sota专题

自动驾驶真正踏出迈向“用户”的第一步:IROS24新SOTA提出个性化的实例迁移模仿学习
导读: 本文针对自动驾驶规划任务,提出了一种基于实例的迁移模仿学习方法,通过预先训练的微调框架从专家域迁移专业知识,以解决用户域数据稀缺问题。实验结果显示,该方法能有效捕捉用户驾驶风格并实现具有竞争力的规划性能,但仍需开发合适的用户风格测量方法。©️【深蓝AI】编译 1. 摘要 个性化运动规划在自动驾驶领域中具有重要意义,可以满足个人用户的独特需求。然而,以往的工作在同时解决两个关键问题

【CVPR‘24】BP-Net:用于深度补全的双边传播网络,新 SOTA!
【CVPR'24】BP-Net:用于深度补全的双边传播网络,新 SOTA! 摘要介绍方法1. 总体架构2. 双边传播模块(Bilateral Propagation Module)深度参数化参数生成先验编码 3. 多模态融合(Multi-modal Fusion)4. 深度细化(Depth Refinement)5. 损失函数 结果与分析结论 论文地址:https://arxiv.

勇夺三项SOTA!北航爱诗科技联合发布灵活高效可控视频生成方法TrackGo!
论文链接:https://arxiv.org/pdf/2408.11475 项目链接:https://zhtjtcz.github.io/TrackGo-Page/ ★ 亮点直击 本文引入了一种新颖的运动可控视频生成方法,称为TrackGo。该方法为用户提供了一种灵活的运动控制机制,通过结合 masks 和箭头,实现了在复杂场景中的精确操控,包括涉及多个对象、细粒度对象部件和复

YOLOv9基础 | 实时目标检测新SOTA,手把手带你深度解析yolov9论文!
前言:Hello大家好,我是小哥谈。YOLOv9是Chien-Yao Wang等人提出的YOLO系列的最新版本之一(截止到目前,YOLOv10已发布),于2024年2月21日发布。它是 YOLOv7的改进版本,两者均由Chien-Yao Wang及其同事开发。本节课就以YOLOv9论文为基础带大家深入解析YOLOv9算法。🌈 目录 🚀1.算法介绍 🚀2.论文解析
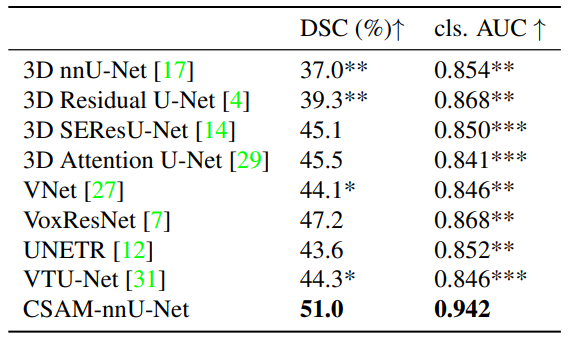
交叉注意力一脚踹进医学图像分割!新成果精度、效率表现SOTA
为解决传统方法的局限性,研究者们提出了将交叉注意力机制应用于医学图像分割。 交叉注意力机制能更有效地整合来自不同模态/尺度的特征,让模型同时捕捉全局和局部信息,加速学习并减少干扰。这样不仅可以提高分割的精度,还可以减少训练时间,提高分割的效率。 因此这种策略成为了目前医学图像领域的重要研究方向,为我们实现更高的综合性能提供了新的解决思路。 本次分享8种最新的用交叉注意力做医学图像分割的创新方
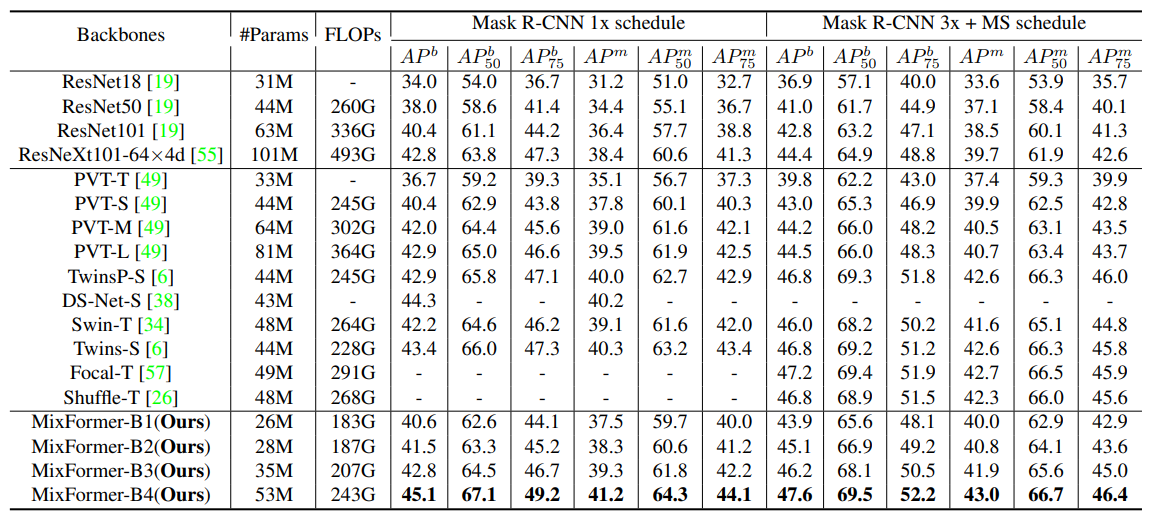
自注意力与卷积高效融合!多SOTA、兼顾低成本与高性能
在自注意力机制中,模型计算输入序列中不同位置的相关性得分,以生成连接权重,从而关注序列中的重要部分。而卷积通过滑动窗口的方式,在输入上应用相同权重矩阵来提取局部特征。 如果将以上两者结合,就可以同时利用自注意力捕捉长距离依赖关系和卷积运算提取局部特征的能力,让模型更全面地理解输入数据(特别是在处理复杂任务时),实现更高的性能和更低的计算成本。比如典型案例X-volution与ACmix。 目前

超高清图像生成新SOTA!清华唐杰教授团队提出Inf-DiT:生成4096图像比UNet节省5倍内存。
清华大学唐杰教授团队最近在生成超高清图像方面的新工作:Inf-DiT,通过提出一种单向块注意力机制,能够在推理过程中自适应调整内存开销并处理全局依赖关系。基于此模块,该模型采用了 DiT 结构进行上采样,并开发了一种能够上采样各种形状和分辨率的无限超分辨率模型。与常用的 UNet 结构相比,Inf-DiT 在生成 4096×4096 图像时可以节省超过 5 倍的内存。该模型在机器和人类评估中均实现
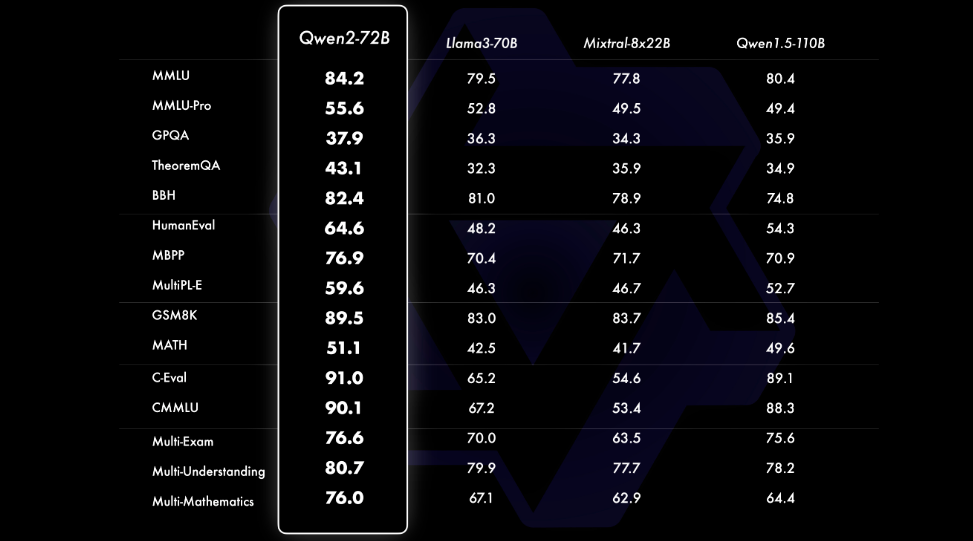
Qwen2——阿里巴巴最新的多语言模型挑战 Llama 3 等 SOTA
引言 经过几个月的期待, 阿里巴巴 Qwen 团队终于发布了 Qwen2 – 他们强大的语言模型系列的下一代发展。 Qwen2 代表了一次重大飞跃,拥有尖端的进步,有可能将其定位为 Meta 著名的最佳替代品 骆驼3 模型。在本次技术深入探讨中,我们将探讨使 Qwen2 成为大型语言模型 (LLM) 领域强大竞争者的关键功能、性能基准和创新技术。 Qwen2 型号系列 核心是 Qwen2

大模型领域最新算法SOTA核心技末要点总结
Hi~!这里是奋斗的小羊,很荣幸您能阅读我的文章,诚请评论指点,欢迎欢迎 ~~ 💥💥个人主页:奋斗的小羊 💥💥所属专栏:C语言 🚀本系列文章为个人学习笔记,在这里撰写成文一为巩固知识,二为展示我的学习过程及理解。文笔、排版拙劣,望见谅。 目录 大模型领域最新算法SOTA核心技末要点总结自注意力机制(Self-Attention Mechanism)迁移学习(T

发布会后苹果股价创历史新高;商汤 Embedding 模型拿下 SOTA丨 RTE 开发者日报 Vol.223
开发者朋友们大家好: 这里是 「RTE 开发者日报」 ,每天和大家一起看新闻、聊八卦。我们的社区编辑团队会整理分享 RTE(Real-Time Engagement) 领域内「有话题的 新闻 」、「有态度的 观点 」、「有意思的 数据 」、「有思考的 文章 」、「有看点的 会议 」,但内容仅代表编辑的个人观点,欢迎大家留言、跟帖、讨论。 本期编辑:@CY,@JLT,@鲍勃 01 有话题的
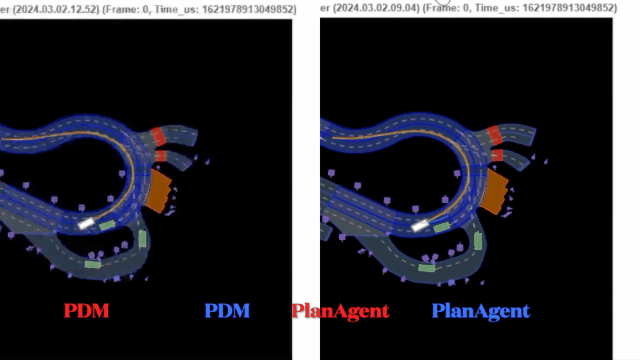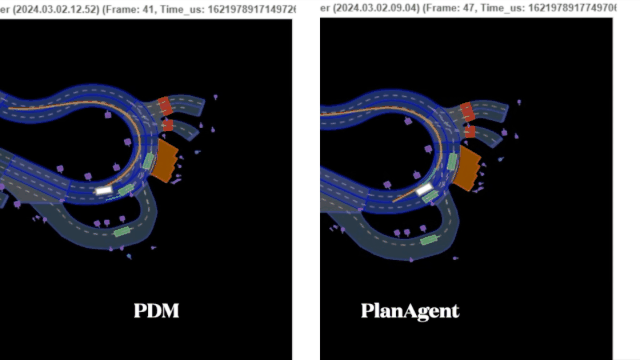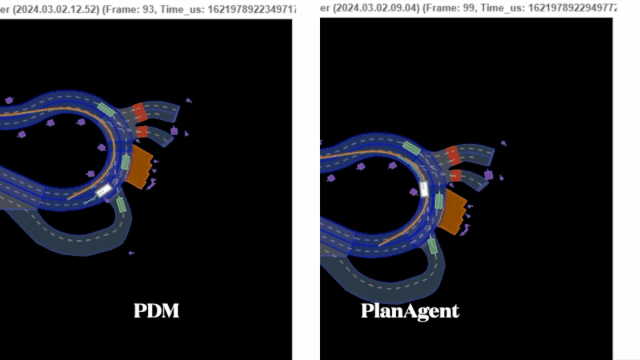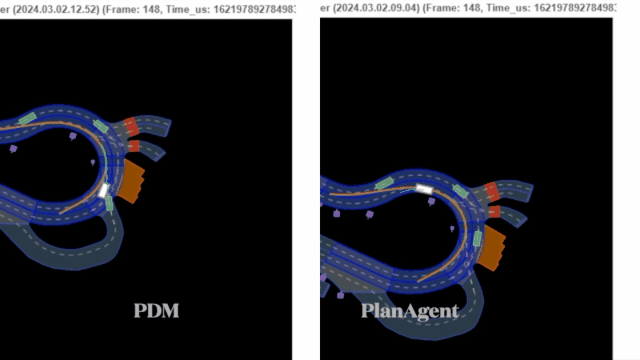
迈向『闭环』| PlanAgent:基于MLLM的自动驾驶闭环规划新SOTA!
中科院自动化所深度强化学习团队联合理想汽车等提出了一种新的基于多模态大语言模型MLLM的自动驾驶闭环规划框架—PlanAgent。该方法以场景的鸟瞰图和基于图的文本提示为输入,利用多模态大语言模型的多模态理解和常识推理能力,进行从场景理解到横向和纵向运动指令生成的层次化推理,并进一步产生规划器所需的指令。在大规模且具有挑战性的nuPlan基准上对该方法进行了测试,实验表明PlanAgent在常规场
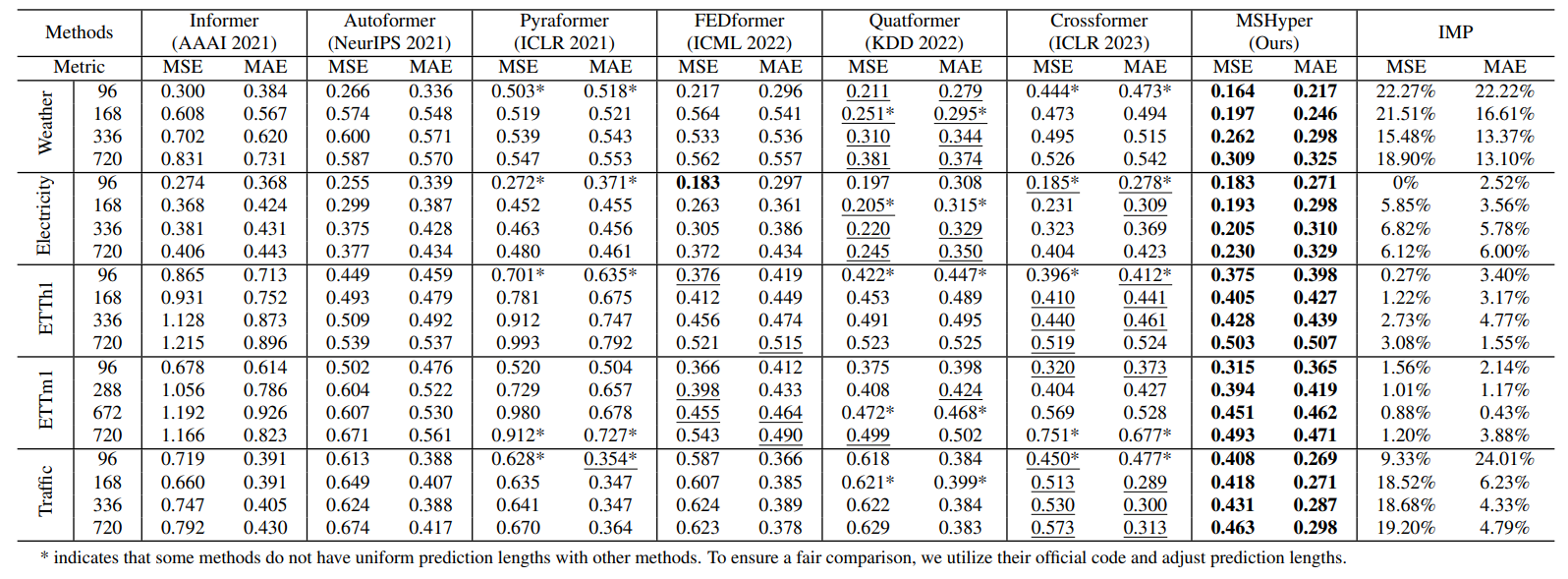
时间序列新范式!多尺度+时间序列,刷爆多项SOTA
当我们面对复杂模式和多变周期的应用场景(比如金融市场分析)时,采用多尺度时间序列来做分析和预测是个更好的选择。 这是因为:传统时序方法通常只用固定时间窗口来提取信息,难以适应不同时间尺度上的模式变化。但多尺度时间序列通过调整时间分辨率和距离,不仅能捕捉到时序的局部细节,还能把握其长期趋势和周期性变化。这就大大提升了模型对新数据集的适应性和不同应用场景迁移能力,让我们能够实现更精确的时间序列预测。
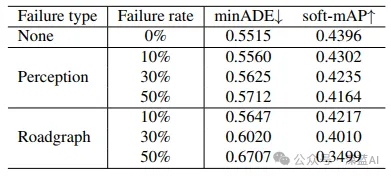
Waymo视角革新!MoST:编码视觉世界,刷新轨迹预测SOTA!
论文标题: MoST: Multi-modality Scene Tokenization for Motion Prediction 论文作者: Norman Mu, Jingwei Ji, Zhenpei Yang, Nate Harada, Haotian Tang, Kan Chen, Charles R. Qi, Runzhou Ge, Kratarth Goel, Zoey Ya

超速解读多模态InternVL-Chat1.5 ,如何做到开源SOTA——非官方首发核心技巧版(待修订)
解读InternVL-chat1.5系列 最近并行是事情太杂乱了,静下心来看一看优秀的开源项目,但是AI技术迭代这么快,现在基本是同时看五、六个方向的技术架构和代码,哪个我都不想放,都想知道原理和代码细节,还要自己训练起来,导致每天脑袋隐隐作痛了,感觉有点天龙八部里的“鸠摩智”的状态。 …目前的大模型核心能力热点是其通用能力的提升,从判别式、到对比学习、再到如今的多阶段对齐训练。VLM多模态模型
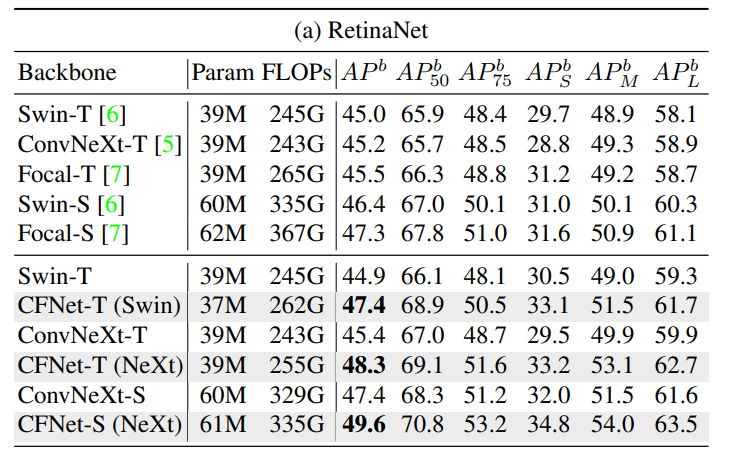
涨点神器:即插即用特征融合模块!超低参数,性能依旧SOTA
在写论文时,一些通用性模块可以在不同的网络结构中重复使用,这简化了模型设计的过程,帮助我们加快了实验的迭代速度。 比如在视觉任务中,即插即用的特征融合模块可以无缝集成到现有网络中,以灵活、简单的方式提升神经网络的性能。这类模块通过专注于数据的关键点和模式,帮助模型更有效地学习特征,从而提高在各种视觉任务中的准确度和效率。 以南航提出的AFF模块、港大等提出的即插即用轻量级模块AdaptForm
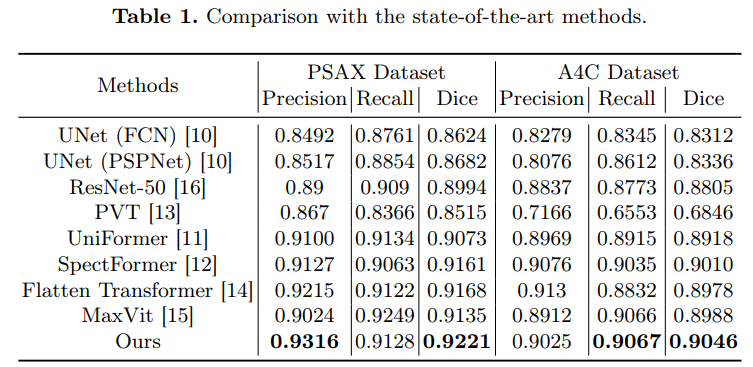
一举颠覆Transformer!最新Mamba结合方案刷新多个SOTA,单张GPU即可处理140k
还记得前段时间爆火的Jamba吗? Jamba是世界上第一个生产级的Mamba大模型,它将基于结构化状态空间模型 (SSM) 的 Mamba 模型与 transformer 架构相结合,取两种架构之长,达到模型质量和效率兼得的效果。 在吞吐量和效率等关键衡量指标上,Jamba处理128k长上下文时吞吐量是 Mixtral 8x7B的3倍;在成本上,Jamba一共支持256k上下文,单张
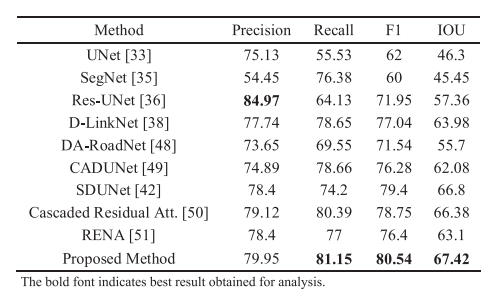
性能再升级!UNet+注意力机制,新SOTA分割准确率高达99%
UNet结合注意力机制能够有效提升图像分割任务的性能。 具体来说,通过将注意力模块集成到UNet的架构中,动态地重新分配网络的焦点,让其更集中在图像中对于分割任务关键的部分。这样UNet可以更有效地利用其跳跃连接特性,以精细的局部化信息来提升分割精度。 这种策略可以帮助UNet更精确地界定目标边界,提升分割精度和效率。同时引导网络关注更有信息量的局部区域,减少模型对计算资源的需求。 以CA
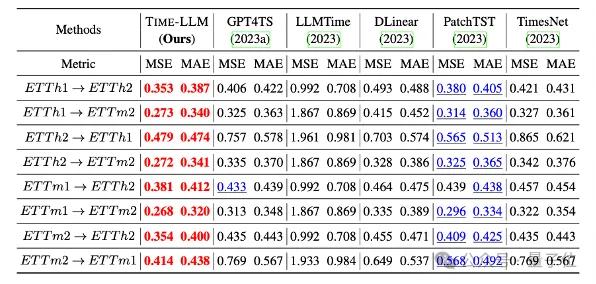
大模型做时序预测也很强!华人团队激活LLM新能力,超越一众传统模型实现SOTA
蔚明 投稿自 凹非寺 量子位 | 公众号 QbitAI 大语言模型潜力被激发—— 无需训练大语言模型就能实现高精度时序预测,超越一切传统时序模型。 来自蒙纳士大学、蚂蚁、IBM研究院提出了一种通用框架,结果成功激活大语言模型跨模态处理时序数据的能力。 时序预测有益于城市、能源、交通、遥感等典型复杂系统的决策制定。 自此,大模型有望彻底改变时序/时空数据挖掘方式。 通用大语言模型

【YOLOv9】完胜V8的SOTA模型Yolov9(论文阅读笔记)
官方论文地址: 论文地址点击即可跳转 官方代码地址: GitCode - 开发者的代码家园 官方代码地址点击即可跳转 1 总述 当输入数据经过各层的特征提取和变换的时候,都会丢失一定的信息。针对这一问题:

参数仅有0.049M!基于Mamba的医学图像分割新SOTA来了!
目前,基于CNN和Transformer的医学图像分割面临着许多挑战。比如CNN在长距离建模能力上存在不足,而Transformer则受到其二次计算复杂度的制约。 相比之下,Mamba的设计允许模型在保持线性计算复杂度的同时,仍然能够捕捉到长距离的依赖关系。因此基于Mamba的医学图像分割能够结合CNN的局部特征提取能力和Transformer的全局上下文理解能力,更有效地处理医学图像中复杂的结
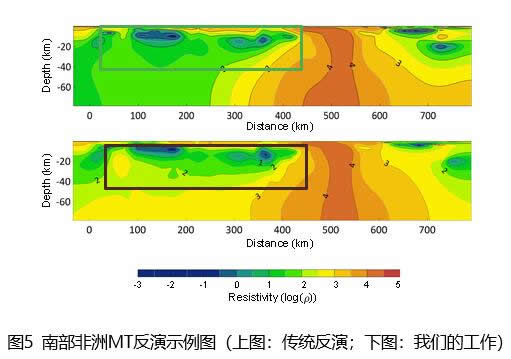
基于昇思的大地电磁智能反演模型达到业界SOTA,助力地球物理勘探加速智能化
近日,华为AI4S Lab与清华大学李懋坤教授团队、华为先进计算与存储实验室合作,基于昇腾AI处理器与昇思MindSpore AI框架打造了大地电磁智能反演模型。该模型通过变分自编码器(VAE)灵活嵌入了多物理先验知识,达到了业界SOTA。该成果已被国际顶级地球物理期刊《Geophysics》收录,相关代码已在昇思MindSpore Elec电磁仿真套件代码仓中开源,同时,该成果也在昇思人工智能框

阿里Qwen1.5-32B开源,评测超Mixtral MoE,挑战SOTA性价比
前言 阿里巴巴近日震撼开源其最新力作——Qwen1.5-32B大语言模型。在当前AI领域,大模型的开发与应用已成为评估技术进步的重要标尺。Qwen1.5-32B的问世,不仅再次证明了阿里在AI技术研发领域的深厚实力,更是在性能与成本之间找到了一个新的平衡点。 Qwen1.5-32B模型简介 Qwen1.5-32B继承了Qwen系列模型的卓越传统,拥有320亿参数,是在Qwen1.5系列中规模

3DGS实时高质量大规模场景渲染最新SOTA!
作者:小柠檬 | 来源:3DCV 在公众号「3DCV」后台,回复「原论文」可获取论文pdf 添加微信:dddvision,备注:3D高斯,拉你入群。文末附行业细分群 详细内容请关注3DCV 3D视觉精品课程:www.3dcver.com 3DGS、NeRF、结构光、相位偏折术、机械臂抓取、点云实战、Open3D、缺陷检测、BEV感知、Occupancy、Transformer、模型
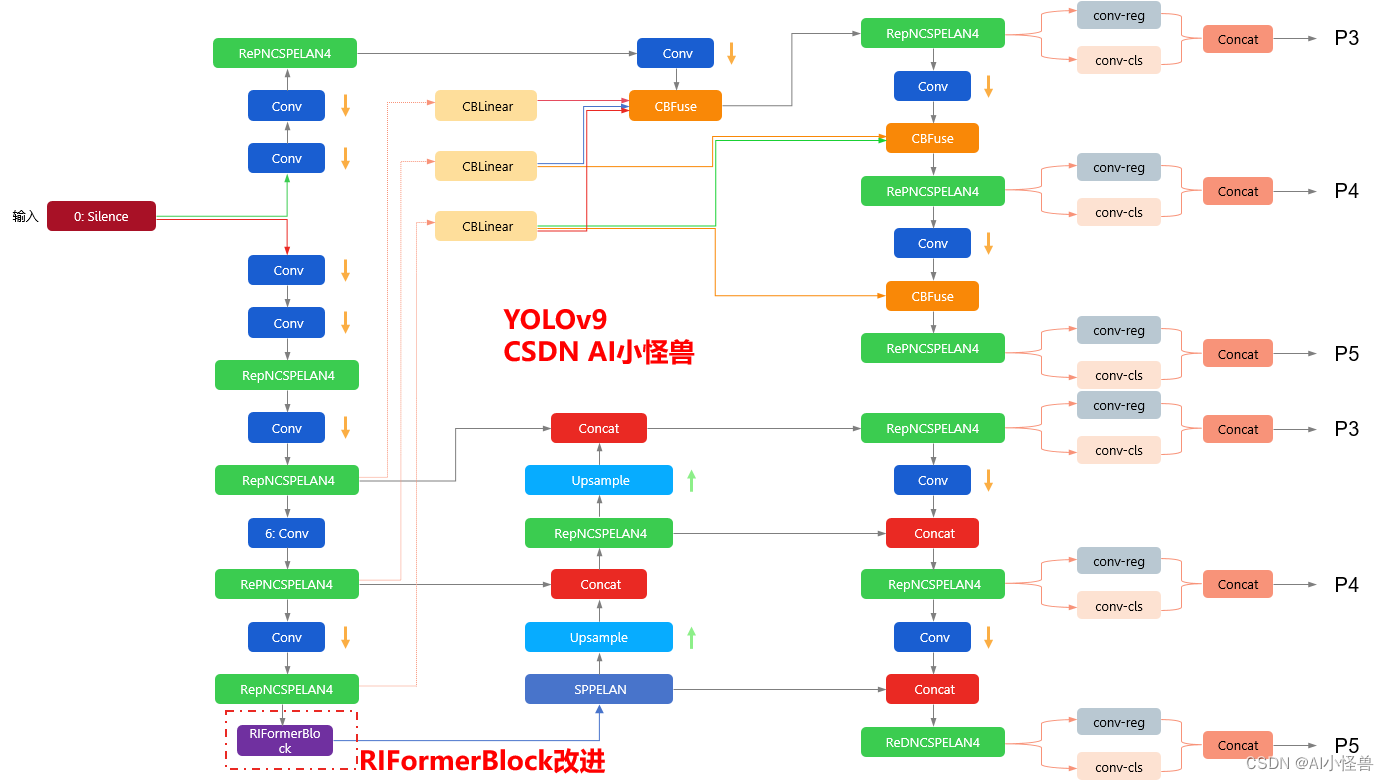
YOLOv9改进策略 :block优化 | 无需TokenMixer也能达成SOTA性能的极简ViT架构 | CVPR2023 RIFormer
💡💡💡本文改进内容: token mixer被验证能够大幅度提升性能,但典型的token mixer为自注意力机制,推理耗时长,计算代价大,而RIFormers是无需TokenMixer也能达成SOTA性能的极简ViT架构 ,在保证性能的同时足够轻量化。 💡💡💡RIFormerBlock引入到YOLOv9,多个数据集验证能够大幅度涨点 改进结构图如下:

车道线检测综述——【极市】方浩:车道线检测新SOTA,RESA个人笔记
视频链接:https://www.bilibili.com/video/BV1664y1o7wg 一、背景 车道线检测:从输入的图片中检测出车道线,图片是由车辆的前置摄像头拍摄。 1.1 车道线检测在自动驾驶中如何使用 自动驾驶从算法的角度主要分为三个部分:环境感知、决策、执行。环境感知即通过各种传感器采集数据,用算法进行分析,再输入Planning模块,Planning模块根据自己要
可变形卷积颠覆式创新!新SOTA提速80%,更高性能,更强几何适应能力
在传统的卷积神经网络中,固定模式的卷积核在处理图像时可能会限制网络对不规则形状特征的提取能力。为了解决这个问题,研究者提出了可变形卷积。 可变形卷积是一种改进的卷积操作,它通过引入可学习的偏移量来增强模型对几何变化的适应能力,让网络能够更好地处理不规则形状的物体或特征。 比如D-LKA Attention模型,这种简化的注意力机制受益于可变形卷积,可以灵活地扭曲采样网格,使模型能够适应不同的