本文主要是介绍通义千问2(Qwen2)大语言模型在PAI-QuickStart的微调、评测与部署实践,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Qwen2(通义千问2)是阿里云最近推出的开源大型语言模型系列,相比2月推出的Qwen1.5,Qwen2实现了整体性能的代际飞跃,大幅提升了代码、数学、推理、指令遵循、多语言理解等能力。其中,Qwen2系列包含5个尺寸的预训练和指令微调模型,Qwen2-0.5B、Qwen2-1.5B、Qwen2-7B、Qwen2-57B-A14B和Qwen2-72B,其中,Qwen2-57B-A14B为混合专家模型(MoE)。Qwen2所有尺寸模型都使用了GQA(分组查询注意力)机制,以便让用户体验到GQA带来的推理加速和显存占用降低的优势。阿里云的人工智能平台PAI,作为一站式的机器学习和深度学习平台,对Qwen2模型系列提供了全面的技术支持。无论是开发者还是企业客户,都可以通过PAI-QuickStart轻松实现Qwen2系列模型的微调、评测和快速部署。
PAI-QuickStart 介绍
快速开始(PAI-QuickStart)是阿里云人工智能平台PAI的产品组件,它集成了国内外 AI 开源社区中优质的预训练模型,涵盖了包括大语言模型,文本生成图片、语音识别等各个领域。通过 PAI 对于这些模型的适配,用户可以通过零代码和 SDK 的方式实现从训练到部署再到推理的全过程,大大简化了模型的开发流程,为开发者和企业用户带来了更快、更高效、更便捷的 AI 开发和应用体验。
运行环境要求
-
本示例目前支持在阿里云北京、上海、深圳、杭州、乌兰察布等多地域,使用PAI-QuickStart产品运行。
-
资源配置要求:
-
Qwen2-0.5B/1.5B/7B量级模型:最低使用V100/P100/T4(16GB显存)及以上卡型运行训练任务;
-
Qwen1.5-72B量级模型:最低使用A100(80GB显存)及以上卡型运行训练任务。
通过PAI-QuickStart使用模型
开发者可以在 PAI 控制台的“快速开始”入口,找到Qwen2系列模型,以Qwen2-7B-Instruct为例,模型卡片如下图所示:
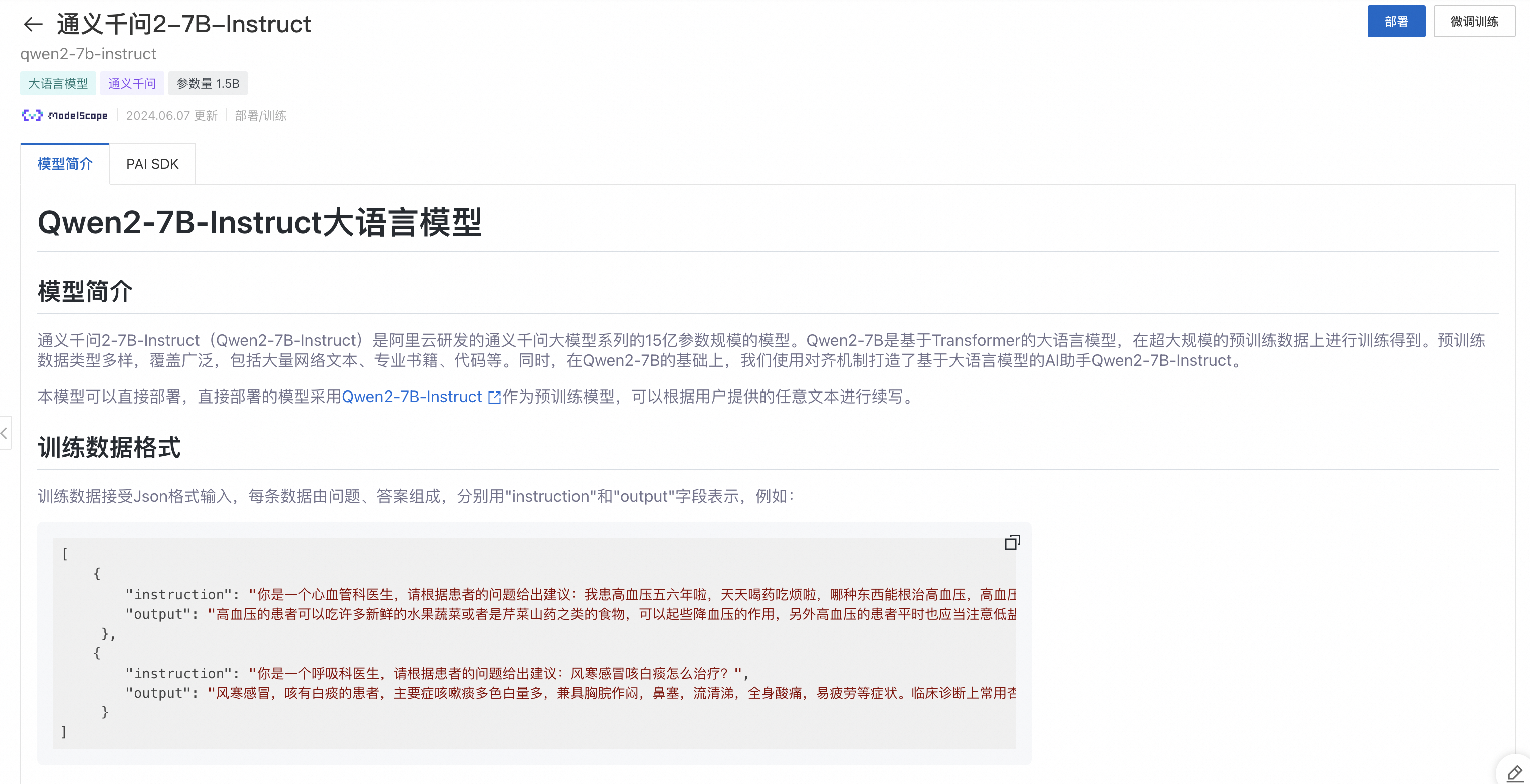
模型部署和调用
PAI 提供的Qwen2-7B-Instruct预置了模型的部署配置信息,用户仅需提供推理服务的名称以及部署配置使用的资源信息即可将模型部署到PAI-EAS推理服务平台。当前模型需要使用公共资源组进行部署。

部署的推理服务支持使用ChatLLM WebUI进行实时交互,示例如下:
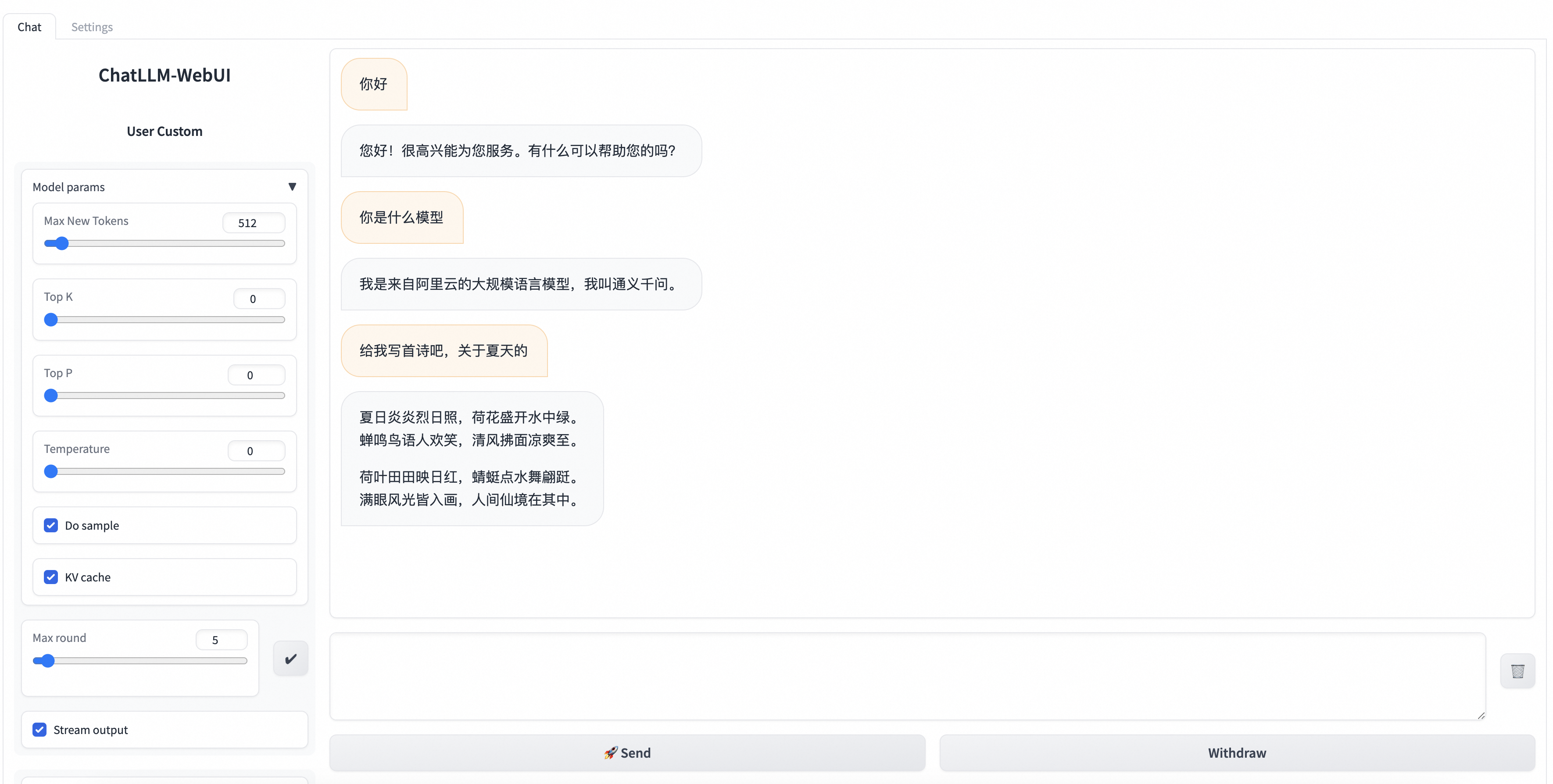
推理服务支持以OpenAI API兼容的方式调用,具体可见以下的Python SDK的示例。
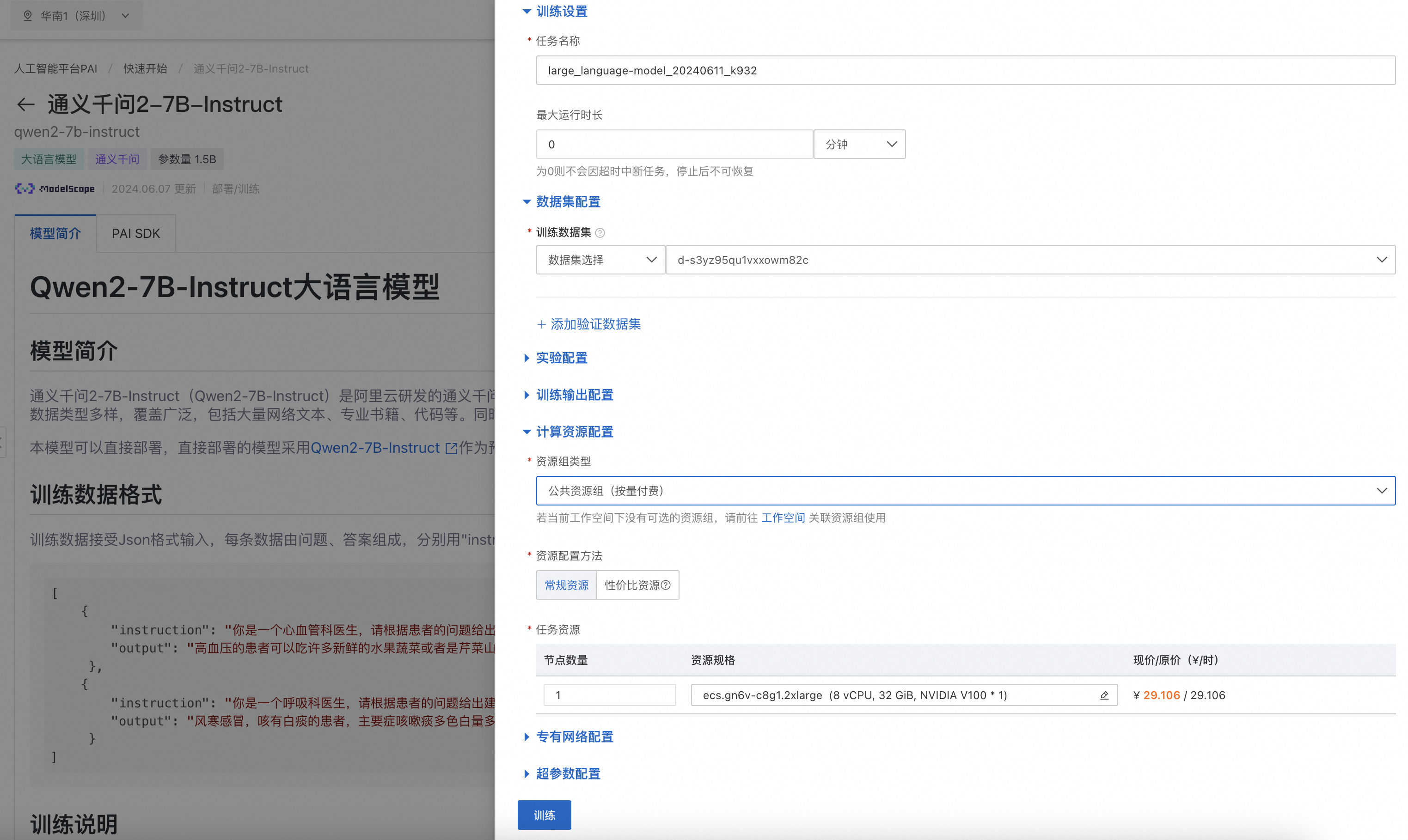
模型微调训练
PAI 为Qwen2-7B-Instruct模型配置了微调算法,支持用户以开箱即用得方式对Qwen2-7B-Instruct进行微调。训练算法支持使用 Json 格式输入,每条数据由问题、答案组成,分用“instruction”、“output”字段表示,例如:
[{"instruction": "你是一个心血管科医生,请根据患者的问题给出建议:我患高血压五六年啦,天天喝药吃烦啦,哪种东西能根治高血压,高血压克星是什么?","output": "高血压的患者可以吃许多新鲜的水果蔬菜或者是芹菜山药之类的食物,可以起些降血压的作用,另外高血压的患者平时也应当注意低盐,低脂,低胆固醇饮食,适当的实施体育运动和锻练高血压的患者还应当在医生的指导下口服降血压的药物,断然不可擅自停药,防止对血压引发影响。" },{"instruction": "你是一个呼吸科医生,请根据患者的问题给出建议:风寒感冒咳白痰怎么治疗?","output": "风寒感冒,咳有白痰的患者,主要症咳嗽痰多色白量多,兼具胸脘作闷,鼻塞,流清涕,全身酸痛,易疲劳等症状。临床诊断上常用杏苏散和二陈丸实施治疗。在用药物治疗的同时,应忌食辛辣刺激性的食物和寒凉性食物,多吃易消化营养丰富的食物,宜清淡饮食,留意歇息。" }
]
当完成数据的准备,用户可以将数据上传到对象存储 OSS Bucket 中。算法需要使用V100/P00/T4(16GB显存)的GPU资源,请确保选择使用的资源配额内有充足的计算资源。
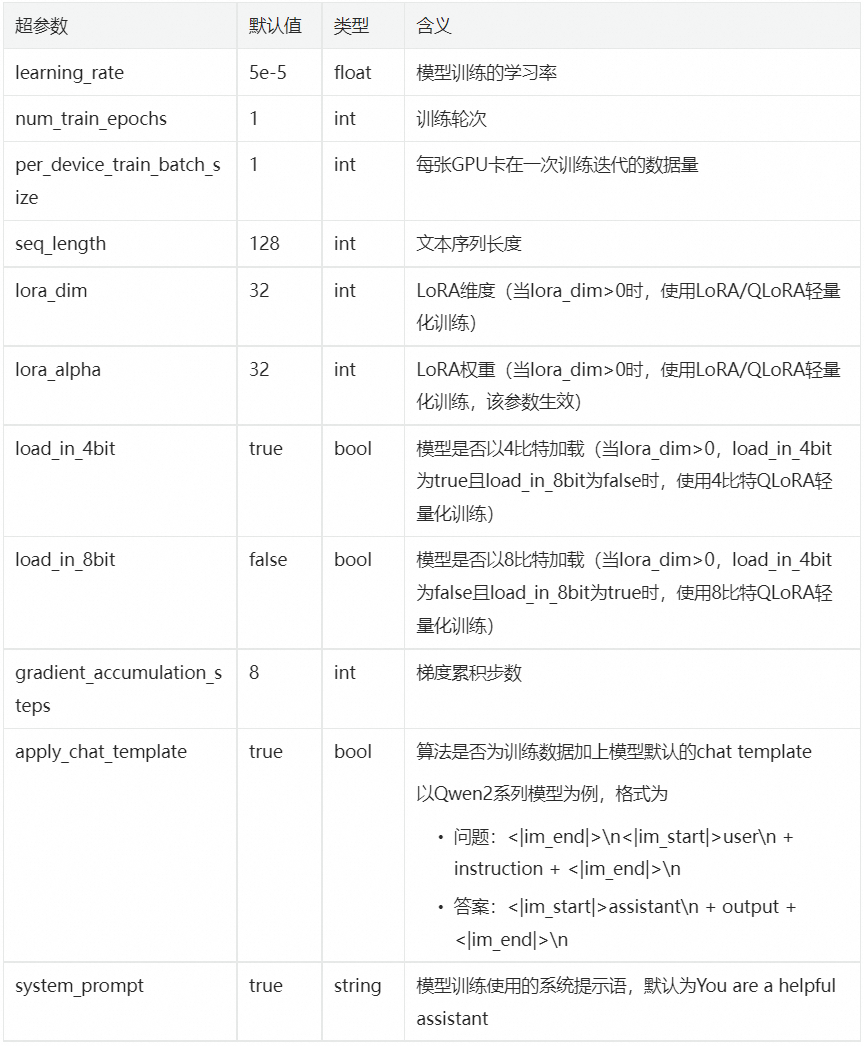
训练算法支持的超参信息如下,用户可以根据使用的数据,计算资源等调整超参,或是使用算法默认配置的超参。
点击“训练”按钮,PAI-QuickStart 开始进行训练,用户可以查看训练任务状态和训练日志。
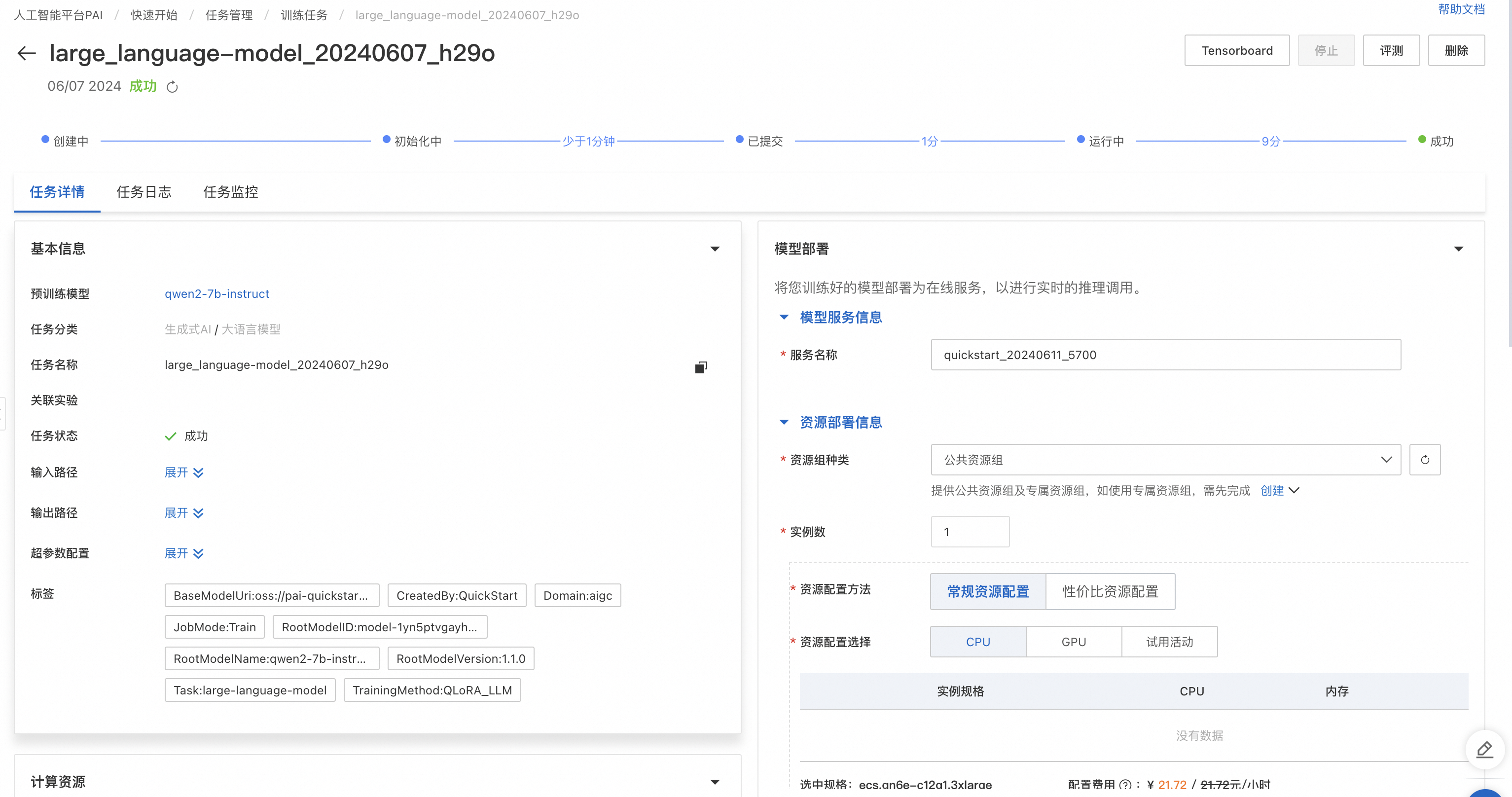
如果需要将模型部署至PAI-EAS,可以在同一页面的模型部署卡面选择资源组,并且点击“部署”按钮实现一键部署。模型调用方式和上文直接部署模型的调用方式相同。如果需要评测微调后模型的性能,可以从任务页面右上角评测按钮进入评测页。详情见下一节:模型评测。
模型评测
PAI 为Qwen2-7B-Instruct模型配置了评测算法,支持用户以开箱即用得方式对Qwen2-7B-Instruc以及微调后模型进行评测。通过评测能帮助用户和其他模型做性能对比,更能指导用户进行精准地模型选择和优化。模型评测入口:
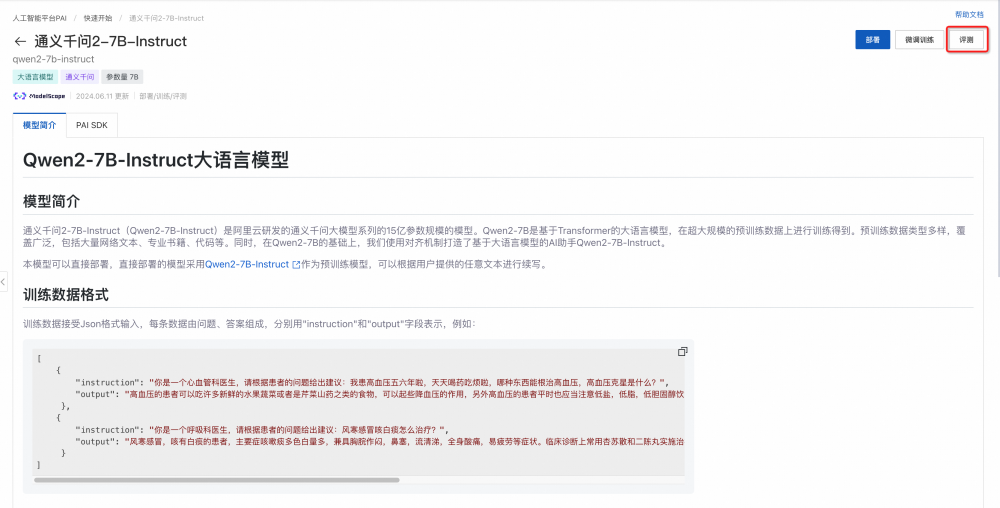
从“快速开始”页面完成Qwen2-7B-Instruct开源模型的评测
从训练任务详情页完成微调后模型的评测

模型评测支持自定义数据集评测和公开数据集评测:
-
自定义数据集评测
对于自定义数据集评测,我们使用NLP领域标准的文本匹配方式,计算模型输出结果和真实结果的匹配度,值越大,模型越好。使用该评测方式,基于自己场景的独特数据,可以评测所选模型是否适合自己的场景。评测需要提供JSONL格式的评测集文件,每条数据使用question标识问题列,answer标识答案列,例如:
[{"question": "中国发明了造纸术,是否正确?", "answer": "正确"}]
[{"question": "中国发明了火药,是否正确?", "answer": "正确"}]
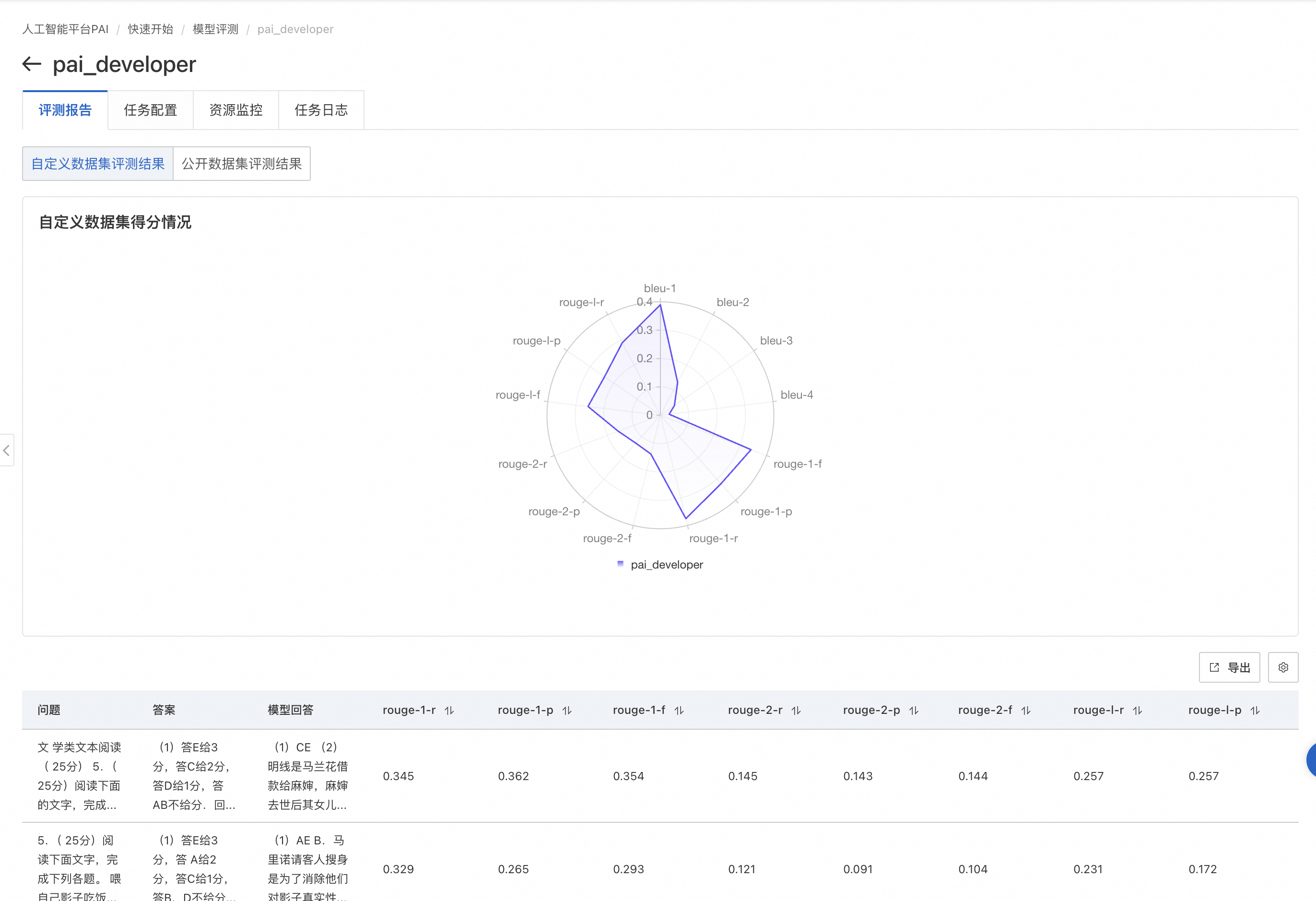
符合格式要求的评测集,可自行上传至OSS,并创建自定义数据集,详情参见上传OSS文件和创建及管理数据集。之后选择评测结果输出路径,并根据系统推荐选择相应计算资源,最后提交评测任务。等待任务完成,在任务页面查看评测结果(模型在ROUGE和BLEU系列指标上的得分):
-
公开数据集评测
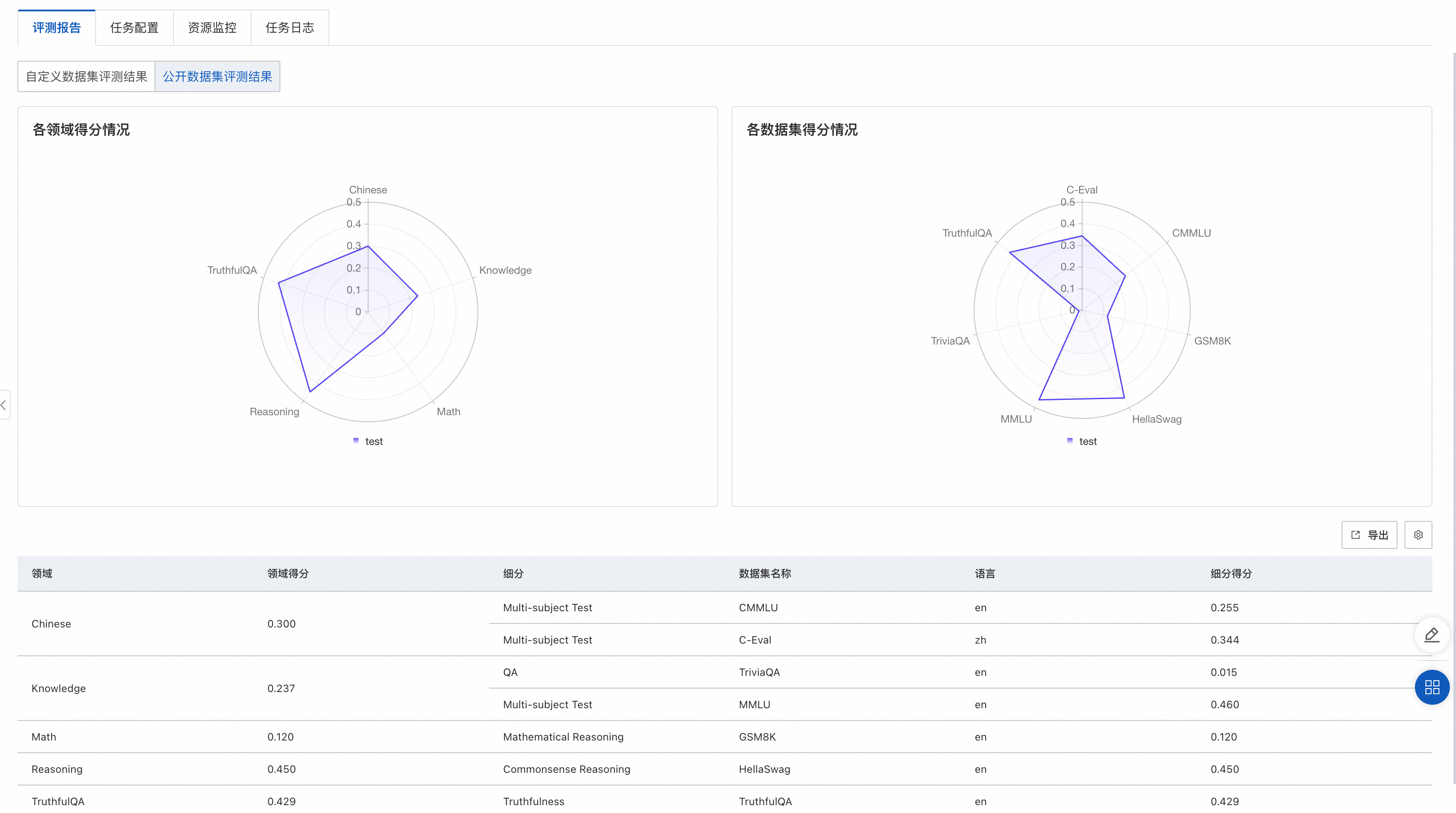
在公开数据集评测中,我们通过对开源的评测数据集按领域分类,对大模型进行综合能力评估,例如数学能力、知识能力、推理能力等,值越大,模型越好。目前PAI维护了MMLU、TriviaQA、HellaSwag、GSM8K、C-Eval、TruthfulQA,其他公开数据集陆续接入中。无需准备数据,直接选择PAI提供的公开数据集、评测结果输出路径、计算资源即可提交评测任务。等待任务完成,在任务页面查看评测结果(模型在各个公开数据集的得分情况,其中每个公开数据集的评测范围详见数据集官方介绍):
通过Python SDK使用
PAI 提供了Python SDK,支持开发者方便得使用Python在PAI完成模型的开发到上线的。通过PAI Python SDK,开发者可以轻松调用PAI-快速开始提供的模型,完成相应模型的微调训练和部署。部署推理服务的示例代码如下:
from pai.model import RegisteredModel
from openai import OpenAI# 获取PAI提供的模型
model = RegisteredModel(model_name="qwen2-7b-instruct",model_provider="pai"
)# 直接部署模型
predictor = model.deploy(service="qwen2_7b_instruct_example"
)# 构建openai client,使用的OPENAI_BASE_URL为: <ServiceEndpint> + "/v1/"
openai_client: OpenAI = predictor.openai()# 通过openai SDK调用推理服务
resp = openai_client.chat.completions.create(messages=[{"role": "system", "content": "You are a helpful assistant."},{"role": "user", "content": "What is the meaning of life?"},],# 默认的model name为"default"model="default"
)print(resp.choices[0].message.content)# 测试完成之后,删除推理服务predictor.delete_service()
微调训练的示例代码如下:
# 获取模型的微调训练算法
est = model.get_estimator()# 获取PAI提供的公共读数据和预训练模型
training_inputs = model.get_estimator_inputs()# 使用用户自定义数据
# training_inputs.update(
# {
# "train": "<训练数据集OSS或是本地路径>",
# "validation": "<验证数据集的OSS或是本地路径>"
# }
# )# 使用默认数据提交训练任务
est.fit(inputs=training_inputs
)# 查看训练产出模型的OSS路径
print(est.model_data())
通过快速开始的模型卡片详情页,用户可以通过“在DSW打开”入口,获取一个完整的Notebooks示例,了解如何通过PAI Python SDK使用的细节。
结论
Qwen2(通义千问2)的推出标志着阿里云在开源大语言模型领域的最新进展。这个系列推出了不同规模的开源模型,可广泛用于多样化的下游应用场景。开发者可以借助PAI-QuickStart轻松地对Qwen2模型进行定制和部署。此外,PAI QuickStart还汇集了一系列先进的模型,覆盖多个专业领域,欢迎广大开发者们体验和应用这些丰富的资源。
相关资源链接:
-
Qwen2介绍:
你好,Qwen2 | Qwen
-
PAI 快速开始:
PAI快速开始功能的介绍/计费/权限/开通/使用_人工智能平台 PAI(PAI)-阿里云帮助中心
-
PAI Python SDK Github:
GitHub - aliyun/pai-python-sdk: A HighLevel Python SDK helps you to train and deploy your model on PAI.
这篇关于通义千问2(Qwen2)大语言模型在PAI-QuickStart的微调、评测与部署实践的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



