本文主要是介绍超速解读多模态InternVL-Chat1.5 ,如何做到开源SOTA——非官方首发核心技巧版(待修订),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
解读InternVL-chat1.5系列
最近并行是事情太杂乱了,静下心来看一看优秀的开源项目,但是AI技术迭代这么快,现在基本是同时看五、六个方向的技术架构和代码,哪个我都不想放,都想知道原理和代码细节,还要自己训练起来,导致每天脑袋隐隐作痛了,感觉有点天龙八部里的“鸠摩智”的状态。
…目前的大模型核心能力热点是其通用能力的提升,从判别式、到对比学习、再到如今的多阶段对齐训练。VLM多模态模型在这两年已经逐渐普及(比如qwen-vl\deepseek-vl\yi-vl\glm4-v\minicpm-v)等优秀开源模型,今天我们来直接看下当前的开源SOTA模型,InternVl1.5是上海AI LAB一直迭代的多模态视觉语言大模型,之前的版本是1.2,今年迭代到1.5后达到了国内开源的SOTA评测分数,今天我们来解读一下InternVL1.5是如何做到的!
文章更新比较仓促,我会后续再修订!感谢阅读
`
文章目录
- 解读InternVL-chat1.5系列
- 文章更新比较仓促,我会后续再修订!感谢阅读
- 阅读前置知识(Internvit的由来)
- 一、模型信息概览
- 二、Feature
- 1. PT阶段
- 2. 训练数据
- 3. Scale up Model
- 4. Dynamic Aspect Ratio Matching
- 总结
如今的VLM多模态虽然训练方式阶段各有不同,但是架构范式同质化严重:
1. 视觉基础模型(多模态图文能力的视觉模型,不只有检测、分割、分类、还有图文检索、图像描述、多模态对话的能力)
2. LLM模型
3. 链接两个模型的mlp projector
阅读前置知识(Internvit的由来)
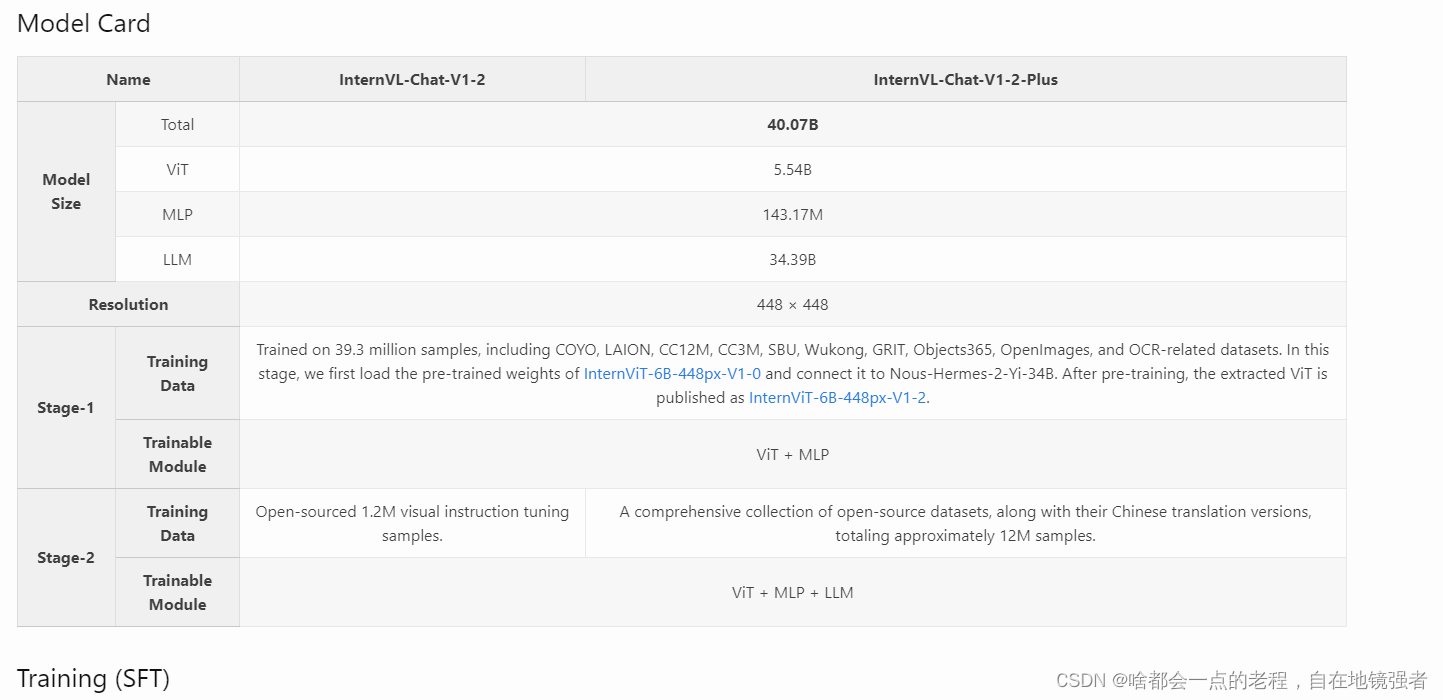
因为InternVL是从1.0开始迭代的,这里我们主要从1.5的版本和其前一版本1.2来进行解析!
Intervl1.0 经过三个阶段:对比学习PT、生成PT、SFT得到的一个视觉语言模型(数据多到少,质量低到高),最后通过深度和广度维度测试选定为6B模型。
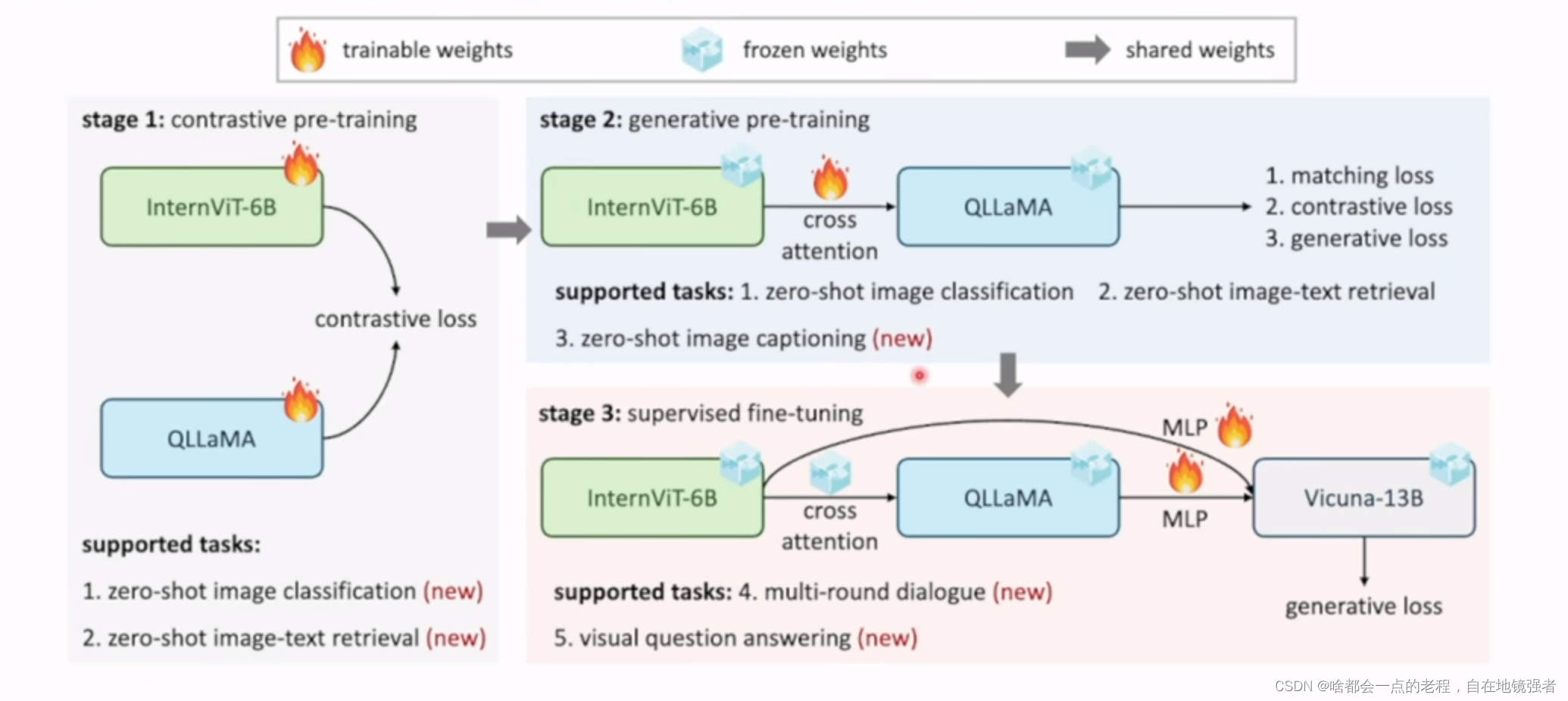
作者团队介绍到:
Intervit就是从Intervl中抽出internVIT-6B.(应该是48层变成45层)作为VLM视觉基础模型;也可以直接
作分类和图文检索、和SD的文本编码器(开源项目Mulan)
PIXEL Shuffle :空间下采样操作,具体在MLP层输入之前;reshape后,默认下采样0.5,1024->256,这样减少了输入到LLM的token数量。代码参考:
vit_embeds = self.pixel_shuffle(vit_embeds,scale_factor=self.downsample_ratio)
一、模型信息概览
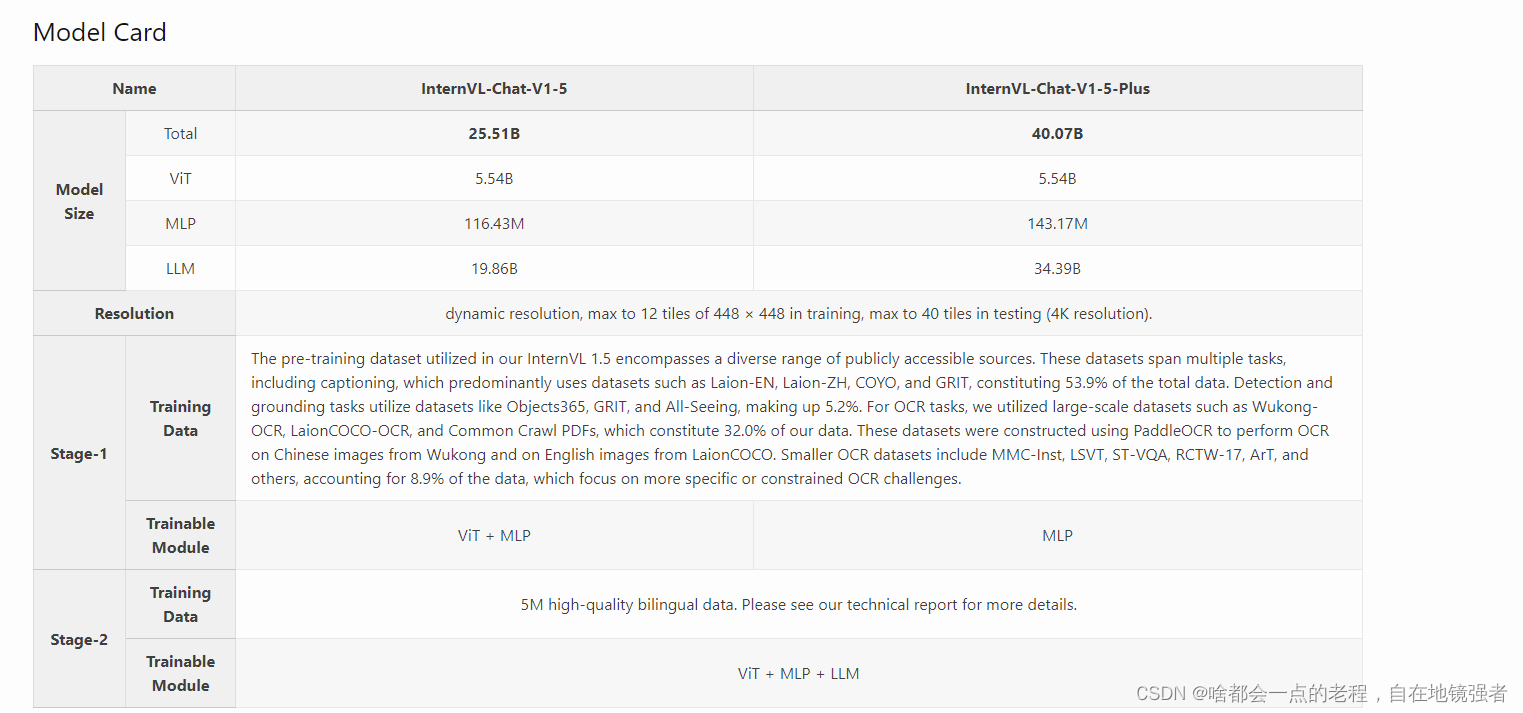
internVL-chat参考了LLaVA-NeXT-34B的做法,scale up 模型尺寸来验证VL性能的提升,这是1.2版本的思路,而1.5建立在1.2基础上进行了 迭代优化,先简要介绍下1.5,以及和1.2的区别。
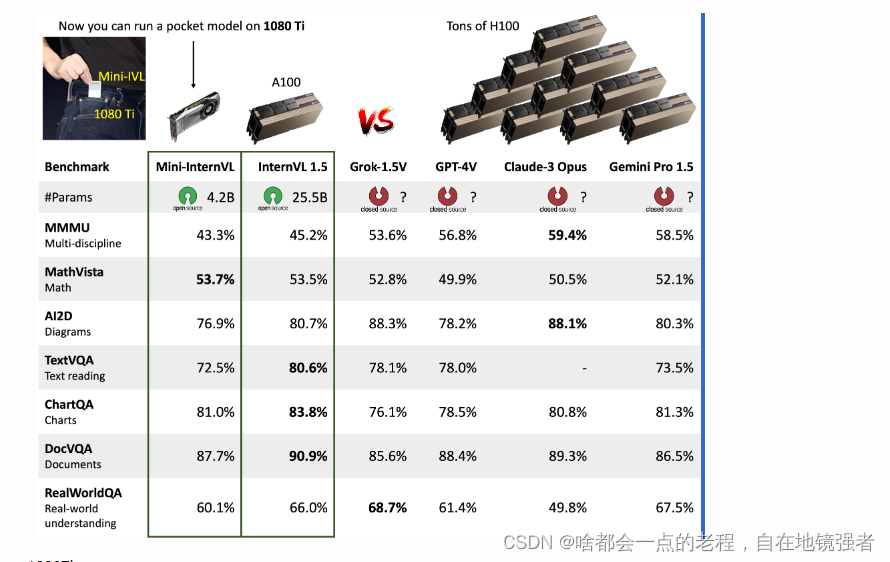
其中包含现在开源的和Plus版本:
MINI-intervl1.5-4 25.5B (internvit (6B)+internlm2-chat-20B(19.86B)+MLP)
MINI-intervl1.5-PLUS: (internvit (6B)+Nous-Hermes-2-Yi-34B+MLP) <未开源>
其中MIN包含:
MINI-intervl1.5-4.2B (internvit (300M)+phi3-mini-128K(3.8b)+MLP)
MINI-intervl1.5-2.2B (internvit (300M)+internLM2-chat_1.8B+MLP)
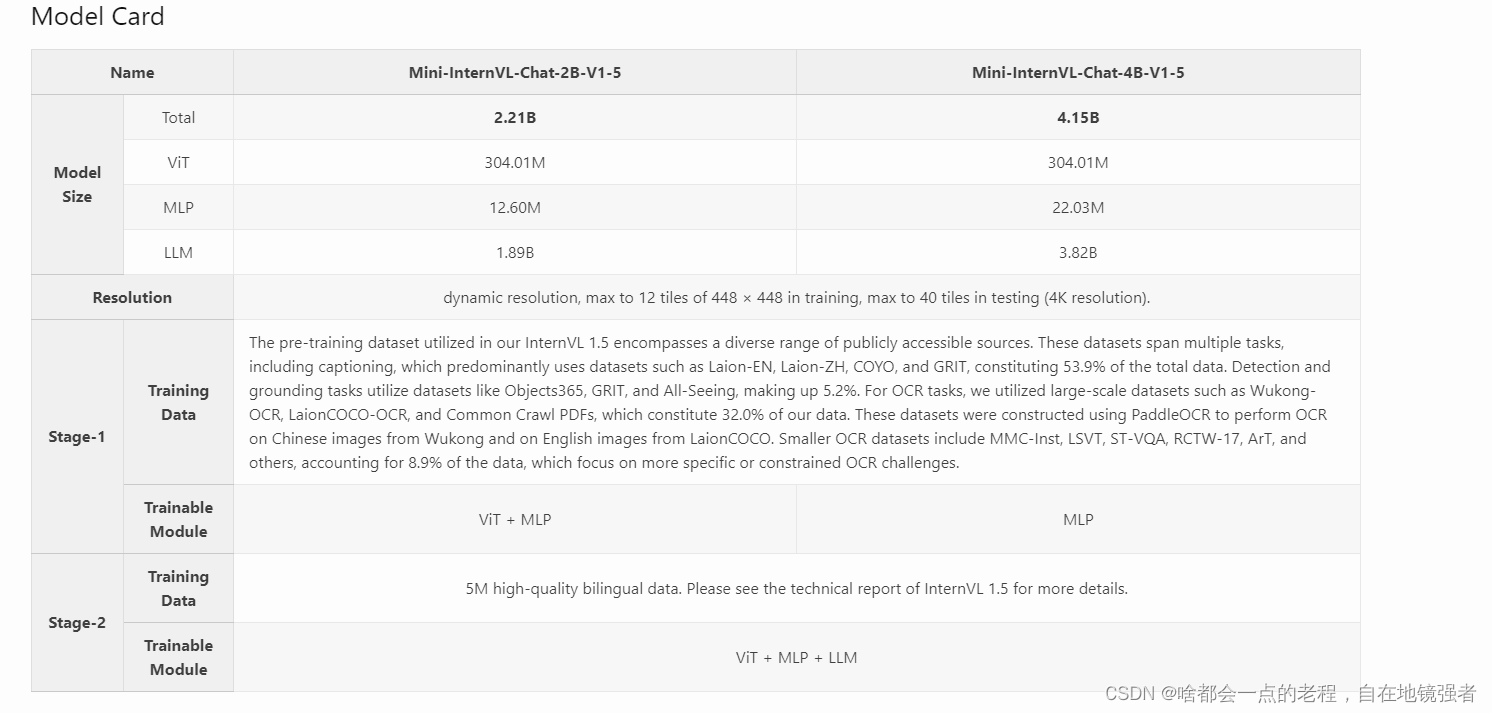
同样我们从上图对比中可以直观看到1.2到1.5之间一些明显的区别,同样也是改进提升的部分。
主要部分来说LLM的模型基座基本是一样的从小到大,再到34B的Nous-Hermes-2-Yi-34B(HF上开源fine-tune的版本)为PLUS版本的基座,基本上都是挑选的开源模型和其兄弟团队的intern2LM系列。所以LLM模型本身没什么特别需要说明的。
而至于MINI版本是其视觉编码器InternVIT通过蒸馏从6B压缩到300M得到的,再结合PHI3这些小模型。接下来让我们进入核心环节。
二、Feature
不同的改进之处:
1. PT阶段
1.2版本的PT阶段VIT+MLP,而1.5的PT阶段对于大尺寸的LLM只训练MLP,小尺寸的LLM训练MLP+vit,
额外说下在PT后模型会被抽出来,减少三层也就是Internvit模型从原来48层减少到45层,再试用Pixel
suffle减少token数量到256.
2. 训练数据
额外使用了GPT-40模型进行标注生成,已经开源在huggingface上
1.5比1.2扩充了在SFT阶段扩充了高质量的双语数据(多语言、精细Prompt标注),特别强化了图像分辨率支持到4K和OCR能力。
因为多模态训练本身需要多任务数据集去训练,数据是保证模型评分指标的第一优先级。
–

不同的只是LLM模型的不同。MINI版本的分别选择了internLM2-chat-1.8B和PHI3-mini-128K

3. Scale up Model
视觉模型与LLM参数量差距过大,一味提升大模型的参数量,VLM的能力并不会随之线性提升,因此从过去的版本的InternVL中通过实验证明了,视觉编码器的scale up也同样重要。所以视觉模型和语言模型同时scale up ,对于性能提升是有必要的,这也贯彻了sacle law。
4. Dynamic Aspect Ratio Matching
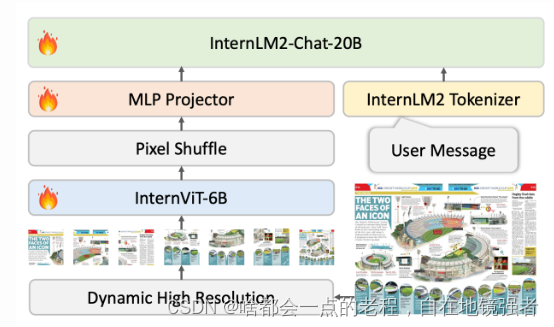
这是internvl1.5非常重要的一步骤,因为模型作者认为图像分辨率对于性能提升非常关键,因此聚焦于动态自定义分辨率,设计实现如上图:
- 预设纵横比集合:例如{1:1, 1:2, 1:3, 1:4, 1:5, 1:6, 2:3, 3:2 …,2:6}多种可能的组合(这取决于自定义min和max两个变量,后面代码会说到)
- 最优匹配:对于每个输入图像,系统会计算其纵横比,并与预定义的集合进行比较,找出差异最小的纵横比。那么如果有多个匹配的纵横比(即并列最小差异)怎么办?比较原始图像面积与特定纵横比下的图像面积来实现的。如果特定纵横比下的图像面积大于原始图像面积的一半,那么这个纵横比会被选为最优纵横比。
- patch 分割:输入图像被动态分割成448x448的patch ,patch的数量是根据图像匹配的纵横比和分辨率 (在1到12之间变化)。
- 图像分割与缩略图(Image Division & Thumbnail)
调整图像分辨率:一旦确定了合适的纵横比,图像将被调整到相应的分辨率。例如,一个800×1300的图像将被调整到896×1344。
分割图像:调整后的图像被分割成448×448像素的瓦片。在训练阶段,根据图像的纵横比和分辨率,瓦片的数量可以在1到12,推理时候是1到40
全局上下文缩略图:同时会resize 原始图像到448x448,帮助模型理解整体场景。
核心代码如下,比较简单不做注释了:
from transformers import AutoTokenizer, AutoModel
import torch
import torchvision.transforms as T
from PIL import Imagefrom torchvision.transforms.functional import InterpolationModeIMAGENET_MEAN = (0.485, 0.456, 0.406)
IMAGENET_STD = (0.229, 0.224, 0.225)def build_transform(input_size):MEAN, STD = IMAGENET_MEAN, IMAGENET_STDtransform = T.Compose([T.Lambda(lambda img: img.convert('RGB') if img.mode != 'RGB' else img),T.Resize((input_size, input_size), interpolation=InterpolationMode.BICUBIC),T.ToTensor(),T.Normalize(mean=MEAN, std=STD)])return transformdef find_closest_aspect_ratio(aspect_ratio, target_ratios, width, height, image_size):best_ratio_diff = float('inf')best_ratio = (1, 1)area = width * heightfor ratio in target_ratios:target_aspect_ratio = ratio[0] / ratio[1]ratio_diff = abs(aspect_ratio - target_aspect_ratio)if ratio_diff < best_ratio_diff:best_ratio_diff = ratio_diffbest_ratio = ratioelif ratio_diff == best_ratio_diff:if area > 0.5 * image_size * image_size * ratio[0] * ratio[1]:best_ratio = ratioreturn best_ratio#动态分辨率预处理
def dynamic_preprocess(image, min_num=1, max_num=6, image_size=448, use_thumbnail=False):orig_width, orig_height = image.sizeaspect_ratio = orig_width / orig_height# calculate the existing image aspect ratiotarget_ratios = set((i, j) for n in range(min_num, max_num + 1) for i in range(1, n + 1) for j in range(1, n + 1) ifi * j <= max_num and i * j >= min_num)target_ratios = sorted(target_ratios, key=lambda x: x[0] * x[1])# find the closest aspect ratio to the targettarget_aspect_ratio = find_closest_aspect_ratio(aspect_ratio, target_ratios, orig_width, orig_height, image_size)# calculate the target width and heighttarget_width = image_size * target_aspect_ratio[0]target_height = image_size * target_aspect_ratio[1]blocks = target_aspect_ratio[0] * target_aspect_ratio[1]# resize the imageresized_img = image.resize((target_width, target_height))processed_images = []for i in range(blocks):box = ((i % (target_width // image_size)) * image_size,(i // (target_width // image_size)) * image_size,((i % (target_width // image_size)) + 1) * image_size,((i // (target_width // image_size)) + 1) * image_size)# split the imagesplit_img = resized_img.crop(box)processed_images.append(split_img)assert len(processed_images) == blocksif use_thumbnail and len(processed_images) != 1:thumbnail_img = image.resize((image_size, image_size))processed_images.append(thumbnail_img)return processed_imagesdef load_image(image_file, input_size=448, max_num=6):image = Image.open(image_file).convert('RGB')transform = build_transform(input_size=input_size)images = dynamic_preprocess(image, image_size=input_size, use_thumbnail=True, max_num=max_num)pixel_values = [transform(image) for image in images]pixel_values = torch.stack(pixel_values)return pixel_values
额外的实验结果是,训练在1-12 块Patch的范围内,但是推理时候泛化到了40个,(开始说过VIT模型输出是256个token,所以256x(40+1)=10496),实验证明24块为最优效果。
后续有代码相关问题和实践问题我会修订补充在这里
总结
internvl,通过自己提炼的Internvit和探索大模型参数,最终以6B为基准作为基线视觉编码器,再通过提高分辨率改为动态;在视觉模型上下了很大的功夫;其次同样scale up大模型参数量,这也符合scale law的经验,但是最关键的还有其1.5版本尚未开源的高质量数据集(1.2的数据集也可以用,但是明显1.5有一多半的功劳还是数据),期待后续开源数据集。其MINI系列提供了2B和4B版本的模型对于散修来说非常友好,最近几天我也在折腾,打算先用Lora试(用MINI2B版本,进行Lora target qkv \bf16 大概19G+显存的训练开销),值得一提的是其尚未开源的PLUS版本应该Beach mark得分会更高,但是因为模型参数40B比较大 ,可能普通散修没有资源来微调。
这篇关于超速解读多模态InternVL-Chat1.5 ,如何做到开源SOTA——非官方首发核心技巧版(待修订)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




