vl专题

MLLM(二)| 阿里开源视频理解大模型:Qwen2-VL
2024年8月29日,阿里发布了 Qwen2-VL!Qwen2-VL 是基于 Qwen2 的最新视觉语言大模型。与 Qwen-VL 相比,Qwen2-VL 具有以下能力: SoTA对各种分辨率和比例的图像的理解:Qwen2-VL在视觉理解基准上达到了最先进的性能,包括MathVista、DocVQA、RealWorldQA、MTVQA等。理解 20 分钟+ 的视频:Qwe

阿里云Qwen2-VL语言模型:特点与实用性解析
最近,阿里云推出了最新的视觉语言模型——Qwen2-VL。作为一款先进的视觉语言模型,Qwen2-VL的发布无疑为AI领域注入了新的活力。那么,这款模型有哪些特别之处?它的实用性又如何呢?今天我们就来详细解析一下Qwen2-VL的特点与实际应用。 一、Qwen2-VL的核心特点 1. 多分辨率与比例图像的理解能力 Qwen2-VL最大的亮点之一,就是它对多分辨率和比例图像的理解能力。

240831-Qwen2-VL-7B/2B部署测试
A. 运行效果 B. 配置部署 如果可以执行下面就执行下面: pip install git+https://github.com/huggingface/transformers accelerate 否则分开执行 git clone https://github.com/huggingface/transformerscd transformerspip install .

通义千问-VL-Chat-Int4
Qwen-VL 是阿里云研发的大规模视觉语言模型(Large Vision Language Model, LVLM)。Qwen-VL 可以以图像、文本、检测框作为输入,并以文本和检测框作为输出。Qwen-VL 系列模型性能强大,具备多语言对话、多图交错对话等能力,并支持中文开放域定位和细粒度图像识别与理解。 安装要求 (Requirements) python 3.8及以上版本pytor
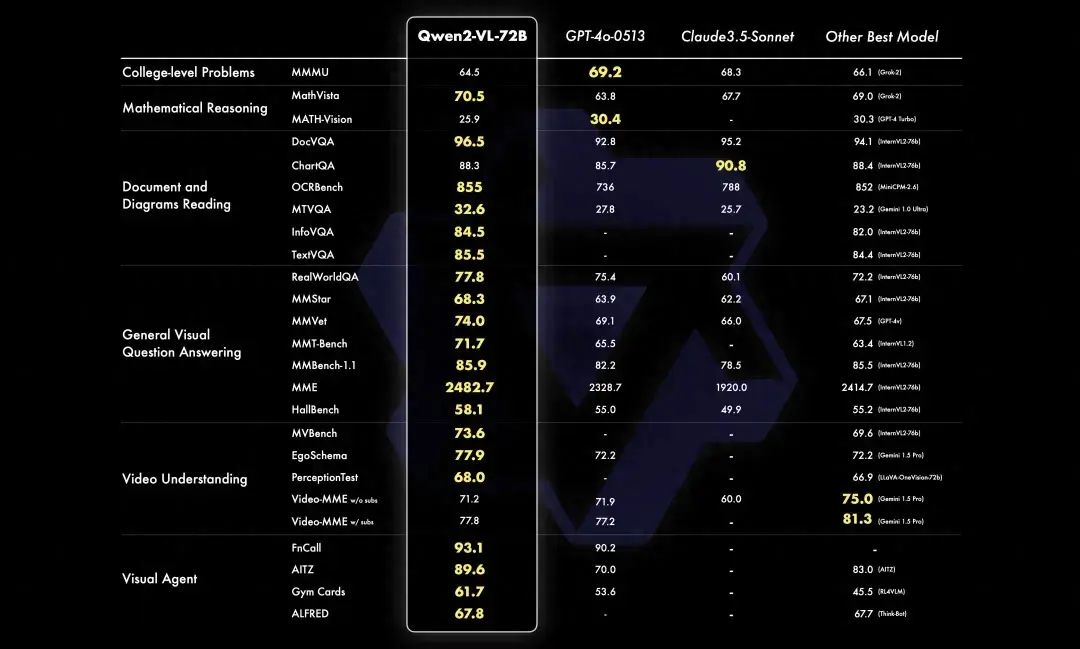
AI大模型日报#0830:智谱AI推出多款升级模型、阿里开源多模态Qwen2-VL
导读:AI大模型日报,爬虫+LLM自动生成,一文览尽每日AI大模型要点资讯!目前采用“文心一言”(ERNIE-4.0-8K-latest)、“智谱AI”(glm-4-0520)生成了今日要点以及每条资讯的摘要。欢迎阅读!《AI大模型日报》今日要点:智谱AI在KDD 2024上展示了其全新大模型GLM-4-Plus,该模型在多任务上逼近甚至超越GPT-4o,并推出了支持中英双语的对话机器人等功能,巩

Qwen-VL模型微调及遇到的一些小问题
Qwen-VL 是阿里云研发的大规模视觉语言模型(Large Vision Language Model, LVLM)。Qwen-VL 可以以图像、文本、检测框作为输入,并以文本和检测框作为输出。相比较前文提到的llava-llama3的模型,它相对更成熟一些,功能更强大一些。 比较有特点的功能: 多图交错对话:支持多图输入和比较,指定图片问答,多图文学创作等;
Qwen-VL部署实操
Qwen-VL 是阿里云研发的大规模视觉语言模型(Large Vision Language Model, LVLM)。Qwen-VL 可以以图像、文本、检测框作为输入,并以文本和检测框作为输出。Qwen-VL 系列模型的特点包括: 强大的性能:在四大类多模态任务的标准英文测评中(Zero-shot Captioning/VQA/DocVQA/Grounding)上,均取得同等通用模型大小下最好

【多模态大模型教程】在自定义数据上使用Qwen-VL多模态大模型的微调与部署指南
Qwen-VL 是阿里云研发的大规模视觉语言模型(Large Vision Language Model, LVLM)。Qwen-VL 可以以图像、文本、检测框作为输入,并以文本和检测框作为输出。 Qwen-VL-Chat = 大语言模型(Qwen-7B) + 视觉图片特征编码器(Openclip ViT-bigG) + 位置感知视觉语言适配器(可训练Adapter)+ 1.5B的图文数据

Qwen-VL图文多模态大模型LoRA微调指南
大模型相关目录 大模型,包括部署微调prompt/Agent应用开发、知识库增强、数据库增强、知识图谱增强、自然语言处理、多模态等大模型应用开发内容 从0起步,扬帆起航。 大模型应用向开发路径:AI代理工作流大模型应用开发实用开源项目汇总大模型问答项目问答性能评估方法大模型数据侧总结大模型token等基本概念及参数和内存的关系大模型应用开发-华为大模型生态规划从零开始的LLaMA-Factor

Qwen-VL论文阅读
论文地址 其他同学的详细讲解 模型结构和参数大小 (1)LLM:Qwen-7B (2)Vision Encoder:ViT架构,初始化参数是 Openclip’s ViT-bigG。 在训练和推理过程中,输入的图像都被调整到特定的分辨率。 视觉编码器通过将图像分割成步长为14 的块来处理图像,从而生成一组图像特征。 「 224 / 14 = 16 16 x 16 = 256」 (3
【多模态】31、Qwen-VL | 一个开源的全能的视觉-语言多模态大模型
文章目录 一、背景二、方法2.1 模型架构2.2 输入和输出2.3 训练 三、效果3.1 Image Caption 和 General Visual Question Answering3.2 Text-oriented Visual Question Answering3.3 Refer Expression Comprehension3.4 视觉-语言任务的少样本学习3.5 真实世

Qwen-VL环境搭建推理测试
引子 这几天阿里的Qwen2.5大模型在大模型圈引起了轰动,号称地表最强中文大模型。前面几篇也写了QWen的微调等,视觉语言模型也写了一篇CogVLM,感兴趣的小伙伴可以移步Qwen1.5微调-CSDN博客。前面也写过一篇智谱AI的视觉大模型(CogVLM/CogAgent环境搭建&推理测试-CSDN博客)。Qwen-VL 是阿里云研发的大规模视觉语言模型(Large Vision Langua

你一定不能错过的多模态大模型!阿里千问开源Qwen-VL!具备图文解读等能力
1. Qwen-VL简介 1.1. 介绍 Qwen-VL的多语言视觉语言模型系列,基于Qwen-7B语言模型。该模型通过视觉编码器和位置感知的视觉语言适配器,赋予语言模型视觉理解能力。 Qwen-VL采用了三阶段的训练流程,并在多个视觉语言理解基准测试中取得了领先的成绩。该模型支持多语言、多图像输入,具备细粒度的视觉理解能力。 另外,通过指令调优,生成了交互式的Qwen-VL-

【中文视觉语言模型+本地部署 】23.08 阿里Qwen-VL:能对图片理解、定位物体、读取文字的视觉语言模型 (推理最低12G显存+)
项目主页:https://github.com/QwenLM/Qwen-VL 通义前问网页在线使用——(文本问答,图片理解,文档解析):https://tongyi.aliyun.com/qianwen/ 论文v3. : 一个全能的视觉语言模型 23.10 Qwen-VL: A Versatile Vision-Language Model for Understanding, Localizat
DeepSeek发布多模态大型语言模型DeepSeek-VL,技术创新性突出
近日,DeepSeek团队发布了一项创新性突出的多模态大型语言模型DeepSeek-VL。该模型参数规模为1.3B和6.7B,采用了创新的联合视觉和语言预训练方法,旨在解决传统的单模态预训练方法的局限性。 DeepSeek-VL在数据准备、模型架构和训练方法等多方面都有创新工作。在数据准备方面,采用了策略性数据采样方法,平衡了多模态数据和纯文本数据的比例,避免影响语言模型原有的语言理解能力。在模型

3月12日 工作记录 DeepSeek-VL阅读笔记
昨天考完试,晚上把那个讨人厌的项目做了阶段结果给合作者展示去了,然后就看到deepseek发布了vision language的技术报告,于是打算今天上午看看。 DeepSeek VL 很多内容直接翻译自其 DeepSeek-VL,下面的我们指的的是deepseek vl的作者。 数据构建 预训练数据 我们努力确保我们的数据是多样化的,可扩展的,并广泛覆盖现实世界的场景,包括web

未定义与 'single' 类型的输入参数相对应的函数 'vl_pr'
这个问题是在实验AlfredXiangWu的人脸验证实验时遇到的问题,后来在百度上搜索,居然发现有人和我遇到了相同的问题,而且直接在github上询问了AlfredXiangWu,幸运的是大神给出了答案,原来是我们缺少一个VLFeat的库(参考网址:https://github.com/AlfredXiangWu/face_verification_experiment/issues/
VLM 系列——Qwen-VL 千问—— 论文解读
一、概述 1、是什么 Qwen-VL全称《Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond》,是一个多模态的视觉-文本模型,当前 Qwen-VL(20231707)可以完成:图像字幕、视觉问答、OCR、文档理解和视觉定位功能,同时支持

零一万物开源Yi-VL多模态大模型,推理微调最佳实践来啦!
近期,零一万物Yi系列模型家族发布了其多模态大模型系列,**Yi Vision Language(Yi-VL)**多模态语言大模型正式面向全球开源。凭借卓越的图文理解和对话生成能力,Yi-VL模型在英文数据集MMMU和中文数据集CMMMU上取得了领先成绩,展示了在复杂跨学科任务上的强大实力。 基于Yi语言模型的强大文本理解能力,只需对图片进行对齐,就可以得到不错的多模态视觉语言模型——这也是Yi

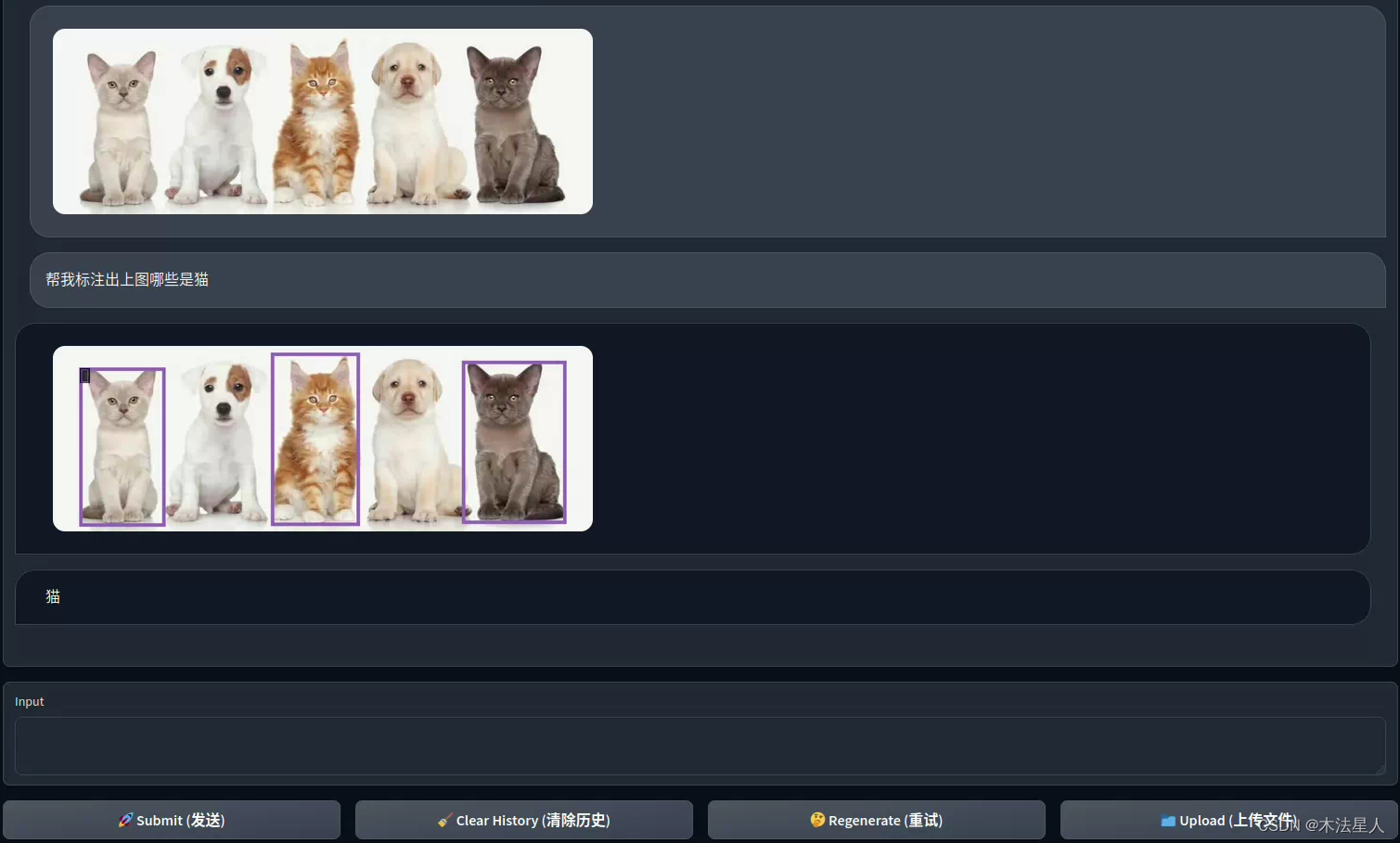
阿里的通义千问也能本地部署了?首发Qwen-VL-Chat模型的本地部署教程(A卡)
阿里云最新开源的通义千问视觉语言模型:Qwen-VL Qwen-VL 是一款支持中英文等多种语言的视觉语言(Vision Language,VL)模型,相较于此前的 VL 模型,其除了具备基本的图文识别、描述、问答及对话能力之外,还新增了视觉定位、图像中文字理解等能力。Qwen-VL 以 Qwen-7B 为基座语言模型,在模型架构上引入视觉编码器,使得模型支持视觉信号输入,该模型支持的图像

DICOM 文件中,VR,VL,Sequence,图像二进制的几个注意点
DICOM 文件中,VR,VL,Sequence,图像二进制的几个注意点 1. 传输语法 DICOM 文件的结构,在网上有很多的学习资料,这里只介绍些容易混淆的概念,作为回看笔记。 每个传输语法,起都是表达的三个概念:大小端、显隐式、压缩算法 DICOM Implicit VR Little Endian: 1.2.840.10008.1.2 DICOM Explicit VR Littl
3090微调多模态模型Qwen-VL踩坑
本人使用记录一下训练过程中的心得和bug 1.数据集准备 数据集的标签形式见官方readme,如下: [{"id": "identity_0","conversations": [{"from": "user","value": "你好"},{"from": "assistant","value": "我是Qwen-VL,一个支持视觉输入的大模型。"}]},{"id": "identity_

Qwen-VL:多功能视觉语言模型,能理解、能定位、能阅读等
Overview 总览摘要1 引言2 方法2.1 模型结构2.2 输入输出 3 训练3.1 预训练3.2 多任务预训练3.3 监督finetune 4 评测4.1 图像文本描述和视觉问答4.2 面向文本的视觉问答4.3 指代表达理解4.4 视觉语言任务中的小样本学习4.4 现实用户行为下的指令遵循 5 相关工作6 总结与展望附录A 数据集细节A.2 视觉问答A.3 定位A.4 文本识别B 多
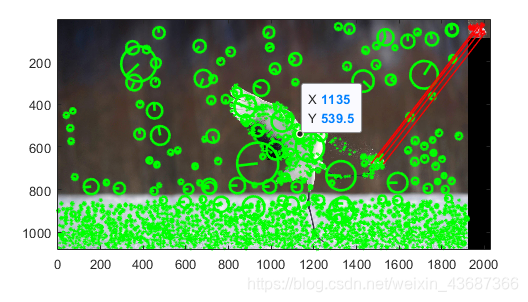
如何使用VL_feat入门SIFT
首先下载vl_feat包http://www.vlfeat.org/download.html 正常解压就完事了 然后在程序开头输入加载vl_feat run('.\vlfeat-0.9.21-bin\vlfeat-0.9.21\toolbox\vl_setup.m');% 测试vlfeat是否成功vl_version verbose 然后开始代码测试两张图像使用sift匹配显示