本文主要是介绍基于昇思的大地电磁智能反演模型达到业界SOTA,助力地球物理勘探加速智能化,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
近日,华为AI4S Lab与清华大学李懋坤教授团队、华为先进计算与存储实验室合作,基于昇腾AI处理器与昇思MindSpore AI框架打造了大地电磁智能反演模型。该模型通过变分自编码器(VAE)灵活嵌入了多物理先验知识,达到了业界SOTA。该成果已被国际顶级地球物理期刊《Geophysics》收录,相关代码已在昇思MindSpore Elec电磁仿真套件代码仓中开源,同时,该成果也在昇思人工智能框架峰会2024上发布亮相。
大地电磁反演(Magnetotelluric, MT)是一种地球物理勘探技术。它利用地球表面上的电磁场与地下岩石、矿床等物质的电导率、磁导率等物理属性之间的关系,推断地下物质的电磁参数分布从而达到探测地下物质的目的。该技术被广泛应用于矿产勘探、油气勘探、地质灾害预测等领域。大地电磁反演相比地震波反演具有探测深度大、测量复杂度低、操作较为简便等优势,但传统的大地电磁反演方法(如像素反演方法等)仍面临数据分辨率低、病态性和多解性等问题。基于昇思的大地电磁智能反演模型通过融入多物理先验知识,有效地解决了上述问题。
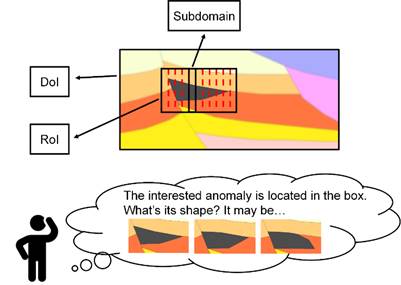
图1大地电磁反演示意图
大地电磁智能反演模型大体分为两步:
· 根据先验知识随机生成电阻率分布图,并进行VAE的自编码预训练
获得解码器构建的图像和隐变量的映射关系m=Ɗ(v)。特别注意的是,我们首次提出采用1D子域编码方案,该方案可有效降低数据集的复杂性和多样性。最终不仅可以减少训练成本,还可以灵活地嵌入具有各种不确定性的先验知识。
|
|
|
|

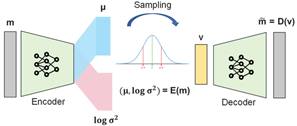
图2 VAE预训练示意图
· 预训练完成后,利用观测数据对隐变量v进行高斯牛顿迭代反演。迭代反演中为了提升反演的稳定性,我们分别引入了关于当前步隐变量梯度的正则项以及前一步隐变量相关的正则项。
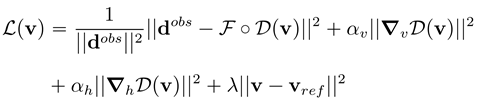
其中,dobs是测量数据,而ℱ为大地电磁正演建模算子,第2/3/4项为不同的正则项。通过上述步骤,我们有效的提升了大地电磁反演的分辨率,克服了病态性和多解性问题。
基于昇思MindSpore框架的分布式并行能力,我们实现了高效的变分自编码器网络的预训练和推理。借助MindSpore的自动微分能力,高斯牛顿迭代反演中灵活地嵌入了含梯度的正则项,提升了反演的稳定性。基于昇思MindSpore的大地电磁反演模型,精度和性能上都有显著提升。
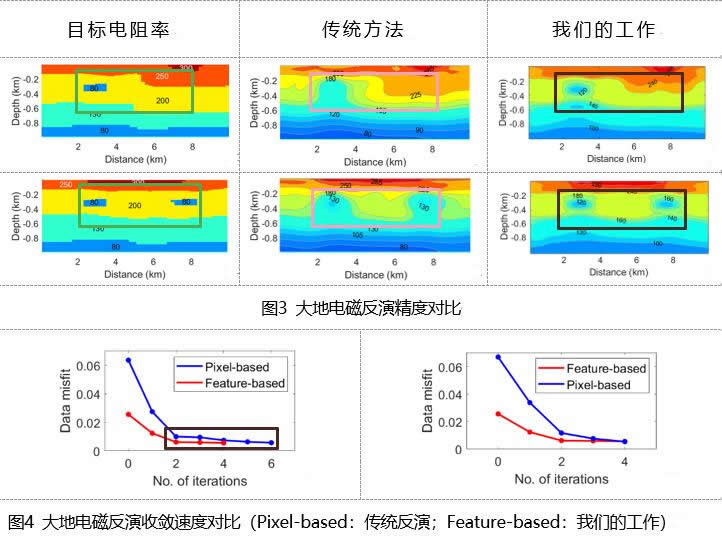
如下是大地电磁智能反演示例:反演区域水平长度为10km,深度为1km。下图3中目标电阻率分布(第一列)与传统大地电磁反演(第二列)、大地电磁智能反演(第三列),可以看出大地电磁智能反演相比传统反演精度显著提升(前者残差为0.0056和0.0054;后者为0.023和0.024);下图4中,大地电磁智能反演性能也优于传统反演方法(前者收敛步数为4和4;后者为6和4)。
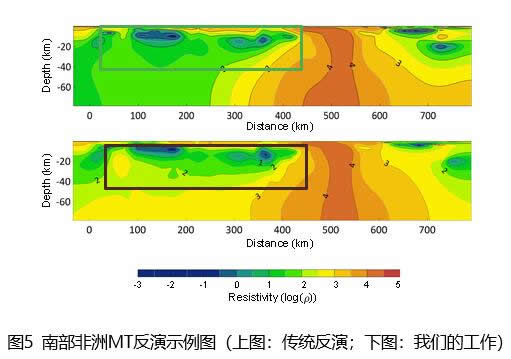
此外,大地电磁智能反演模型还在南部非洲开源数据集(SAMTEX)上做了验证。该反演区域位于南部非洲西海岸附近,长度约为750km,深度选定为80km。该测区显著特征为在水平方向100km至400km之间,深度20km以浅的区域存在的高导结构。由于低频电磁波在导体结构中的衰减,MT方法对高导结构下部区域的敏感度很低, 因此无先验知识约束的传统MT反演难以准确重建高导地层的下边界位置。大地电磁智能反演对高导地层的下边界重建较为清晰准确,较好地将地层厚度的先验知识融入了反演。
昇思MindSpore为用户和开发者提供了一个高效易用的AI4S加速库,大地电磁智能反演模型充分利用该加速库,并取得了SOTA的结果。未来,AI4S加速库将不断拓展该模型,推动应用落地到更多领域。同时,希望有更多的企业、科研院所能够共同参与共建、共享,依托昇思MindSpore共同打造更多智能电磁的创新应用。
了解更多可查看论文:
https://library.seg.org/doi/10.1190/geo2022-0774.1
相关工作:
· MindSpore Science开源路径
https://gitee.com/mindspore/mindscience
· 昇思大地电磁智能反演模型开源路径
https://gitee.com/mindspore/mindscience/tree/master/MindElec/examples/hybrid_driven/feature_based_MT_inversion
这篇关于基于昇思的大地电磁智能反演模型达到业界SOTA,助力地球物理勘探加速智能化的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








