本文主要是介绍勇夺三项SOTA!北航爱诗科技联合发布灵活高效可控视频生成方法TrackGo!,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!


论文链接:https://arxiv.org/pdf/2408.11475
项目链接:https://zhtjtcz.github.io/TrackGo-Page/
★亮点直击
本文引入了一种新颖的运动可控视频生成方法,称为TrackGo。该方法为用户提供了一种灵活的运动控制机制,通过结合 masks 和箭头,实现了在复杂场景中的精确操控,包括涉及多个对象、细粒度对象部件和复杂运动轨迹的场景。
本文开发了一个新组件,称为TrackAdapter,用于有效且高效地将运动控制信息集成到时间自注意力层中。
本文进行了广泛的实验来验证本文的方法。实验结果表明,本文的模型在视频质量(FVD)、图像质量(FID)和运动真实性(ObjMC)方面优于现有模型。
近年来,基于扩散的可控视频生成领域取得了显著进展。然而,在复杂场景中实现精确控制仍然是一个挑战,包括对细粒度的物体部分、复杂的运动轨迹以及连贯的背景运动的控制。在本文中,本文介绍了TrackGo,这是一种利用自由形式的masks和箭头进行条件视频生成的新方法。该方法为用户提供了一种灵活且精确的机制来操控视频内容。本文还提出了用于控制实现的TrackAdapter,这是一种高效轻量的适配器,旨在无缝集成到预训练视频生成模型的时间自注意力层中。该设计利用了本文的观察,即这些层的注意力图可以准确激活与视频中运动对应的区域。本文的实验结果表明,借助TrackAdapter增强的新方法在关键指标如FVD、FID和ObjMC得分上实现了最先进的性能。
方法
概览
本文的任务是运动可控的视频生成。对于输入图像 和从箭头中提取的点轨迹 ,描述了轨迹信息,生成与轨迹一致的视频 ,其中 表示视频的长度。
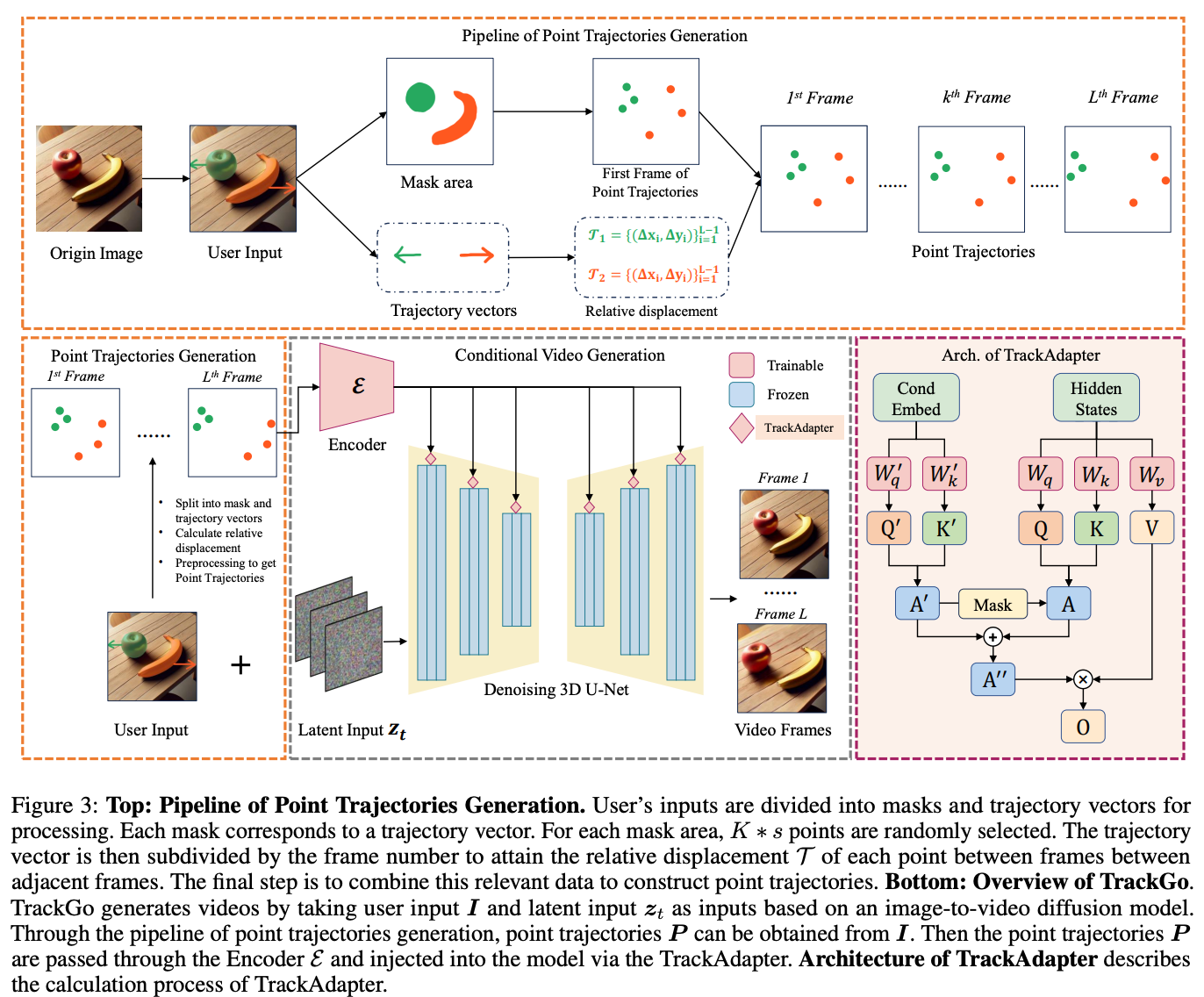
我们使用SVD模型(Stable Video Diffusion Model, SVD)作为本文的基础架构。SVD模型类似于大多数视频潜在扩散模型,在图像扩散的U-Net上添加了一系列时间层以形成3D U-Net。在此基础上,本文通过一个可训练的编码器 将点轨迹 转化为压缩表示 。然后将该表示注入到每个时间自注意力模块中,使用下采样来处理并适应到合适的分辨率。本文引入了TrackAdapter,并在SVD的每个时间自注意力中添加一个TrackAdapter来注入 ,如下图3所示。
在接下来的部分中,本文将讨论三个主要主题:
-
点轨迹的优势以及本文如何获取和使用它们。
-
TrackAdapter的结构以及它如何帮助SVD理解复杂的运动模式并完成复杂动作的生成。
-
我们模型的训练和推理过程。
点轨迹生成
在推理过程中,当用户提供第一帧图像、编辑区域的masks以及相应的箭头时,本文的方法可以通过预处理将用户输入的masks和箭头转换为点轨迹,如上图3所示。
在训练过程中,本文首先使用DEVA对真实视频中的主要组件进行分割,并获得相应的分割序列,其中表示第帧,表示第个组件。然后,对于第一帧的masks序列,本文需要在每个masks区域选择个点作为控制点,其中表示组件的数量。对于masks,本文在白色区域随机选择个点,然后使用K-means得到个点。这保证了选择的个点的均匀性,同时不会带来过多的时间开销。经过这个阶段,本文将总共获得个控制点。在获得控制点后,本文使用Co-Tracker追踪这些点,并获得相应的运动轨迹,其中是视频的长度。最后,本文为对应于同一组件的控制点分配颜色,绘制轨迹并得到点轨迹。本文使用这种方法构建了训练数据集,并经过数据清理和其他操作,最终获得了110k 个三元组。
通过 TrackAdapter 注入运动条件
运动条件提取。 本文使用与Animate Anyone相同的编码器结构来提取时间特征。这个过程可以通过公式1获得,其中是的压缩时间表示。
![]()
f 将根据不同时间自注意力层的分辨率进行下采样,并与其输入尺寸对齐。
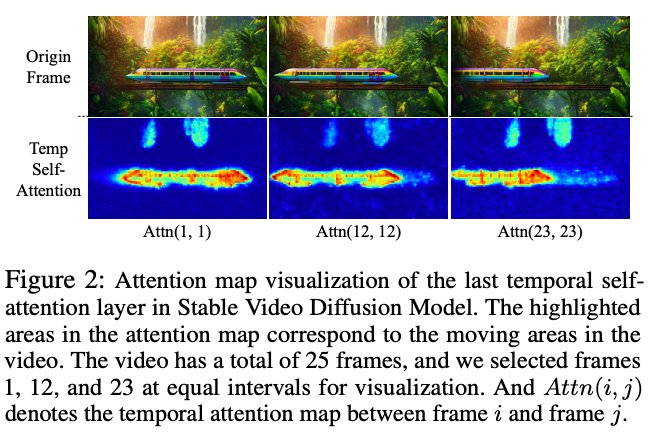
TrackAdapter设计。 为了利用压缩的时间表示指导模型生成对应于该动作的视频,一个直接的方法是使用构建如下图2所示的注意力图。因此,本文提出了一种轻量且简单的结构,称为TrackAdapter。TrackAdapter的功能是激活与指定对象对应的运动区域,从而引导模型的生成过程。在注入点轨迹时,TrackAdapter负责激活指定对象的运动区域。本文首先为TrackAdapter计算注意力图:
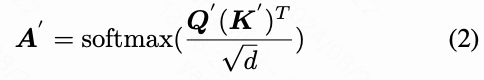
其中, 和 是 TrackAdapter 的查询和键矩阵,其中 是从方程 1 中获得的 的压缩表示。
为了避免原始时间自注意力分支对最终活跃区域的影响,本文根据注意力图获得一个注意力 mask ,以抑制由原始时间自注意力分支激活的区域。
本文通过设置一个阈值 将注意力图 转换为相应的注意力 mask :
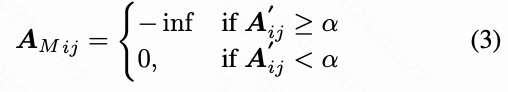
TrackAdapter 所关注的运动区域是注意力图 中超过阈值 的部分。通过将注意力 mask 中对应的区域设置为 ,原始时间自注意力将不再关注这一部分,从而产生分离效果。然后,原始时间自注意力的注意力图可以重写为:
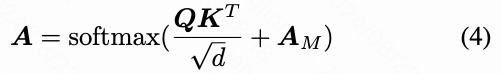
最终,本文得到当前块的时间自注意力输出:,其中 ,, 分别是时间自注意力操作中的查询、键和值矩阵, 是输入特征, 是最终的注意力图。在注意力计算过程中,本文完成了对应区域和未指定区域的分离。
TrackAdapter的训练和推理
训练视频扩散模型时,该模型通过迭代预测噪声 在噪声输入中,逐步将高斯噪声转化为有意义的视频帧。模型 的优化是通过噪声预测损失实现的。
![]()
其中, 表示时间步, 表示 U-Net 的参数, 表示条件, 是经过噪声变换后的真实视频 的版本。
![]()
这里, 和 表示预定义的常数序列。在方程 (5) 的基础上,本文添加点轨迹 和图像 作为条件,优化目标可以写为:
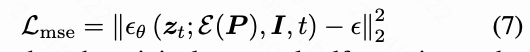
为了使原始的时间自注意力机制快速适应新的输入模式,并加速模型的收敛,本文设计了一种基于注意力图的损失函数。本文从不同的块中收集注意力图,得到一个集合,其中包含16个不同的注意力图。对于,表示在块中帧和帧之间的时间自注意力图。注意力损失的目的是抑制原始分支的注意力图中对应于 mask 的区域,即运动区域。
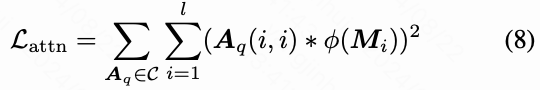
其中,表示下采样操作,表示第帧中所有运动组件的 mask 。总的来说,本文的最终损失函数由这两个项的加权平均定义。
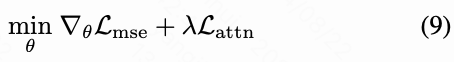
其中,是一个超参数。
推理。 在推理过程中,本文将未指定区域的强度设置为,即将方程3中小于的部分设置为。用户可以通过调整来控制未指定区域的运动,以便在需要与前景运动同步移动或需要减轻未指定区域的感官干扰时进行调整。此功能将极大地提升流畅且高度同步的运动视频的创作。
Experiment Settings
实现细节。 本文采用SVD作为基础模型。所有实验均使用PyTorch在8个NVIDIA A100-80G GPU上进行。AdamW被配置为本文的优化器,总共运行18,000个训练步骤,学习率为,批量大小为8。根据Animate Anyone中提出的方法,本文开发了一个轻量级编码器。该编码器使用总共六个卷积层、两个池化层和一个最终的全连接层。其主要功能是将点轨迹对齐到适当的分辨率。TrackAdapter的查询和键矩阵从原始的时间注意力分支初始化。
数据集。 对于本文的实验,本文使用了一个内部数据集,该数据集具有优质的视频质量,包括大约20万段视频。根据实验设计,本文进一步筛选数据,得到约11万段视频作为本文的最终训练数据集。在训练过程中,每个视频被调整为1024 × 576的分辨率,并标准化为每段25帧。
本文的测试集包括VIPSeg验证集以及内部验证数据集中额外的300段视频。值得注意的是,VIPSeg数据集中的所有视频均为16:9的宽高比。为了保持一致性,本文将验证集中的所有视频的分辨率调整为1024 × 576,而不是DragAnything中使用的256 × 256。为了评估,本文从测试集中每个视频的前14帧中提取轨迹。
评估指标和基线方法。 本文使用FVD(Frechet Video Distance)来测量视频质量,并使用FID来测量图像质量。本文将本文的方法与DragNUWA和DragAnything进行比较,这些方法也可以使用轨迹信息作为条件输入。根据DragAnything,ObjMC用于通过计算预测轨迹和真实轨迹之间的欧几里得距离来评估运动控制性能。
定量评价
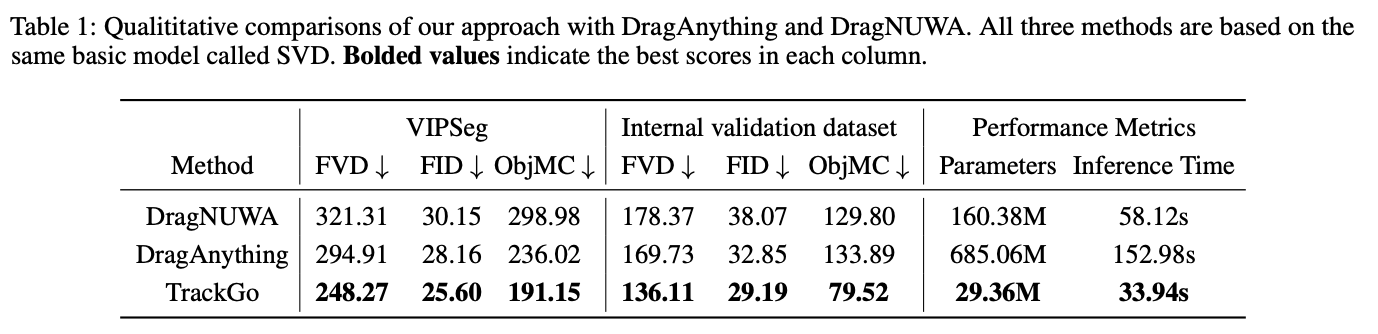
本文的方法与基线方法的定量比较如下表1所示。本文在VIPSeg验证集和内部验证集上测试了所有模型。从结果可以看出,TrackGo在所有指标上都优于其他方法,这表明本文的方法可以生成具有更高视觉质量的视频,并且更加忠实于输入的运动控制。本文还比较了三种方法的模型参数和推理速度。由于这三种方法都使用相同的基础模型,本文的比较专注于新增模块的总权重。为了评估模型的推理速度,本文在NVIDIA A100 GPU上使用相同的输入数据对每种方法进行了100次推理测试。结果表明,本文的方法不仅提供了最佳的视觉质量,还实现了最快的推理速度,同时需要的额外参数最少。
定性评价
可视化。 本文在下图4中展示了与DragAnything和DragNUWA的可视化比较。本文可以做出以下观察:首先,DragNUWA在感知控制区域时存在困难,这可能导致光流不完整或不准确。在案例(b)中,行星未被正确感知,而在案例(a)中,枪的移动也是不正确的。在案例(c)中,虽然成功预测了火车的光流,但烟雾的光流缺失导致了刺眼的视觉效果。其次,DragAnything在处理部分或细粒度物体的移动时也面临困难。如案例(a)所示,只有枪和马里奥的手应该移动,但马里奥的整个位置也意外地移动了。类似的问题也出现在案例(b)中。此外,DragAnything难以生成和谐的背景。在案例(c)中,烟雾没有跟随移动的火车。相比之下,本文提出的TrackGo可以生成视频,使目标区域的移动与用户输入精确对齐,同时保持背景的一致性和和谐性。这一能力显著提高了生成视频的视觉质量和连贯性,展示了TrackGo的有效性。更多本文方法的案例可以在上图1中找到。

背景运动的注意力 mask 控制。 本文的模型具备通过特定参数调整未指定区域运动强度的能力,如下图5所示。本文用参数定义未指定区域的运动抑制强度。如图5所示,当手部移动时,方向盘也需要相应移动以增强输出的真实感。当时,未指定区域的运动被显著抑制,仅允许手部沿其轨迹移动,而其他部分保持静止。这通常会导致视频整体失真。当时,未指定区域的抑制较少,允许手部和方向盘同时移动。然而,这种设置仍可能产生不和谐的结果,例如方向盘上的汽车标志保持静止。当时,未指定区域可以自由移动,这通常会导致视频更加连贯和和谐。然而,并非所有未指定区域的运动都是理想的,过度的运动可能损害视频质量。因此,仔细管理抑制水平以平衡真实感和艺术控制是至关重要的。

相机运动。 类似于 DragAnything,TrackGo 也能够实现相机运动效果,如下图 6 所示。只需选择整个图像区域作为运动区域,并提供一个运动轨迹,就可以实现相机沿着该轨迹指定方向移动的效果。

消融研究
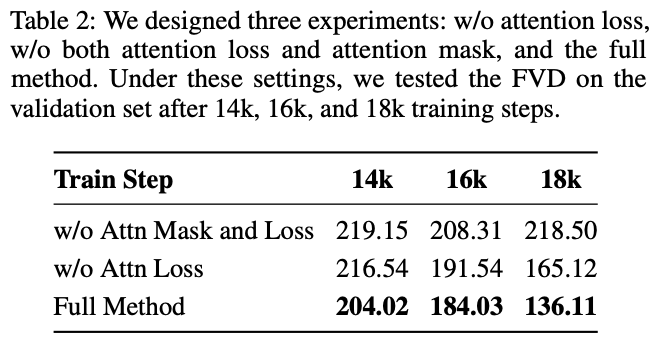
为了验证注意力 mask 和注意力损失的有效性,本文在不同的训练步数下报告了内部验证集上的 FVD 指标,如下表 2 所示。在相同的训练步数下,未使用注意力损失的模型显示出略高的 FVD,与使用注意力损失的模型相比。当不使用注意力损失时,FVD 高于应用注意力损失时的水平。这种差异在 18K 训练步时尤为明显。这表明使用注意力损失可以加速模型训练并有助于收敛。在没有使用注意力 mask 和注意力损失的情况下,FVD 在大约 16K 步时趋于稳定,但仍然显著高于完整设置下的 FVD。
用户研究
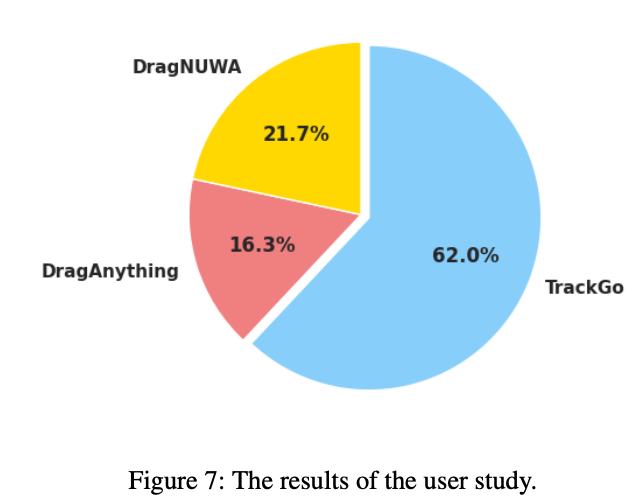
本文进行了一项用户研究来评估合成视频的质量。本文随机抽取了60个案例,并对三种不同的方法进行用户研究。每份问卷包含从这60个案例中随机抽取的30个案例。本文要求用户根据整体质量从两个方面选择最佳视频:生成视频与给定条件之间的一致性,以及生成视频的质量(例如,主体是否失真,未选择的背景是否抖动等)。 本文邀请了30人填写问卷,性别比例约为3:1(男性:女性)。大多数参与者是来自不同科学与工程领域的大学生,年龄在18到27岁之间。结果显示,本文的方法获得了62%的投票,高于DragAnything的16.33%和DragNUWA的21.67%,如下图7所示。
结论
在本文中,本文引入了点轨迹来捕捉视频中的复杂时间信息。本文提出了TrackAdapter来处理这些点轨迹,重点关注指定目标的运动,并使用注意力 mask 来减轻原始时间自注意力对指定区域的影响。在推理过程中,注意力 mask 可以调节未指定区域的运动,从而使视频输出更符合用户输入。大量实验表明,本文的TrackGo在FVD、FID和ObjMC评分上达到了最新的水平。此外,定性分析显示,本文的方法在各种复杂场景中提供了精确的控制。
参考文献
[1]TrackGo: A Flexible and Efficient Method for Controllable Video Generation [1] TrackGo: A Flexible and Efficient Method for Controllable Video Generation
更多精彩内容,请关注公众号:AI生成未来

这篇关于勇夺三项SOTA!北航爱诗科技联合发布灵活高效可控视频生成方法TrackGo!的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





