数据结构专题

C#数据结构之字符串(string)详解
《C#数据结构之字符串(string)详解》:本文主要介绍C#数据结构之字符串(string),具有很好的参考价值,希望对大家有所帮助,如有错误或未考虑完全的地方,望不吝赐教... 目录转义字符序列字符串的创建字符串的声明null字符串与空字符串重复单字符字符串的构造字符串的属性和常用方法属性常用方法总结摘

Go语言中三种容器类型的数据结构详解
《Go语言中三种容器类型的数据结构详解》在Go语言中,有三种主要的容器类型用于存储和操作集合数据:本文主要介绍三者的使用与区别,感兴趣的小伙伴可以跟随小编一起学习一下... 目录基本概念1. 数组(Array)2. 切片(Slice)3. 映射(Map)对比总结注意事项基本概念在 Go 语言中,有三种主要

【数据结构】——原来排序算法搞懂这些就行,轻松拿捏
前言:快速排序的实现最重要的是找基准值,下面让我们来了解如何实现找基准值 基准值的注释:在快排的过程中,每一次我们要取一个元素作为枢纽值,以这个数字来将序列划分为两部分。 在此我们采用三数取中法,也就是取左端、中间、右端三个数,然后进行排序,将中间数作为枢纽值。 快速排序实现主框架: //快速排序 void QuickSort(int* arr, int left, int rig

6.1.数据结构-c/c++堆详解下篇(堆排序,TopK问题)
上篇:6.1.数据结构-c/c++模拟实现堆上篇(向下,上调整算法,建堆,增删数据)-CSDN博客 本章重点 1.使用堆来完成堆排序 2.使用堆解决TopK问题 目录 一.堆排序 1.1 思路 1.2 代码 1.3 简单测试 二.TopK问题 2.1 思路(求最小): 2.2 C语言代码(手写堆) 2.3 C++代码(使用优先级队列 priority_queue)

《数据结构(C语言版)第二版》第八章-排序(8.3-交换排序、8.4-选择排序)
8.3 交换排序 8.3.1 冒泡排序 【算法特点】 (1) 稳定排序。 (2) 可用于链式存储结构。 (3) 移动记录次数较多,算法平均时间性能比直接插入排序差。当初始记录无序,n较大时, 此算法不宜采用。 #include <stdio.h>#include <stdlib.h>#define MAXSIZE 26typedef int KeyType;typedef char In

【408数据结构】散列 (哈希)知识点集合复习考点题目
苏泽 “弃工从研”的路上很孤独,于是我记下了些许笔记相伴,希望能够帮助到大家 知识点 1. 散列查找 散列查找是一种高效的查找方法,它通过散列函数将关键字映射到数组的一个位置,从而实现快速查找。这种方法的时间复杂度平均为(
浙大数据结构:树的定义与操作
四种遍历 #include<iostream>#include<queue>using namespace std;typedef struct treenode *BinTree;typedef BinTree position;typedef int ElementType;struct treenode{ElementType data;BinTree left;BinTre

Python 内置的一些数据结构
文章目录 1. 列表 (List)2. 元组 (Tuple)3. 字典 (Dictionary)4. 集合 (Set)5. 字符串 (String) Python 提供了几种内置的数据结构来存储和操作数据,每种都有其独特的特点和用途。下面是一些常用的数据结构及其简要说明: 1. 列表 (List) 列表是一种可变的有序集合,可以存放任意类型的数据。列表中的元素可以通过索
浙大数据结构:04-树7 二叉搜索树的操作集
这道题答案都在PPT上,所以先学会再写的话并不难。 1、BinTree Insert( BinTree BST, ElementType X ) 递归实现,小就进左子树,大就进右子树。 为空就新建结点插入。 BinTree Insert( BinTree BST, ElementType X ){if(!BST){BST=(BinTree)malloc(sizeof(struct TNo

【数据结构入门】排序算法之交换排序与归并排序
前言 在前一篇博客,我们学习了排序算法中的插入排序和选择排序,接下来我们将继续探索交换排序与归并排序,这两个排序都是重头戏,让我们接着往下看。 一、交换排序 1.1 冒泡排序 冒泡排序是一种简单的排序算法。 1.1.1 基本思想 它的基本思想是通过相邻元素的比较和交换,让较大的元素逐渐向右移动,从而将最大的元素移动到最右边。 动画演示: 1.1.2 具体步

数据结构:线性表的顺序存储
文章目录 🍊自我介绍🍊线性表的顺序存储介绍概述例子 🍊顺序表的存储类型设计设计思路类型设计 你的点赞评论就是对博主最大的鼓励 当然喜欢的小伙伴可以:点赞+关注+评论+收藏(一键四连)哦~ 🍊自我介绍 Hello,大家好,我是小珑也要变强(也是小珑),我是易编程·终身成长社群的一名“创始团队·嘉宾” 和“内容共创官” ,现在我来为大家介绍一下有关物联网-嵌入
![[数据结构]队列之顺序队列的类模板实现](/front/images/it_default2.jpg)
[数据结构]队列之顺序队列的类模板实现
队列是一种限定存取位置的线性表,允许插入的一端叫做队尾(rear),允许删除的一端叫做队首(front)。 队列具有FIFO的性质 队列的存储表示也有两种方式:基于数组的,基于列表的。基于数组的叫做顺序队列,基于列表的叫做链式队列。 一下是基于动态数组的顺序队列的模板类的实现。 顺序队列的抽象基类如下所示:只提供了接口和显式的默认构造函数和析构函数,在派生类中调用。 #i
[数据结构]栈之链式栈的类模板实现
栈的抽象基类的实现:(不用抽象基类也是可以的,为了使用虚函数方便) #ifndef STACK#define STACK//栈的抽象基类template<class T>class Stack{public:Stack(){}~Stack(){}virtual void Push(const T& x)=0;virtual bool Pop(T& x)=0;virtual b
[数据结构]栈之顺序栈的类模板实现
栈的数组实现形式,采用动态分配数组,不够时可以调整栈的大小。 Stack.h文件:主要定义栈的抽象基类,提供公共的接口函数。 #ifndef STACK#define STACK//栈的抽象基类template<class T>class Stack{public:Stack(){}~Stack(){}virtual void Push(const T& x)=0;virt
[数据结构]线性表之单链表的类模板实现
类的具体实现如下: /#include"LinearList.h"#include <iostream>#include <cstdlib>using namespace std;template<class T>struct LinkNode //链表节点类{T data;LinkNode<T>* link;LinkNode(LinkNode<T>* ptr=NULL):
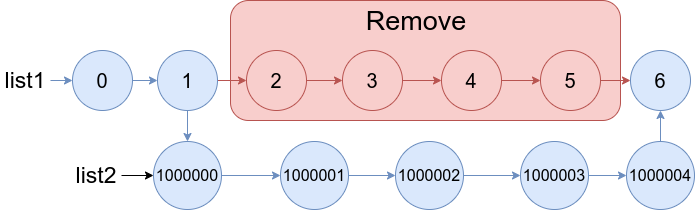
【数据结构与算法 | 灵神题单 | 删除链表篇】力扣3217, 82, 237
总结,删除链表节点问题使用到列表,哈希表,递归比较容易超时,我觉得使用计数排序比较稳,处理起来也不是很难。 1. 力扣3217:从链表中移除在数组中的节点 1.1 题目: 给你一个整数数组 nums 和一个链表的头节点 head。从链表中移除所有存在于 nums 中的节点后,返回修改后的链表的头节点。 示例 1: 输入: nums = [1,2,3], head = [1,2,3,

Java-数据结构-栈和队列-Stack和Queue (o゚▽゚)o
文本目录: ❄️一、栈(Stack): ▶ 1、栈的概念: ▶ 2、栈的使用和自实现: ☑ 1)、Stack(): ☑ 2)、push(E e): ☑ 3)、empty(): ☑ 4)、peek(E e): ☑ 5)、pop(E e): ☑ 6)、size(E e): ▶ 3、栈自实现的总代
数据结构--二叉树(C语言实现,超详细!!!)
文章目录 二叉树的概念代码实现二叉树的定义创建一棵树并初始化组装二叉树前序遍历中序遍历后序遍历计算树的结点个数求二叉树第K层的结点个数求二叉树高度查找X所在的结点查找指定节点在不在完整代码 二叉树的概念 二叉树(Binary Tree)是数据结构中一种非常重要的树形结构,它的特点是每个节点最多有两个子节点,通常称为左子节点和右子节点。这种结构使得二叉树在数据存储和查找等方面具
数据结构中抽象数据类型如何实现?
抽象数据类型可以通过固有的数据类型(如整形,实型,字符型等)来表示和实现。 即利用处理器中已存在的数据类型来说明新的结构,用已经实现的操作来组合新的操作。 用类c语言(介于伪码和c语言之间)作为描述工具。 例如:抽象数据类型“复数”的实现 typedef sturt{ float realpart; //实部

C语言-数据结构 克鲁斯卡尔算法(Kruskal)邻接矩阵存储
相比普里姆算法来说,克鲁斯卡尔的想法是从边出发,不管是理解上还是实现上都更简单,实现思路:我们先把找到所有边存到一个边集数组里面,并进行升序排序,然后依次从里面取出每一条边,如果不存在回路,就说明可以取,否则就跳过去看下一条边。其中看是否是回路这个操作利用到了并查集,就是判断新加入的这条边的两个顶点是否在同一个集合中,如果在就说明产生回路,如果没在同一个集合那么说明没有回路可以加入

算法复杂度 —— 数据结构前言、算法效率、时间复杂度、空间复杂度、常见复杂度对比、复杂度算法题(旋转数组)
目录 一、数据结构前言 1、数据结构 2、算法 3、学习方法 二、 算法效率 引入概念:算法复杂度 三、时间复杂度 1、大O的渐进表示法 2、时间复杂度计算示例 四、空间复杂度 计算示例:空间复杂度 五、常见复杂度对比 六、复杂度算法题(旋转数组) 1、思路1 2、思路2 3、思路3 一、数据结构前言 1、数据结构 数据结构(D
![[数据结构] 哈希结构的哈希冲突解决哈希冲突](https://i-blog.csdnimg.cn/direct/b5e222d58577426588b1442d6c7cb63e.png)
[数据结构] 哈希结构的哈希冲突解决哈希冲突
标题:[C++] 哈希结构的哈希冲突 && 解决哈希冲突 @水墨不写bug 目录 一、引言 1.哈希 2.哈希冲突 3.哈希函数 二、解决哈希冲突 1.闭散列 I,线性探测 II,二次探测 2.开散列 正文开始: 一、引言 哈希表是一种非常实用而且好用的关联式容器,如果你刷过不少题,

数据结构——双链表实现和注释浅解
关于双链表的基础部分增删查改的实现和一点理解,写在注释里~ 前言 浅记 1. 哨兵位的节点不能被删除,节点的地址也不能发生改变,所以是传一级指针 2. 哨兵位并不存储有效数据,所以它并不是有效节点 3. 双向链表为空时,说明只剩下一个头节点(哨兵位) List.h #pragma once#include<
数据结构基础(栈,队列,数组,链表,树)
栈:后进先出,先进后出 队列:先进先出,后进后出 数组:查询速度快,通过地址值和索引定位,查询任意数据消耗时长相同,在内存中是连续存储的,删除效率低,要将原始数据删除,然后后面的数据前移,添加效率低,添加索引位置的元素,剩下的都需要向前后移动 链表:节点的存储位置(地址)里面存储本身的数据值,和下一个节点的地址值,链表中的节点是独立对象,在内存中是不连续的。查询速度慢,无论查询哪个数据都要从

浙大数据结构:02-线性结构4 Pop Sequence
这道题我们采用数组来模拟堆栈和队列。 简单说一下大致思路,我们用栈来存1234.....,队列来存输入的一组数据,栈与队列进行匹配,相同就pop 机翻 1、条件准备 stk是栈,que是队列。 tt指向的是栈中下标,front指向队头,rear指向队尾。 初始化栈顶为0,队头为0,队尾为-1 #include<iostream>using namespace std;#defi