llm专题
![[论文笔记]LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale](https://img-blog.csdnimg.cn/img_convert/172ed0ed26123345e1773ba0e0505cb3.png)
[论文笔记]LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale
引言 今天带来第一篇量化论文LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale笔记。 为了简单,下文中以翻译的口吻记录,比如替换"作者"为"我们"。 大语言模型已被广泛采用,但推理时需要大量的GPU内存。我们开发了一种Int8矩阵乘法的过程,用于Transformer中的前馈和注意力投影层,这可以将推理所需

LLM系列 | 38:解读阿里开源语音多模态模型Qwen2-Audio
引言 模型概述 模型架构 训练方法 性能评估 实战演示 总结 引言 金山挂月窥禅径,沙鸟听经恋法门。 小伙伴们好,我是微信公众号《小窗幽记机器学习》的小编:卖铁观音的小男孩,今天这篇小作文主要是介绍阿里巴巴的语音多模态大模型Qwen2-Audio。近日,阿里巴巴Qwen团队发布了最新的大规模音频-语言模型Qwen2-Audio及其技术报告。该模型在音频理解和多模态交互
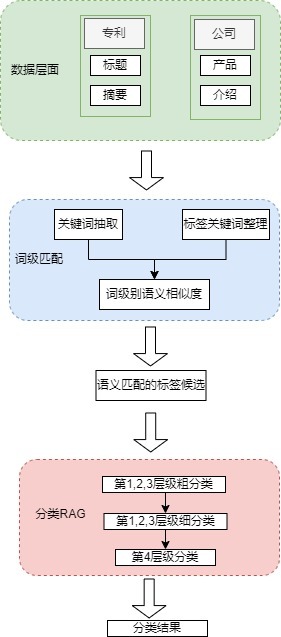
LLM应用实战: 产业治理多标签分类
数据介绍 标签体系 产业治理方面的标签体系共计200+个,每个标签共有4个层级,且第3、4层级有标签含义的概括信息。 原始数据 企业官网介绍数据,包括基本介绍、主要产品等 企业专利数据,包括专利名称和专利摘要信息,且专利的数据量大。 LLM选型 经调研,采用Qwen2-72B-Instruct-GPTQ-Int4量化版本,占用显存更少,且效果与非量化相当,

LLM大模型教程:langchain 教程
软件安装 pip install pymupdfpip install langchainpip install langchain-cliconda install -c pytorch -c nvidia faiss-gpu=1.7.4 mkl=2021 blas=1.0=mkl 由于langchain不支持qwen模型,我们需要自定义模型 from typing import A

LLM模型:代码讲解Transformer运行原理
视频讲解、获取源码:LLM模型:代码讲解Transformer运行原理(1)_哔哩哔哩_bilibili 1 训练保存模型文件 2 模型推理 3 推理代码 import torchimport tiktokenfrom wutenglan_model import WutenglanModelimport pyttsx3# 设置设备为CUDA(如果可用),否则使用CPU#
![[论文笔记] LLM大模型剪枝篇——2、剪枝总体方案](/front/images/it_default2.jpg)
[论文笔记] LLM大模型剪枝篇——2、剪枝总体方案
https://github.com/sramshetty/ShortGPT/tree/main My剪枝方案(暂定): 剪枝目标:1.5B —> 100~600M 剪枝方法: 层粒度剪枝 1、基于BI分数选择P%的冗余层,P=60~80 2、对前N%冗余层,

jmeter压力测试,通过LLM利用RAG实现知识库问答,NEO4J部署,GraphRAG以知识图谱在查询时增强提示实现更准确的知识库问答(9/7)
前言 这周也是杂七杂八的一天(高情商:我是一块砖,哪里需要往哪里搬),首先是接触了jemter这个压力测试工具,然后帮公司的AIGC项目编写使用手册和问答手册的第一版,并通过这个平台的智能体实现知识库问答的功能展示,以及部分个人扩展和思考(NEO4J创建知识图谱的GraphRAG)。 Jmeter Jmeter是一个压力测试工具,一开始导师叫我熟悉的时候我还说

下载量10w+!LLM经典《大型语言模型:语言理解和生成》pdf分享
介绍 近年来,人工智能在新语言能力方面取得了显著进展,深度学习技术的快速发展推动了语言AI系统在文本编写和理解方面的表现。这一趋势催生了许多新功能、产品和整个行业的兴起。 本书旨在为Python开发者提供实用工具和概念,帮助他们利用预训练的大型语言模型的能力,如拷贝写作、摘要等用例;构建高级的LLM流水线来聚类文本文档并探索主题;创建超越关键词搜索的语义搜索引擎;深入了解基础Transfo

深入解析五大 LLM 可视化工具:Langflow、Flowise、Dify、AutoGPT UI 和 AgentGPT
近年来,大语言模型(LLM)技术的迅猛发展推动了智能代理(Agent)应用的广泛应用。从任务自动化到智能对话系统,LLM 代理可以极大简化复杂任务的执行。为了帮助开发者更快地构建和部署这些智能代理,多个开源工具应运而生,尤其是那些提供可视化界面的工具,让开发者通过简单的图形界面设计、调试和管理智能代理。 本文将详细介绍五款热门的 LLM 可视化工具,分别是 Langflow、Flowise、Di

基于LangChain+LLM的相关技术研究及初步实践
01 概述 大模型概述 大模型是指具有大规模参数和复杂计算结构的机器学习模型。这些模型通常由深度神经网络构建而成,拥有数十亿甚至数千亿个参数。大模型的设计目的是为了提高模型的表达能力和预测性能,能够处理更加复杂的任务和数据。大模型在各种领域都有广泛的应用,包括自然语言处理、计算机视觉、语音识别和推荐系统等。大模型通过训练海量数据来学习复杂的模式和特征,具有更强大的泛化能力,可以对未见过的数据
[论文笔记] LLM大模型剪枝篇——1、调研
Attention Is All You Need But You Don’t Need All Of It For Inference of Large Language Models LLaMA2在剪枝时,跳过ffn和跳过full layer的效果差不多。相比跳过ffn/full layer,跳过attention layer的影响会更小。 跳过attention layer:7B/13B从

大牛书单 |LLM大模型方向好书推荐
我们已经加速进入了大模型的时代。以ChatGPT为首的一些超强模型服务,背后是百亿或千亿参数的基础模型,它们学到了丰富的世界知识,领悟了“与人类打交道”的门路,甚至开始连接和使用外部工具、成为“万物接口”。 新的时代有新的机会,与其担心AI将取代我们的工作,不如学会驾驭它!不远的未来,AI大模型或许将是人人可用、人人可开发。 本期大牛书单,我们请来了几位鹅厂同事,为大家推荐一些大模型相关的书籍
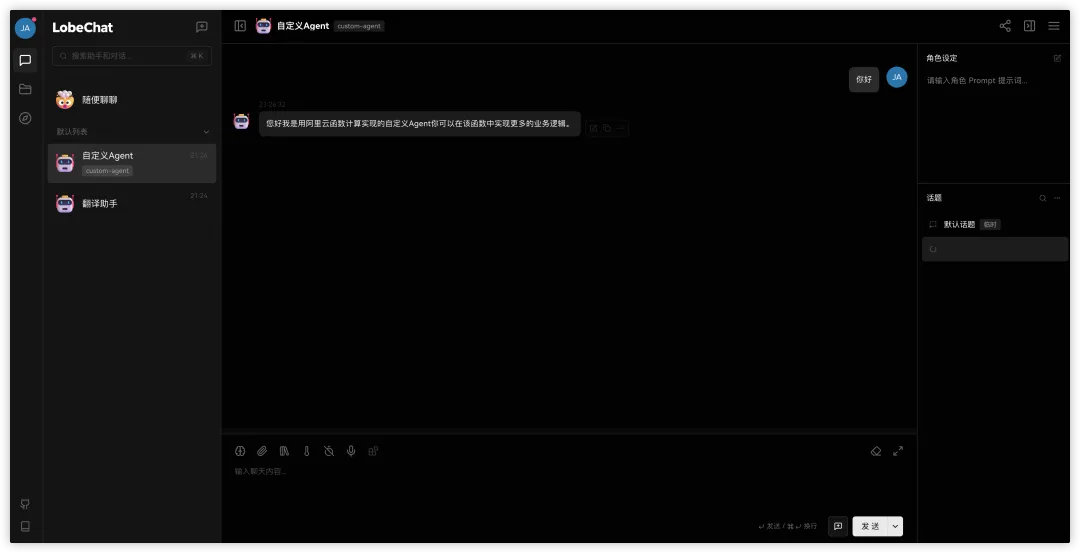
基于阿里云函数计算(FC)x 云原生 API 网关构建生产级别 LLM Chat 应用方案最佳实践
作者:计缘 LLM Chat 应用大家应该都不陌生,这类应用也逐渐称为了我们日常的得力助手,如果只是个人使用,那么目前市面上有很多方案可以快速的构建出一个LLM Chat应用,但是如果要用在企业生产级别的项目中,那对整体部署架构,使用组件的性能,健壮性,扩展性要求还是比较高的。本文带大家了解一下如何使用阿里云Serverless计算产品函数计算构建生产级别的LLM Chat应用。 该最佳实践会
![[最优化方法] 《最优化方法》个人问答式学习笔记 with LLM](https://i-blog.csdnimg.cn/direct/6d0179d218ce4971a16401b0d872f04b.png)
[最优化方法] 《最优化方法》个人问答式学习笔记 with LLM
《最优化方法》问答式学习笔记 with LLM 文章目录 《最优化方法》问答式学习笔记 with LLM写在前面每周提问的链接表格绪论 | 第一周 | [answer by 文心一言]Q1 请为我解释一下最优化方法研究的核心重点主要是哪些?一、问题定义与建模二、求解方法三、算法性能与优化四、应用领域与交叉学科 Q2 请为我分别解释一下L0,L1和L2范数。L0范数L1范数L2范数总结 Q3

小白入门LLM大模型最牛X教程------上交《动手学大模型应用开发》!
本项目是一个面向小白开发者的大模型应用开发教程,旨在结合个人知识库助手项目,通过一个课程完成大模型开发的重点入门,涵盖了大模型应用开发的方方面面,主要包括: 教程一共有七章内容: 《动手学大模型》是上海交大 更新的系列编程实践教程。从已经跟新的内容来看,侧重安全垂直方向。命名是向他们的学长李沐的《动手学深度学习》课程致敬。 感受下大纲、课件和教程风格: 微调与部署 提示学习与思维

NL2SQL:基于LLM的解决方案是最好的吗?
The Dawn of Natural Language to SQL: Are We Fully Ready? 将用户的日常语言问题转化为SQL查询(即nl2sql),极大地简化了我们与关系型数据库的互动。随着大型语言模型的崛起,nl2sql任务迎来了革新,其能力得到了显著提升。但这同时引出了一个核心议题:我们是否已经完全准备好将nl2sql模型应用于实际生产环境?为回应这一议题,我们推出了一

提升LLM结果:何时使用知识图谱RAG
通过知识图谱增强 RAG 可以帮助检索,使系统能够更深入地挖掘数据集以提供详细的响应。 有时,检索增强生成 (RAG) 系统无法深入文档集以找到所需的答案。我们可能会得到泛泛的或肤浅的回复,或者我们可能会得到回复,其中 RAG 系统检索到的细节很少,然后用不相关或不正确的信息填补空白——这被称为“幻觉”。 深度知识库和文档集可能包含我们用 RAG 提示回答问题所需的所有信息,但 RAG 系统

GraphRAG:LLM之使用neo4j可视化GraphRAG运行结果
前言 微软开源的GraphRAG是真的不好用,起码现在是,太多吐槽点了 如果你没有安装好GraphRAG,请看我的这篇文章: GraphRAG:LLM之本地部署GraphRAG(GLM-4+Xinference的embedding模型)(附带ollma部署方式 然后你需要安装docker: Docker之基于Ubuntu安装 Neo4j 还是不说简介,有空再补 Neo4j Dcoc

教育LLM—大型教育语言模型: 调查,原文阅读:Large Language Models for Education: A Survey
Large Language Models for Education: A Survey 大型教育语言模型: 调查 paper: https://arxiv.org/abs/2405.13001 文章目录~ 原文阅读Abstract1 Introduction2 Characteristics of LLM in Education2.1.Characteristics of LLM

九银十拿到大模型(LLM)offer,面试八股
金九银十拿到大模型(LLM)offer,面试八股 从事大模型的朋友在 金J九银十拿到了一份不错的offer,面试十几家公司,通过了六家。好在分享了大佬总结的大模型方向面试的常见题目(含答案),短时间内过了一边,能针对的回答。有了面试框架更容易拿到offer,分享给大家,祝大家都能拿到自己心仪的offer

【LLM大模型深度解析】LlamaIndex的高阶概念详解
本篇内容为您快速介绍在构建基于大型语言模型(LLM)的应用程序时会频繁遇到的一些核心概念。 增强检索生成(RAG) LLM 是基于海量数据训练而成,但并未涵盖您的具体数据。增强检索生成(Retrieval-Augmented Generation, RAG)通过将您的数据添加至 LLM 已有的数据集中,解决了这一问题。在本文档中,您将频繁看到对 RAG 的引用。 在 RAG 中,您的数据被加
LLM代码实现-Qwen(挂载知识库)
为什么要挂载知识库? LLM 在回答用户的问题时可能会产生幻觉,或者由于训练数据中不包含用户想要的内容而无法回答,通常情况下我们可以选择微调模型或者外挂知识库来缓解这类问题。微调模型的对数据和算力都有一定的要求,而知识库的门槛会更低一些,所以通常情况下会选择外挂知识库高效地来解决这类问题。 挂载知识库其实相当于引入外部知识,为了扩展语言模型以减少歧义,从大型文本数据库中检索相关文档。通常将输入

论文速读|ROS-LLM:具有任务反馈和结构化推理的具身智能ROS 框架
论文地址:https://arxiv.org/pdf/2406.19741 ROS-LLM 框架旨在通过集成大型语言模型(LLM)和机器人操作系统(ROS),实现对机器人的直观编程。该框架支持通过聊天界面接收自然语言提示,并能够根据 ROS 环境中的传感器读数自动提取和执行行为。框架支持三种行为模式:序列、行为树和状态机。此外,通过模仿学习,用户可以向系统添加新的机器人动作。该研究通过实验

LLM指令微调实践与分析
重磅推荐专栏: 《大模型AIGC》 《课程大纲》 《知识星球》 本专栏致力于探索和讨论当今最前沿的技术趋势和应用领域,包括但不限于ChatGPT和Stable Diffusion等。我们将深入研究大型模型的开发和应用,以及与之相关的人工智能生成内容(AIGC)技术。通过深入的技术解析和实践经验分享,旨在帮助读者更好地理解和应用这些领域的最新进展 指令微调的代码实践 代码示例
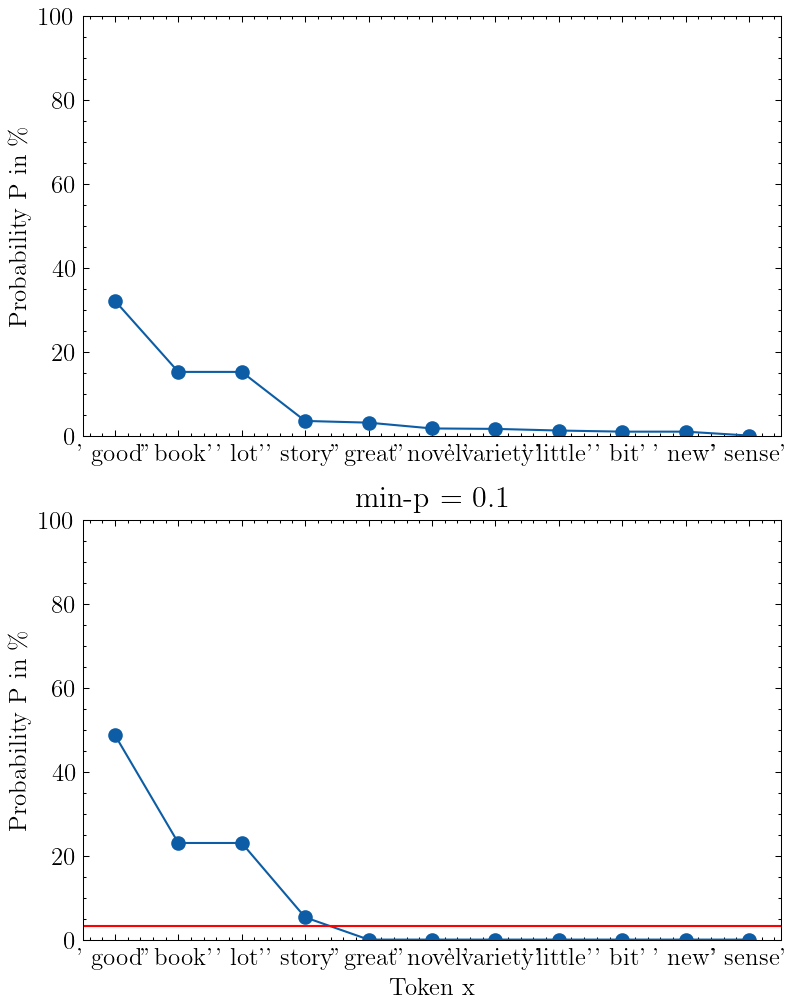
如何通过更好的采样参数来提高 LLM 响应率
深入研究使用温度、top_p、top_k 和 min_p 进行随机解码 当你向大型语言模型 (LLM) 提出问题时,该模型会输出其词汇表中每个可能标记的概率。 从该概率分布中抽取一个标记后,我们可以将选定的标记附加到我们的输入提示中,以便 LLM 可以输出下一个标记的概率。 temperature该采样过程可以通过著名的和等参数来控制top_p。 在本文中,我将解释并直观地展示定义 LLM