综述专题

kaggle竞赛宝典 | Mamba模型综述!
本文来源公众号“kaggle竞赛宝典”,仅用于学术分享,侵权删,干货满满。 原文链接:Mamba模型综述! 型语言模型(LLMs),成为深度学习的基石。尽管取得了令人瞩目的成就,Transformers仍面临固有的局限性,尤其是在推理时,由于注意力计算的平方复杂度,导致推理过程耗时较长。 最近,一种名为Mamba的新型架构应运而生,其灵感源自经典的状态空间模型,成为构建基础模型的有力替代方案
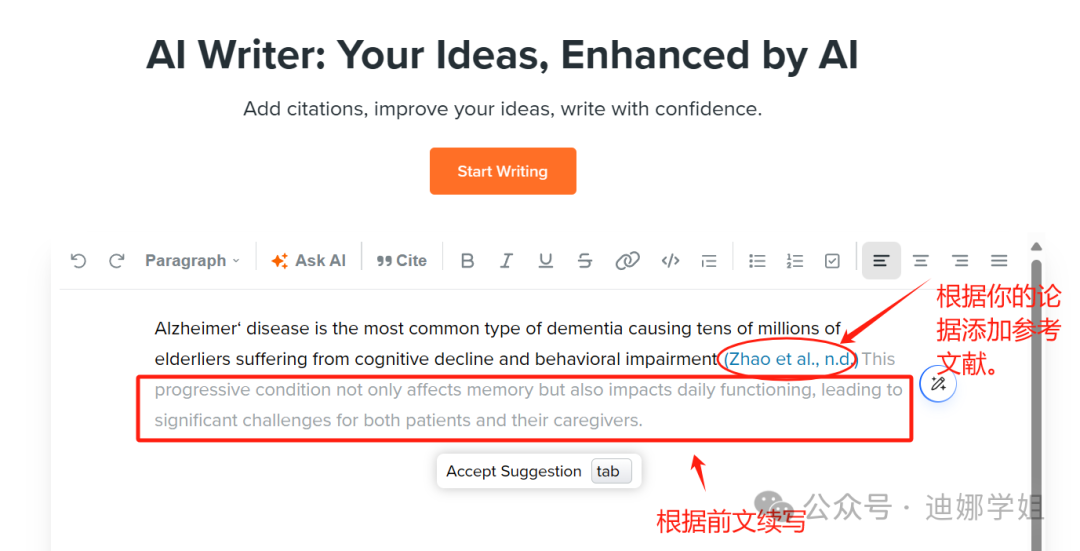
AI文献综述神器,有这一款就够了!
我是娜姐 @迪娜学姐 ,一个SCI医学期刊编辑,探索用AI工具提效论文写作和发表。 当前的AI辅助文献综述的工具有很多,如果说功能最强大的,娜姐无疑要推SciSpace了。 SciSpace利用强大的AI算法,理解并建立研究论文之间的联系,可以大大提升文献综述的质量和效率。并且其功能还在不断更新和完善。 1 强大的语义搜索功能 传统的关键词搜索可能会遗漏相关文献,Sc

20180108文献综述书写感悟
在写文献综述理清各章节脉络的时候,发现了以下几个问题,共勉之。 1、资源对接问题:章节应该明确标注出处,来源,例如(from 百度/某篇文章链接),不写,则默认为原创。 以方便下一个接着写的同学清晰了解资料来源。 2、质量低:上任对发展史做了整理,但并没有输出成原创性文字,重新阅读加大理解成本,并且思路不新不全局不清晰,需要重新绘之。

Netty源码解析4-Handler综述
Netty中的Handler简介 Handler在Netty中,占据着非常重要的地位。Handler与Servlet中的filter很像,通过Handler可以完成通讯报文的解码编码、拦截指定的报文、 统一对日志错误进行处理、统一对请求进行计数、控制Handler执行与否。一句话,没有它做不到的只有你想不到的 Netty中的所有handler都实现自ChannelHandler接口。按照输入


零样本学习(zero-shot learning)——综述
-------本文内容来自对论文A Survey of Zero-Shot Learning: Settings, Methods, and Applications 的理解和整理,这里省去了众多的数学符号,以比较通俗的语言对零样本学习做一个简单的入门介绍,用词上可能缺乏一定的严谨性。一些图和公式直接来自于论文,并且省略了论文中讲的比较细的东西,如果感兴趣建议还是去通读论文 注1:为了方便,文中
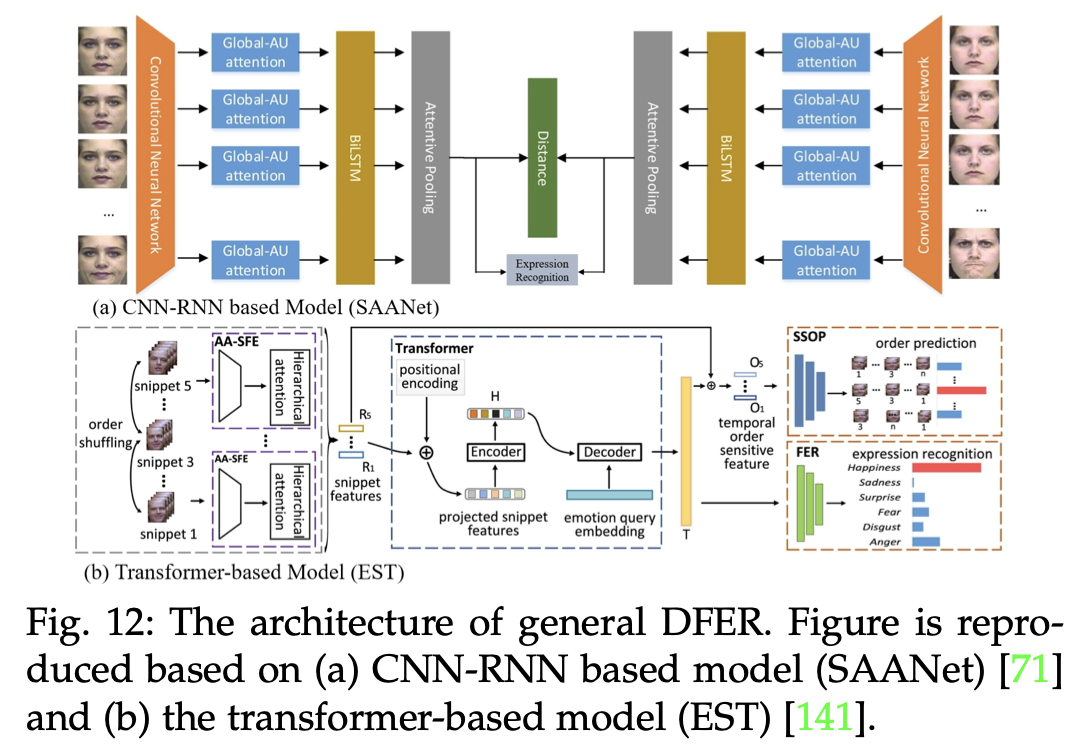
复旦大学王龑团队发布《静态与动态情感的面部表情识别》综述
论文链接:https://arxiv.org/pdf/2408.15777 复旦大学,王龑博士后领衔,发布《静态与动态情感的面部表情识别》(A Survey on Facial Expression Recognition of Static and Dynamic Emotions)综述,对基于图像的静态面部表情识别(SFER)和基于视频的动态面部表情识别(DFER)方法进行了全面综述,从

【论文阅读】语义通信安全研究综述(2024)
摘要 语义通信系统架构 笔记 内容概述 引言:介绍了语义通信技术的背景、发展和重要性,以及它在无线通信系统中面临的安全挑战。 语义通信系统架构及安全攻击:描述了一个端到端的深度学习语义通信系统的基本架构,包括语义编解码器、信道编解码器和收发端知识库等模块,并讨论了这些模块可能遇到的安全攻击,如窃听、篡改等。 语义通信模型安全研究现状:详细讨论了模型安全攻击手段(数据投毒、后门
《基础模型时代的图像分割》研究综述
图像分割的目标:将像素划分为不同的组别 现代图像分割方法:①适配基础模型(例如CLIP、Stable Diffusion、DINO)用于图像分割②开发专门的分割基础模型(如SAM) 一、本综述的两大基本研究方向 通用图像分割(即语义分割、实例分割、全景分割) 可提示的图像分割(即交互式分割、参考分割、少样本分割):指定图像要分割的内容 本综述的贡献: 对基于著名基础模型的最近图像分割方
jmeter 录制回放工具 badboy 界面综述
界面及功能总述 1. 菜单栏: (1)1 File: 包括常用的打开脚本,新建脚本,导出脚本,保存脚本等功能 (2)Edit: 点击Edit menu下的Search/Replace将在面板中弹出如下界面,帮助我们在脚本中选择和替换功能。点击X 关闭窗口。当然我们也可以使用F3快捷键弹出此界面 (3)View: 点击和再次点击,改变展示和隐藏视图
综述翻译:Machine Learning-Based Cache Replacement Policies: A Survey 2021
摘要: 虽然在提高命中率方便有了广泛进展,设计一个模拟Belady‘s 算法的缓存替换策略依旧很有挑战。现存的标准静态替换策略并不适合动态的内存访问模式,而计算机程序的多样性加剧了这个问题。有几个因素影响缓存策略的设计,如硬件升级,内存开销,内存访问模式,模型延时等。 用机器学习的算法解决缓存替换的问题取得了令人惊讶的结果,并朝着具有成本效应的解决方案发展。在本文中,我们回顾了一些基于机器学习

线性代数:线性代数(Linear Algebra)综述
文章目录 矩阵 / Matrix元素运算加法 A + B A+B A+B数量乘法 c A cA cA与向量之间的运算乘法 A b A\mathbf{b} Ab 与矩阵之间的运算矩阵乘法 乘方 性质方阵 / Square Matrix零矩阵对角矩阵 / Diagonal Matrix单位矩阵 / Identity Matrix转置 / Transpose逆矩阵 / Inverse Mat

跨模态检索研究文献综述(二)
随着互联网技术的蓬勃发展和智能设备的普及,多媒体数据在数量爆炸式增长的同时,其形态也越来越多样化。人们获取信息的需求已经不满足于单一模态的数据检索,通过不同模态的知识协同实现跨模态的检索成为近几年研究的热点。 在深入了解分析跨模态检索研究背景和研究进展的基础上,以跨模态检索的关键技术——公共子空间建模为主线,对跨模态检索技术的三大类方法传统统计分析方法、深度学习方法与哈希学习方法,从不同角度对研

跨模态检索研究进展综述【跨模态检索的核心工作在于:①不同模态数据的特征提取、②不同模态数据之间内容的相关性度量】【主流研究方法:基于传统统计分析的技术、基于深度学习的技术】【哈希编码提高检索速度】
随着互联网上多媒体数据的爆炸式增长,单一模态的检索已经无法满足用户需求,跨模态检索应运而生. 跨模态检索旨在以一种模态的数据去检索另一种模态的相关数据。 跨模态检索的核心任务是:数据特征提取 和 不同模态数据之间内容的相关性度量。 文中梳理了跨模态检索领域近期的研究进展,从以下角度归纳论述了跨模态检索领域的研究成果.: 传统方法;深度学习方法;手工特征的哈希编码方法;深度学习的哈希编码方法
tomcat + spring mvc 原理(一):tomcat原理综述和静态架构
tomcat + spring mvc 原理(一):tomcat原理综述和静态架构 tomcat + spring mvc的运作模式tomcat内部的基本容器构成tomcat容器对应的外部配置 tomat + spring mvc 是目前比较流行java微服务体系架构,包括现在的spring boot以及基于spring boot的进一步应用化封装的spring clou
《C++20 特性综述》
《C++20 特性综述》 在编程世界中,C++一直以其强大的性能和灵活性占据着重要地位。随着时间的推移,C++不断发展和演进,C++20 带来了一系列令人瞩目的新特性,为开发者提供了更强大的工具和更高效的编程方式。 一、概念(Concepts) C++20 引入了概念,这是一种对模板参数进行约束的方式。通过概念,开发者可以明确指定模板参数所必须满足的条件,提高代码的可读性和可维护性。例如,可

VLM(视觉语言模型)综述
概述 大型语言模型的出现标志着人工智能领域转型的开始,它们在文本信息处理上的能力极大地推动了这一进程。尽管LLMs在文本处理上表现出色,但它们主要限于处理单一模态的数据,即文本。这限制了它们在理解和生成涉及图像和视频等多模态数据方面的能力。自然智能能够处理多种模态的信息,包括书面和口头语言、图像的视觉解释以及视频的理解。为了使人工智能系统具有类似人类的认知功能,它们必须也能够处理多模态数据。
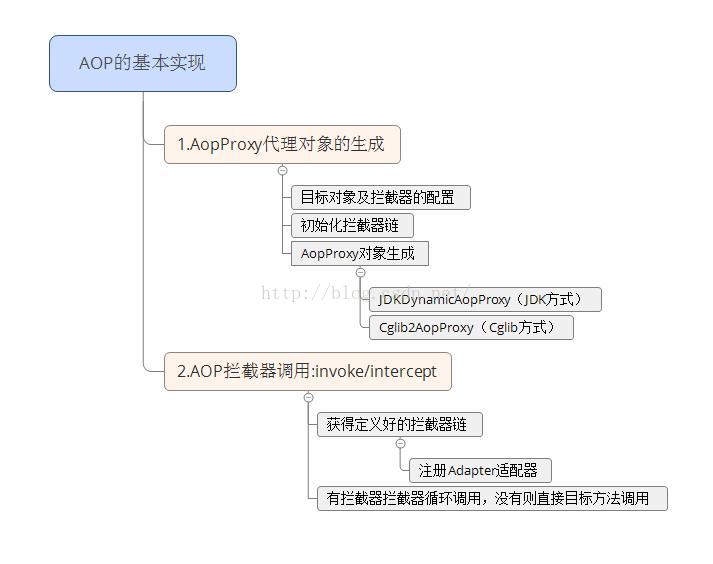
【Spring源码--AOP的实现】--综述
前言: 相比于IOC的源码,AOP的源码更为抽象一点。因为我们在读IOC源码,可以根据我们的Bean配置,去相结合着思考和理解,而AOP的是一个切面的概念,所生成的代理对象也不是我们说看到就看到的,相对抽象一点,但是AOP的源码相对于IOC的源码少了很多。所以我们在读AOP源码的时候,应该先把整个流程快速的读通,再去一点点具体到方法,再者就是自己动手写demo。那么,本文作为AOP的综述,主要

【JAVA入门】Day27 - 集合体系结构综述
【JAVA入门】Day27 - 集合体系结构综述 文章目录 【JAVA入门】Day27 - 集合体系结构综述一、单列集合体系结构1.1 Collection 集合的基本方法1.2 Collection 集合的遍历方式1.2.1 迭代器遍历1.2.2 增强 for 遍历1.2.3 利用 Lambda 表达式进行遍历 1.3 List 集合的基本方法1.4 List 集合的遍历方式
【综述】 从稀疏的数据中进行深度补全:Deep Depth Completion from Extremely Sparse Data: A Survey
【综述】 从稀疏的数据中进行深度补全:Deep Depth Completion from Extremely Sparse Data: A Survey 占坑,3日内更新

大语言模型向量检索技术综述:背景知识、数据效率、泛化能力、多任务学习、未来趋势
预训练语言模型如BERT和T5,是向量检索(后续文中使用密集检索)的关键后端编码器。然而,这些模型通常表现出有限的泛化能力,并在提高领域内准确性方面面临挑战。最近的研究探索了使用大型语言模型(LLMs)作为检索器,实现了各种任务的最新性能。尽管取得了这些进展,LLMs相对于传统检索器的具体优势,以及不同LLM配置—例如参数大小、预训练持续时间和对齐过程—对检索任务的影响仍然不清楚。在这项工作中,我

Games101学习 - 线性代数综述
1. 叉积矩阵形式 叉乘矩阵形式通常在物理模拟中有运用,处理四元数旋转也类似这样的形式。 // 定义两个向量 A 和 BFVector A(1.0f, 2.0f, 3.0f);FVector B(4.0f, 5.0f, 6.0f);// 计算叉积FVector CrossProduct = FVector::CrossProduct(A, B);if (GEngine){GEngine
『大模型笔记』Prompt Engineering具体实施方案综述!
Prompt Engineering具体实施方案综述! 文章目录 1. 背景2. prompt原则&技巧2.1. 指令清晰、详细2.1.1 问题里包含更多细节2.1.2 让模型角色扮演2.1.3 使用分隔符2.1.4 指定完成任务所需的步骤2.1.5 提供示例2.1.6 设定回答的长度 2.2 提供参考文本2.3 将复杂任务拆分2.3.1 问题分类2.3.2 分段总结长文/长对话 2.
