随机专题

Python中随机休眠技术原理与应用详解
《Python中随机休眠技术原理与应用详解》在编程中,让程序暂停执行特定时间是常见需求,当需要引入不确定性时,随机休眠就成为关键技巧,下面我们就来看看Python中随机休眠技术的具体实现与应用吧... 目录引言一、实现原理与基础方法1.1 核心函数解析1.2 基础实现模板1.3 整数版实现二、典型应用场景2
Python中的随机森林算法与实战
《Python中的随机森林算法与实战》本文详细介绍了随机森林算法,包括其原理、实现步骤、分类和回归案例,并讨论了其优点和缺点,通过面向对象编程实现了一个简单的随机森林模型,并应用于鸢尾花分类和波士顿房... 目录1、随机森林算法概述2、随机森林的原理3、实现步骤4、分类案例:使用随机森林预测鸢尾花品种4.1

使用C#如何创建人名或其他物体随机分组
《使用C#如何创建人名或其他物体随机分组》文章描述了一个随机分配人员到多个团队的代码示例,包括将人员列表随机化并根据组数分配到不同组,最后按组号排序显示结果... 目录C#创建人名或其他物体随机分组此示例使用以下代码将人员分配到组代码首先将lstPeople ListBox总结C#创建人名或其他物体随机分组

AI学习指南深度学习篇-带动量的随机梯度下降法的基本原理
AI学习指南深度学习篇——带动量的随机梯度下降法的基本原理 引言 在深度学习中,优化算法被广泛应用于训练神经网络模型。随机梯度下降法(SGD)是最常用的优化算法之一,但单独使用SGD在收敛速度和稳定性方面存在一些问题。为了应对这些挑战,动量法应运而生。本文将详细介绍动量法的原理,包括动量的概念、指数加权移动平均、参数更新等内容,最后通过实际示例展示动量如何帮助SGD在参数更新过程中平稳地前进。

AI学习指南深度学习篇-带动量的随机梯度下降法简介
AI学习指南深度学习篇 - 带动量的随机梯度下降法简介 引言 在深度学习的广阔领域中,优化算法扮演着至关重要的角色。它们不仅决定了模型训练的效率,还直接影响到模型的最终表现之一。随着神经网络模型的不断深化和复杂化,传统的优化算法在许多领域逐渐暴露出其不足之处。带动量的随机梯度下降法(Momentum SGD)应运而生,并被广泛应用于各类深度学习模型中。 在本篇文章中,我们将深入探讨带动量的随
HDD 顺序和随机文件拷贝和存储优化策略
对于机械硬盘(HDD),顺序拷贝和随机拷贝涉及到磁头的移动方式和数据的读取/写入模式。理解这些概念对于优化硬盘性能和管理文件操作非常重要。 1. 顺序拷贝 定义: 顺序拷贝指的是数据从硬盘的一个位置到另一个位置按顺序连续读取和写入。这意味着数据在硬盘上的位置是线性的,没有跳跃或回溯。 特点: 磁头移动最小化:由于数据是连续的,磁头在读取或写入数据时只需要在磁盘的一个方向上移动,减少了寻道时
算法:将数组随机打乱顺序,生成一个新的数组
一、思路 核心:缩小原数组的可随机取数范围 1、创建一个与原数组长度相同的新数组; 2、从原数组的有效的可取数范围 (不断缩小) 中随机取出一个数据,添加进新的数组; 3、将取出的随机数与原数组的最后一个数据进行置换; 4、重复步骤2和3。 二、代码 public class ArrayRandomTest {//将数组随机打乱顺序,生成一个新的数组public static int

Midjourney 随机风格 (Style Random),开启奇幻视觉之旅
作者:老余捞鱼 原创不易,转载请标明出处及原作者。 写在前面的话: Midjourney 最近推出了 "Style Random"(随机风格),这项功能可以让我们使用独特的随机 sref 代码创建图像,从而每次都能获得不同的美感。通过对这些功能的探索和尝试,我发现了一些很棒的风格,我很高兴能与大家分享,这样可以节省大家的时间,不用自己动手测试。在本文中,我将展示十个M


Arcgis字段计算器:随机生成规定范围内的数字
选择字段计算器在显示的字段计算器对话框内,解析程序选择Python,勾选上显示代码块, 半部分输入: import random; 可修改下半部分输入: random.randrange(3, 28) 表示生成3-28之间的随机数 字段计算器设置点击确定完成随机数的生成,生成的随机数如下图所示。
随机森林的知识博客:原理与应用
随机森林(Random Forest)是一种基于决策树的集成学习算法,它通过组合多棵决策树的预测结果来提升模型的准确性和稳健性。随机森林具有强大的分类和回归能力,广泛应用于各种机器学习任务。本文将详细介绍随机森林的原理、构建方法及其在实际中的应用。 1. 随机森林的原理 1.1 集成学习(Ensemble Learning) 在机器学习中,集成学习是一种通过结合多个模型的结果来提高预测性能的
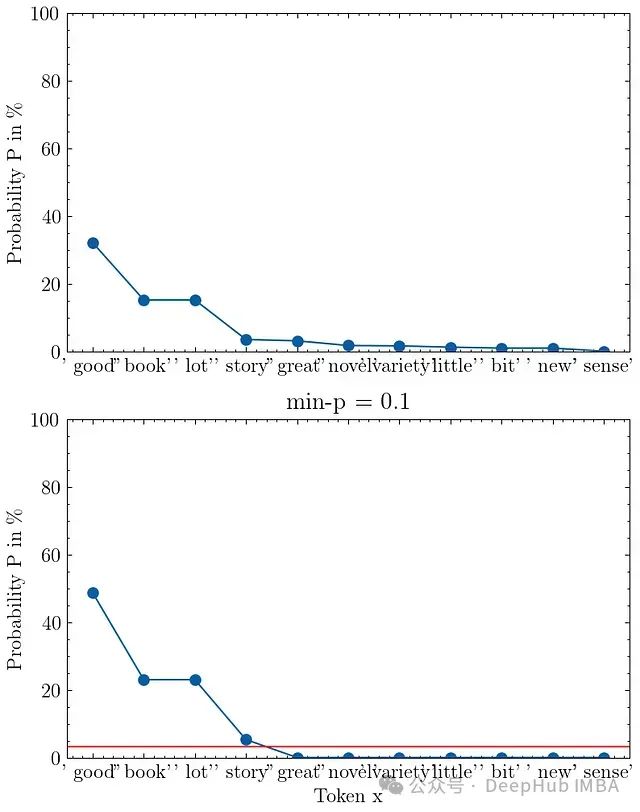
优化采样参数提升大语言模型响应质量:深入分析温度、top_p、top_k和min_p的随机解码策略
当向大语言模型(LLM)提出查询时,模型会为其词汇表中的每个可能标记输出概率值。从这个概率分布中采样一个标记后,我们可以将该标记附加到输入提示中,使LLM能够继续输出下一个标记的概率。这个采样过程可以通过诸如 temperature 和 top_p 等参数进行精确控制。但是你是否曾深入思考过temperature和top_p参数的具体作用? 本文将详细解析并可视化定义LLM输出行为的

PCB过孔规则排列,还是随机?
在现代电子设备设计中,印刷电路板(PCB)的复杂性不断增加,尤其是在高密度集成电路和多层PCB中,过孔(Via)起到了至关重要的作用。过孔通过将PCB的不同层相互连接,使得电路板不再局限于平面的布线,而是实现了立体化的电气连接结构,从而提升了设计的灵活性和电气性能。 1. 过孔的定义与作用 过孔,顾名思义,是PCB板上的一种孔,用于连接PCB不同层之间的导电路径。由于单层PCB的布线空间有限

【机器学习】梯度提升和随机森林的概念、两者在python中的实例以及梯度提升和随机森林的区别
引言 梯度提升(Gradient Boosting)是一种强大的机器学习技术,它通过迭代地训练决策树来最小化损失函数,以提高模型的预测性能 随机森林(Random Forest)是一种基于树的集成学习算法,它通过组合多个决策树来提高预测的准确性和稳定性 文章目录 引言一、梯度提升1.1 基本原理1.1.1 初始化模型1.1.2 迭代优化1.1.3 梯度计算1.1.4模型更新 1.2

win7下Mongodb安装配置为随机启动
mongodb在win7下只需要解压到相应的文件夹下就行了,然后添加到win7路径下面,在CMD命令下面打开可能会出现无法服务器积极拒绝的情况,所以就选着添加到win7服务里面,具体的方法是: 需要在路径下面的文件夹里面新建以下内容: data,logs文件夹: 然后再建一个mongod.cfg里面写入地址: logpath=D:\mongodb\logs\mongodb.log db
随机算法 - HNU 13348 Finding Lines
Finding Lines Problem's Link: http://acm.hnu.cn/online/?action=problem&type=show&id=13348&courseid=0 Mean: 给你平面上1e5个点,让你判断是否可以找到一条直线,使得p%的点都在这条直线上。 analyse: 经典的随机算法题。 每次随机出两个点,

mllib之随机森林与梯度提升树
随机森林和GBTs都是集成学习算法,它们通过集成多棵决策树来实现强分类器。 集成学习方法就是基于其他的机器学习算法,并把它们有效的组合起来的一种机器学习算法。组合产生的算法相比其中任何一种算法模型更强大、准确。 随机森林和梯度提升树(GBTs)。两者之间主要差别在于每棵树训练的顺序。 随机森林通过对数据随机采样来单独训练每一棵树。这种随机性也使得模型相对于单决策树更健壮,且不易在

Open3D 体素随机下采样
目录 一、概述 1.1原理 1.2实现步骤 1.3应用场景 二、代码实现 三、实现效果 3.1原始点云 3.2体素下采样后点云 Open3D点云算法汇总及实战案例汇总的目录地址: Open3D点云算法与点云深度学习案例汇总(长期更新)-CSDN博客 一、概述 体素随机下采样是一种常用的点云简化方法,通过将点云划分为立方体体素网格,并从每个体素中随机

机器学习项目——基于机器学习(决策树 随机森林 朴素贝叶斯 SVM KNN XGBoost)的帕金森脑电特征识别研究(代码/报告材料)
完整的论文代码见文章末尾 以下为核心内容和部分结果 问题背景 帕金森病(Parkinson’s Disease, PD)是一种常见的神经退行性疾病,其主要特征是中枢神经系统的多巴胺能神经元逐渐丧失,导致患者出现运动障碍、震颤、僵硬等症状。然而,除运动症状外,帕金森病患者还常常伴有一系列非运动症状,其中睡眠障碍是最为显著的非运动症状之一。 脑电图(Electroencephalogram, E

【重点必读】|《商用密码随机抽查事项清单》要点解读与应对策略
近期,国家密码管理局发布了《商用密码随机抽查事项清单(2024年版)》公告,抽查类别包括商用密码检测和商用密码应用、电子认证服务使用密码、电子政务电子认证服务。其中抽查清单序号3的抽查类别为商用密码应用与应用安全息息相关,要求使用国密算法(SM1、SM2、SM3、SM4、SM7、SM9、ZUC等),并采取必要的密码安全防护措施,并防止数据泄露、篡改等。 主要抽查内容
AI学习指南深度学习篇-随机梯度下降法(Stochastic Gradient Descent,SGD)简介
AI学习指南深度学习篇-随机梯度下降法(Stochastic Gradient Descent,SGD)简介 在深度学习领域,优化算法是至关重要的一部分。其中,随机梯度下降法(Stochastic Gradient Descent,SGD)是最为常用且有效的优化算法之一。本篇将介绍SGD的背景和在深度学习中的重要性,解释SGD相对于传统梯度下降法的优势和适用场景,并提供详细的示例说明。 1.
聊聊随机测试和猴子测试
目录 随机测试的特点 1.不可预测性 2.缺乏针对性 3.自动化 4.资源密集型 猴子测试 随机测试 (Random Testing) 猴子测试 (Monkey Testing) 特点: 区别 1.控制程度 2.目标差异 3.实现方式 在我们测试的过程中,通常会使用到随机测试和猴子测试,其中随机测试侧重于人工测试,猴子测试侧重于借助工具执行命令进行测试。 随机测试
iOS 随机打乱一个数组的顺序 获得一个新的数组
第一种方法:笨方法 -(NSMutableArray*)getRandomArrFrome:(NSArray*)arr{NSMutableArray *newArr = [NSMutableArray new];while (newArr.count != arr.count) {//生成随机数int x =arc4random() % arr.count;id obj = arr[x];

随即近似与随机梯度下降
一、均值计算 方法1:是直接将采样数据相加再除以个数,但这样的方法运行效率较低,要将所有数据收集到一起后再求平均。 方法2:迭代法 二、随机近似法: Robbins-Monro算法(RM算法) g(w)是有界且递增的 ak的和等于无穷,并且ak平方和小于无穷。我们会发现在许多强化学习算法中,通常会选择 ak作为一个足够小的常数,因为 1/k 会越来越小导致算法效率较低
随机实现100以内的的加减乘除运算
算法思想: (1) 产生两个随机数 (2) 产生一个运算符 (3) 用户输入答案 (4) 验证答案正确与否 (5) 转(1) 重复执行 主函数中用到了srand(time(NULL))上百度查了一下和随机产生有关。如果在程序运行时没有自主设置种子的话,用函数rand产生的随机数序列会是一样的。 而用srand设置随机数种子后,可能产生不同的随机序列(概率很大)。