本文主要是介绍车道线检测综述——【极市】方浩:车道线检测新SOTA,RESA个人笔记,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
视频链接:https://www.bilibili.com/video/BV1664y1o7wg
一、背景
车道线检测:从输入的图片中检测出车道线,图片是由车辆的前置摄像头拍摄。


1.1 车道线检测在自动驾驶中如何使用

自动驾驶从算法的角度主要分为三个部分:环境感知、决策、执行。环境感知即通过各种传感器采集数据,用算法进行分析,再输入Planning模块,Planning模块根据自己要开往哪里并分析周围环境来规划下一步动作,动作输入到Control模块,Control模块再与硬件作交互,实现具体执行。
车道线检测的执行是在感知模块,在Planning模块被使用。
在Planning模块中使用车道线检测:
- 轨迹规划
- 行为预测
- 车道保持
- …
1.2 问题定义
输入:[3×H×W]的图片
输出:N×车道线(实例、点、参数等)
1.3 主要难点
- 遮挡非常严重,路面上的人和车非常多,有的车道线磨损严重,有的车道线是一段一段的。
- 车道线又细又长,监督信号非常稀疏,正样本非常少
- 一般要求实时性
二、相关工作
2.1 传统方法
2.1.1 Hough变换
论文: Yu and A. K. Jain, “Lane boundary detection using a multiresolution Hough transform,” Proceedings of International Conference on Image Processing, Santa Barbara, CA, USA, 1997, pp. 748-751 vol.2, doi: 10.1109/ICIP.1997.638604
首先,将RGB彩色图变为灰度图
再做高斯模糊
再做边缘检测,得到mask点
最后再做Hough变换,找到整张图的所有直线,得到一堆参数,并不知道直线的起点与终点

传统算法的局限性:
- 若出现遮挡,直线拟合效果差
- 曲线车道线效果不好
2.2 深度学习方法
2.2.1 检测类方法
2.2.1.1 LanNet
论文:Towards End-to-End Lane Detection: an Instance Segmentation Approach

实例分割
像素嵌入+聚类
缺点:依赖于聚类,结果不稳定;起始位置不确定;效果并没有特别好。
2.2.1.2 SCNN
论文:Spatial As Deep: Spatial CNN for Traffic Scene Understanding

RNN——让信息在水平和竖直方向传递
语义分割+后处理
缺点:用类似RNN做信息传递,速度慢
2.2.1.3 light-weight
- self-attention distillation(SAD)
论文:Learning Lightweight Lane Detection CNNs by Self Attention Distillation

- CurveLane-NAS(5000GPU hours)
论文:
2.2.2 新的思路
2.2.2.1 Gridding
论文:CurveLane-NAS: Unifying Lane-Sensitive Architecture Search and Adaptive Point Blending

将一张图片的像素做水平分割与竖直分割,将很多像素变为一个cell,相当于把整张图做了降采样,对每个cell做分类(网格化)
行分类——判断这行是否有车道线
速度很快,但因为降采样精度会下降
2.2.2.2 PolyLaneNet:Lane Estimation via Deep Polynomial Regreesion
论文:PolyLaneNet: Lane Estimation via Deep Polynomial Regression

假设车道线为曲线,曲线是由很多参数决定的,使用多项式去学习这些参数。
缺点:若摄像头换角度拍就不work了
2.2.2.3 Anchor-based
论文:Keep your Eyes on the Lane: Real-time Attention-guided Lane Detection

强先验
处理变化的情况不太灵活
三、RESA方法
经典的语义分割不能应用于车道线检测的原因:
- 严重的遮挡和模糊的车道线
- 稀疏的监督信号(车道线又细又长,有的车道线是一段一段的)
idea: - 强形状先验(label连续)
- 空间依赖性,通过空间相关性大概推理车道线
将远处的特征传过来,近处的特征传过去,或者左边传到右边,右边传到左边,来做信息增强。
设计一个能够把空间的信息的聚合、把原始特征增强的模块。

图(a)显示了CNN的结果车道线不够完整也不够精细,但RESA可以得到精细且完整的线。
图(b)对信息进行切片,若从左往右传递,则把每列特征作为一个slice,特征在列与列之间传递,考虑线与线之间特征的相关性;若从上往下传递,则把每行作为一个slise,特征在行与行之间传递 ,考虑近处与远处的连续性。
网络架构:

图(a)输入一张图片,先经过一个Encoder(VGG、retinanet等)将图片降采样到1/8特征图,再经过RESA将信息增强,最后经过Decoder做上采样到原图大小,输出两个分支,分别是segmentation和判断车道线是否存在(0和1二分类)。
图(b)和(c)是分别从两个方向对特征进行切片,对每个切片使用一层一卷积(即使用一维卷积作用于切片),每个方向要进行K次迭代。
RESA:

上图为从右往左传递的示意图,首先把每一列进行切片,将特征变成一列一列的。
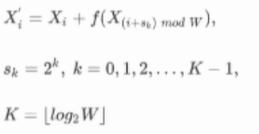

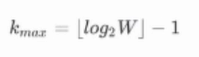
Decoder:

Decoder主要分为两部分,一部分主要依赖于双线性差值,可得到粗略的预测结果;另外一部分依赖于转置卷积,求精细特征。两部分的结果进行加和出结果。
Decoder的两个作用:
- 将通道数量除以2
- 上采样
四、RESA的结果和分析
CULane

TuSimple


对比实验


迭代次数

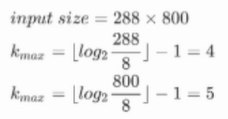
上下左右传递实验

分析:

RESA做了空间的特征传递,将稀疏的特征空间转换为丰富的特征空间,即设计一个模块去聚合空间信息和增强由原始的CNN提取的特征。
架构的关键因素:编码器+聚合+解码器。
Encoder可以用任何原始的CNN分类网络。
这篇关于车道线检测综述——【极市】方浩:车道线检测新SOTA,RESA个人笔记的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!