模态专题

LLM系列 | 38:解读阿里开源语音多模态模型Qwen2-Audio
引言 模型概述 模型架构 训练方法 性能评估 实战演示 总结 引言 金山挂月窥禅径,沙鸟听经恋法门。 小伙伴们好,我是微信公众号《小窗幽记机器学习》的小编:卖铁观音的小男孩,今天这篇小作文主要是介绍阿里巴巴的语音多模态大模型Qwen2-Audio。近日,阿里巴巴Qwen团队发布了最新的大规模音频-语言模型Qwen2-Audio及其技术报告。该模型在音频理解和多模态交互

时序预测|变分模态分解-双向时域卷积-双向门控单元-注意力机制多变量时间序列预测VMD-BiTCN-BiGRU-Attention
时序预测|变分模态分解-双向时域卷积-双向门控单元-注意力机制多变量时间序列预测VMD-BiTCN-BiGRU-Attention 文章目录 一、基本原理1. 变分模态分解(VMD)2. 双向时域卷积(BiTCN)3. 双向门控单元(BiGRU)4. 注意力机制(Attention)总结流程 二、实验结果三、核心代码四、代码获取五、总结 时序预测|变分模态分解-双向时域卷积

一键部署Phi 3.5 mini+vision!多模态阅读基准数据集MRR-Benchmark上线,含550个问答对
小模型又又又卷起来了!微软开源三连发!一口气发布了 Phi 3.5 针对不同任务的 3 个模型,并在多个基准上超越了其他同类模型。 其中 Phi-3.5-mini-instruct 专为内存或算力受限的设备推出,小参数也能展现出强大的推理能力,代码生成、多语言理解等任务信手拈来。而 Phi-3.5-vision-instruct 则是多模态领域的翘楚,能同时处理文本和视觉信息,图像理解、视频摘要

ACL22--基于CLIP的非代表性新闻图像的多模态检测
摘要 这项研究调查了假新闻如何使用新闻文章的缩略图,重点关注新闻文章的缩略图是否正确代表了新闻内容。在社交媒体环境中,如果一篇新闻文章与一个不相关的缩略图一起分享,可能会误导读者对问题产生错误的印象,尤其是用户不太可能点击链接并消费整个内容的情况下。我们提议使用预训练的CLIP(Contrastive Language-Image Pretraining)表示来捕捉多模态关系中语义不一致的程度。

大白话说什么是“MLLM”多模态大语言模型
1. 什么是MLLM多模态大语言模型 1.1 先来思考一个问题 如果上传了一张图片,并向大模型提问。“图片中绿色框框中的人是谁?” 大模型回答:“那是波多野吉衣老师” 请问,大模型是怎么做到的? 我们用常规的思路来想一下,难道是: 第一步:先对图片进行目标检测,先把绿色框的内容剪切出来; 第二步:在剪切后的图片中,把人脸标记出来,并读取其landmark转为向量; 第三步:在人脸向

AI推介-多模态视觉语言模型VLMs论文速览(arXiv方向):2024.08.20-2024.08.25
文章目录~ 1.LowCLIP: Adapting the CLIP Model Architecture for Low-Resource Languages in Multimodal Image Retrieval Task2.Evaluating Attribute Comprehension in Large Vision-Language Models3.PropSAM: A P

基于多模态大语言模型的摄像头实时感知交互
简介: 调用本地摄像头,通过多模态大语言模型实时感知世界,并进行交互 界面: 代码: import tkinter as tkfrom tkinter import ttkfrom PIL import Image, ImageTkimport cv2import requests# 定义处理函数def capture_and_send():# 从摄像头读取当前帧ret, fra

多模态:DetCLIPv3解析
文章目录 前言一、介绍二、方法2. Open vocabulary detector2.1 encoder2.2 decoder 3. Object captioner 三、数据工程1. Auto-annotation data pipeline 四、训练策略五、实验总结 前言 目前多模态目标检测逐渐成为检测领域的主要发力方向,从最初的检测大模型grounding dino,

多模态大模型如何改变我们的生活?
2022年,OpenAI 的ChatGPT 3.5 横空出世,搅动了整个AI 行业。Transformer、LLM、VLM、大模型、多模态等概念蜂拥而至。让我们不禁感慨这世界技术更新之快。 【什么是大模型?】 “大模型”通常指具有数十亿到数千亿个参数的神经网络模型,需要大量的计算资源和数据来进行训练和运行。通过硬件计算能力的提升,以及训练数据量的增加,使得大模型可以完成更复杂的任务,为人们

MLM:多模态大型语言模型的简介、微调方法、发展历史及其代表性模型、案例应用之详细攻略
MLM:多模态大型语言模型的简介、微调方法、发展历史及其代表性模型、案例应用之详细攻略 目录 相关文章 AI之MLM:《MM-LLMs: Recent Advances in MultiModal Large Language Models多模态大语言模型的最新进展》翻译与解读 MLM之CLIP:CLIP(对比语言-图像预训练模型)的简介、安装和使用方法、案例应用之详细攻略 多模

AI推介-多模态视觉语言模型VLMs论文速览(arXiv方向):2024.08.15-2024.08.20
文章目录~ 1.Out-of-Distribution Detection with Attention Head Masking for Multimodal Document Classification2.Open-FinLLMs: Open Multimodal Large Language Models for Financial Applications3.HiRED: Atte
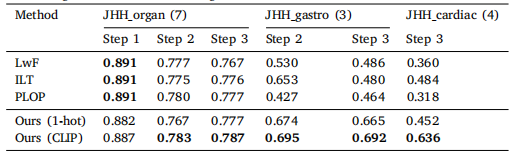
用于腹部计算机断层扫描中器官分割和肿瘤检测的通用且可扩展的语言-视觉模型|文献-大模型与多模态诊断阿尔茨海默症与帕金森疾病应用
Title 题目 Universal and extensible language-vision models for organ segmentation and tumor detection from abdominal computed tomography 用于腹部计算机断层扫描中器官分割和肿瘤检测的通用且可扩展的语言-视觉模型 01 文献速递介绍 计算

大模型之多模态检索,零基础入门到精通,收藏这一篇就够了
“ 多模态,一种让大模型更加像人的技术**”** 多模态是目前人工智能领域非常重要的一个研究方向,也可以说多模态是走向AGI(通用人工智能)的一种方式,关于多模态的介绍可以看文章什么是多模态 但从宏观来看多模态只是一种实现人工智能的方法论,其中有很多细分方向需要研究,比如多模态大模型,多模态检索等;然后不同领域还会涉及到不同的技术

多目标应用:基于双存档模型的多模态多目标进化算法(MMOHEA)的移动机器人路径规划研究(提供MATLAB代码)
一、机器人路径规划介绍 移动机器人(Mobile robot,MR)的路径规划是 移动机器人研究的重要分支之,是对其进行控制的基础。根据环境信息的已知程度不同,路径规划分为基于环境信息已知的全局路径规划和基于环境信息未知或局部已知的局部路径规划。随着科技的快速发展以及机器人的大量应用,人们对机器人的要求也越来越高,尤其表现在对机器人的智能化方面的要求,而机器人自主路径规划是实现机器人智能化的
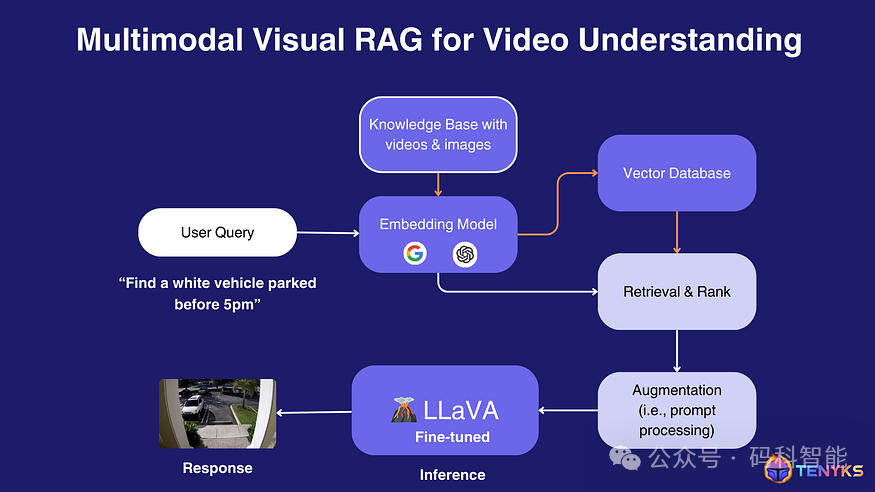
自然语言处理:第四十三章 视觉RAG:变革传统深度学习模型开发流程,开创下一代多模态视觉模型的新时代
文章链接:微信公众平台 (qq.com) 写在前面: 笔者更新不易,希望走过路过点个关注和赞,笔芯!!! 写在前面: 笔者更新不易,希望走过路过点个关注和赞,笔芯!!! 写在前面: 笔者更新不易,希望走过路过点个关注和赞,笔芯!!! 我们相信视觉领域即将发生范式转变,从而产生计算机视觉管道 2.0,其中一些传统阶段(例如标记)将被可提示的基础模型所取代。 本文深入剖析了Vis

LLaVA-MoLE:解决多模态大模型指令微调中的数据冲突问题
人工智能咨询培训老师叶梓 转载标明出处 多模态大模型(MLLMs)通过指令微调(instruction finetuning),能够执行各种任务,如理解图表、处理文档和回答基于图像的问题。但是,当从不同领域混合指令数据进行微调时,模型在特定领域的任务上可能会出现性能下降。这种现象被称为数据冲突,它限制了通过增加新领域训练数据来扩展MLLM能力的可能性。为了应对这一挑战,来自美团公司的研究者们提出
跨模态检索研究文献综述(二)
随着互联网技术的蓬勃发展和智能设备的普及,多媒体数据在数量爆炸式增长的同时,其形态也越来越多样化。人们获取信息的需求已经不满足于单一模态的数据检索,通过不同模态的知识协同实现跨模态的检索成为近几年研究的热点。 在深入了解分析跨模态检索研究背景和研究进展的基础上,以跨模态检索的关键技术——公共子空间建模为主线,对跨模态检索技术的三大类方法传统统计分析方法、深度学习方法与哈希学习方法,从不同角度对研

跨模态检索研究进展综述【跨模态检索的核心工作在于:①不同模态数据的特征提取、②不同模态数据之间内容的相关性度量】【主流研究方法:基于传统统计分析的技术、基于深度学习的技术】【哈希编码提高检索速度】
随着互联网上多媒体数据的爆炸式增长,单一模态的检索已经无法满足用户需求,跨模态检索应运而生. 跨模态检索旨在以一种模态的数据去检索另一种模态的相关数据。 跨模态检索的核心任务是:数据特征提取 和 不同模态数据之间内容的相关性度量。 文中梳理了跨模态检索领域近期的研究进展,从以下角度归纳论述了跨模态检索领域的研究成果.: 传统方法;深度学习方法;手工特征的哈希编码方法;深度学习的哈希编码方法

Python自适应光学模态星形小波分析和像差算法
🎯要点 🎯星形小波分析像差测量 | 🎯对比傅里叶和小波分析 | 🎯定义多尺度图像质量度量,矩阵数据 | 🎯像差校正算法 | 🎯受激发射损耗显微镜布局 | 🎯干涉仪分支校准,求解正则化最小二乘问题计算控制矩阵 | 🎯像差理论多项式逼近算法 📜光学和散射用例 🍪语言内容分比 🍇Python光学成像点源响应 荧光显微镜是一种光学显微镜,它使用荧光代替或补充散射、反射

书生浦语实训营-InternVL 多模态模型部署微调实践
1.什么是InternVL InternVL 是一种用于多模态任务的深度学习模型,旨在处理和理解多种类型的数据输入,如图像和文本。它结合了视觉和语言模型,能够执行复杂的跨模态任务,比如图文匹配、图像描述生成等。 2.InternVL模型介绍 对于InternVL这个模型来说,它的vision模块就是一个微调过的ViT,llm模块是一个InternLM的模型。对于视觉模块来说,它的特殊之处在
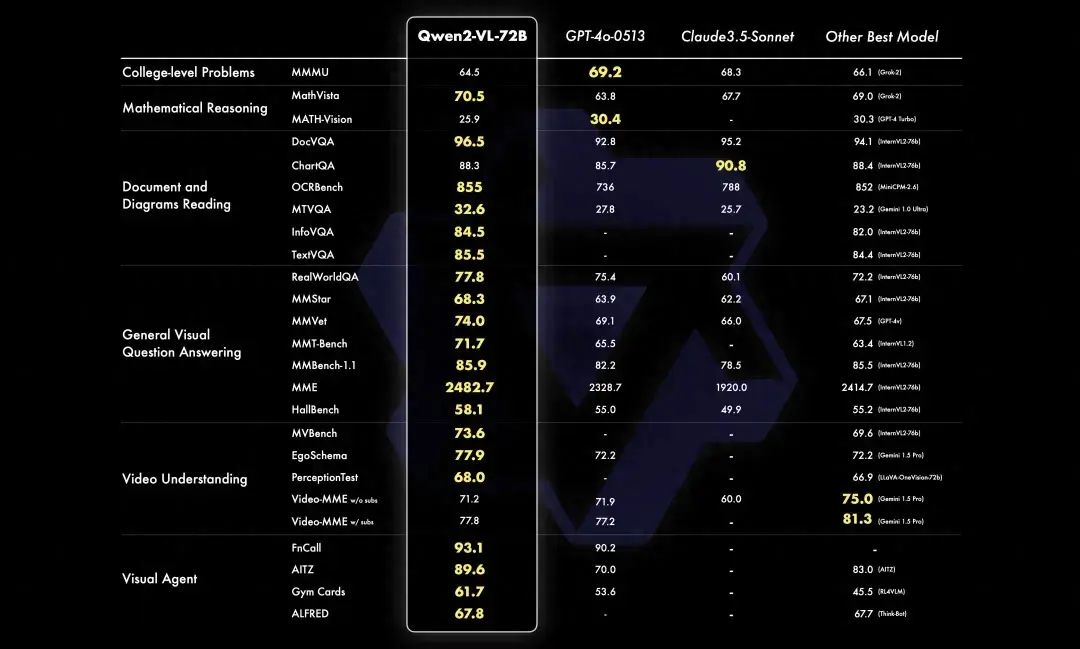
AI大模型日报#0830:智谱AI推出多款升级模型、阿里开源多模态Qwen2-VL
导读:AI大模型日报,爬虫+LLM自动生成,一文览尽每日AI大模型要点资讯!目前采用“文心一言”(ERNIE-4.0-8K-latest)、“智谱AI”(glm-4-0520)生成了今日要点以及每条资讯的摘要。欢迎阅读!《AI大模型日报》今日要点:智谱AI在KDD 2024上展示了其全新大模型GLM-4-Plus,该模型在多任务上逼近甚至超越GPT-4o,并推出了支持中英双语的对话机器人等功能,巩
多模态论文学习8.29
系列论文研读目录 文章目录 系列论文研读目录翻译《The Power of Scale for Parameter-Efficient Prompt Tuning》 翻译《The Power of Scale for Parameter-Efficient Prompt Tuning》

遥感多模态基础大模型汇总-实时更新
本文内容来自下面链接,考虑到很多同学登录不了,故在此平台进行分享。 遥感基础大模型 Table of Contents ModelsRemote Sensing Vision Foundation Models 遥感视觉基础模型Remote Sensing Vision-Language Foundation Models 遥感视觉语言基础模型Remote Sensing Generative

探索多模态人工智能:融合视觉、语言与声音的未来智能系统
前言 在这个信息爆炸的时代,人工智能(AI)已经渗透到我们生活的每一个角落,从智能手机的语音助手到自动驾驶汽车,再到医疗诊断和个性化推荐系统。然而,随着技术的进步,我们对智能系统的要求也在不断提高。我们不再满足于单一的智能功能,而是期待它们能够理解并处理来自不同源的复杂信息——这正是多模态人工智能(Multimodal AI)的魅力所在。 多模态AI技术,它通过融合多种模态的数据——文
bootstrap中模态框覆盖其他样的解决
在bootstrap的CSS中样式中淡入淡出的样式。 如果模态框的div在当前页面中,那么有可能其他的样式被覆盖。解决方式就是重写下面CSS样式。 .modal.fade { top: -100%; //bootstrap中的top是-25% -webkit-transition: opacity 0.3s linear, top 0.3s ease-out; -moz-transition:
bootstrap模态框传值问题
关于模态框传值的方法有很多种,这里我主要记录下我传递的过程。 <div style="height: 90px;" class="default"><p>${receiver.consignee}</p><p>${receiver.phone}</p><p>${receiver.address}</p> <input type="button" class="btn upd" value=