的累积概率质量定义一个阈值
p
。对(已排序的)概率进行累加,直到达到累积概率阈值。保留所有使累积概率不超过阈值
p
的标记。

获取top-p采样的top-p词汇表的数学公式 [2]
随后对截断后的概率分布进行重新归一化,使其总和为1。
下面是使用top-p对提示"I love to"进行采样的可视化结果:

输入提示"I love to"的top-p采样可视化,top_p=0.2。上图显示模型的原始输出概率,下图展示top-p截断和重新归一化后的概率分布。
上图展示了模型的原始输出分布,其中红线标记了20%的累积概率阈值,将图分为下方的top-p标记和上方的其余部分。重新归一化后,下图显示我们只保留了四个标记,其余标记的概率被置为零。
从理论角度来看,从logprobs的长尾分布中剔除极低概率的标记通常是合理的。因此
top_p
参数通常应设置为小于
1.0
的值。
但是top-p采样也并非完美无缺。下图展示了一个案例,其中top-p采样为了达到累积概率阈值而包含了大量低概率标记,这可能导致不理想的结果。

Top-p采样可能包含过多低概率标记的示例。(图片来源:[1])
结合Top-p和温度的策略
尽管OpenAI的官方文档中没有明确说明,但根据社区的测试结果,似乎top_p参数在温度参数之前应用。
一般情况下通常不建议同时设置top_p和温度参数,但在某些场景下,这种组合可能会带来优势。
仅调整温度参数会使概率分布变得更加平坦或尖锐。这会使输出要么更加确定(低温度),要么更具创意性(高温度)。但是模型仍然是从概率分布中随机采样。所以会始终存在采样到高度不可能标记的风险。
例如,模型可能会采样到外语字符或罕见的Unicode字符。理论上模型词汇表中的任何内容(现在通常非常庞大且多语言)都有可能被采样到。
作为一种解决方案,可以首先应用top-p采样来剔除这些极端情况,然后通过较高的温度从剩余的合理标记池中进行创造性采样。这种方法可以在保持输出多样性的同时,有效控制输出质量。
Min-p采样策略
最近一种新的采样方法被提出,称为min-p采样,源自论文"Min P Sampling: Balancing Creativity and Coherence at High Temperature"[1]。
Min-p同样是一种基于截断的随机解码方法,它试图通过引入动态阈值
p
来解决top-p采样的某些局限性。

计算min-p采样动态最小阈值的数学公式 [1]
Min-p采样的工作原理如下:
- 首先从概率分布中找出最大概率
p_max,即排名最高的标记的概率。 - 将这个最大概率乘以一个参数
p_base,得到一个最小阈值p_scaled。 - 采样所有概率大于或等于
p_scaled的标记。 - 最后,对截断后的概率进行重新归一化,得到新的概率分布。

Min-p采样使用相对最小概率的示意图。(图片来源:[1])
Min-p采样已在一些后端实现,如VLLM和llama.cpp。下图展示了min-p采样的可视化结果,其中
p_base = 0.1
,输入提示为"I love to read a"。
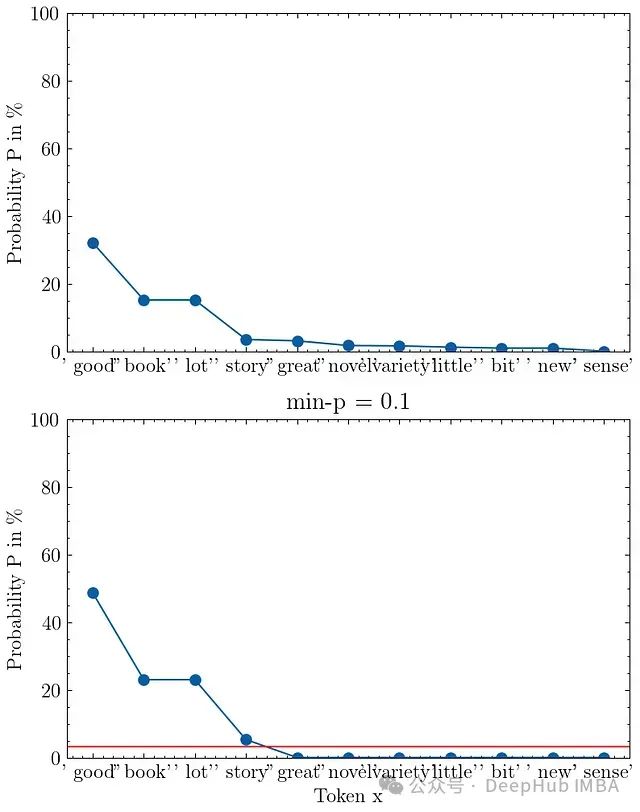
输入提示"I love to read a"的min-p采样可视化,p_base=0.1。上图显示模型的原始输出概率,下图展示min-p截断和重新归一化后的概率分布。
在这个例子中标记"good"的概率为32%。设置
p_base = 0.1
后,我们得到最小概率阈值
p_scaled = 3.2%
,即图中的红线位置。
总结与建议
通过深入理解采样参数的作用机制,我们可以更有针对性地为特定的LLM应用场景优化参数设置。
最关键的参数是温度和top_p。
温度参数调节模型输出概率分布的形状。需要注意的是,无论如何调整,总是存在采样到语义或语法上不合适标记的可能性。在给定概率分布的情况下,我们仍在进行概率性采样。
top_k参数通过截断概率分布来限制可能的候选标记集。但这种方法也存在风险:可能会过度剔除有价值的候选项,或者保留过多不适当的选项。
如果使用的LLM框架支持min-p采样,建议进行实验性尝试,评估其在特定任务中的表现。
在实际应用中,建议采取以下步骤:
- 首先尝试调整温度参数,观察其对输出质量的影响。
- 如果单纯调整温度无法达到理想效果,考虑引入top_p或top_k参数。
- 对不同参数组合进行系统性测试,找出最适合您特定任务的配置。
- 持续关注新的采样策略研究,如min-p采样,并在条件允许时进行评估。
通过精细调整这些参数,可以在保持输出多样性和创造性的同时,显著提高大语言模型生成内容的质量和相关性。
参考文献
[1] N. N. Minh, A. Baker, A. Kirsch, C. Neo, Min P Sampling: Balancing Creativity and Coherence at High Temperature (2024), arXiv:2407.01082
[2] A. Holtzman, J. Buys, L. Du, M. Forbes, Y. Choi, The Curious Case of Neural Text Degeneration (2019), Proceedings of International Conference on Learning Representations (ICLR) 2020
https://avoid.overfit.cn/post/6a30e6cfd2ac4f0d89edb4235e30c876
作者:Dr. Leon Eversberg
这篇关于优化采样参数提升大语言模型响应质量:深入分析温度、top_p、top_k和min_p的随机解码策略的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



