llama专题

Python安装llama库出错“metadata-generation-failed”
Python安装llama库出错“metadata-generation-failed” 1. 安装llama库时出错2. 定位问题1. 去官网下载llama包 2.修改配置文件2.1 解压文件2.2 修改配置文件 3. 本地安装文件 1. 安装llama库时出错 2. 定位问题 根据查到的资料,发现时llama包中的execfile函数已经被下线了,需要我们手动修改代码后

Llama 3.1大模型的预训练和后训练范式解析
Meta的Llama大型语言模型每次出新版本,都会是一大事件。前段时间他们不仅发布了3.1的一个超大型的405亿参数模型,还对之前的8亿和70亿参数的模型做了升级,让它们在MMLU测试中的表现更好了。 不同模型在MMLU基准测试中的表现 他们还出了一个92页的技术报告《Llama 3 Herd of Models》(https://arxiv.org/abs/2407.21783),里

llama.cpp demo
git clone https://github.com/ggerganov/llama.cppcd llama.cpp 修改Makefile使能mfma参数 MK_CFLAGS += -mfma -mf16c -mavx MK_CXXFLAGS += -mfma -mf16c -mavx 安装python3依赖 cat ./requirements/requirem
llama.cpp本地部署大模型
llama.cpp 是一个C++库,用于简化LLM推理的设置,它使得在本地机器上运行大模型(GGUF格式)成为可能。 官网:https://github.com/ggerganov/llama.cpp 模型库: https://huggingface.co/ HF-Mirror 魔搭社区 安装并且使用llama.cpp 0.安装llama.cpp 官方文档:https://gi

3天把Llama训成Mamba,性能不降,推理更快!
近日,Mamba方面又搞出了有意思的研究:来自康奈尔、普林斯顿等机构的研究人员成功将Llama提炼成了Mamba模型,并且设计了新的推测解码算法,加速了模型的推理。\ 先来看一张其乐融融的图片(一眼AI): 右边的小羊驼代表Llama,而左边的蛇(Mamba)也是我们的老熟人了。 至于到底能不能其乐融融,咱就不管了,之所以有此场景,是因为Mamba方面又搞出了有意思的研究: ——如何把

LLaMA-Factory仓基础功能架构及NPU/GPU环境实战演练
LLaMA-Factory 基础篇 LLaMA-Factory简介 LLaMA-Factory是一个开源的大规模语言模型微调框架,设计用于简化大模型的训练过程。它提供了一个统一的平台,支持多种大模型的微调,包括LLaMA、BLOOM、Mistral等,旨在帮助用户快速适应和调整这些模型以适应特定的应用场景。LLaMA-Factory通过提供一套完整的工具和接口,使用户能够轻松地对预训练的

The Llama 3 Herd of Models【论文原文下载】
关注B站可以观看更多实战教学视频:hallo128的个人空间 The Llama 3 Herd of Models【论文原文】 点击下载:原文下载链接 摘要 现代人工智能(AI)系统由基础模型驱动。本文介绍了一组新的基础模型,称为 Llama 3。它是一群原生支持多语言、编码、推理和工具使用的语言模型。我们最大的模型是一个密集型 Transformer,具有 405 B {40

lit-llama代码解析
https://github.com/Lightning-AI/lit-llama/blob/main/README.md 下载的时候会报错误,因为网不行,一种方法就是多次尝试,另一种方法是终端连上代理下载 pycharm连接hugging face等网站_hugging face怎么连接-CSDN博客 根据指引下载权重 下载完权重运行:python scripts/convert_h

【AI大模型】近100页的LLaMA 3技术报告:模型结构及影响解析
LLama 3 405B模型效果已经赶上目前最好的闭源模型比如GPT 4o和Claude 3.5,这算是开源届的大事,技术报告接近100页,信息很丰富,粗略看了一下,很有启发。这里就LLaMA 3的模型结构、训练过程做些解读,并对其影响、小模型如何做、合成数据等方面谈点看法。 一、LLaMA 3模型结构 LLaMA 3的模型结构如图1所示,这基本已经形成目前Dense LLM模型的标准结构了,

LLaMA-Factory微调入门个人重制版
LLaMA-Factory微调入门个人重制版 说明: 首次发表日期:2024-08-30LLaMA-Factory 官方Github仓库: https://github.com/hiyouga/LLaMA-Factory 关于 本文是对LLaMA-Factory入门教程 https://zhuanlan.zhihu.com/p/695287607 的个人重制版,记录一下学习过程,省略掉了很

什么情况用Bert模型,什么情况用LLaMA、ChatGLM类大模型,咋选?
什么情况用Bert模型,什么情况用LLaMA、ChatGLM类大模型,咋选? 答:Bert 的模型由多层双向的Transformer编码器组成,由12层组成,768隐藏单元,12个head,总参数量110M,约1.15亿参数量。NLU(自然语言理解)任务效果很好,单卡GPU可以部署,速度快,V100GPU下1秒能处理2千条以上。 ChatGLM-6B, LLaMA-7B模型分别是60亿参数量和

Llama 3.1 405B:4050亿参数史上最强开源大模型
01 。 概述 Meta公司推出了其最大的开源人工智能模型——Llama 3.1 405B,拥有4050亿个参数,与GPT-4o和Claude 3.5 Sonnet相媲美。该模型在16000个Nvidia H100 GPU上训练而成,现已在云平台上可用,并被应用于WhatsApp和Meta.ai中。它能够处理包括编码和摘要在内的八种语言任务,但仅限于文本。Llama 3.1模型拥有128000个
Docker下使用llama.cpp部署带Function calling和Json Mode功能的Mistral 7B模型
Docker下使用llama.cpp部署带Function calling和Json Mode功能的Mistral 7B模型 说明: 首次发表日期:2024-08-27参考: https://www.markhneedham.com/blog/2024/06/23/mistral-7b-function-calling-llama-cpp/https://github.com/abetlen/

Code Llama: Open Foundation Models for Code论文阅读
整体介绍 Code Llama 发布了3款模型,包括基础模型、Python 专有模型和指令跟随模型,参数量分别为 7B、13B、34B 和 70B。这些模型在长达 16k tokens 的序列上训练。都是基于 Llama 2。 作者针对infilling (FIM) 、长上下文、指令专门做了微调 long-context fine-tuning (LCFT). codellama细节 C
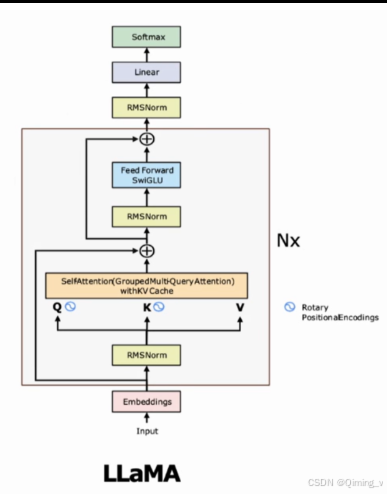
LLaMA代码笔记 --基于lit-llama
代码来自:lit-llama modelscope模型下载 :llama-7b 下载后的模型需要转换为lit-llama使用的格式,详见 howto 文件夹下的 download_weights.md 文中代码为了方便说明,删减了一些内容,详细代码请查看源码。 generate 输入参数: idx: 输入的prompt经过 tokenizer encode之后输出的序列tensor.使用了
(章节 3.1) 本地运行 AI 有多慢 ? 大模型推理测速 (llama.cpp, Intel GPU A770)
由于本文太长, 分开发布, 方便阅读. 3.1 CPU (i5-6200U, 2C/4T/2.8GHz) x86_64 AVX2 在 4 号 PC (物理机) 上运行. 版本: > ./llama-b3617-bin-ubuntu-x64/build/bin/llama-cli --versionversion: 3617 (a07c32ea)built with cc (Ubunt

Unsloth 教程 - 如何微调 Llama-3并导出到 Ollama
本文翻译整理自:🦙 How to Finetune Llama-3 and Export to Ollama https://docs.unsloth.ai/tutorials/how-to-finetune-llama-3-and-export-to-ollama 文章目录 1、什么是Unsloth?2、什么是Ollama?3、安装Unsloth4、选择要微调的模型5、微调参数6、
【深度学习】LLaMA-Factory 大模型微调工具, 微调GLM-4-9B-Chat-1M ,Docker (4)
文章目录 回顾制作镜像数据准备WebUI训练推理导出模型部署 回顾 之前LLaMA-Factory 还未正式支持GLM-4-9B,做了魔改后进行微调了: https://qq742971636.blog.csdn.net/article/details/140620014 如今LLaMA-Factory 已正式支持GLM-4-9B,本篇文章会以Docker方式进行GLM-4-9

transformers调用llama的方式
transformers调用llama的使用方式 不同版本llama对应的transformers库版本llama2llama3Meta-Llama-3-8B-InstructMeta-Llama-3-8B llama3.1Meta-Llama-3.1-8B-Instruct 不同版本llama对应的transformers库版本 # llama2pip install to

编译运行 llama.cpp (vulkan, Intel GPU SYCL)
llama.cpp 是一个运行 AI (神经网络) 语言大模型的推理程序, 支持多种 后端 (backend), 也就是不同的具体的运行方式, 比如 CPU 运行, GPU 运行等. 但是编译运行 llama.cpp 并不是那么容易的, 特别是对于 SYCL 后端 (用于 Intel GPU), 坑那是一大堆. 只有特定版本的 llama.cpp, 特定版本的 Linux 系统和 GPU 驱动程

基于华为昇腾910B和LLaMA Factory多卡微调的实战教程
大家好,我是herosunly。985院校硕士毕业,现担任算法研究员一职,热衷于大模型算法的研究与应用。曾担任百度千帆大模型比赛、BPAA算法大赛评委,编写微软OpenAI考试认证指导手册。曾获得阿里云天池比赛第一名,CCF比赛第二名,科大讯飞比赛第三名。授权多项发明专利。对机器学习和深度学习拥有自己独到的见解。曾经辅导过若干个非计算机专业的学生进入到算法行业就业。希望和大家一起成长进步。

大模型笔记!以LLAMA为例,快速入门LLM的推理过程
本文借助llama这个模型快速入门LLM的推理过程,技术细节很多都是通用的,也适合其他的LLM。本篇也可以作为CV快速入门NLP简易指南。 本文借助llama这个模型快速入门LLM的推理过程,很多技术细节都是通用的,也适合其他的LLM。这篇文章之前发过一次,现在整理下内容重新发下。 这篇也算是总结的性质,仅需要的知识点都列出来,简单介绍一番。可能说的不够详细,想看具体细节的小伙伴可参考文中引用

零成本部署秘籍:Llama 3本地使用全攻略,轻松实现高效模型运行!
Meta公司的Llama 3大模型引领AI新篇章 各位朋友,我是袋鼠帝。 近日,真正的“OpenAI”——Meta公司,对“Close AI”进行了有力回应,推出了其开源大模型系列的最新力作——Llama 3。自Llama 1起,这个系列便以其卓越性能在开源大模型领域独占鳌头。在相同规模的参数量下,它无疑是最出色的选手之一。而Llama 3更是青出于蓝,不仅在技术层面实现了对Llama 2的重大

大模型学习笔记 - LLM 之 LLaMA系列(待更新)
LLaMA 系列 LLaMA 概述 LLaMA-1LLaMA-2LLaMA-3 LLaMA 概述 LLaMA: Open and Efficient Foundation Language Models Llama 2: Open Foundation and Fine-Tuned Chat Models (LLama2 & LLama2-Chat) LLama 3 | LLama 3.1
transformers调用llama的使用方式
transformers调用llama的使用方式 不同版本llama对应的transformers库版本llama2llama3Meta-Llama-3-8B-InstructMeta-Llama-3-8B llama3.1Meta-Llama-3.1-8B-Instruct 不同版本llama对应的transformers库版本 # llama2pip install to

【从Qwen2,Apple Intelligence Foundation,Gemma 2,Llama 3.1看大模型的性能提升之路】
从早期的 GPT 模型到如今复杂的开放式 LLM,大型语言模型 (LLM) 的发展已经取得了长足的进步。最初,LLM 训练过程仅侧重于预训练,但后来扩展到包括预训练和后训练。后训练通常包括监督指令微调和校准,这是由 ChatGPT 推广的。 自 ChatGPT 首次发布以来,训练方法已不断发展。在本文中,我回顾了训练前和训练后方法的最新进展,特别是最近几个月取得的进展。 概述 LLM 开发和培