本文主要是介绍重复采样魔法:用更多样本击败单次尝试的最强模型,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
这篇文章探讨了通过增加生成样本的数量来扩展大型语言模型(LLMs)在推理任务中的表现。
研究发现,重复采样可以显著提高模型的覆盖率,特别是在具有自动验证工具的任务中。研究还发现,覆盖率与样本数量之间的关系可以用指数幂律建模,揭示了推理时间的扩展规律。尽管多数投票和奖励模型在样本数量增加时趋于饱和,但在没有自动验证工具的任务中,识别正确样本仍然是一个重要的研究方向。
总体而言,重复采样提供了一种有效的方法来增强较弱模型的能力,并在某些情况下比使用更强大、更昂贵的模型更具成本效益。
论文:Large Language Monkeys: Scaling Inference Compute with Repeated Sampling
链接:https://arxiv.org/pdf/2407.21787
研究背景
研究问题:这篇文章探讨了如何通过增加生成样本的数量来扩展推理计算,从而提高大型语言模型(LLMs)在推理任务中的表现。具体来说,研究了重复采样作为一种扩展推理计算的方法,以提高模型的覆盖率和精度。
研究难点:该问题的研究难点包括:如何在有限的预算内提高覆盖率,如何在不具备自动验证工具的任务中识别正确的样本,以及如何在性能和成本之间找到平衡。
相关工作:相关研究表明,通过扩展训练计算量可以显著提高LLMs的能力。然而,在推理阶段,用户和开发者通常限制模型只进行一次尝试。已有工作表明,重复采样在数学、编程和拼图解决设置中可以提高性能。
研究方法
这篇论文提出了通过重复采样来扩展推理计算,以提高LLMs的性能。具体来说,
重复采样过程:首先,通过从LLM中采样生成许多候选解决方案。然后,使用领域特定的验证器(例如代码的单位测试)从生成的样本中选择最终答案。
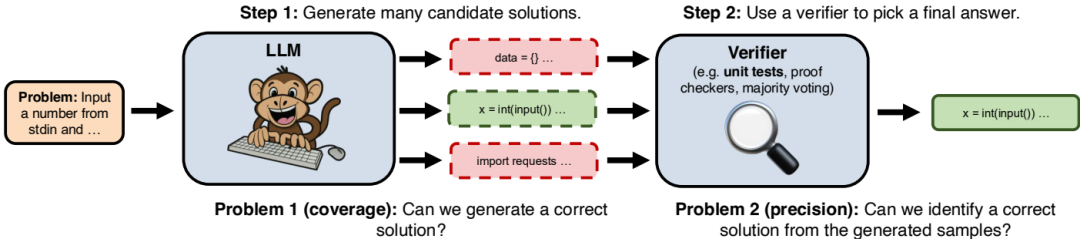
覆盖率和精度:重复采样的有效性取决于两个关键属性:覆盖率和精度。覆盖率是指通过生成样本能够解决问题的比例;精度是指在需要从多个样本中选择最终答案的情况下,能否识别出正确样本。
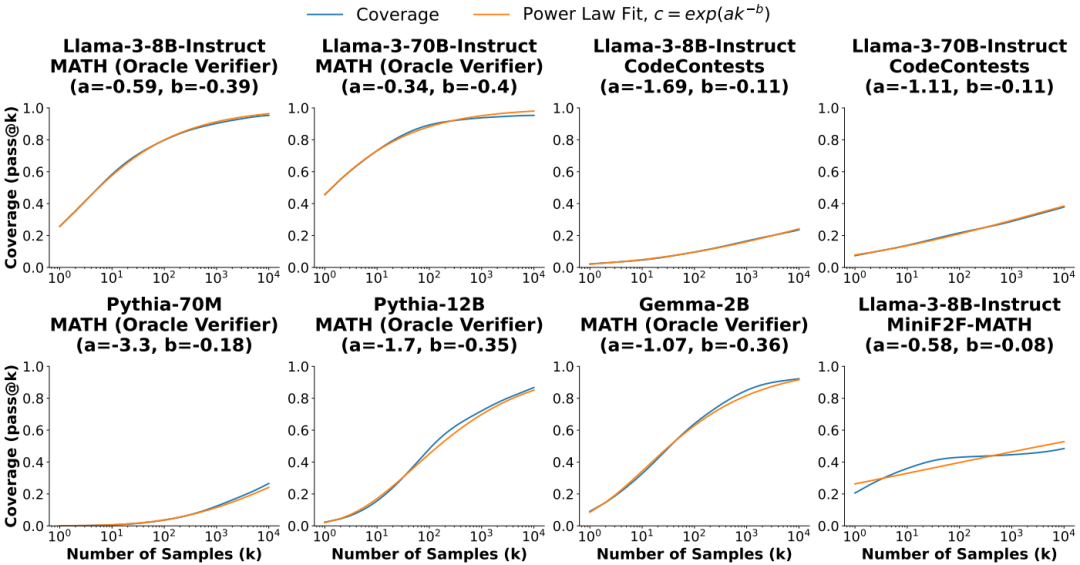
覆盖率的建模:研究发现,覆盖率与样本数量之间的关系通常可以用指数幂律建模,即:
其中,a 和 b 是拟合的模型参数。通过对数变换,最终的模型为:
这表明推理时间的扩展规律可能存在。
实验设计
任务和模型:实验涵盖了五个任务:GSM8K、MATH、MiniF2F-MATH、CodeContests和SWE-bench Lite。使用了多个模型家族,包括Llama 3、Gemma和Pythia。
数据集:GSM8K和MATH是数学单词问题数据集,MiniF2F-MATH是形式化数学问题的数据集,CodeContests是编程竞赛问题数据集,SWE-bench Lite是GitHub实际问题的数据集。
采样策略:在每个任务中,每个问题生成10,000个独立样本。对于SWE-bench Lite,由于所需的上下文长度超过了Llama 3模型的极限,使用了DeepSeek-V2-Coder-Instruct模型,并限制了每个问题的尝试次数为250次。
验证工具:在具有自动验证工具的任务中(如Lean证明检查和单元测试),直接使用这些工具来评估覆盖率。在没有自动验证工具的任务中(如GSM8K和MATH),使用多数投票和奖励模型来选择最终答案。
结果与分析
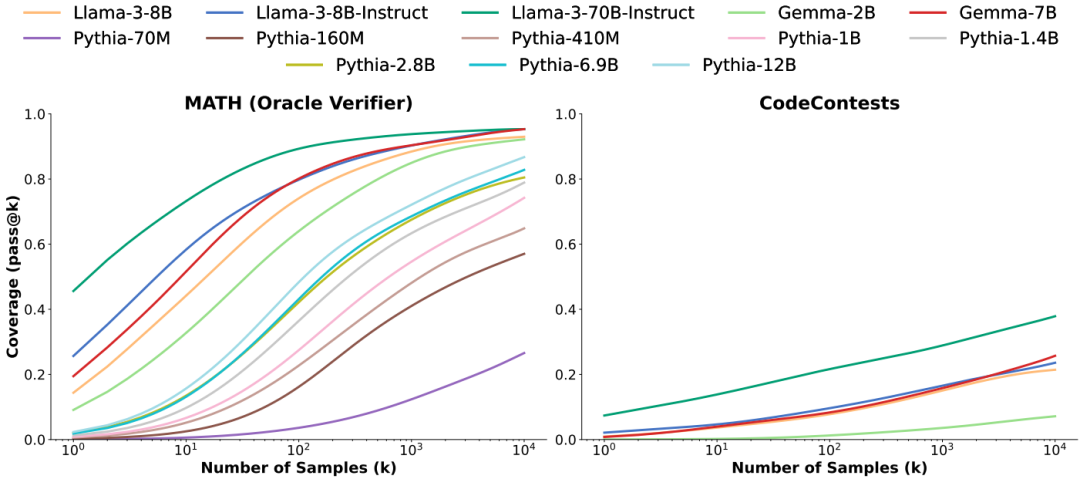
覆盖率提升:在所有任务中,随着样本数量的增加,覆盖率平滑提升。例如,在使用Gemma-2B模型解决CodeContests问题时,覆盖率从10,000次尝试的0.02%提高到7.1%。
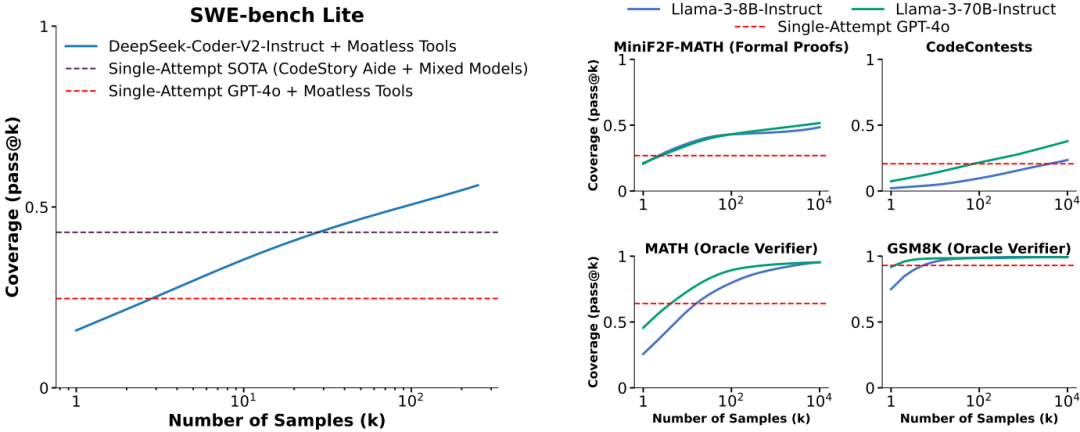
模型大小和家族的广泛适用性:重复采样在不同模型大小、家族和训练水平上均表现出覆盖率提升。较小的模型在应用重复采样时显示出更显著的覆盖率提升。
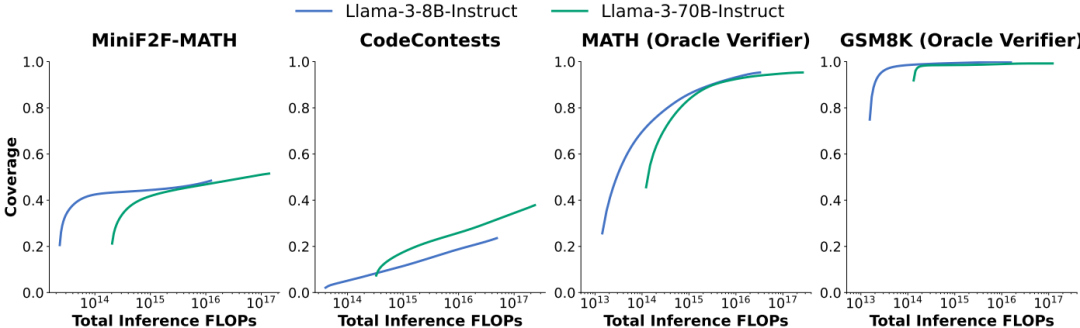
性能和成本平衡:通过重复采样,较弱的模型可以在成本和性能之间取得更好的平衡。例如,使用DeepSeek-V2-Coder-Instruct模型进行SWE-bench Lite问题的重复采样,比使用GPT-4o或Claude 3.5 Sonnet模型单次尝试更经济高效。
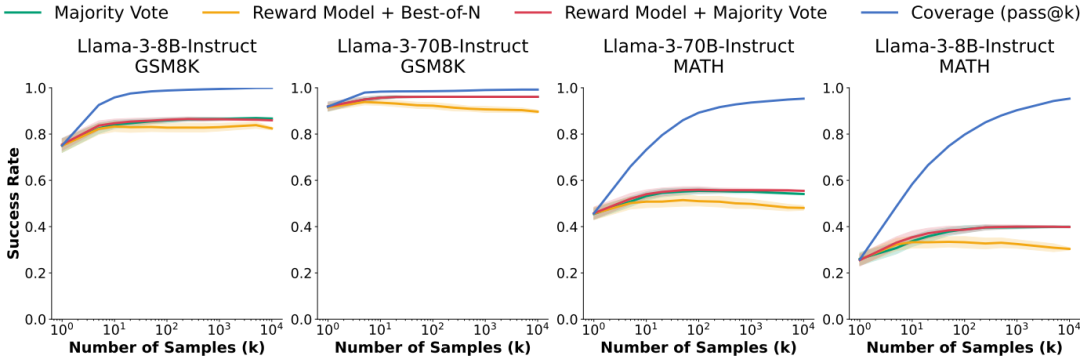
验证方法的局限性:在GSM8K和MATH任务中,多数投票和奖励模型在样本数量超过100后趋于饱和,未能完全随样本预算扩展。
总体结论
这篇论文展示了通过重复采样扩展推理计算可以显著提高LLMs的性能,特别是在具有自动验证工具的任务中。研究结果表明,覆盖率与样本数量之间的关系可以用指数幂律建模,不同模型家族内的覆盖率曲线具有相似的形状。此外,尽管多数投票和奖励模型在样本数量增加时趋于饱和,但在没有自动验证工具的任务中,识别正确样本仍然是一个重要的研究方向。总体而言,重复采样提供了一种有效的方法来增强较弱模型的能力,并在某些情况下比使用更强大、更昂贵的模型更具成本效益。
AI辅助人工完成。
备注:昵称-学校/公司-方向/会议(eg.ACL),进入技术/投稿群

id:DLNLPer,记得备注呦
这篇关于重复采样魔法:用更多样本击败单次尝试的最强模型的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








