本文主要是介绍如何通过更好的采样参数来提高 LLM 响应率,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
深入研究使用温度、top_p、top_k 和 min_p 进行随机解码

当你向大型语言模型 (LLM) 提出问题时,该模型会输出其词汇表中每个可能标记的概率。
从该概率分布中抽取一个标记后,我们可以将选定的标记附加到我们的输入提示中,以便 LLM 可以输出下一个标记的概率。
temperature该采样过程可以通过著名的和等参数来控制top_p。
在本文中,我将解释并直观地展示定义 LLM 输出行为的采样策略。通过了解这些参数的作用并根据我们的用例进行设置,我们可以改进 LLM 生成的输出。
理解使用 Logprobs 进行抽样
LLM解码理论 欢迎来到雲闪世界。
LLM 在有限词汇表 上进行训练V,其中包含模型可以看到和输出的所有可能的标记x。标记可以是单词、字符或介于两者之间的任何内容。
LLM 将一系列标记x = (x_1, x_2, x_3, ..., x_n)作为输入提示,其中每个标记x都是 的一个元素V。
然后,LLM 根据输入提示输出下一个 token 的概率分布 P。从数学上讲,这可以描述为P(x_t | x_1, x_2, x_3, ..., x_t-1)。
从这个分布中选择哪个 token 由我们自己决定。在这里,我们可以在不同的采样策略和采样参数之间进行选择。

采样是掷骰子的一种花哨说法。照片由Jonathan Petersson在Unsplash上拍摄
选择下一个标记后,我们将选定的标记附加到输入提示并重复该循环。
在法学硕士 (LLM) 领域中,这些概率分布通常使用对数概率 (称为logprobs)来描述。
如下图所示,对数函数在零到一之间始终为负。
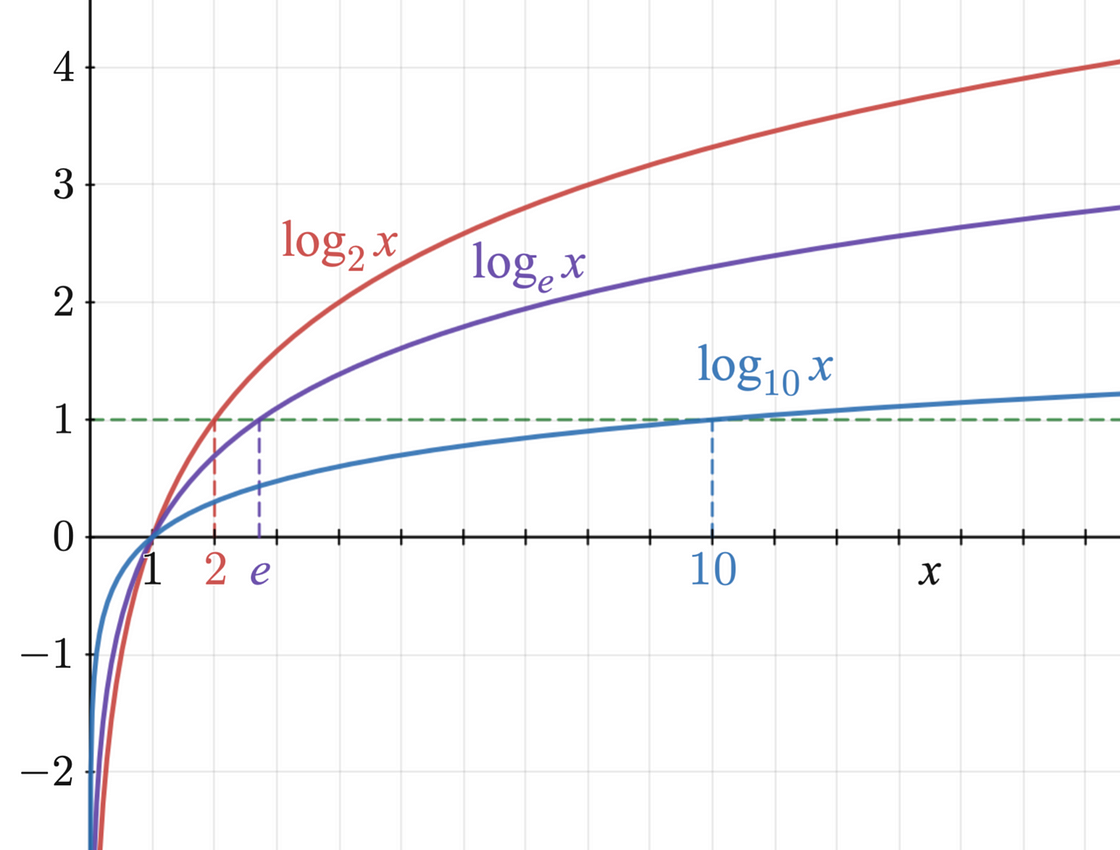
具有三个常用底数的对数函数图。图片来源:Richard F. Lyon,根据CC BY-SA 3.0许可
这就是 logprob 为负数的原因。接近于零的 logprob 表示非常高的概率,接近于 100%,而较大的负 logprob 表示概率接近于 0%。
使用 OpenAI Python SDK 检索 Logprobs
这是一个简单的 Python 脚本,它使用官方的 OpenAI Python 客户端进行聊天补全。有了这些参数,模型将尝试根据输入提示预测下一个标记。
from openai import OpenAIclient = OpenAI()completion = client.completions.create(model="jester6136/Phi-3.5-mini-instruct-awq",prompt="The quick brown fox jumps over the",logprobs=10,temperature=1.0,top_p=1.0,max_tokens=1
)下面是给定句子的 token 概率分布。模型选择tokens=[' lazy']作为下一个 token。我们还可以在列表中看到前 10 个 logprobs top_logprobs。
logprobs = completion.choices[0].logprobs0].logprobsprint(logsprobs)
>> Logprobs(text_offset=[0],
>> token_logprobs=[-0.0013972291490063071],
>> tokens=[' lazy'],
>> top_logprobs=[{' lazy': -0.0013972291490063071,
>> ' sleep': -7.501397132873535,
>> ' l': -9.095147132873535,
>> ' log': -9.126397132873535,
>> ' la': -9.220147132873535,
>> ' le': -9.313897132873535,
>> ' lay': -9.720147132873535,
>> ' Laz': -9.938897132873535,
>> ' dog': -9.970147132873535,
>> ' ': -9.970147132873535}])我们可以使用以下公式将对数概率转换为百分比:
import numpy as np
probability = 100 * np.exp(logprob)转换所有对数概率后,我们可以看到标记“lazy”有 99.86% 的概率被采样。这也意味着有 0.14% 的概率其他东西会被采样。
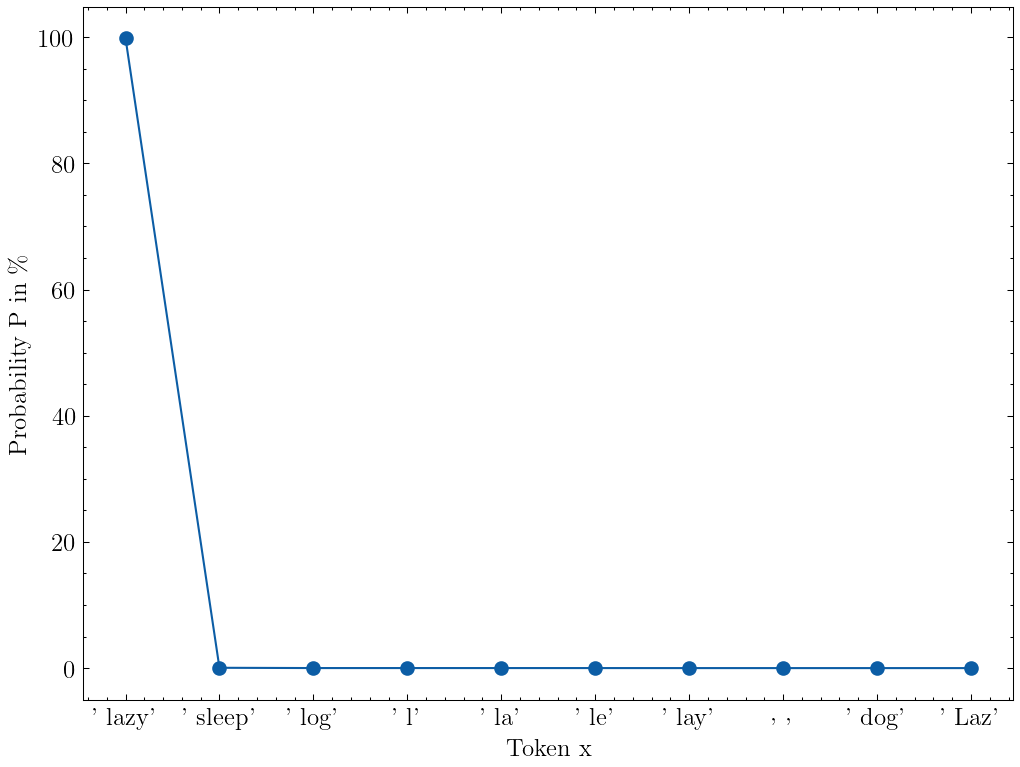
给出完成提示“The quick brown fox jumps over the”且温度 = 1 的前 10 个 token 的 token 概率。图片来自作者
贪婪解码
最基本的采样策略称为贪婪解码。贪婪解码每次只是选择最可能的标记。
贪婪解码是一种确定性采样策略,因为不涉及随机性。给定相同的概率分布,模型将始终选择相同的下一个标记。
贪婪解码的缺点是生成的文本重复性强,缺乏创造性。想象一下,在写一篇文章时,你总是选择你能想到的最常用的单词和标准短语。
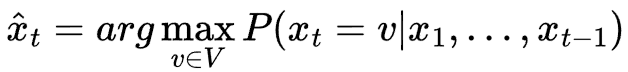
贪婪解码公式[1]
确定性贪婪解码的反面称为随机解码。这是我们从分布中开始采样以获得基于机会的更具创造性的文本的地方。随机解码是我们通常对 LLM 输出执行的操作。
温度
大多数使用 LLM 的人都听说过温度参数。
OpenAI对温度参数给出了如下定义:
使用什么采样温度,在 0 到 2 之间。较高的值(如 0.8)将使输出更加随机,而较低的值(如 0.2)将使其更加集中和确定性。
在我们的 LLM 输出下一个 token 的概率分布后,我们可以修改其形状。温度T是一个参数,它控制下一个 token 的概率分布变得多么尖锐或平坦。
从数学上来说,温度缩放后的新概率分布P_T可以按照以下公式计算。z_v是来自 LLM 的 token 的 logprob 或 logit,v除以温度参数T。
温度缩放公式本质上是带有附加缩放参数的softmax T。
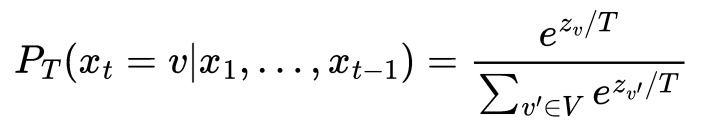
温度缩放公式[1]
我们不再从原始概率分布中抽样P,而是从新的概率分布中抽样P_T。
下图中,我针对输入提示“1+1=”绘制了四种不同的概率分布。显然,下一个 token 应该是 2。
(这些不是完整的分布,因为我只绘制了几个值)。
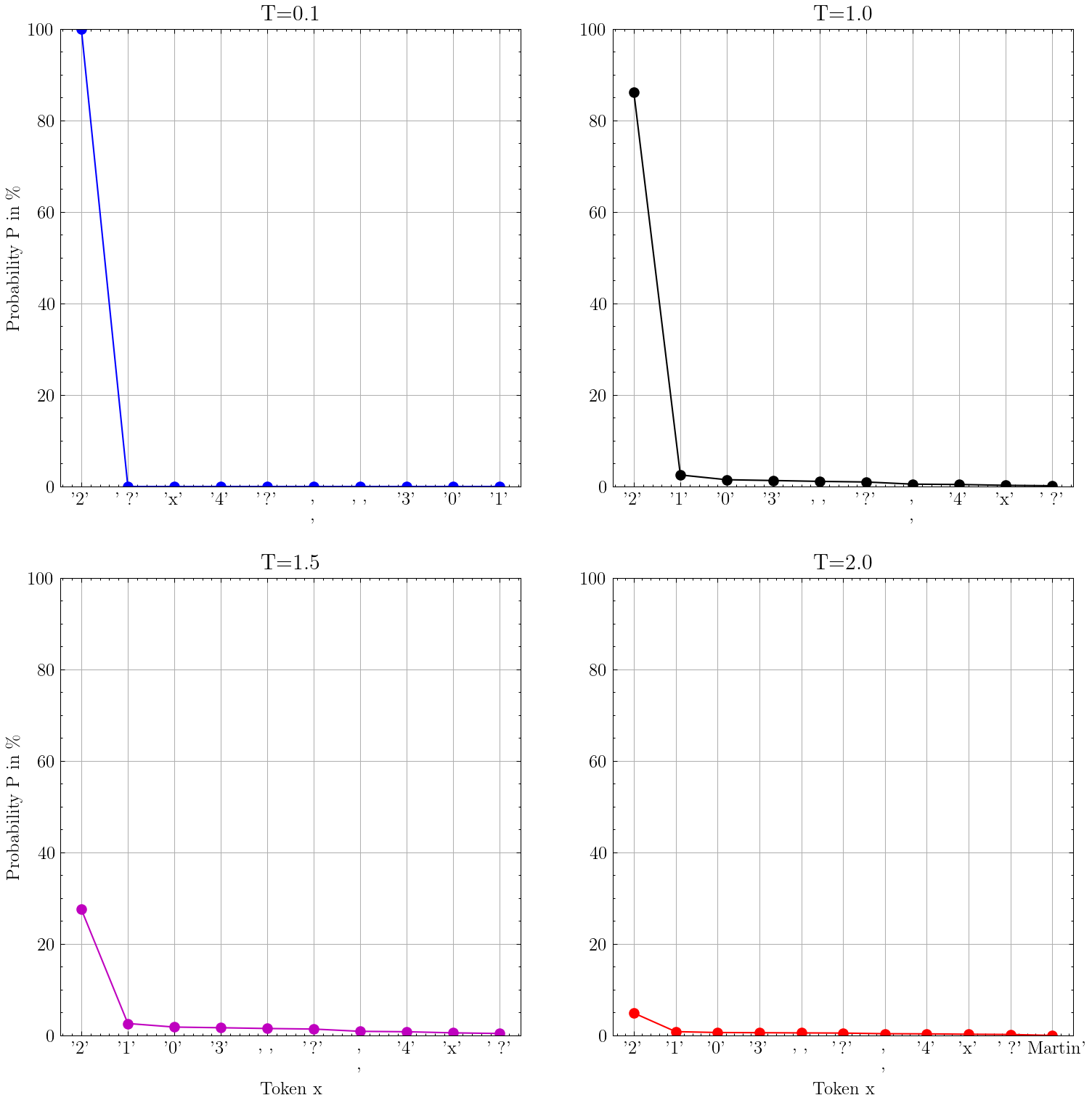
微软 Phi-3.5-mini-instruct LLM 的四种不同概率分布图,针对输入提示“1+1=”具有不同的温度 T 参数。图片由作者提供
如你所见,温度越高T,分布越平坦。“平坦”意味着所有事物发生的可能性都变得更相等。
有趣的是,在默认温度下T=1.0,显而易见的答案 2 的概率约为 85%,这意味着如果您对输出进行足够多次采样,则得到不同的答案的可能性并不大。
对于温度为T=2.0“2”的令牌,可能性仍然最大,但概率只有 5% 左右。这意味着此时采样的令牌几乎完全是随机的。在我看来,出于这个原因,永远使用温度为 2 是没有道理的。
正如 OpenAI 文档中所述,温度是一种使输出更加随机或更加集中的方法。但是,由于我们只是塑造概率分布,因此总是存在非零概率来采样完全无意义的标记,这可能导致事实上不正确的陈述或语法上的胡言乱语。
Top-k 采样
Top-k 采样只是选取最好的k标记并忽略其余的标记。
如果设置k=1,则会得到贪婪解码。
更正式地说,top-k 采样会在最可能的 top-k 个标记之后截断概率分布V。这意味着我们将词汇表中不属于 top-k 个标记的所有标记的概率设置为零。
将非前 k 个标记设置为零后,剩余分布将重新调整为总和为 1:
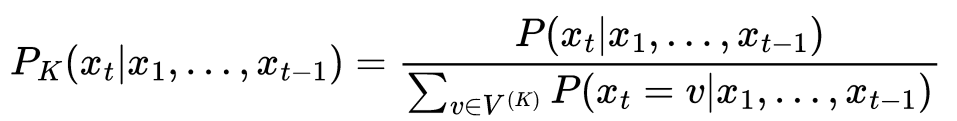
将概率分布重新缩放为总和为 1 的公式 [2]
以下是 top-k 采样的可视化k=4:
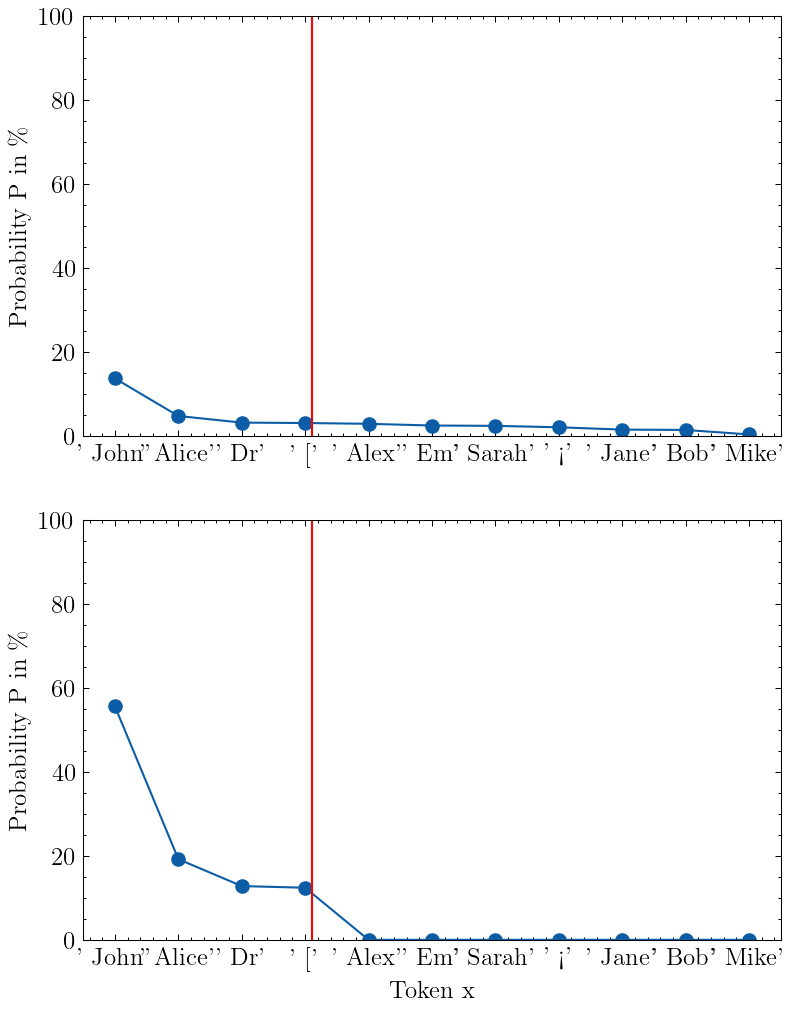
输入提示“我的名字是”的 top-k 采样(k=4)的可视化。上图显示了模型的输出概率,下图显示了 top-k 截断和重新缩放后的概率。图片来自作者
上图展示了模型的输出分布。我画了一条红线,将图分为左侧的 top-k 个 token 和右侧的其余部分。
P_K下图显示了截断和重新缩放后新的 top-k 分布。
Top-k 采样目前不是 OpenAI API 中的参数,但其他 API(例如Anthropic 的)确实有一个top_k参数。
top-k 抽样的一个问题是设置参数k。如果我们有一个非常尖锐的分布,我们希望有一个低值,k以避免在截断词汇表中包括大量极不可能的标记。但如果我们的分布非常平坦,我们希望有一个高值,k以包含大量合理的标记可能性。
Top-p 抽样
Top-p 采样(也称为核采样)是另一种随机解码方法,它通过从词汇表中删除不太可能的标记来截断概率分布。
OpenAI对top_p参数给出了如下定义:
温度采样的替代方法是核心采样,其中模型考虑具有 top_p 概率质量的标记的结果。因此 0.1 表示仅考虑包含前 10% 概率质量的标记。
在 top-p 抽样中,我们p为token 的累积概率质量定义一个阈值。从数学上讲,我们将(排序后的)概率与其累积概率相加。我们将所有 token 都包括在内,直到累积概率大于阈值p。
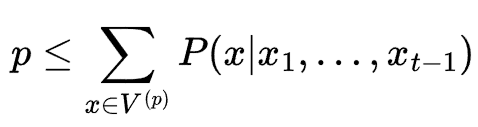
获取 top-p 抽样的 top-p 词汇表的公式 [2]
然后,我们将截断的概率重新调整为总和为 1 的新概率分布。
以下是使用 top-p 对提示“我喜欢”的可视化:
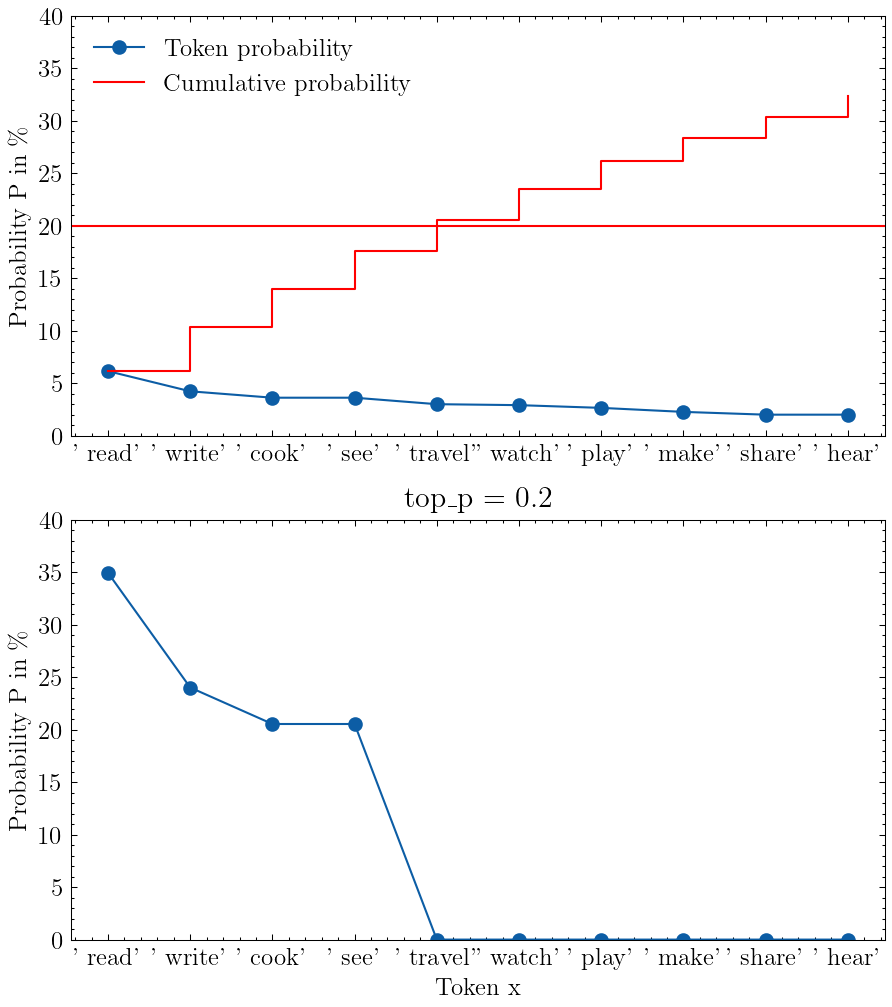
输入提示“I love to”的 top-p 采样可视化,其中 top_p=0.2。上图显示模型的输出概率,下图显示 top-p 截断和重新缩放后的概率。图片来自作者
上图显示了模型的输出分布,我在 20% 的阈值处画了一条红线,将图分为底部的 top-p 个 token 和顶部的其余 token。重新缩放后,下图显示我们只剩下 4 个 token,其余的 token 已被清零。
我认为从对数概率的长尾中删除极不可能的标记总是有意义的。因此,top_p应该始终小于1.0。
但 top-p 采样也并非完美。下图展示了 top-p 采样为了达到累积阈值而包含大量低概率 token 的情况。
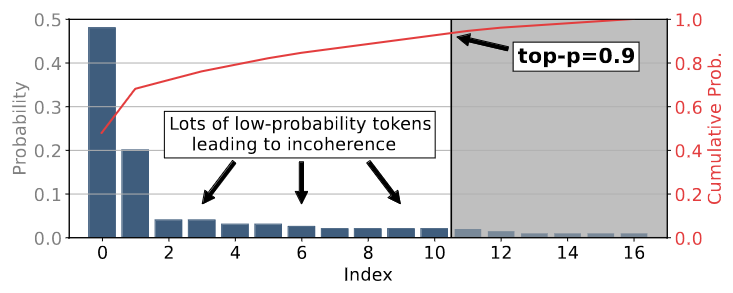
Top-p 采样可能包含太多低概率标记。图片取自 [1],CC BY 4.0许可
结合 Top-p 和温度
虽然我找不到 OpenAI 的任何官方文档,但根据社区测试, top_p似乎在temperature之前使用。
虽然 OpenAI 文档通常建议不要同时设置 top_p 和温度,但我认为这样做有充分的理由。
如果只改变温度参数,概率分布就会变得平坦或锐化。这会使输出更加确定(低温)或更具创造性(高温)。
但是,模型仍然会从概率分布中随机抽样。因此,模型总有可能抽取一个不太可能出现的 token。
例如,模型可能会采样外语中的字符。或者奇怪的 Unicode 字符。模型词汇表(现在非常大且多语言)中的任何内容都可以采样。
作为一种解决方案,top-p 采样可以首先消除这些随机令牌,以便更高温度可以从剩余的合理令牌池中创造性地进行采样。
最小p采样
有一种相对较新的采样方法,称为最小 p 采样,源自论文“最小 P 采样:高温下平衡创造力和连贯性”[1]。
Min-p 也是一种基于截断的随机解码方法,它尝试通过更动态的阈值 来解决 top-p 采样的问题p。
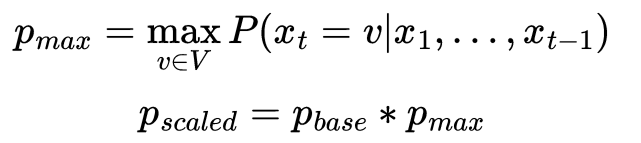
min-p采样动态最小阈值计算公式[1]
首先,我们从概率分布中的顶部标记中找到最大概率。 p_max
然后将此最大概率乘以一个参数,p_base得到最小阈值p_scaled。然后,我们对所有概率大于或等于的标记进行采样 p_scaled。最后,我们将截断概率重新调整为新的概率分布。
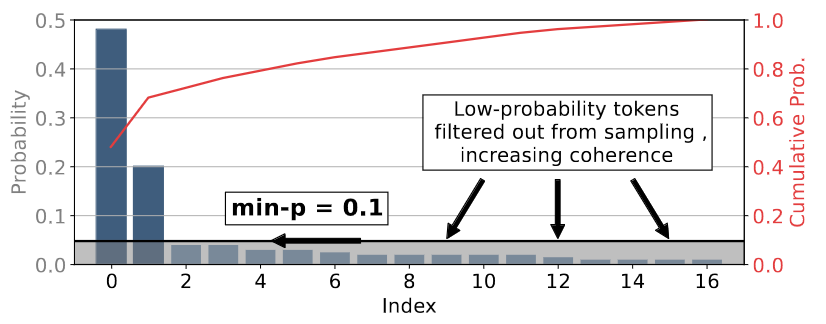
Min-p 采样使用相对最小概率。图片取自 [1],CC BY 4.0许可
Min-p 采样已经在一些后端实现,例如 VLLM 和 llama.cpp,我不会惊讶地看到它很快被添加到 OpenAI API 中。
我在下图中以p_base = 0.1“我喜欢读 a”作为输入提示,形象地展现了最小 p 采样。
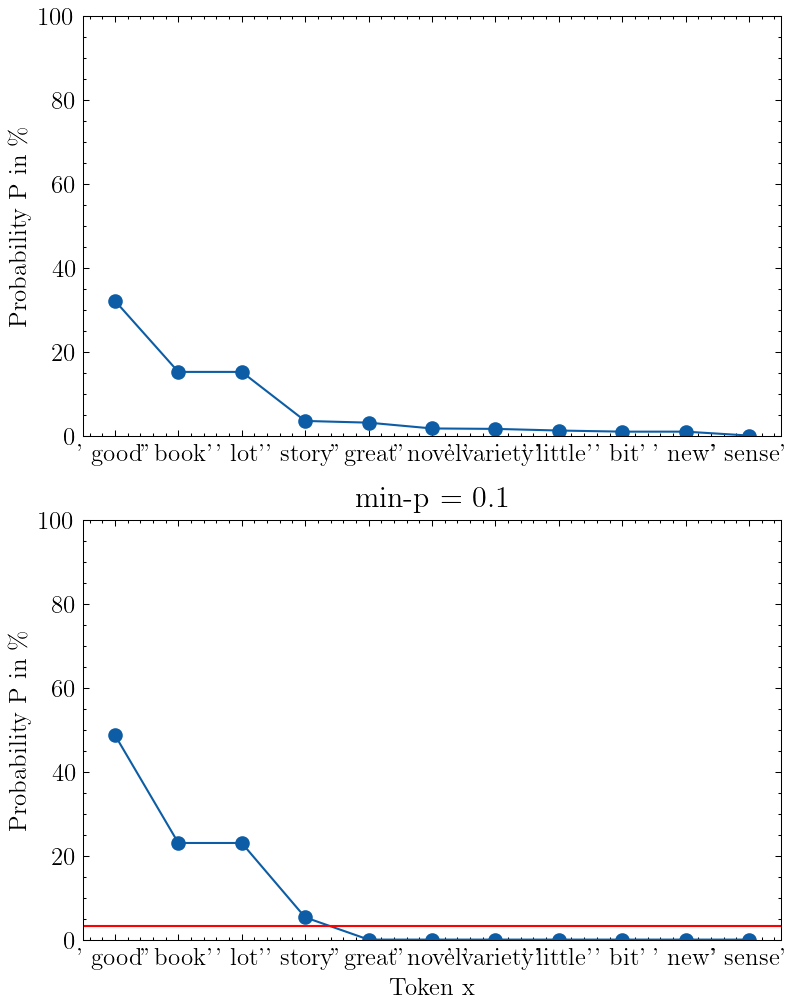
输入提示“我喜欢读 a”,p_base=0.1 的 min-p 采样可视化。上图显示模型的输出概率,下图显示 min-p 截断和重新缩放后的概率。图片来自作者
由于标记“好”的概率为 32%,并且我设置,p_base = 0.1我们得到的最小概率阈值为p_scaled = 3.2%,即图中的红线。
结论
现在我们确切地知道了采样参数的作用,我们可以尝试找到适合我们的 LLM 用例的值。
此时最重要的参数是温度和top_p。
温度参数使模型的输出概率平坦化或锐化。但是,总是有机会采样一个完全无意义的标记。最后,在给定概率分布的情况下,我们在采样下一个标记时仍然会掷骰子。
top_k 参数会截断概率分布,即从可能的候选集合中删除不太可能的标记。但是,如果我们运气不好,top_k 可能会删除太多好的候选,或者删除不够多的坏的候选。
感谢关注雲闪世界。(Aws解决方案架构师vs开发人员&GCP解决方案架构师vs开发人员)
订阅频道(https://t.me/awsgoogvps_Host)
TG交流群(t.me/awsgoogvpsHost)
这篇关于如何通过更好的采样参数来提高 LLM 响应率的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!


