本文主要是介绍最强数学模型现世,阿里千问新模型——Qwen2-Math,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
标题:最强数学模型现世!阿里千问新模型——Qwen2-Math
介绍:
近日,阿里通义团队发布了新一代数学模型Qwen2-Math。Qwen2-Math包含1.5B、7B、72B三个参数规模的基础模型和指令微调模型。其数学能力显著超越了此前的开源模型,甚至超过了闭源模型(如GPT-4o),成为当前最先进的数学专项模型之一。
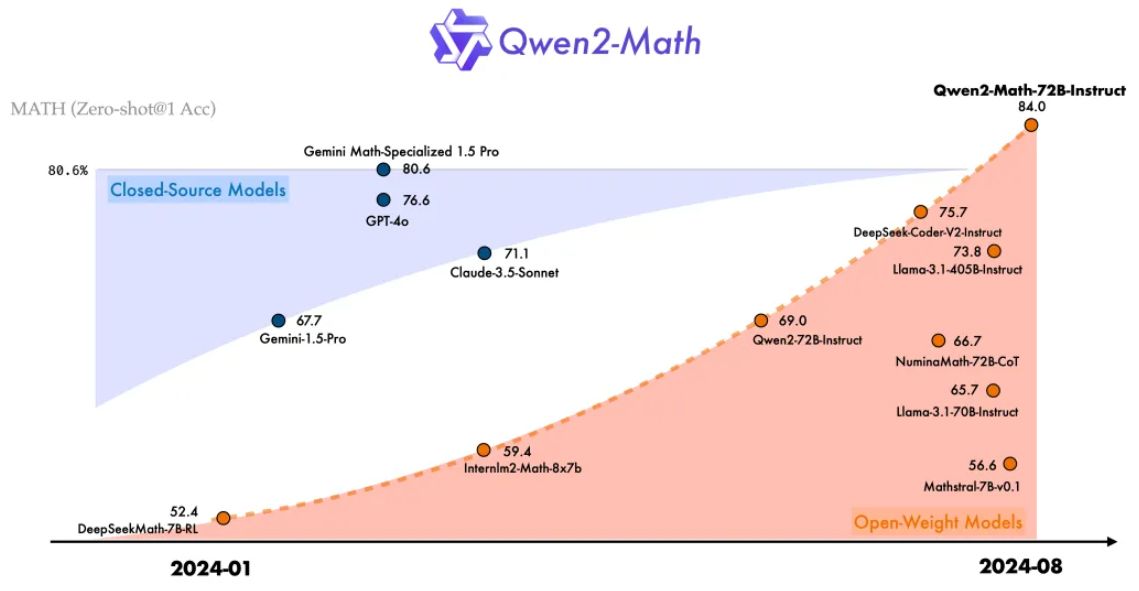
Qwen2-Math包含1.5B、7B、72B三个参数规模的基础模型和指令微调模型,其中,基础模型72B版本在备受瞩目的MATH数据集上表现出色,相较于GPT-4o,它额外斩获了7分,这一优势相当于提升了9.6%的准确率。

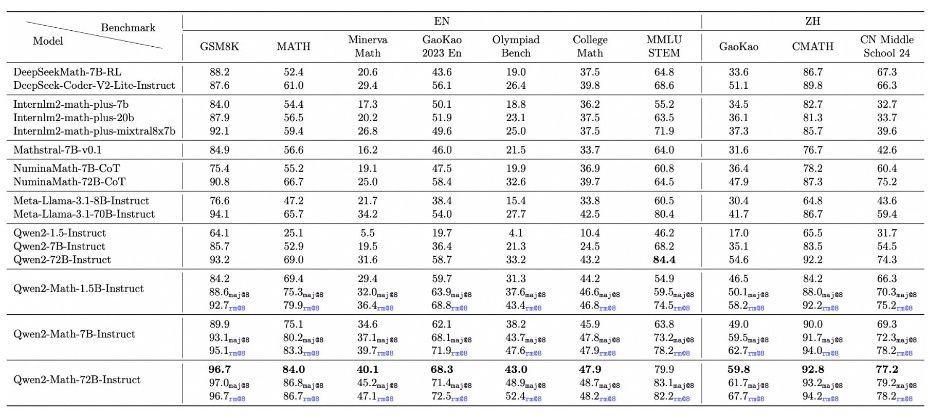
为了考验Qwen2-Math基础模型的数学能力,团队设计了一套数学试卷,该试卷融合了三个广泛应用的英语数学基准测试集——GSM8K(针对小学数学)、Math以及MMLU-STEM,同时纳入了三个专为中国学生设计的数学基准——CMATH、高考数学小题以及高考数学大题。根据这些基准测试集的得分结果,通义千问的Qwen2-Math基础模型展现出了显著的领先优势,成绩“遥遥领先”于其他同类模型。

指令调优模型Qwen2-Math-Instruct是阿里通义团队在Qwen2大语言模型基础上,专为数学解题领域开发的进阶模型。包含多个参数规模,如72B、7B、1.5B等,其中72B版本为旗舰款。
指令微调模型基于Qwen2-Math-72B训练一个数学专用的奖励模型,用于评估模型的数学解题表现。将密集的奖励信号与指示模型是否正确回答问题的二元信号结合,用作学习标签。通过拒绝采样构建监督微调(SFT)数据,对基础模型进行指令微调。在SFT模型基础上,使用GRPO(一种强化学习方法)进一步优化模型,提升其数学解题的准确性和效率。

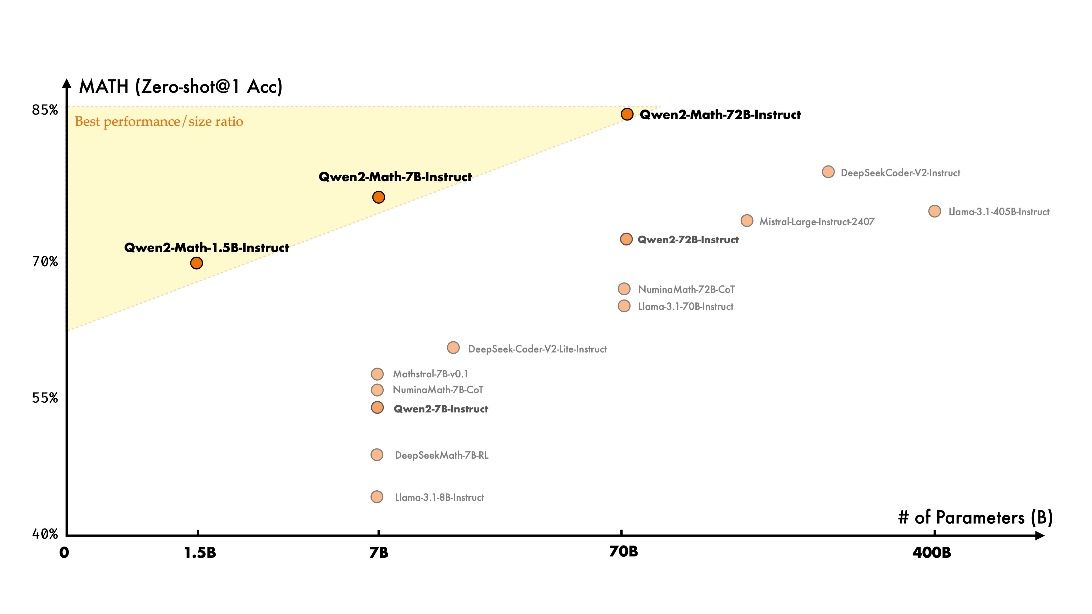
在权威的数学基准评测集MATH上,在MATH数据集上进行的零样本测试里,参数量为1.5B的Instruct模型以70%的准确率,超越了参数量达到70B的Llama 3.1模型。
Qwen2-Math-72B-Instruct以84%的准确率处理了代数、几何、计数与概率、数论等多种数学问题,这一成绩超越了GPT-4.0、Claude-3.5-Sonnet、Gemini-1.5-Pro和Llama-3.1-405B等主流模型。
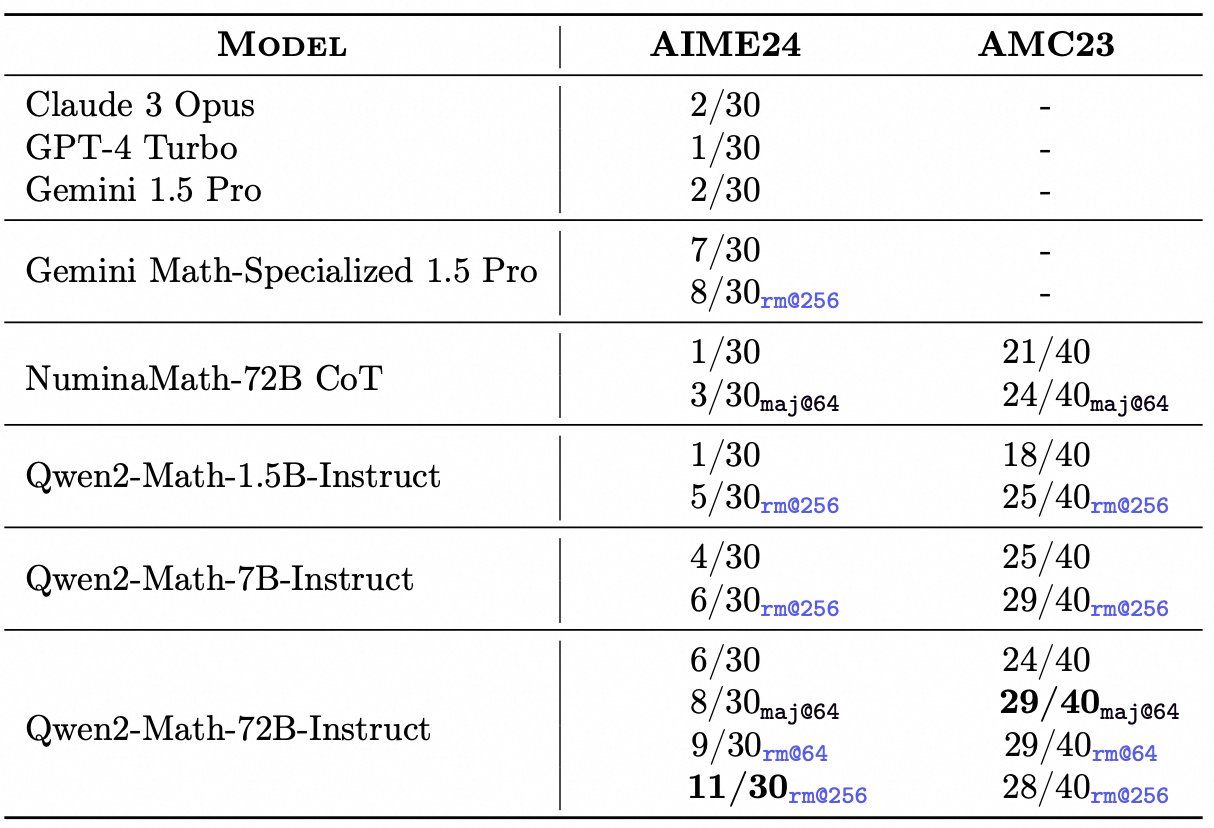
Qwen2-Math-Instruct模型已显示出对部分竞赛级简单试题的解答能力。在AIME 24的试题集中,利用rm@256策略,其72B-Instruct版本脱颖而出,正确解答了11道题目。相比之下,诸如GPT-4 Turbo、Claude 3 Opus以及Gemini 1.5 PRo等尖端模型,它们的表现均显得逊色,仅能解答出一两道题目。尤为值得一提的是,即便是Qwen2-Math系列中规模最小的1.5B版本,在相同的rm@256条件下,也成功解答了五道题目,这一成绩已超越了前面提到的所有模型。
尽管Gemini 1.5 Pro特别推出了针对数学任务的优化版本,但在面对这些试题时,其解答正确的题目数量仍停留在七八道左右。而Qwen2-Math-72B-Instruct则以其出色的表现,成为了首个解答题目数量达到两位数(即超过十道)的模型,这无疑再次证明了其在数学解题领域的领先地位。
Qwen2-Math模型答题展示
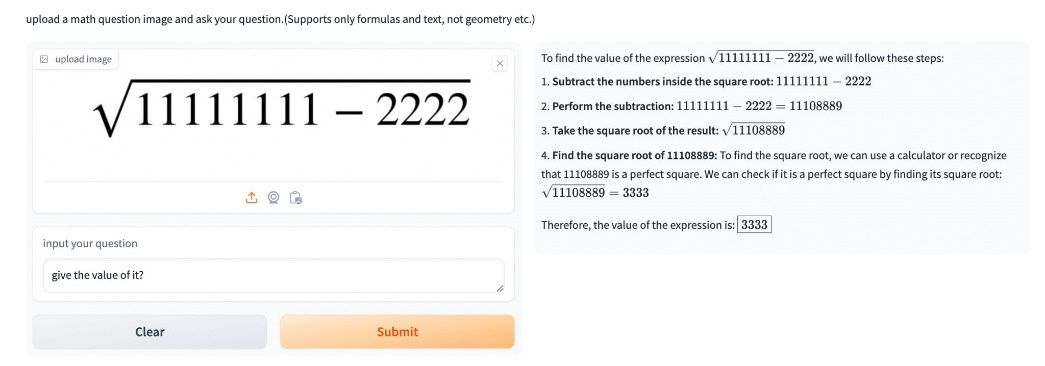
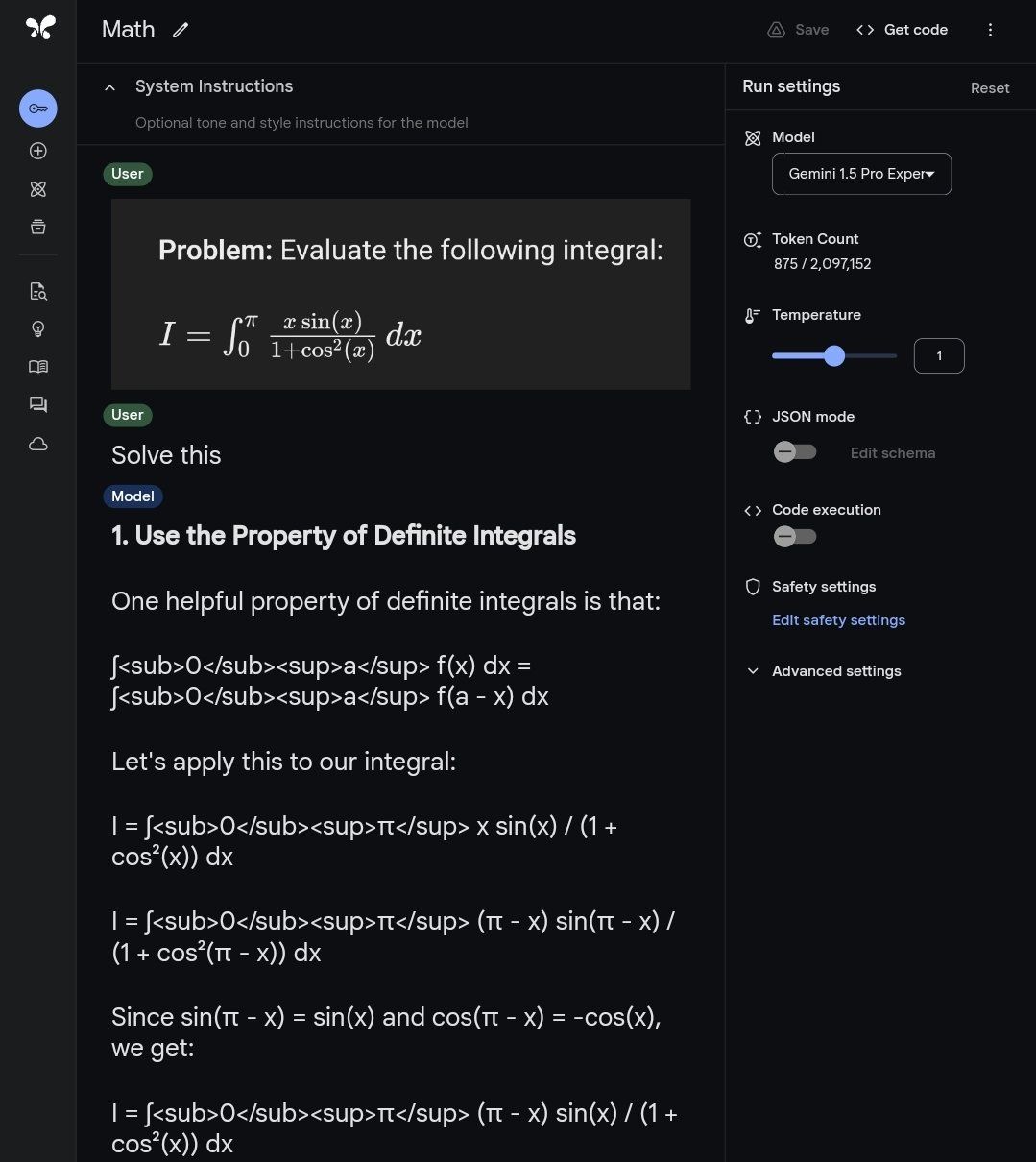
目前Qwen2-Math主要支持英文,中英双语和多语言模型正在开发中,多语言支持提上日程。
Qwen2-Math团队在训练模型时采用了高质量的数学专用语料库,并通过严格的评估验证了模型在数学解题方面的卓越能力,未来,团队将继续优化模型的性能,包括但不限于提高解题准确率、加快解题速度、扩展解题范围等。
这篇关于最强数学模型现世,阿里千问新模型——Qwen2-Math的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









