本文主要是介绍大模型之多模态检索,零基础入门到精通,收藏这一篇就够了,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
“ 多模态,一种让大模型更加像人的技术**”**
多模态是目前人工智能领域非常重要的一个研究方向,也可以说多模态是走向AGI(通用人工智能)的一种方式,关于多模态的介绍可以看文章什么是多模态
但从宏观来看多模态只是一种实现人工智能的方法论,其中有很多细分方向需要研究,比如多模态大模型,多模态检索等;然后不同领域还会涉及到不同的技术与难点。
今天就来介绍一下多模态检索以及其技术问题和应用。
多模态检索
多模态检索是一个涉及多个数据模态(文本,图像,视频)的检索技术,旨在通过整合这些不同形式的数据,提供更全面和精确的检索结果。
以下从原理,技术和应用等多个方面详细介绍多模态检索:
原理
多模态检索的核心原理包括以下几个方面:
模态融合:将不同模态的数据结合起来进行检索,融合方法可以是早期融合(特征层面融合)或晚期融合(在决策层面融合)。
嵌入空间:通过将不同模态的数据映射到一个共同的嵌入空间,使得不同模态的数据可以在同一空间中进行比较和检索。这个嵌入空间可以使得在一个模态中的查询能够找到在其它模态中相关的内容。
特征共享:利用共享的特征表示(如联合特征向量)来进行检索,提升了跨模态匹配的准确性。
技术
多模态检索技术可以从以下几个方面进行理解:
数据预处理
文本处理:包括分词,去停用词,词嵌入(如Word2Vec,GloVe,BERT等)
图像处理:包括缩放,裁剪,颜色标准化等,通常使用CNN提取特征
音频处理:包括声音分段,特征提取(如MFCC,图谱)等
视频处理:包括帧提取,时间序列建模等,使用3D CNN,LSTM等技术处理时空特征
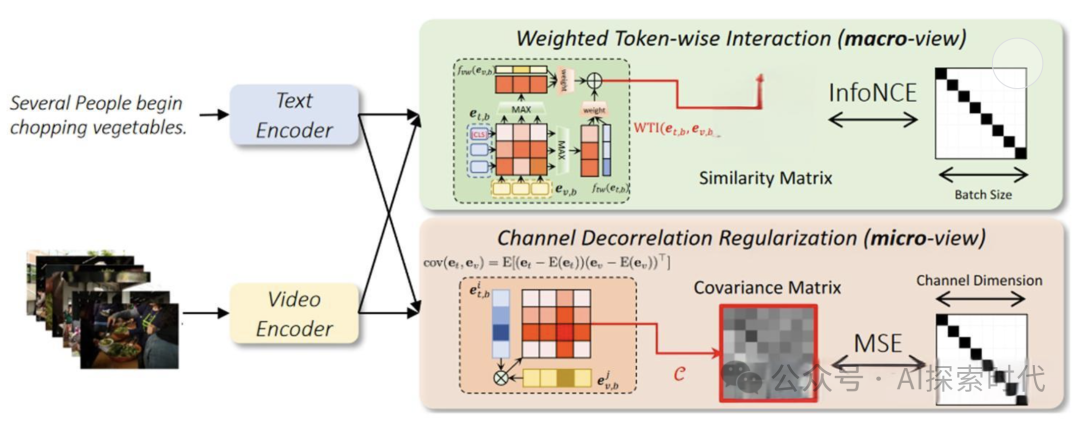
特征提取与表示
文本特征:通过深度学习模型(如BERT,GPT)提取文本的上下文语义
图像特征:通过卷积神经网络提取图像的视觉特征
音频特征:利用声学模型(如CNN,RNN)提取音频的特征
视频特征:通过3D CNN或RNN捕捉视频中的时空动态特征
模态融合技术
早期融合:将不同模态的数据在特征层面进行融合,生成综合特征表示,常见的方法包括特征拼接,加权平均等
晚期融合:先分别处理各个模态的特征,然后在检索或决策阶段将这些结果进行合并。常见的方法包括投票机制,加权合并等
联合嵌入:将不同模态数据映射到一个共同的嵌入空间,通过优化算法(如对比损失函数)来保持模态间的一致性
模型与算法
对比学习:通过对比不同模态的嵌入向量,使得相似内容在嵌入空间中更接近
生成对抗网络:用于生成和增强跨模态数据的特征表示
注意力机制:在模态融合中用于动态调整不同模态的权重
深度神经网络:包括多模态神经网络架构,如多模态Transformer等
应用
多模态检索技术具有广泛的应用场景:
图像与文本检索
图像搜索:用户上传一张图片,系统检索与该图像相关的文本描述或标签
文本到图像检索:用户输入一段文本,系统找到匹配该描述的图像
视频检索
视频内容检索:通过输入文字描述或语音查询,检索包含相关内容的视频片段
视频标签生成:自动为视频生成相关的文本标签,以便于检索和分类
多模态推荐系统
个性化推荐:基于用户的文本评论,点击行为,观看历史等多种数据提供推荐。例如,推荐电影,音乐和商品。
医疗诊断
影像与文本分析:结合医学图像(如X光片,CT扫码)和患者的文本记录进行诊断和病情分析
社交媒体分析
内容理解:分析社交媒体中的文本,图片和视频内容,提供更全面的情感分析,趋势识别等
_挑战与发展方向_
数据对齐与匹配
多模态对齐:如何有效对齐不同模态的数据,使得跨模态匹配更加准确
跨模态学习
跨模态迁移:如何在不同模态间迁移学习,提高系统在新模态下的表现
实时性与效率
处理大规模数据:需要处理和检索大规模的多模态数据,保证系统的实时响应能力
隐私与安全
数据隐私保护:在处理用户的多模态数据时,需要保护用户隐私和数据安全
总结
多模态检索技术通过整合不同形式的数据,提供了更加丰富和精准的检索能力。随着技术的不断进步和应用场景的拓展,多模态检索在实际应用中展现出巨大的潜力,同时也面临着一系列挑战,需要进一步的研究和技术突破。
如果你也想学习:黑客&网络安全的零基础攻防教程
今天只要你给我的文章点赞,我私藏的网安学习资料一样免费共享给你们,来看看有哪些东西。
1.学习路线图
攻击和防守要学的东西也不少,具体要学的东西我都写在了上面的路线图,如果你能学完它们,你去就业和接私活完全没有问题。
2.视频教程
网上虽然也有很多的学习资源,但基本上都残缺不全的,这是我自己录的网安视频教程,上面路线图的每一个知识点,我都有配套的视频讲解。
内容涵盖了网络安全法学习、网络安全运营等保测评、渗透测试基础、漏洞详解、计算机基础知识等,都是网络安全入门必知必会的学习内容。

(都打包成一块的了,不能一一展开,总共300多集)
因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
CSDN大礼包:《黑客&网络安全入门&进阶学习资源包》免费分享
3.技术文档和电子书
技术文档也是我自己整理的,包括我参加大型网安行动、CTF和挖SRC漏洞的经验和技术要点,电子书也有200多本,由于内容的敏感性,我就不一一展示了。

因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
CSDN大礼包:《黑客&网络安全入门&进阶学习资源包》免费分享
4.工具包、面试题和源码
“工欲善其事必先利其器”我为大家总结出了最受欢迎的几十款款黑客工具。涉及范围主要集中在 信息收集、Android黑客工具、自动化工具、网络钓鱼等,感兴趣的同学不容错过。
还有我视频里讲的案例源码和对应的工具包,需要的话也可以拿走。
因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
CSDN大礼包:《黑客&网络安全入门&进阶学习资源包》免费分享
最后就是我这几年整理的网安方面的面试题,如果你是要找网安方面的工作,它们绝对能帮你大忙。
这些题目都是大家在面试深信服、奇安信、腾讯或者其它大厂面试时经常遇到的,如果大家有好的题目或者好的见解欢迎分享。
参考解析:深信服官网、奇安信官网、Freebuf、csdn等
内容特点:条理清晰,含图像化表示更加易懂。
内容概要:包括 内网、操作系统、协议、渗透测试、安服、漏洞、注入、XSS、CSRF、SSRF、文件上传、文件下载、文件包含、XXE、逻辑漏洞、工具、SQLmap、NMAP、BP、MSF…

因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
CSDN大礼包:《黑客&网络安全入门&进阶学习资源包》免费分享
这篇关于大模型之多模态检索,零基础入门到精通,收藏这一篇就够了的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






