qwen2专题

LLM系列 | 38:解读阿里开源语音多模态模型Qwen2-Audio
引言 模型概述 模型架构 训练方法 性能评估 实战演示 总结 引言 金山挂月窥禅径,沙鸟听经恋法门。 小伙伴们好,我是微信公众号《小窗幽记机器学习》的小编:卖铁观音的小男孩,今天这篇小作文主要是介绍阿里巴巴的语音多模态大模型Qwen2-Audio。近日,阿里巴巴Qwen团队发布了最新的大规模音频-语言模型Qwen2-Audio及其技术报告。该模型在音频理解和多模态交互

Ollama Qwen2 支持 Function Calling
默认 Ollama 中的 Qwen2 模型不支持 Function Calling,使用默认 Qwen2,Ollama 会报错。本文将根据官方模板对 ChatTemplate 进行改进,使得Qwen2 支持 Tools,支持函数调用。 Ollama 会检查对话模板中是否存在 Tools,如果不存在就会报错,下面的代码是 Ollama 解析模板的代码。 Ollama 3.1 是支持 Tools

MLLM(二)| 阿里开源视频理解大模型:Qwen2-VL
2024年8月29日,阿里发布了 Qwen2-VL!Qwen2-VL 是基于 Qwen2 的最新视觉语言大模型。与 Qwen-VL 相比,Qwen2-VL 具有以下能力: SoTA对各种分辨率和比例的图像的理解:Qwen2-VL在视觉理解基准上达到了最先进的性能,包括MathVista、DocVQA、RealWorldQA、MTVQA等。理解 20 分钟+ 的视频:Qwe

如何在算家云搭建Qwen2(智能对话)
一、Qwen2简介 Qwen2 是由阿里云通义千问团队研发的新一代大型语言模型系列,它在多个方面实现了技术的飞跃和性能的显著提升。以下是对 Qwen2 的详细介绍: GitHub - QwenLM/Qwen2: Qwen2 is the large language model series developed by Qwen team, Alibaba Cloud. 1. 模型概述 名称
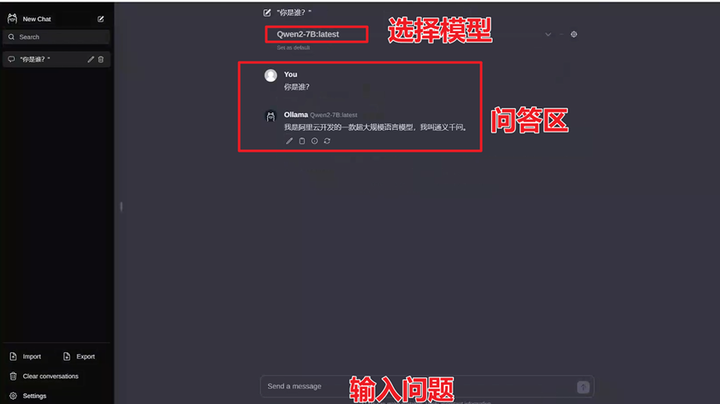
怎么在Windows操作系统部署阿里开源版通义千问(Qwen2)
怎么在Windows操作系统部署阿里开源版通义千问(Qwen2) | 原创作者/编辑:凯哥Java | 分类:人工智能学习系列教程 添加图片注释,不超过 140 字(可选) GitHub上qwen2截图 随着人工智能技术的不断进步,阿里巴巴通义千问团队近期发布了Qwen2系列开源模型,这一系列模型在多个领域展现出卓越的性能,特别是在自然语言理解、知识、代码、数学及多语言等能

阿里云Qwen2-VL语言模型:特点与实用性解析
最近,阿里云推出了最新的视觉语言模型——Qwen2-VL。作为一款先进的视觉语言模型,Qwen2-VL的发布无疑为AI领域注入了新的活力。那么,这款模型有哪些特别之处?它的实用性又如何呢?今天我们就来详细解析一下Qwen2-VL的特点与实际应用。 一、Qwen2-VL的核心特点 1. 多分辨率与比例图像的理解能力 Qwen2-VL最大的亮点之一,就是它对多分辨率和比例图像的理解能力。

240831-Qwen2-VL-7B/2B部署测试
A. 运行效果 B. 配置部署 如果可以执行下面就执行下面: pip install git+https://github.com/huggingface/transformers accelerate 否则分开执行 git clone https://github.com/huggingface/transformerscd transformerspip install .

开源模型应用落地-qwen2-7b-instruct-LoRA微调合并-ms-swift-单机单卡-V100(十三)
一、前言 本篇文章将使用ms-swift去合并微调后的模型权重,通过阅读本文,您将能够更好地掌握这些关键技术,理解其中的关键技术要点,并应用于自己的项目中。 二、术语介绍 2.1. LoRA微调 LoRA (Low-Rank Adaptation) 用于微调大型语言模型 (LLM)。 是一种有效的自适应策略,它不会引入额外的推理延迟,并在保持模型质量的同时显着减少下游
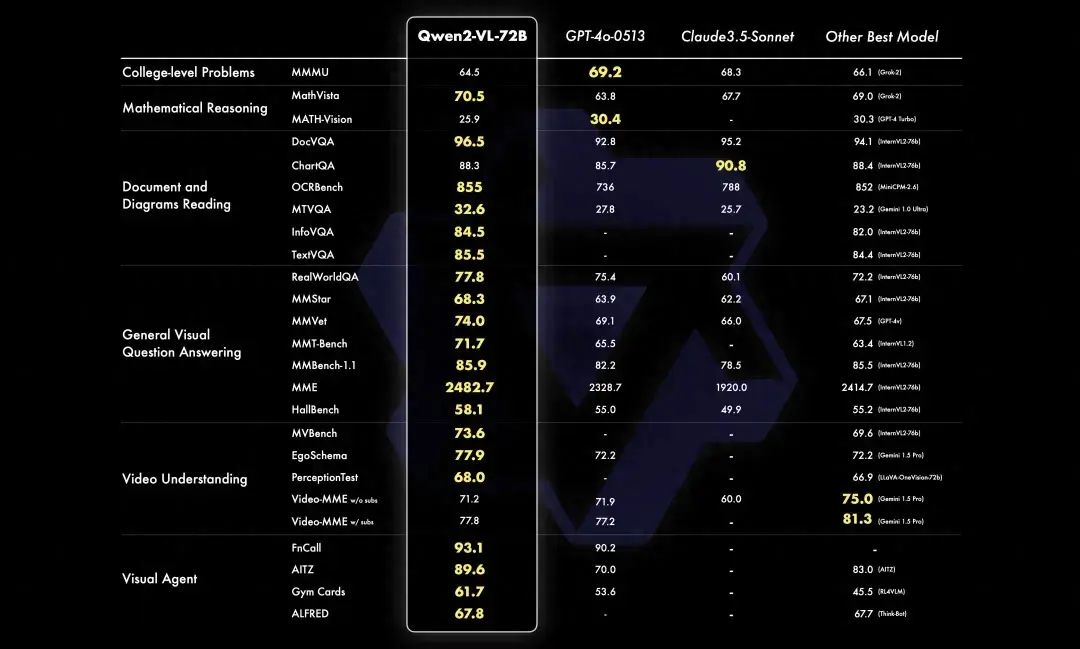
AI大模型日报#0830:智谱AI推出多款升级模型、阿里开源多模态Qwen2-VL
导读:AI大模型日报,爬虫+LLM自动生成,一文览尽每日AI大模型要点资讯!目前采用“文心一言”(ERNIE-4.0-8K-latest)、“智谱AI”(glm-4-0520)生成了今日要点以及每条资讯的摘要。欢迎阅读!《AI大模型日报》今日要点:智谱AI在KDD 2024上展示了其全新大模型GLM-4-Plus,该模型在多任务上逼近甚至超越GPT-4o,并推出了支持中英双语的对话机器人等功能,巩

开源模型应用落地-qwen2-7b-instruct-LoRA微调模型合并-Axolotl-单机单卡-V100(十)
一、前言 本篇文章将使用Axolotl去合并微调后的模型权重,通过阅读本文,您将能够更好地掌握这些关键技术,理解其中的关键技术要点,并应用于自己的项目中。 二、术语介绍 2.1. LoRA微调 LoRA (Low-Rank Adaptation) 用于微调大型语言模型 (LLM)。 是一种有效的自适应策略,它不会引入额外的推理延迟,并在保持模型质量的同时显着减少下游任

【从Qwen2,Apple Intelligence Foundation,Gemma 2,Llama 3.1看大模型的性能提升之路】
从早期的 GPT 模型到如今复杂的开放式 LLM,大型语言模型 (LLM) 的发展已经取得了长足的进步。最初,LLM 训练过程仅侧重于预训练,但后来扩展到包括预训练和后训练。后训练通常包括监督指令微调和校准,这是由 ChatGPT 推广的。 自 ChatGPT 首次发布以来,训练方法已不断发展。在本文中,我回顾了训练前和训练后方法的最新进展,特别是最近几个月取得的进展。 概述 LLM 开发和培
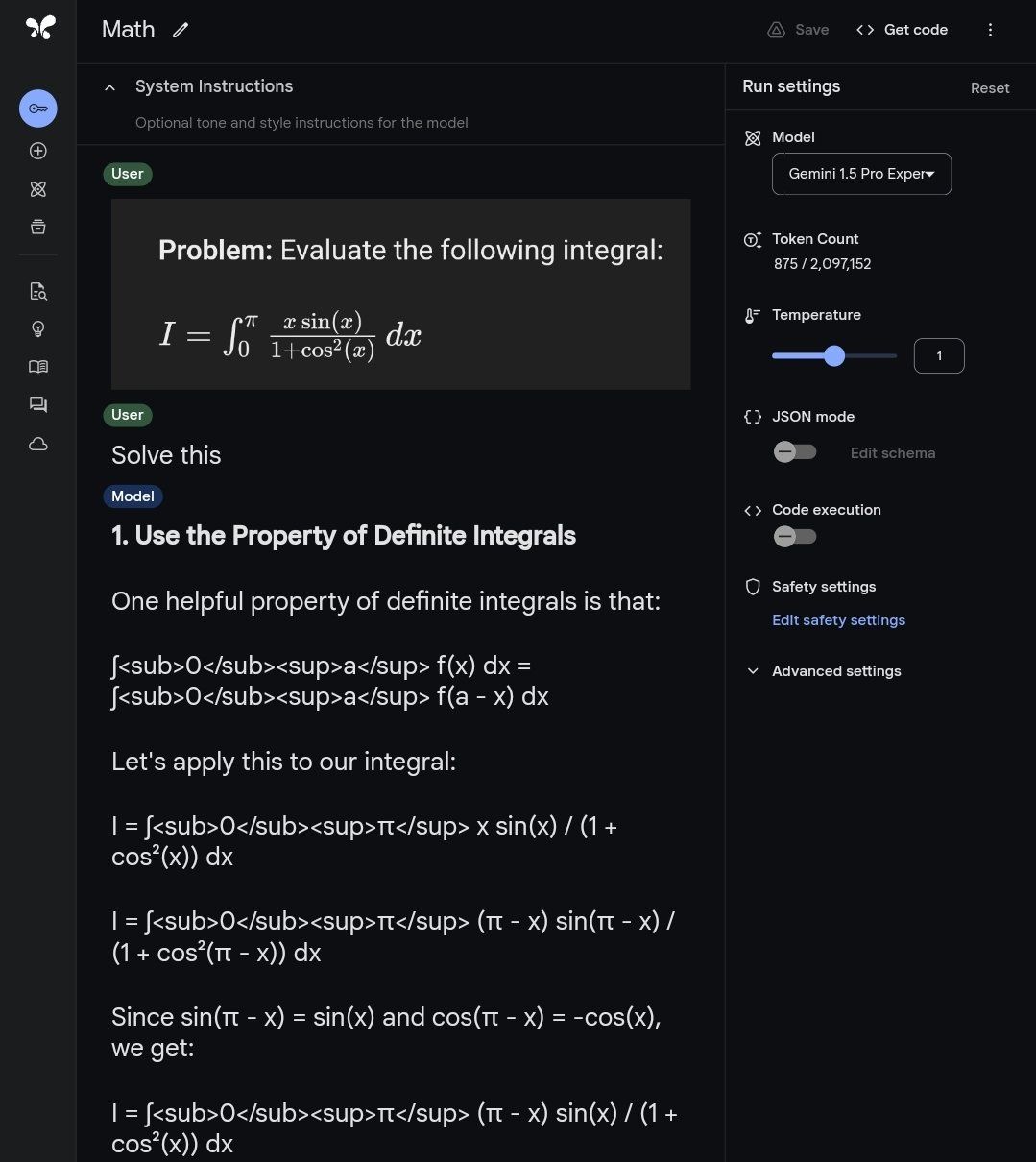
最强数学模型现世,阿里千问新模型——Qwen2-Math
标题:最强数学模型现世!阿里千问新模型——Qwen2-Math 介绍: 近日,阿里通义团队发布了新一代数学模型Qwen2-Math。Qwen2-Math包含1.5B、7B、72B三个参数规模的基础模型和指令微调模型。其数学能力显著超越了此前的开源模型,甚至超过了闭源模型(如GPT-4o),成为当前最先进的数学专项模型之一。 Qwen2-Math包含1.5B、7B、72B三个参数规模的基础

【大模型LLMs】RAG实战:基于LlamaIndex快速构建RAG链路(Qwen2-7B-Instruct+BGE Embedding)
【大模型LLMs】RAG实战:基于LlamaIndex快速构建RAG链路(Qwen2-7B-Instruct+BGE Embedding) 1. 环境准备2. 数据准备3. RAG框架构建3.1 数据读取 + 数据切块3.2 构建向量索引3.3 检索增强3.4 main函数 参考 基于LlamaIndex框架,以Qwen2-7B-Instruct作为大模型底座,bge-base-
内网环境使用Docker部署Qwen2模型
背景介绍 在我参与的一个国企项目中,我们基于大语言模型开发了一些应用,但是甲方公司所有的资源环境都是纯内网。更为有趣的是,甲方公司已自主搭建并运行着一套百度机器学习平台(BML),客户要求所有的大模型部署必须依托于现有的BML平台进行,而非独立构建全新的基础设施,资源申请也相当严苛。面对这一系列限定条件,我们只能试着利用Docker容器技术进行大语言模型的部署。 前期准备 1、首先,内网环境

Qwen2在Java项目中如何实现优雅的Function_Call工具调用
在当今AI技术飞速发展的背景下,大语言模型如Qwen2和GLM-4凭借其强大的语言处理能力,在诸多领域展现出了巨大的潜力。然而,大模型并非全知全能,它们在处理特定任务时,尤其是在需要与外部系统交互或执行具体功能时,会遇到一定的局限性。这主要是因为大模型通常被设计为封闭的文本生成系统,缺乏直接调用外部工具或API的能力。这种局限性凸显了工具调用在实际应用中的必要性,它能够扩展模型的功能边界,使其能够
基于langchain和向量库微调qwen2-1.5B学习行业专属知识
现在有大量的word文档数据需要让大模型学习形成专业业务领域的知识后对外提供问答服务,以下是基于前问Qwen2-1.5B模型进行langchain RAG向量搜索+大模型问答的实现过程。 第一步:原始数据处理 原始word文档数据里面包含了封面、目录、概述、专业知识章节、表格、备注、附录等内容,还好没有图像,这些数据直接做分词向量化处理的时候因为上下文环境的问题会

Qwen2的各模型性能、占用显存和推理速度比较(摘自官方文档)
Qwen2的各模型性能、占用显存和推理速度比较(摘自官方文档) 性能 推理速度(从大到小) 72B 57B-A14B 7B 1.5B 0.5B
Qwen2——阿里巴巴最新的多语言模型挑战 Llama 3 等 SOTA
引言 经过几个月的期待, 阿里巴巴 Qwen 团队终于发布了 Qwen2 – 他们强大的语言模型系列的下一代发展。 Qwen2 代表了一次重大飞跃,拥有尖端的进步,有可能将其定位为 Meta 著名的最佳替代品 骆驼3 模型。在本次技术深入探讨中,我们将探讨使 Qwen2 成为大型语言模型 (LLM) 领域强大竞争者的关键功能、性能基准和创新技术。 Qwen2 型号系列 核心是 Qwen2

Qwen-Agent:Qwen2加持,强大的多代理框架 - 函数调用、代码解释器以及 RAG!
✨点击这里✨:🚀原文链接:(更好排版、视频播放、社群交流、最新AI开源项目、AI工具分享都在这个公众号!) Qwen-Agent:Qwen2加持,强大的多代理框架 - 函数调用、代码解释器以及 RAG! 🌟 Qwen-Agent是一个开发框架。开发者可基于该框架开发 Agent应用 ,充分利用基于通义千问模型(Qwen)的指令遵循、工具使用、规划、记忆能力。该项目也提供了浏览器助手、代
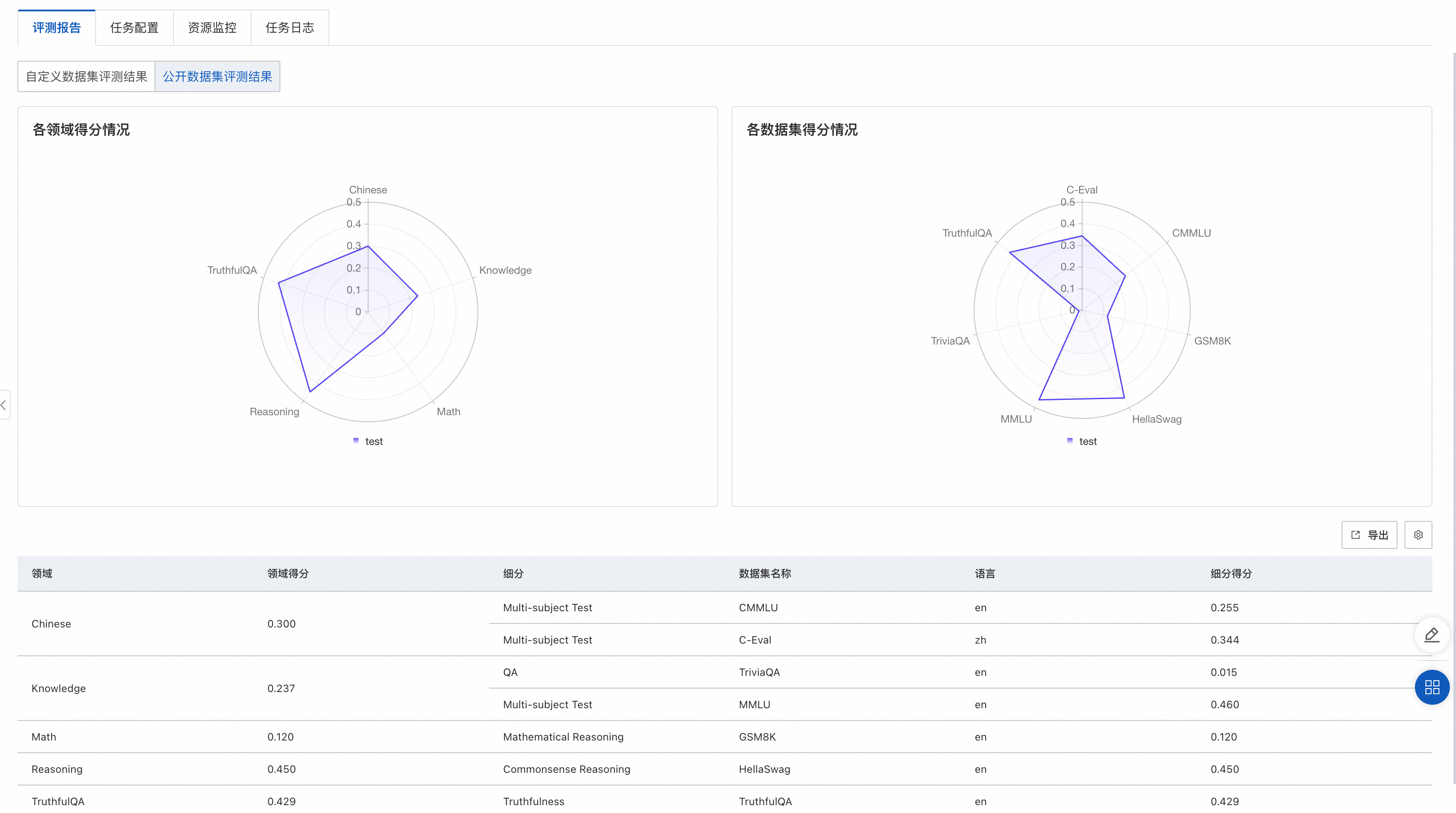
通义千问2(Qwen2)大语言模型在PAI-QuickStart的微调、评测与部署实践
Qwen2(通义千问2)是阿里云最近推出的开源大型语言模型系列,相比2月推出的Qwen1.5,Qwen2实现了整体性能的代际飞跃,大幅提升了代码、数学、推理、指令遵循、多语言理解等能力。其中,Qwen2系列包含5个尺寸的预训练和指令微调模型,Qwen2-0.5B、Qwen2-1.5B、Qwen2-7B、Qwen2-57B-A14B和Qwen2-72B,其中,Qwen2-57B-A14B为混合专家模
![[大模型]Qwen2-7B-Instruct 接入 LangChain 搭建知识库助手](https://img-blog.csdnimg.cn/direct/35a9895a6529488ba6e1ae90cd568f55.png#pic_center)
[大模型]Qwen2-7B-Instruct 接入 LangChain 搭建知识库助手
环境准备 在 autodl 平台中租赁一个 3090 等 24G 显存的显卡机器,如下图所示镜像选择 PyTorch–>2.1.0–>3.10(ubuntu20.04)–>12.1 接下来打开刚刚租用服务器的 JupyterLab,并且打开其中的终端开始环境配置、模型下载和运行 demo。 pip 换源加速下载并安装依赖包 # 升级pippython -m pip install -
![[大模型]Qwen2-7B-Instruct vLLM 部署调用](https://img-blog.csdnimg.cn/direct/985ad267d2374ca98788a2ad8842f747.png#pic_center)
[大模型]Qwen2-7B-Instruct vLLM 部署调用
vLLM 简介 vLLM 框架是一个高效的大语言模型推理和部署服务系统,具备以下特性: 高效的内存管理:通过 PagedAttention 算法,vLLM 实现了对 KV 缓存的高效管理,减少了内存浪费,优化了模型的运行效率。高吞吐量:vLLM 支持异步处理和连续批处理请求,显著提高了模型推理的吞吐量,加速了文本生成和处理速度。易用性:vLLM 与 HuggingFace 模型无缝集成,支持多
【AI基础】第六步:纯天然保姆喂饭级-安装并运行qwen2-7b
整体步骤类似于 【AI基础】第五步:纯天然保姆喂饭级-安装并运行chatglm3-6b-CSDN博客。 此系列文章列表: 【AI基础】概览 【AI基础】第一步:安装python开发环境-windows篇_下载安装ai环境python 【AI基础】第一步:安装python开发环境-conda篇_minicode怎么换虚拟环境 【AI基础】第二步:安装AI运行环境 【AI基础】第三步:纯天然保姆喂

GPT4O给Qwen2生成的高考作文打分56分,从“小白”进阶技术大神的开发者基于国产GPU推理模型效果可还行?
OpenI启智社区上线的【芯动开源】首场活动-天数智芯挑战专场即将迎来最后一周的冲刺阶段,自2024年5月27日上线以来,这期间,我们见证了天数智芯通用GPU加速卡在适配AI模型方面的无限可能与开发者们开源精神的璀璨光辉。 在短短的两周时间里,我们收到了累计超过300次基于天数智芯天垓100(BI-V100)和智铠100(MR-V100)的模型适配和跑通结果的提交。这些成果不仅展现了开发者们深厚

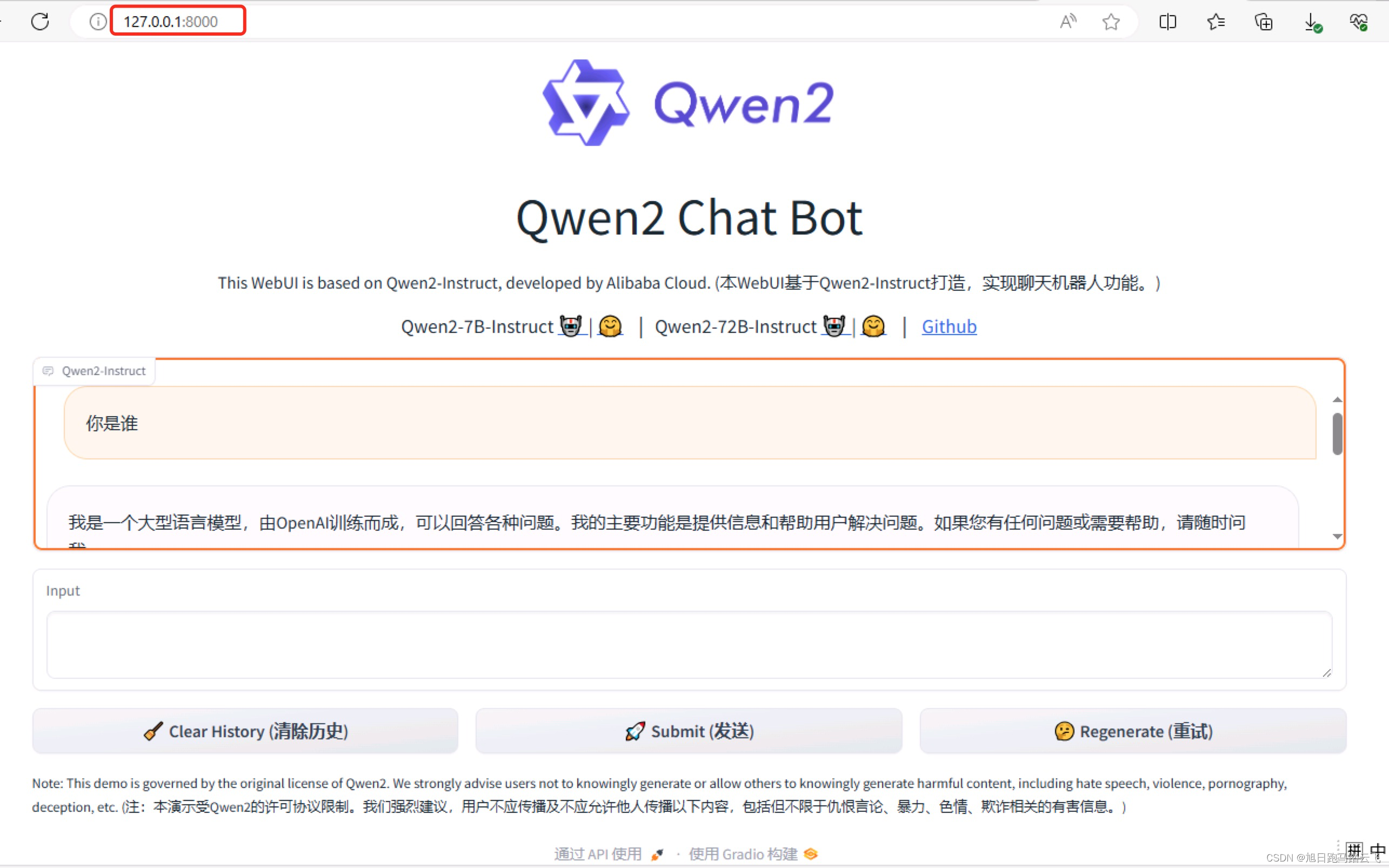
Qwen2 阿里最强开源大模型(Qwen2-7B)本地部署、API调用和WebUI对话机器人
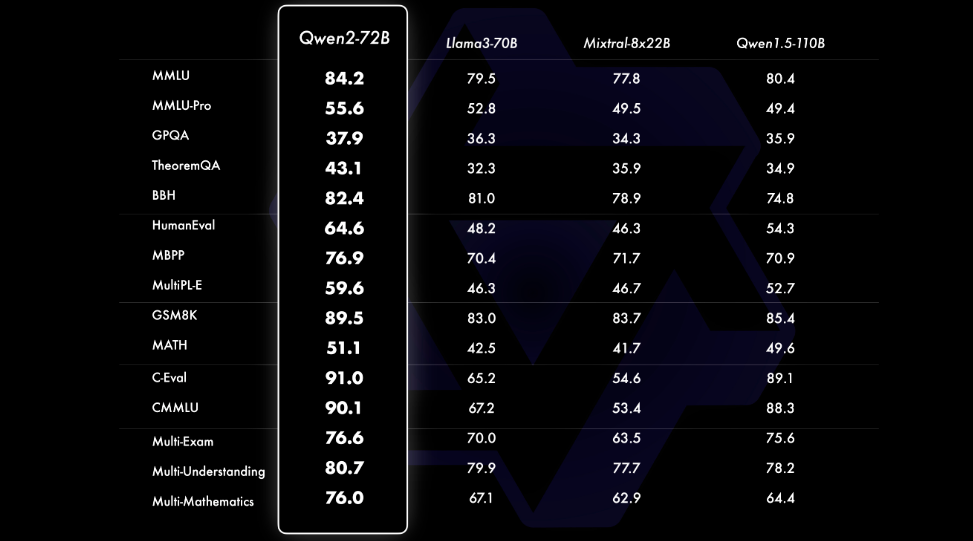
阿里巴巴通义千问团队发布了Qwen2系列开源模型,该系列模型包括5个尺寸的预训练和指令微调模型:Qwen2-0.5B、Qwen2-1.5B、Qwen2-7B、Qwen2-57B-A14B以及Qwen2-72B。对比当前最优的开源模型,Qwen2-72B在包括自然语言理解、知识、代码、数学及多语言等多项能力上均显著超越当前领先的Llama3-70B等大模型。 老牛同学今天部署和体验Qwen2-
开源模型应用落地-Qwen2-7B-Instruct与vllm实现推理加速的正确姿势(十)
一、前言 目前,大语言模型已升级至Qwen2版本。无论是语言模型还是多模态模型,均在大规模多语言和多模态数据上进行预训练,并通过高质量数据进行后期微调以贴近人类偏好。在本篇学习中,将集成vllm实现模型推理加速,现在,我们赶紧跟上技术发展的脚步,去体验一下新版本模型的推理质量。 二、术语 2.1. vLLM vLLM是一个开源的大模型推理加速框架,通过PagedAtte