本文主要是介绍MLLM(二)| 阿里开源视频理解大模型:Qwen2-VL,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

2024年8月29日,阿里发布了 Qwen2-VL!Qwen2-VL 是基于 Qwen2 的最新视觉语言大模型。与 Qwen-VL 相比,Qwen2-VL 具有以下能力:
- SoTA对各种分辨率和比例的图像的理解:Qwen2-VL在视觉理解基准上达到了最先进的性能,包括MathVista、DocVQA、RealWorldQA、MTVQA等。
- 理解 20 分钟+ 的视频:Qwen2-VL 可以理解 20 分钟以上的视频,以进行高质量的基于视频的问答、对话、内容创建等。
- 可以操作您的手机、机器人等的代理:Qwen2-VL 具有复杂的推理和决策能力,可以与手机、机器人等设备集成,根据视觉环境和文本指令进行自动操作。
- 多语言支持:为了服务全球用户,除了英文和中文外,Qwen2-VL 现在还支持理解图像中不同语言的文本,包括大多数欧洲语言、日语、韩语、阿拉伯语、越南语等。
Qwen2-VL-2B 和 Qwen2-VL-7B模型开源了, Qwen2-VL-72B只开源了API!开源模型已集成到 Hugging Face Transformers、vLLM 和其他第三方框架中。
一、性能
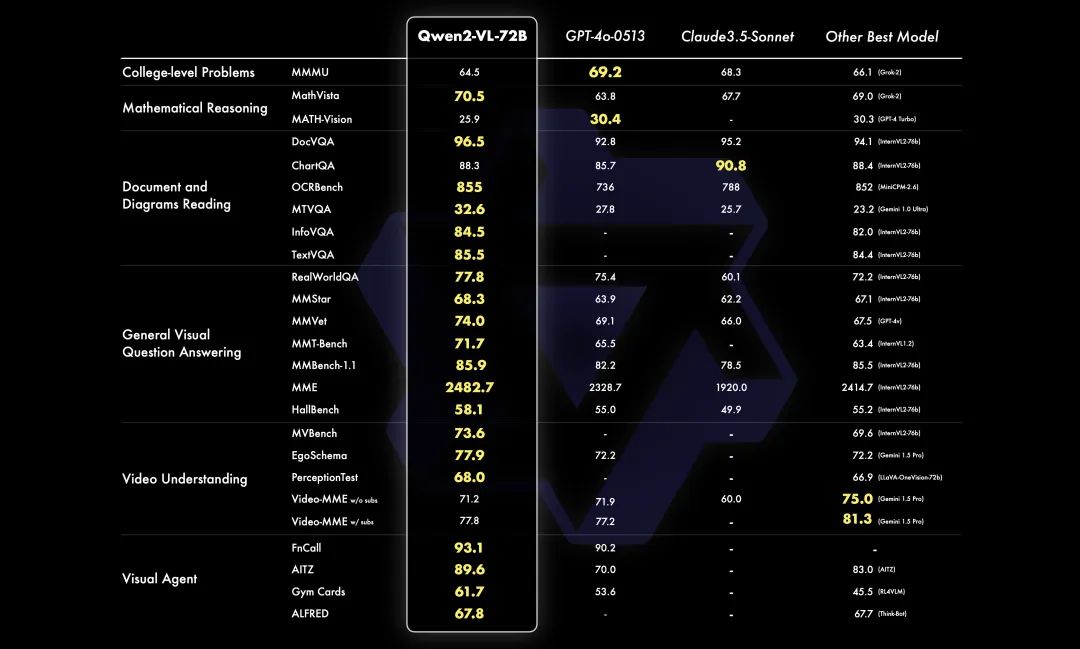
72B:
从六个关键维度评估模型的视觉能力:复杂的大学水平问题解决、数学能力、文档和表格理解、多语言文本图像理解、一般场景问答、视频理解和基于代理的交互。总体而言, 72B 模型在大多数指标上都展示了顶级性能,甚至超过了 GPT-4o 和 Claude 3.5-Sonnet 等闭源模型。值得注意的是,它在文档理解方面表现出显着优势。
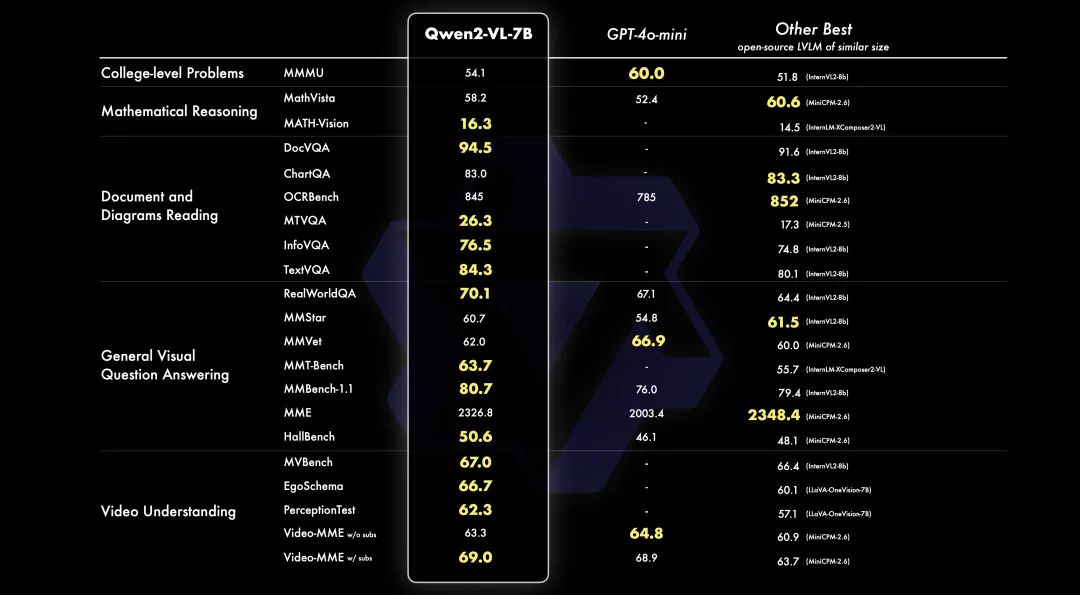
7B:
在 7B 模型上,保留了对图像、多图像和视频输入的支持,以更具成本效益的模型大小提供有竞争力的性能。具体来说,在 DocVQA 等文档理解任务和图像中的多语言文本理解方面表现出色。
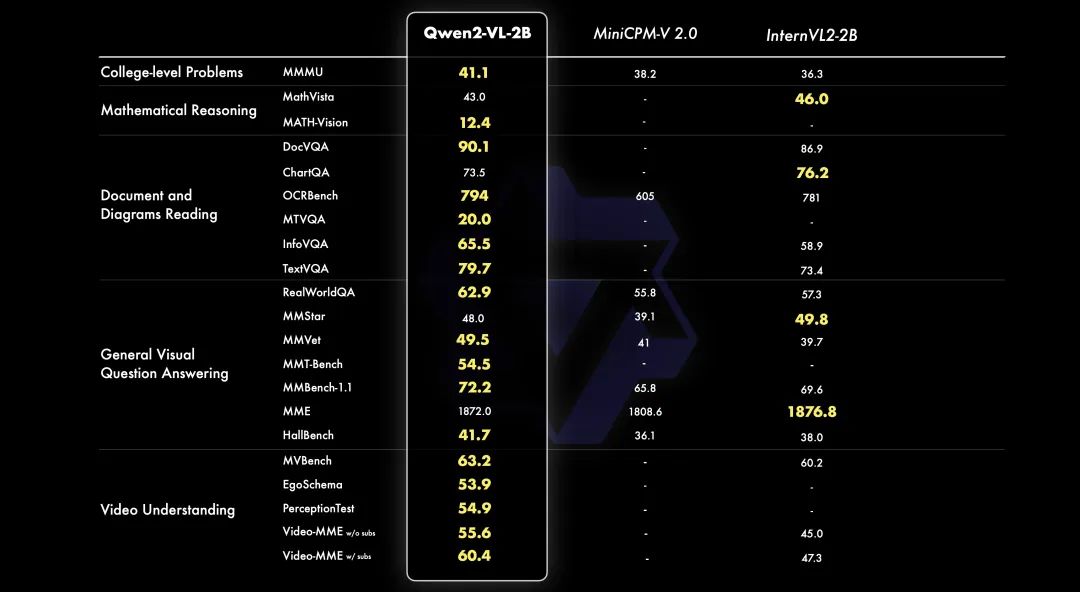
2B:
此外,更小的 2B 模型针对潜在的移动部署进行了优化。尽管体积小巧,但该模型在图像、视频和多语言理解方面拥有强大的性能。与其他类似规模的模型相比,它在与视频相关的任务、文档理解和一般场景问答方面尤其突出。
二、模型任务表现
2.1 增强的识别功能
Qwen2-VL 现在拥有改进的对象识别功能,超越了植物和地标,可以理解场景中多个对象之间的复杂关系。我们还显著提高了该模型识别图像中的手写文本和多种语言的能力,使其更易于全球用户访问。
示例:多对象识别
User:Output the color and number of each box.
输出每个框的颜色和编号。

Qwen2-VL:
The image shows a stack of colorful blocks with numbers on them. Here is the color and number of each block from top to bottom:
该图像显示了一堆带有数字的彩色块。以下是每个块的颜色和编号,从上到下:
-
Top row (single block): Blue with the number 9
顶行(单个块):带有数字 9 的蓝色 -
Second row (two blocks): Light blue with the number 7, and green with the number 8
第二行(两个块):浅蓝色的数字 7 和绿色的数字 8 -
Third row (three blocks): Purple with the number 4, pink with the number 5, and light green with the number 6
第三行(三个块):紫色的数字 4、粉红色的数字 5 和浅绿色的数字 6 -
Bottom row (four blocks): Red with the number 0, orange with the number 1, yellow with the number 2, and light green with the number 3
底行(四个块):红色的数字 0、橙色的数字 1、黄色的数字 2 和浅绿色的数字 3
2.2 视觉推理:解决现实世界的问题
在这次迭代中,显著提高了 Qwen2-VL 的数学和编码能力。该模型不仅能够通过分析图片来解决问题,还可以通过图表分析来解释和解决复杂的数学问题。极度纵横比失真的图像也可以被正确解释。此外,还增强了模型从真实世界图像和图表中提取信息的能力,并提高了其指令跟踪技能。这种视觉感知和逻辑推理的融合使模型能够解决实际问题,弥合抽象概念和有形解决方案之间的差距。
示例:数学
User 用户
Find the length of AC in the isosceles triangle ABC.
求等腰三角形 ABC 中 AC 的长度。
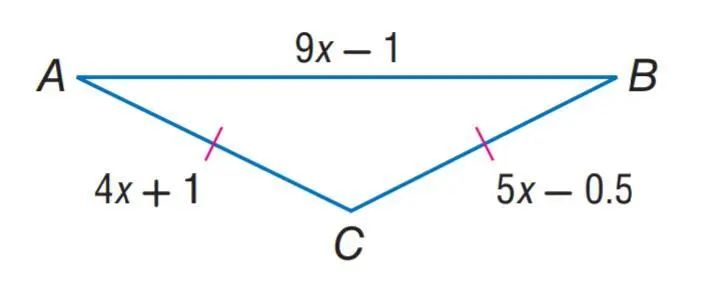
Qwen2-VL
Since triangle ABC is isosceles, we know that AC = BC. Therefore, we can set the expressions for AC and BC equal to each other and solve for x:
由于三角形 ABC 是等腰三角形,我们知道 AC = BC。因此,我们可以将 AC 和 BC 的表达式设置为彼此相等并求解 x:
4x + 1 = 5x - 0.5
Subtracting 4x from both sides, we get:
从两侧减去 4 倍,我们得到:
1 = x - 0.5
Adding 0.5 to both sides, we get:
将 0.5 加到两侧,我们得到:
1.5 = x
Now that we know the value of x, we can substitute it back into the expression for AC to find its length:
现在我们知道了 x 的值,我们可以将其代入表达式中,让 AC 找到它的长度:
AC = 4x + 1
AC = 4(1.5) + 1
AC = 6 + 1
Therefore, the length of AC is 7.
因此,AC 的长度为 7。
2.3 视频理解和实时聊天
除了静态图像之外,Qwen2-VL 还将其能力扩展到视频内容分析。它可以总结视频内容,回答与之相关的问题,并实时保持持续的对话流,提供实时聊天支持。此功能允许它充当个人助理,通过提供直接从视频内容中提取的见解和信息来帮助用户。
User:Please describe the video in detail.
请详细描述视频。
Qwen2-VL
The video begins with a man speaking to the camera, followed by a group of people sitting in a control room. The camera then cuts to two men floating inside a space station, where they are seen speaking to the camera. The men appear to be astronauts, and they are wearing space suits. The space station is filled with various equipment and machinery, and the camera pans around to show the different areas of the station. The men continue to speak to the camera, and they appear to be discussing their mission and the various tasks they are performing. Overall, the video provides a fascinating glimpse into the world of space exploration and the daily lives of astronauts.
视频开始时,一名男子对着镜头讲话,然后是一群坐在控制室里的人。然后镜头切换到漂浮在空间站内的两名男子,可以看到他们对着镜头说话。这些人似乎是宇航员,他们穿着宇航服。空间站里装满了各种设备和机械,摄像机四处平移以显示空间站的不同区域。这些人继续对着镜头说话,他们似乎在讨论他们的任务和他们正在执行的各种任务。总体而言,该视频提供了对太空探索世界和宇航员日常生活的迷人一瞥。
User 用户
What is the color of the clothes the two astronauts wearing?
两位宇航员穿的衣服是什么颜色的?
Qwen2-VL
The two astronauts are wearing blue and black clothes.
这两名宇航员穿着蓝色和黑色的衣服。
2.4 可视化代理功能:函数调用和可视化交互
Qwen2-VL 作为视觉代理表现出强大的潜力,可促进类似于人类对世界感知的交互。
该模型可以函数调用,使其能够利用外部工具通过破译视觉线索来实时检索数据,无论是航班状态、天气预报还是包裹跟踪。这种视觉解释与功能执行的集成提升了它的实用性,使其成为信息管理和决策的强大工具。
示例:函数调用
Ask about the weather 询问天气
-
Visual Interactions represent a significant stride towards mimicking human perception. By allowing the model to engage with visual stimuli akin to human senses, we’re pushing the boundaries of AI’s ability to perceive and respond to its environment. This capability paves the way for more intuitive and immersive interactions, where Qwen2-VL acts not just as an observer, but an active participant in our visual experiences.
视觉交互代表了向模仿人类感知迈出的重大一步。通过允许模型与类似于人类感官的视觉刺激互动,我们正在突破 AI 感知和响应环境的能力的界限。此功能为更直观和身临其境的交互铺平了道路,Qwen2-VL 不仅充当观察者,而且是我们视觉体验的积极参与者。
三、模型架构
总体而言,继续使用 Qwen-VL 架构,该架构利用了 Vision Transformer (ViT) 模型和 Qwen2 语言模型。对于所有这些变体,使用了具有大约 600M 参数的 ViT,旨在无缝处理图像和视频输入。为了进一步增强模型有效感知和理解视频中视觉信息的能力,引入了几项关键升级:
- Qwen2-VL 中的一项关键架构改进是实现了 Naive Dynamic Resolution 支持。与前代产品不同,Qwen2-VL 可以处理任意图像分辨率,将它们映射到动态数量的视觉标记,从而确保模型输入与图像中固有信息之间的一致性。这种方法更接近于人类视觉感知,使模型能够处理任何清晰度或大小的图像。
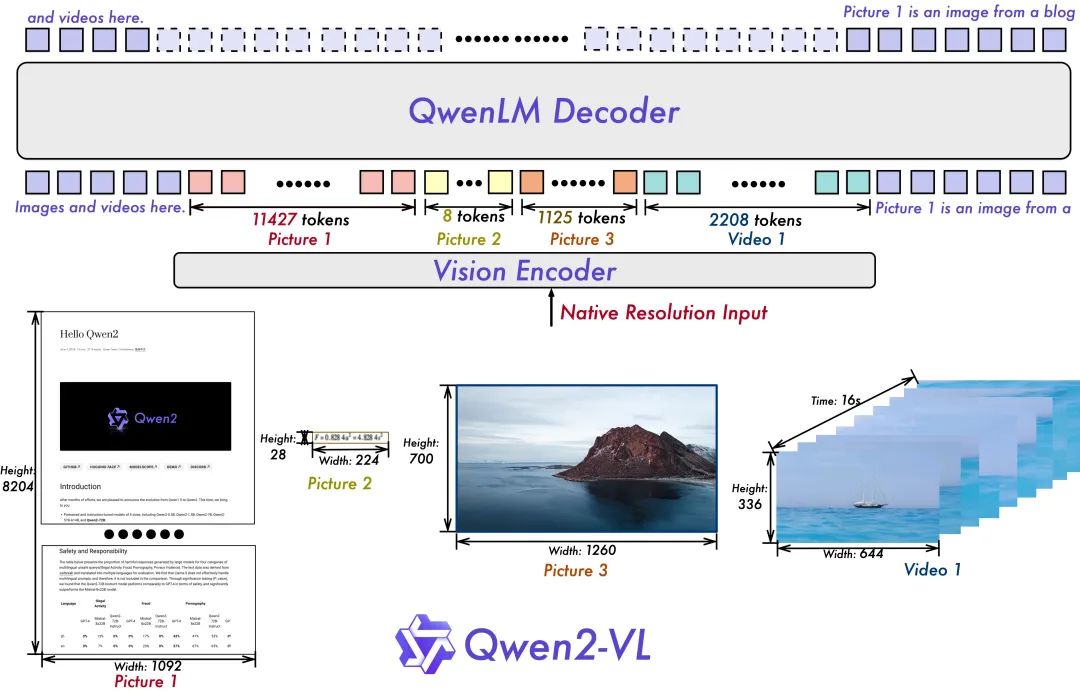
- 另一个关键的架构增强功能是多模态旋转位置嵌入 (M-ROPE) 的创新。通过将原始旋转嵌入物解构为代表时间和空间(高度和宽度)信息的三个部分,M-ROPE 使 LLM 能够同时捕获和整合 1D 文本、2D 视觉和 3D 视频位置信息。

四、使用 Qwen2-VL 进行开发
要使用最大的 Qwen2-VL 模型 Qwen2-VL-72B,您可以通过我们的官方 API(注册账号并通过 DashScope 获取 API 密钥)临时访问它,如下所示:
from openai import OpenAIimport osimport base64def encode_image(image_path):with open(image_path, "rb") as image_file:return base64.b64encode(image_file.read()).decode("utf-8")# Path to your imageimage_path = "dog_and_girl.jpeg"# Getting the base64 stringbase64_image = encode_image(image_path)def get_response():client = OpenAI(api_key=os.getenv("DASHSCOPE_API_KEY"),base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",)completion = client.chat.completions.create(model="qwen-vl-max-0809",messages=[{"role": "user","content": [{"type": "text", "text": "What is this?"},{"type": "image_url","image_url": {"url": "https://dashscope.oss-cn-beijing.aliyuncs.com/images/dog_and_girl.jpeg"},},{"type": "image_url","image_url": {"url": f"data:image/jpeg;base64,{base64_image}"},},],}],top_p=0.8,stream=True,stream_options={"include_usage": True},)for chunk in completion:print(chunk.model_dump_json())if __name__ == "__main__":get_response()
Qwen2-VL 系列的 2B 和 7B 型号是开源的,可在 Hugging Face 和 ModelScope 上访问。
确保你从源安装transformers, pip install git+https://github.com/huggingface/transformers 因为Qwen2-VL 的代码刚刚合并到 main 分支中。如果您未从源码安装它,则可能会遇到以下错误:
KeyError: 'qwen2_vl'阿里提供了一个工具包来帮助您更方便地处理各种类型的视觉输入。它支持的输入包括 base64、URL 以及交错图像和视频。您可以使用以下命令安装它:
pip install qwen-vl-utils下面是一个用于演示的代码片段。具体来说,我们建议尽可能使用 flash attention 2,以便加速和节省内存。
from transformers import Qwen2VLForConditionalGeneration, AutoTokenizer, AutoProcessorfrom qwen_vl_utils import process_vision_info# default: Load the model on the available device(s)model = Qwen2VLForConditionalGeneration.from_pretrained("Qwen/Qwen2-VL-7B-Instruct", device_map="auto")# We recommend enabling flash_attention_2 for better acceleration and memory saving, especially in multi-image and video scenarios.# model = Qwen2VLForConditionalGeneration.from_pretrained(# "Qwen/Qwen2-VL-7B-Instruct",# torch_dtype=torch.bfloat16,# attn_implementation="flash_attention_2",# device_map="auto",# )# default processerprocessor = AutoProcessor.from_pretrained("Qwen/Qwen2-VL-7B-Instruct")# The default range for the number of visual tokens per image in the model is 4-16384. You can set min_pixels and max_pixels according to your needs, such as a token count range of 256-1280, to balance speed and memory usage.# min_pixels = 256*28*28# max_pixels = 1280*28*28# processor = AutoProcessor.from_pretrained("Qwen/Qwen2-VL-7B-Instruct", min_pixels=min_pixels, max_pixels=max_pixels)messages = [{"role": "user","content": [{"type": "image","image": "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen-VL/assets/demo.jpeg",},{"type": "text", "text": "Describe this image."},],}]# Preparation for inferencetext = processor.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)image_inputs, video_inputs = process_vision_info(messages)inputs = processor(text=[text],images=image_inputs,videos=video_inputs,padding=True,return_tensors="pt",)# Inference: Generation of the outputgenerated_ids = model.generate(**inputs, max_new_tokens=128)generated_ids_trimmed = [out_ids[len(in_ids) :] for in_ids, out_ids in zip(inputs.input_ids, generated_ids)]output_text = processor.batch_decode(generated_ids_trimmed, skip_special_tokens=True, clean_up_tokenization_spaces=False)print(output_text)
Qwen2-VL已经支持开源生态系统中的一系列工具和框架,包括量化 (AutoGPTQ、AutoAWQ)、部署 (vLLM)、微调 (Llama-Factory) 等
这篇关于MLLM(二)| 阿里开源视频理解大模型:Qwen2-VL的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








