本文主要是介绍Waymo视角革新!MoST:编码视觉世界,刷新轨迹预测SOTA!,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
论文标题:
MoST: Multi-modality Scene Tokenization for Motion Prediction
论文作者:
Norman Mu, Jingwei Ji, Zhenpei Yang, Nate Harada, Haotian Tang, Kan Chen, Charles R. Qi, Runzhou Ge, Kratarth Goel, Zoey Yang, Scott Ettinger, Rami Al-Rfou, Dragomir Anguelov, Yin Zhou
导读:
现有的运动预测模型通常依赖于符号化的感知输出(如3D边界框),来生成智能体(如车辆、行人)的轨迹。然而,这种方法可能会因感知错误而变得脆弱,并且可能忽略了场景上下文中的关键信息。MoST方法通过将视觉世界划分为一组紧凑的场景元素,然后利用预训练的图像基础模型和LiDAR神经网络以开放词汇的方式编码所有场景元素,从而解决了这个问题。©️【深蓝AI】编译
1. 问题提出
在复杂环境中,自动驾驶系统需要准确模拟周围智能体的行为,来确保安全高效运行。当前的运动预测模型通常依赖于象征性的感知数据,如3D边界框,来描述智能体状态,而非直接处理原始传感器数据。这种简化输入的方法有助于构建计算效率更高的模型,并便于构建多种模拟场景进行测试。然而,为了提升模型的预测准确性和稳定性,则需要引入更高精度的传感器特征。
例如,相比于边界框,行人姿态和视线等信息能为运动预测提供更丰富的信息。某些场景元素(如车道线)和环境背景(如路面状况和危险区域)难以用简单的边界框表示。手工构建这些复杂概念的表示需要大量的工程工作。
深度学习模型通常在扩大计算资源和数据量时,通过直接利用观察到的特征来替代人工设计的特征,从而提高性能。然而,直接从高维传感器输入(如高分辨率的LiDAR和相机数据)学习预测复杂模式,如智能体行为,是一个极具挑战性的任务,需要处理大量点和像素的时空关系,而且端到端模型的中间表示难以验证。
2. 方案提出
为了解决上述问题,作者提出了一种新方法,它结合了传统的符号表示和学习到的场景标记。作者首先将场景分解为地面、检测到的智能体和未识别物体,然后利用大规模预训练的2D图像模型和3D点云模型来编码这些元素,提取出包含语义、几何和环境信息的标记。这些多模态信息被压缩成数百个标记,与智能体状态、道路图和交通信号灯信息一起输入到类似Wayformer的网络中。
作者通过在扩展后的Waymo Open Motion数据集(包含相机数据)上进行实验,评估了这种方法。模型在soft mAP和minADE上分别提升了6.6%和10.3%。即使在感知输出不准确和道路图信息不完整的情况下,我们的模型仍能保持出色的稳定性和准确性。我们发现,使用最新的图像模型取得了最佳结果,而其他预训练图像模型也显示了显著的性能提升。
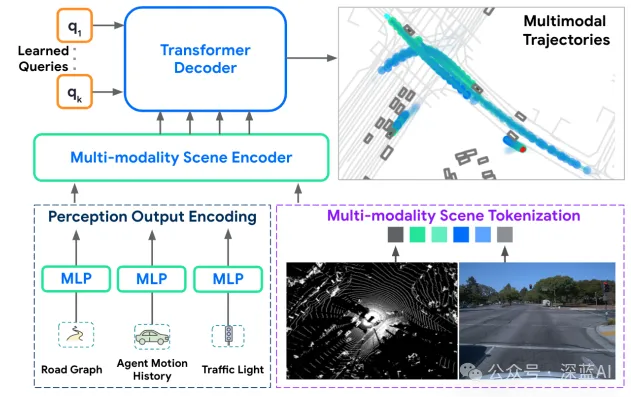
▲图1|本文所提出的运动预测范式©️【深蓝AI】编译
3. 方法详析
我们创新性地提出了MoST,即多模态场景标记化技术,该技术旨在高效地融合多模态传感器数据以提升运动预测的性能。我们通过将连续帧的场景分解为一系列具有丰富语义和几何信息的场景元素,利用强大的预训练图像模型和3D点云处理网络对每个元素进行编码。
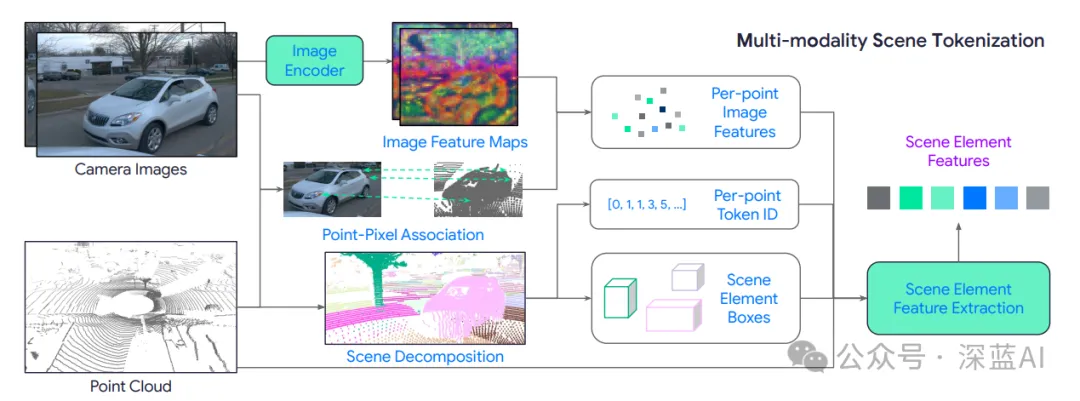
▲图2|多模态场景token化流程图©️【深蓝AI】编译
■3.1 图像编码与点像素关联
首先从每个摄像头提取图像特征图,然后利用传感器校准信息将这些特征与3D激光雷达点对应。每个时间步骤有K个摄像头捕获的图像,以及一个包含多个点的3D激光雷达点云。通过预训练的2D图像编码器,得到每个图像的特征图。
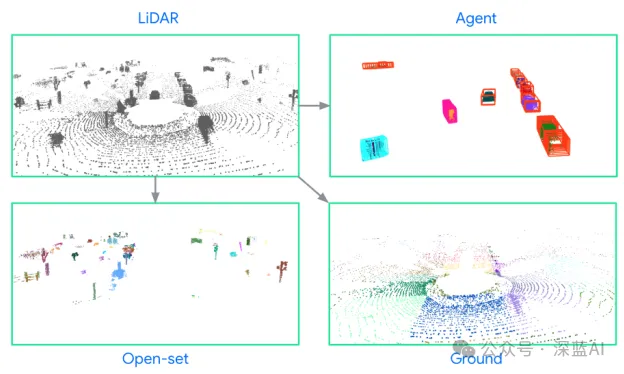
▲图3|场景分解可视化©️【深蓝AI】编译
■3.2 场景分解
将场景分解为地面、智能体和开放集合物体三种元素。地面元素通过分割模型或算法确定,智能体元素对应于检测到的智能体,开放集合物体包含未分类的其他物体。我们对每种元素进行计数,并将它们分组:
● 地面元素:划分为10米x10米的不相交区域。
● 智能体元素:基于已知的感知管道。
● 开放集合物体元素:通过连通分量分析分组。
每个激光雷达点分配一个唯一的token id,属于同一元素的点共享id。通过点像素关联,我们可以在图像特征图上定位这些元素。
作者用图像、粗几何和细几何特征组合编码场景元素。场景元素框B用于表示粗略几何。智能体元素的粗几何信息源于感知系统,包括位置、尺寸和方向;开放集合物体的边界框是点集的最小包围盒,用中心、尺寸和方向描述;地面元素用固定大小的格子表示,位置是格子中心。这些框与图像特征和细粒度特征一起编码。
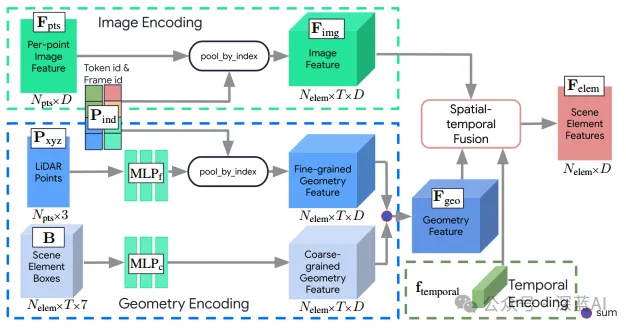
▲图4|场景元素特征提取©️【深蓝AI】编译
■3.3 场景元素特征提取
我们使用神经网络提取场景元素特征。首先,多帧信息被高效压缩,然后输入到特征提取模块,为每个场景元素生成单一特征向量。特征提取模块与Transformer模型相连,形成端到端训练。
◆高效的多帧数据表示: 通过采用跟踪、聚合和下采样策略来减少数据量。开放集合元素通过卡尔曼滤波器跨帧关联,地面元素合并后分块,激光雷达点进行下采样。
◆网络架构: 网络接收跨T帧的图像嵌入、边界框和激光雷达点信息。通过空间-时间融合模块,网络将这些信息整合为每个场景元素的特征向量。这个向量可以输入到运动预测模型的场景编码模块中。
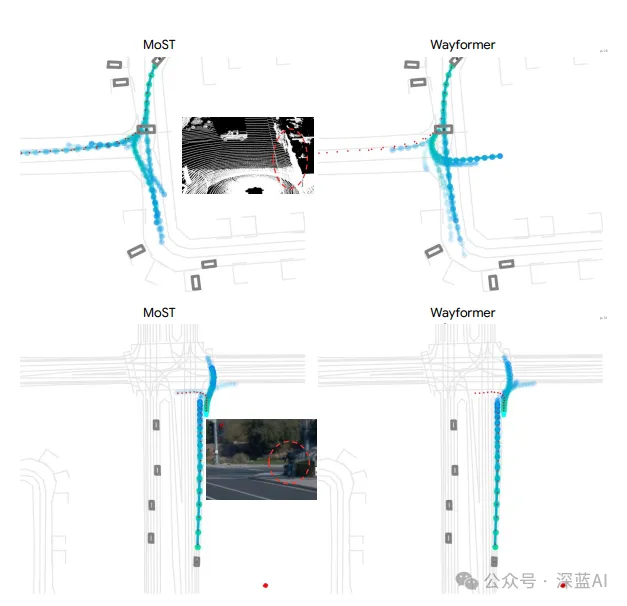
▲图5|定性结果对比©️【深蓝AI】编译
4. 实验结果
与现有的多模态方法相比,MoST在预测准确性和效率上都有显著提升。具体来说,MoST在多个评价指标(如平均精度、平均距离误差等)上超越了基线模型,证明了其在处理复杂多模态场景时的有效性。此外,MoST的内存效率和计算速度也得到了验证,表明它在实际应用中是可行的。

▲表1|WOMD相机编码的详细信息©️【深蓝AI】编译
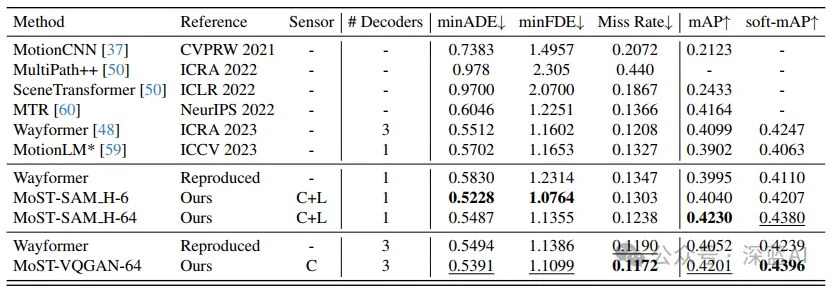
▲表2|在WOMD验证集上的性能比较。列出了不同方法的最小平均绝对误差(minADE)、最小均方误差(minFDE)、漏检率、mAP和soft-mAP等指标,展示了MoST方法相对于其他方法的性能提升©️【深蓝AI】编译
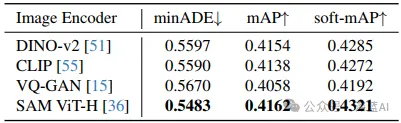
▲表3|不同图像特征的消融研究。比较了使用不同预训练图像编码器(如DINO-v2、CLIP、VQ-GAN和SAM ViT-H)对运动预测性能的影响©️【深蓝AI】编译
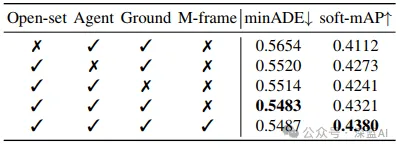
▲表4|场景元素影响的消融研究。展示了不同场景元素(开放集代理、地面和多帧)对模型性能的贡献©️【深蓝AI】编译

▲表5|不同输入模态的消融研究。比较了仅使用LiDAR、仅使用相机图像特征和两者结合的效果©️【深蓝AI】编译
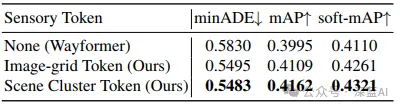
▲表6|场景token化策略的比较。比较了使用图像网格token和场景聚类token与不使用传感器数据的Wayformer基线的性能©️【深蓝AI】编译

▲表7|在困难场景中的评估。展示了MoST方法在挖掘的困难场景中相对于Wayformer基线的性能©️【深蓝AI】编译
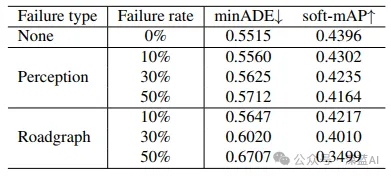
▲表8|模拟感知和道路图失败的评估。展示了在不同比例的感知和道路图失败情况下,MoST方法的性能稳定性©️【深蓝AI】编译
5. 结论
本文提出了一种新的多模态场景分块化轨迹预测方法,有效地整合了图像和3D点云数据。通过跟踪、聚合和下采样策略,MoST能够减少数据表示的复杂性,同时保持高预测精度。实验结果证明了MoST在运动预测任务上的优越性,为多模态传感器融合提供了新的思路。未来的研究方向包括进一步优化数据表示和网络架构,以适应更复杂的环境和更高的实时性要求。
编译:Deep蓝同学
审核:Los
移步公众号【深蓝AI】,第一时间获取自动驾驶、人工智能与机器人行业最新最前沿论文和科技动态。
这篇关于Waymo视角革新!MoST:编码视觉世界,刷新轨迹预测SOTA!的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!