本文主要是介绍Qwen2——阿里巴巴最新的多语言模型挑战 Llama 3 等 SOTA,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
引言

经过几个月的期待, 阿里巴巴 Qwen 团队终于发布了 Qwen2 – 他们强大的语言模型系列的下一代发展。 Qwen2 代表了一次重大飞跃,拥有尖端的进步,有可能将其定位为 Meta 著名的最佳替代品 骆驼3 模型。在本次技术深入探讨中,我们将探讨使 Qwen2 成为大型语言模型 (LLM) 领域强大竞争者的关键功能、性能基准和创新技术。
Qwen2 型号系列
核心是 Qwen2 拥有一系列多样化的模型,可满足不同的计算需求。该系列包含五种不同的型号:Qwen2-0.5B、Qwen2-1.5B、Qwen2-7B、Qwen2-57B-A14B 和旗舰产品 Qwen2-72B。这一系列选项可满足广泛的用户需求,从拥有适度硬件资源的用户到能够使用尖端计算基础设施的用户。
Qwen2 的突出特点之一是它的多语言功能。虽然之前的 Qwen1.5 该模型在英语和中文方面表现出色,Qwen2 还接受了涵盖 27 种其他语言的数据的训练。这种多语言训练方案包括来自西欧、东欧和中欧、中东、东亚和南亚等不同地区的语言。

Qwen2 型号支持的语言(按地理区域分类)
通过扩展其语言库,Qwen2 展示了理解和生成多种语言内容的卓越能力,使其成为全球应用和跨文化交流的宝贵工具。
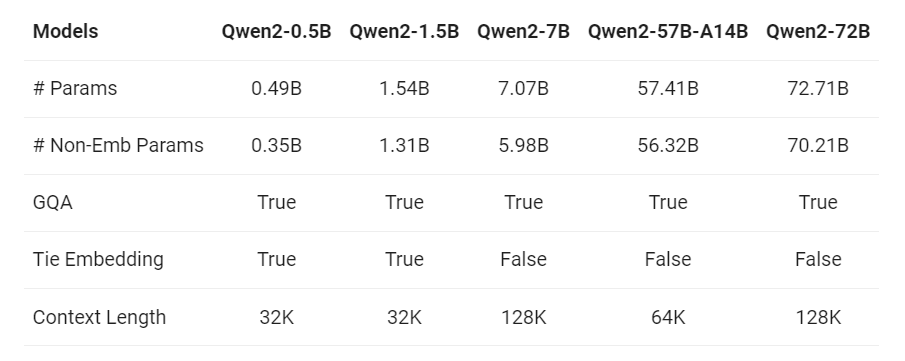
Qwen2 模型的规格包括参数、GQA 和上下文长度。
解决代码转换问题:多语言挑战
在多语言环境中,语码转换现象(即在一次对话或话语中交替使用不同语言的做法)很常见。 Qwen2 经过精心培训,可以处理语码转换场景,显着减少相关问题并确保语言之间的平滑转换。
使用通常会引起语码转换的提示进行的评估证实了 Qwen2 在该领域的实质性改进,这证明了阿里巴巴致力于提供真正的多语言语言模型。
擅长编码和数学
Qwen2 在编码和数学领域拥有卓越的能力,这些领域传统上对语言模型提出了挑战。通过利用广泛的高质量数据集和优化的训练方法,Qwen2-72B-Instruct(旗舰模型的指令调整变体)在解决数学问题和跨各种编程语言的编码任务方面表现出出色的性能。
扩展语境理解
Qwen2 最令人印象深刻的功能之一是它能够理解和处理扩展的上下文序列。虽然大多数语言模型都难以处理长文本,但 Qwen2-7B-Instruct 和 Qwen2-72B-Instruct 模型经过精心设计,可以处理长达 128K 个标记的上下文。
这种非凡的功能对于需要深入了解冗长文档(例如法律合同、研究论文或密集的技术手册)的应用程序来说是一个颠覆性的变化。通过有效地处理扩展上下文,Qwen2 可以提供更准确、更全面的响应,从而开辟自然语言处理的新领域。
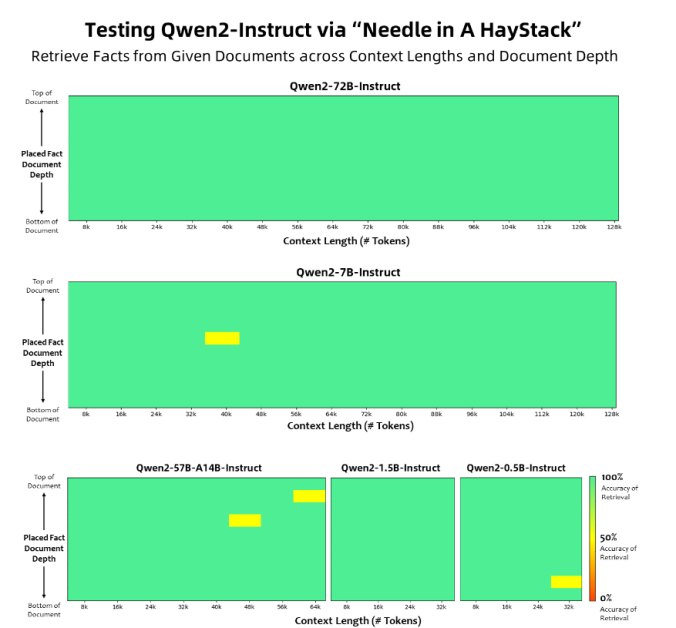
Qwen2 模型从不同上下文长度和文档深度的文档中检索事实的准确性。
该图表显示了 Qwen2 模型从不同上下文长度和深度的文档中检索事实的能力。
分组查询注意力和优化嵌入
在底层,Qwen2 融合了多项架构创新,从而实现了卓越的性能。其中一项创新是在所有模型大小上采用组查询注意力(GQA)。 GQA 提供更快的推理速度并减少内存使用,使 Qwen2 更加高效并可支持更广泛的硬件配置。
此外,阿里巴巴还针对 Qwen2 系列中的小模型对嵌入进行了优化。通过绑定嵌入,团队成功减少了这些模型的内存占用,使其能够在性能较弱的硬件上部署,同时保持高质量的性能。
对 Qwen2 进行基准测试:超越最先进的模型
Qwen2 在各种基准测试中均表现出色。对比评估显示,该系列中最大的模型 Qwen2-72B 在自然语言理解、知识获取、编码能力、数学技能和多语言能力等关键领域均优于 Llama-3-70B 等领先竞争对手。
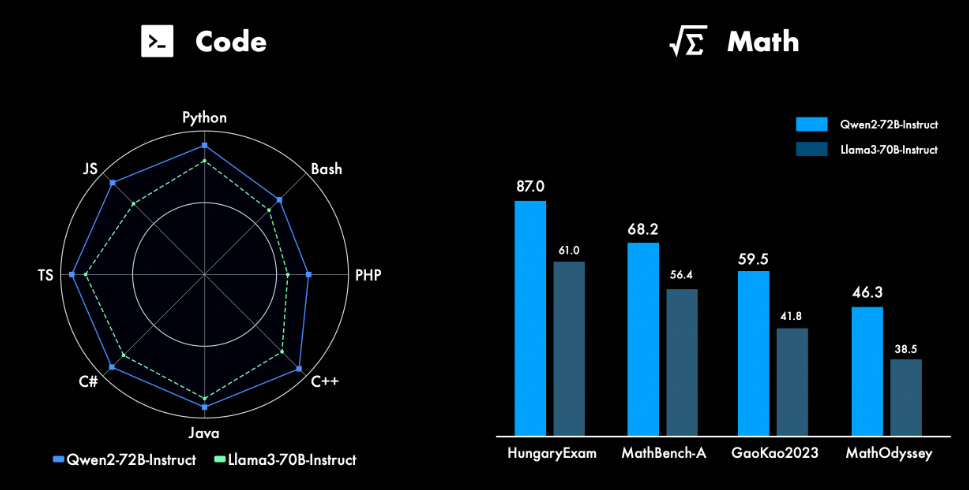
Qwen2-72B-Instruct 与 Llama3-70B-Instruct 的编码和数学表现对比
Qwen1.5-110B 虽然参数比上一代 Qwen2-72B 少,但性能表现却更为出色,充分证明了阿里巴巴精心挑选的数据集和优化的训练方法的有效性。
安全与责任:与人类价值观相一致
Qwen2-72B-Instruct 已接受严格评估,以确认其处理与非法活动、欺诈、色情和侵犯隐私相关的潜在有害查询的能力。结果令人鼓舞:Qwen2-72B-Instruct 在安全性方面的表现可与备受推崇的 GPT-4 模型相媲美,与其他大型模型(如 Mistral-8x22B)相比,有害响应的比例明显较低。
这一成就凸显了阿里巴巴致力于开发符合人类价值观的人工智能系统,确保Qwen2不仅强大,而且值得信赖和负责。
许可和开源承诺
为了进一步扩大 Qwen2 的影响,阿里巴巴采用了开源的许可方式。虽然 Qwen2-72B 及其指令调整型号保留了原始的Qianwen 许可证,但其余型号 – Qwen2-0.5B、Qwen2-1.5B、Qwen2-7B 和 Qwen2-57B-A14B – 已根据宽松的 Apache 2.0 许可证获得许可。
这种增强的开放性预计将加速 Qwen2 模型在全球的应用和商业使用,促进全球人工智能社区的协作和创新。
使用与实施
使用 Qwen2 模型非常简单,这得益于它们与流行框架的集成,例如Hugging Face。下面是使用 Qwen2-7B-Chat-beta 进行推理的示例:
from transformers import AutoModelForCausalLM, AutoTokenizer
device = "cuda" # the device to load the model onto
model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen1.5-7B-Chat", device_map="auto")
tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen1.5-7B-Chat")
prompt = "Give me a short introduction to large language models."
messages = [{"role": "user", "content": prompt}]
text = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
model_inputs = tokenizer([text], return_tensors="pt").to(device)
generated_ids = model.generate(model_inputs.input_ids, max_new_tokens=512, do_sample=True)
generated_ids = [output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
print(response)此代码片段演示了如何使用 Qwen2-7B-Chat 模型设置和生成文本。与的集成Hugging Face使其易于访问且易于实验。
Qwen2 与 Llama 3:比较分析
虽然 Qwen2 和 梅塔的羊驼 3都是强大的语言模型,它们表现出独特的优势和权衡。
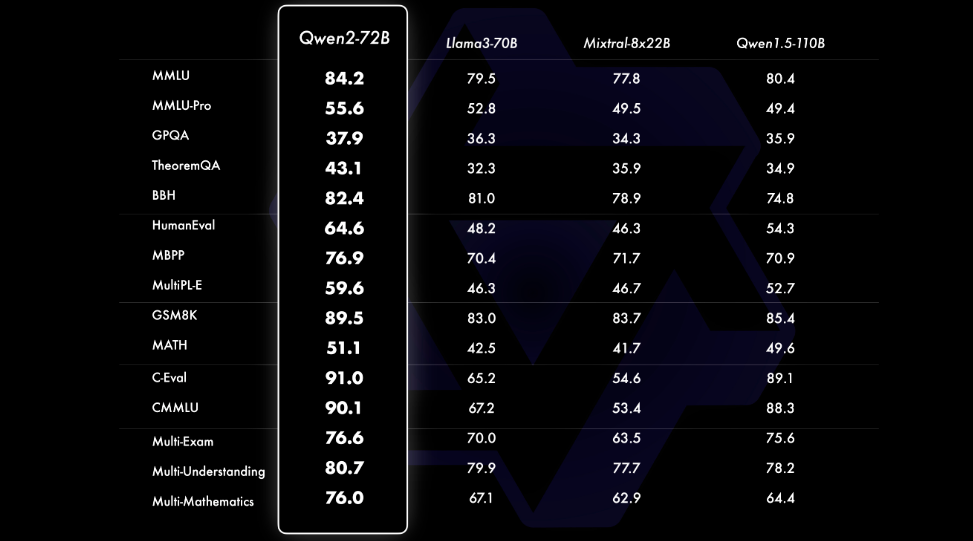
Qwen2-72B、Llama3-70B、Mixtral-8x22B 和 Qwen1.5-110B 在各种基准(包括 MMLU、MMLU-Pro、GPQA 等)上的性能比较图表。
以下是一个比较分析,可以帮助您了解它们的主要区别:
多语言能力:Qwen2在多语言支持方面具有明显优势。其对除英语和中文之外的另外 27 种语言的数据进行训练,使 Qwen2 在跨文化交流和多语言场景中表现出色。相比之下,Llama 3 的多语言能力不太明显,可能限制其在不同语言环境中的有效性。
编码和数学能力:Qwen2 和 骆驼3表现出令人印象深刻的编码和数学能力。然而,Qwen2-72B-Instruct 似乎略有优势,因为它在这些领域对大量高质量数据集进行了严格的训练。阿里巴巴专注于增强 Qwen2 在这些领域的能力,这可能会让它在涉及编码或数学问题解决的专业应用中占据优势。
长上下文理解:Qwen2-7B-Instruct 和 Qwen2-72B-Instruct 模型拥有处理高达 128K 令牌的上下文长度的令人印象深刻的能力。此功能对于需要深入理解冗长文档或密集技术材料的应用程序尤其有价值。 Llama 3 虽然能够处理长序列,但在该特定领域的性能可能无法与 Qwen2 相媲美。
虽然 Qwen2 和 Llama 3 都表现出了最先进的性能,但 Qwen2 的模型阵容多样化,从 0.5B 到 72B 参数,提供了更大的灵活性和可扩展性。这种多功能性使用户可以选择最适合其计算资源和性能要求的模型大小。此外,阿里巴巴正在努力将 Qwen2 扩展到更大的模型,这可能会进一步增强其功能,未来可能会超越 Llama 3。
简化 Qwen2 采用
为了促进Qwen2的广泛采用和集成,阿里巴巴采取了积极措施,确保跨各种平台和框架的无缝部署。 Qwen 团队与众多第三方项目和组织密切合作,使 Qwen2 能够与各种工具和框架结合使用。
微调和量化:Axolotl、Llama-Factory、Firefly、Swift 和 XTuner 等第三方项目已经过优化,支持 Qwen2 模型的微调,使用户能够根据其特定任务和数据集定制模型。此外,量化工具如 自动GPTQ, 自动AWQ、Neural Compressor 已适应与 Qwen2 配合使用,有助于在资源受限的设备上进行高效部署。
部署和推理:Qwen2 模型可以使用各种框架进行部署和服务,包括 法学硕士、SGL、SkyPilot、 TensorRT-法学硕士, 打开维诺和 TGI。这些框架提供了优化的推理管道,支持在生产环境中高效、可扩展地部署 Qwen2。
API 平台和本地执行:对于希望将 Qwen2 集成到其应用程序中的开发人员,Together、Fireworks 和 OpenRouter 等 API 平台提供了访问模型功能的便捷方式。或者,通过 MLX、Llama.cpp 等框架支持本地执行, 奥拉马和 LM Studio,允许用户在本地计算机上运行 Qwen2,同时保持对数据隐私和安全的控制。
代理和 RAG 框架:Qwen2 对工具使用和代理功能的支持得到了诸如骆驼指数、CrewAI 和 开放的Devin.这些框架支持创建专门的AI代理,并将Qwen2集成到 检索增强生成(RAG)管道,扩大应用范围和用例。
未来的发展和机遇
阿里巴巴对 Qwen2 的愿景远不止于当前版本。该团队正在积极训练更大的模型,以探索模型扩展的前沿,并辅以持续的数据扩展工作。此外,他们正在计划将 Qwen2 扩展到多模态 AI 领域,实现视觉和音频理解能力的整合。
随着开源人工智能生态系统的不断蓬勃发展,Qwen2 将发挥关键作用,为寻求推进自然语言处理和人工智能技术发展的研究人员、开发人员和组织提供强大的资源。
这篇关于Qwen2——阿里巴巴最新的多语言模型挑战 Llama 3 等 SOTA的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








