采样专题

重复采样魔法:用更多样本击败单次尝试的最强模型
这篇文章探讨了通过增加生成样本的数量来扩展大型语言模型(LLMs)在推理任务中的表现。 研究发现,重复采样可以显著提高模型的覆盖率,特别是在具有自动验证工具的任务中。研究还发现,覆盖率与样本数量之间的关系可以用指数幂律建模,揭示了推理时间的扩展规律。尽管多数投票和奖励模型在样本数量增加时趋于饱和,但在没有自动验证工具的任务中,识别正确样本仍然是一个重要的研究方向。 总体而言,重复采样提供了一种

研究纹理采样器在像素级别的采样位置
问题 【纹理采样器】是一个基础的概念。假设有一个正方形面片,顶点的UV范围是0.0~1.0,那么在这个正方形面片上采样一张纹理时,会呈现出完整的纹理。 但我现在关注的问题是,在像素级别上,采样的位置是怎样的。具体来讲:对于UV值是(0.0,0.0)的点,它对应的采样位置是纹理最左上角像素的中心?还是纹理最左上角像素的左上角?即,下面左右哪个是正确的情况? 在宏观上,尤其是像素较多的时候,二者

爆改YOLOv8|利用yolov10的SCDown改进yolov8-下采样
1, 本文介绍 YOLOv10 的 SCDown 方法来优化 YOLOv8 的下采样过程。SCDown 通过点卷积调整通道维度,再通过深度卷积进行空间下采样,从而减少了计算成本和参数数量。这种方法不仅降低了延迟,还在保持下采样过程信息的同时提供了竞争性的性能。 关于SCDown 的详细介绍可以看论文:https://arxiv.org/pdf/2405.14458 本文将讲解如何将SCDow
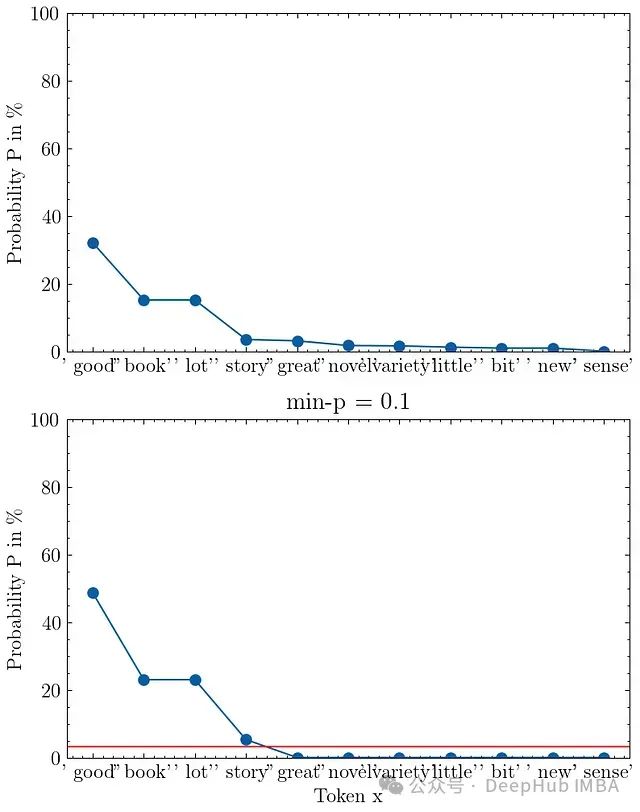
优化采样参数提升大语言模型响应质量:深入分析温度、top_p、top_k和min_p的随机解码策略
当向大语言模型(LLM)提出查询时,模型会为其词汇表中的每个可能标记输出概率值。从这个概率分布中采样一个标记后,我们可以将该标记附加到输入提示中,使LLM能够继续输出下一个标记的概率。这个采样过程可以通过诸如 temperature 和 top_p 等参数进行精确控制。但是你是否曾深入思考过temperature和top_p参数的具体作用? 本文将详细解析并可视化定义LLM输出行为的

word2vec 两个模型,两个加速方法 负采样加速Skip-gram模型 层序Softmax加速CBOW模型 item2vec 双塔模型 (DSSM双塔模型)
推荐领域(DSSM双塔模型): https://www.cnblogs.com/wilson0068/p/12881258.html word2vec word2vec笔记和实现 理解 Word2Vec 之 Skip-Gram 模型 上面这两个链接能让你彻底明白word2vec,不要搞什么公式,看完也是不知所云,也没说到本质. 目前用的比较多的都是Skip-gram模型 Go

YoloV10改进策略:下采样改进|自研下采样模块(独家改进)|疯狂涨点|附结构图
文章目录 摘要自研下采样模块及其变种第一种改进方法 YoloV10官方测试结果改进方法测试结果总结 摘要 本文介绍我自研的下采样模块。本次改进的下采样模块是一种通用的改进方法,你可以用分类任务的主干网络中,也可以用在分割和超分的任务中。已经有粉丝用来改进ConvNext模型,取得了非常好的效果,配合一些其他的改进,发一篇CVPR、ECCV之类的顶会完全没有问题。 本次我将这个模

CUDAPCL 点云体素下采样
文章目录 一、简介二、实现代码三、实现效果参考资料 一、简介 体素下采样是指使用常规体素网格从输入点云创建均匀下采样的点云。它经常被用作许多点云处理任务的预处理步骤。该算法分为两步操作: (1)并行的将每个点分配到其所处的体素中。 (2)并行遍历所有体素,并求取每个体素中所有点的质心点。 二、实现代码 VoxelSample.cuh #ifndef VOXELS

Open3D 体素随机下采样
目录 一、概述 1.1原理 1.2实现步骤 1.3应用场景 二、代码实现 三、实现效果 3.1原始点云 3.2体素下采样后点云 Open3D点云算法汇总及实战案例汇总的目录地址: Open3D点云算法与点云深度学习案例汇总(长期更新)-CSDN博客 一、概述 体素随机下采样是一种常用的点云简化方法,通过将点云划分为立方体体素网格,并从每个体素中随机

matlab实现kaiser窗+时域采样序列(不管原信号拉伸成什么样子)是一样的,变到频谱后再采样就是一样的频域序列。
下图窗2的频谱在周期化的时候应该是2(w-k*pi/T)我直接对2w减得写错了 可见这两个kaiser窗频谱不一样,采样间隔为2T的窗,频谱压缩2倍,且以原采样频率的一半周期化。 但是这两个不同的kaiser窗在频域采样点的值使完全一致的。这和matlab模拟dft的过程吻合 也说明不管原信号拉伸成什么样子,只要时域采样序列是一样的,变到频谱后再采样就是一样的频域序列。 (与原信号的
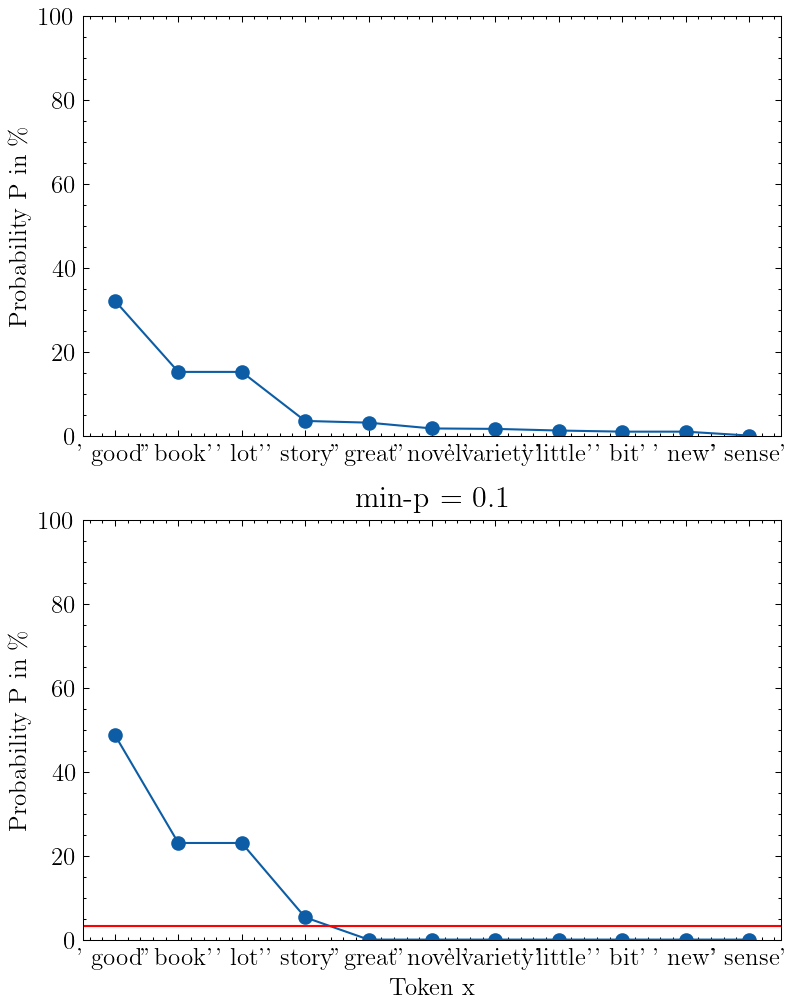
如何通过更好的采样参数来提高 LLM 响应率
深入研究使用温度、top_p、top_k 和 min_p 进行随机解码 当你向大型语言模型 (LLM) 提出问题时,该模型会输出其词汇表中每个可能标记的概率。 从该概率分布中抽取一个标记后,我们可以将选定的标记附加到我们的输入提示中,以便 LLM 可以输出下一个标记的概率。 temperature该采样过程可以通过著名的和等参数来控制top_p。 在本文中,我将解释并直观地展示定义 LLM

【STM32 Blue Pill编程】-ADC数据采样(轮询、中断和DMA模式)
ADC数据采样(轮询、中断和DMA模式) 文章目录 ADC数据采样(轮询、中断和DMA模式)1、硬件准备及接线2、ADC轮询模式2.1 轮询模式配置2.2 代码实现 3、ADC中断模式3.1 中断模式配置3.2 代码实现 4、ADC的DMA模式4.1 DMA模式配置4.2 代码实现 在本文中,我们将介绍如何使用 ADC 并使用 STM32CubeIDE 和 HAL 库读取模拟输
YoloV9改进策略:下采样改进|集成GCViT的Downsampler模块实现性能显著提升|即插即用
摘要 随着深度学习在计算机视觉领域的广泛应用,目标检测任务成为了研究热点之一。YoloV9作为实时目标检测领域的领先模型,凭借其高效性与准确性赢得了广泛的关注。然而,为了进一步提升YoloV9的性能,特别是在特征提取与下采样过程中的信息保留能力,我们引入了来自GCViT(Global Context Vision Transformers)模型中的Downsampler模块。本文将详细阐述这一改
GEE土地分类预处理:NAIP和NLCD影像的数据进行随机样本点提取采样作为土地分类的标签数据(R\G\B和landcover)
目录 简介 数据集 NAIP National Agriculture Imagery Program NLCD 2021: USGS National Land Cover Database 函数 neighborhoodToArray(kernel, defaultValue) Arguments: Returns: Image Export.table.toCloudS

结合代码详细讲解DDPM的训练和采样过程
本篇文章结合代码讲解Denoising Diffusion Probabilistic Models(DDPM),首先我们先不关注推导过程,而是结合代码来看一下训练和推理过程是如何实现的,推导过程会在别的文章中讲解;首先我们来看一下论文中的算法描述。DDPM分为扩散过程和反向扩散过程,也就是训练过程和采样过程; 代码来自https://github.com/zoubohao/DenoisingDi

MATLAB算法实战应用案例精讲-【采样路径规划算法】RRT算法(附MATLAB源码)
目录 前言 算法原理 算法流程 算法流程图 优缺点 伪代码 知识拓展 基于BINN算法的CCPP全路径覆盖算法 1、CCPP整体算法 2. 核心代码 代码 1.MATLAB 前言 RRT算法是适用于高维空间,通过对状态空间中的采样点进行碰撞检测,避免了对空间的建模,较好的处理带有非完整约束的路径规划问题,有效的解决了高维空间和复杂约束的路径规划问题。该算法

Open3D mesh 均匀下采样
目录 一、概述 1.1原理 1.2实现步骤 1.3应用 二、代码实现 2.1关键函数 2.2完整代码 三、实现效果 3.1原始mesh 3.2下采样mesh Open3D点云算法汇总及实战案例汇总的目录地址: Open3D点云算法与点云深度学习案例汇总(长期更新)-CSDN博客 一、概述 在 Open3D 中,均匀下采样(Uniform M
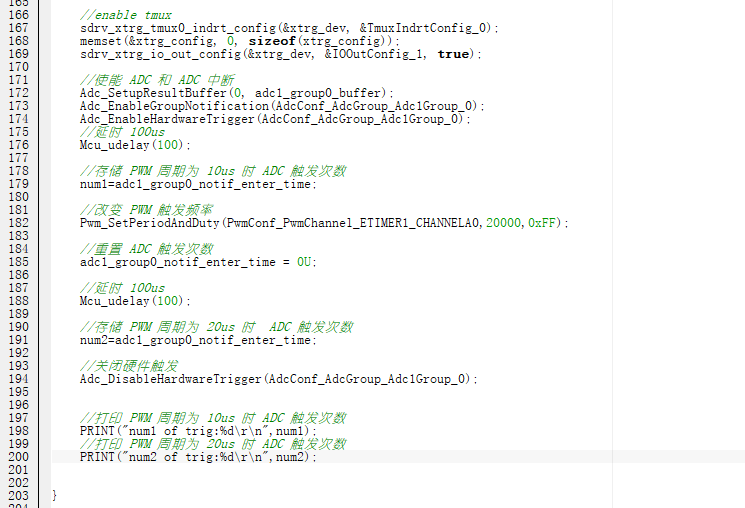
SemiDrive E3 MCAL 配置 :PWM 硬件触发 ADC 采样
一、前言 在使用 ADC 进行采样时,ADC 的硬件触发采样是 ADC 的典型应用。 本文将介绍 SemiDrive E3 MCAL 配置 :PWM 硬件触发 ADC 采样。 硬件平台:芯驰 E3640 Gateway 开发板 软件平台:SemiDrive_E3_MCAL_V3.0 二、EB 配置 2.1 ADC 配置 ADC 的 Hardware 触发对应的是 ADC 中 Gr

Vulkan入门系列17 - 多重采样( Multisampling)
一:概述 我们的程序现在可以加载多个级别的纹理,从而解决了在渲染远离观察者的物体时出现的伪影问题。现在图像变得平滑多了,但仔细观察,你会发现绘制的几何图形边缘呈现锯齿状。这在我们早期渲染一个四边形的程序中尤为明显: 这种不希望有的效果被称为 “锯齿”,这是由于可用于渲染的像素数量有限造成的。由于没有无限分辨率的显示器,因此在某种程度上总是会出现这种现象。解决

PCIe563XD系列多功能异步数据采集卡64路AD信号采集500K采样频率
阿尔泰科技 型号:PCIe5630D/5631D/5632D/5633Dhttps://item.taobao.com/item.htm?spm=a1z10.3-c-s.w4002-265216876.12.84513350msbilC&id=589158158140&pisk=f6qstfsYFCA6dK09z-BERdlfDjobG5szWKMYE-KwHcntcqeoOlla3juYGWc
如何实现下采样(教科书级别教你拿捏)
在数据处理、信号处理、图像处理以及机器学习等多个领域中,下采样(Downsampling)是一项至关重要的技术。下采样旨在减少数据集中的样本数量,同时尽量保留原始数据的关键信息,以便在降低计算成本、提高处理速度或适应特定分析需求时仍然保持数据的代表性。本文将详细介绍下采样的基本概念、应用场景以及几种常用的实现方法。 一、下采样的基本概念 下采样,也称为降采样,是通过对原始数据进行抽样或聚合

机器学习-过采样(全网最详解)
文章目录 相关介绍1.过采样的基本概念2.常见的过采样方法3.过采样在逻辑回归中的应用 过采样实际运用1.导入相关包2.数据预处理3.过采样操作4.交叉验证5.绘制混淆矩阵6.模型评估与测试 总结 相关介绍 在逻辑回归中,处理不平衡数据集是一个重要的步骤,因为不平衡的数据集可能导致模型偏向于多数类,而忽略少数类。过采样(Over-sampling)是处理不平衡数据集的一种常用方法

《机器学习》—— 使用过采样方法实现逻辑回归分类问题
文章目录 一、什么是过采样方法?二、使用过采样方法实现逻辑回归分类问题三、过采样的优缺点 本篇内容是 基于Python的scikit-learn库中sklearn.linear_model 类中的 LogisticRegression()逻辑回归方法实现的,其内容中只是在处理训练集的方法上与以下链接内容里的不同,在其他的方面都是一样的,可以放在一起看。 《机器学习》—— 通过

机器学习:逻辑回归实现下采样和过采样
1、概述 逻辑回归本身是一种分类算法,它并不涉及下采样或过采样操作。然而,在处理不平衡数据集时,这些技术经常被用来改善模型的性能。下采样和过采样是两种常用的处理不平衡数据集的方法。 2、下采样 1、概念 下采样是通过减少数量较多的类别(多数类)的样本数量,使其与数量较少的类别(少数类)的样本数量相匹配或接近。这样可以使模型在训练时不会偏向于多
YoloV8改进策略:下采样与上采样改进|下采样模块和DUpsampling上采样模块|即插即用
摘要 在深度学习与计算机视觉领域,YoloV8作为实时目标检测算法的代表,以其卓越的性能和效率赢得了广泛认可。然而,为了不断追求更高的精度与更快的推理速度,我们在YoloV8的基础上进行了创新性改进,重点引入了先进的下采样模块和DUpsampling上采样模块。这些改进不仅显著提升了YoloV8的性能,还为其在复杂场景下的应用提供了更强大的支持。 下采样模块的革新 该模块结合了卷积层和最大池

【Oracle篇】统计信息和动态采样的深度剖析(第一篇,总共六篇)
💫《博主介绍》:✨又是一天没白过,我是奈斯,DBA一名✨ 💫《擅长领域》:✌️擅长Oracle、MySQL、SQLserver、阿里云AnalyticDB for MySQL(分布式数据仓库)、Linux,也在扩展大数据方向的知识面✌️ 💖💖💖大佬们都喜欢静静的看文章,并且也会默默的点赞收藏加关注💖💖💖 兄弟们,沉寂了一段时间后,今天我回来了!!!最近博主在赶项