本文主要是介绍性能再升级!UNet+注意力机制,新SOTA分割准确率高达99%,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
UNet结合注意力机制能够有效提升图像分割任务的性能。
具体来说,通过将注意力模块集成到UNet的架构中,动态地重新分配网络的焦点,让其更集中在图像中对于分割任务关键的部分。这样UNet可以更有效地利用其跳跃连接特性,以精细的局部化信息来提升分割精度。
这种策略可以帮助UNet更精确地界定目标边界,提升分割精度和效率。同时引导网络关注更有信息量的局部区域,减少模型对计算资源的需求。
以CAS-UNet算法为例: CAS-UNet是一种基于注意机制的视网膜血管分割算法,它通过引入跨融合通道注意机制、加性注意门模块和SoftPool池化模块,改进了传统的U-Net算法,提高了模型的分割能力和对细节图像区域的分割效果。
在CHASEDB1和DRIVE数据集上的实验结果表明,CAS-UNet分别达到了96.68%和95.86%的准确率,以及83.21%和83.75%的灵敏度,优于现有的基于U-Net的经典算法。

本文挑选了12个UNet结合注意力机制最新成果,可借鉴的方法和创新点做了简单提炼,原文以及相应代码都整理了,方便同学们学习和复现。
论文和开源代码需要的同学看文末
High-Resolution Model for Segmenting and Predicting Brain Tumor Based on Deep UNet with Multi Attention Mechanism
方法:论文提出了一种利用增强注意机制的UNet框架分割脑肿瘤的新技术。通过在记录全面的上下文信息的同时,通过选择性地强调重要方面的注意过程,该策略克服了脑肿瘤分割的挑战。在总体准确率方面表现出色,达到了99%的准确率。

创新点:
-
建立了一种基于UNet和多重注意机制的深度学习模型,用于精确分割和预测脑肿瘤。该模型通过在UNet架构中整合注意机制来强化特征提取和上下文理解,从而克服了传统分割技术的局限性。
-
通过引入空间注意和通道注意机制,提高了模型对肿瘤和非肿瘤区域的区分能力,并加强了对多尺度层次的上下文理解。
-
利用离散余弦变换(DCT)从医学图像中提取特征,降低了计算复杂度和内存需求。这有助于减少UNet模型的输入数组维度。
DA-TransUNet: Integrating Spatial and Channel Dual Attention with Transformer U-Net for Medical Image Segmentation
方法:论文提出一种新的深度医学图像分割框架DA-TransUNet,旨在将Transformer和双注意力块(DA-Block)与传统的U-shaped架构相结合,以改善医学图像分割的性能。通过在嵌入层和每个跳跃连接层中引入DA-Block,提高特征提取能力和编码器-解码器结构的效率,从而改善医学图像分割的性能。

创新点:
-
DA-TransUNet:将双重注意机制集成到Transformer U-net框架中,将位置和通道信息处理与编码器-解码器结构相结合,提高了医学图像分割任务的性能。
-
双重注意块(DA-Block):在编码器的Transformer层之前和跳跃连接中引入了DA-Block,增强了特征提取能力,改善了图像分割性能。

SCTV-UNet: a COVID-19 CT segmentation network based on attention mechanism
方法:论文提出了一种新的COVID-19分割网络SCTV-UNet,结合了编码器上的注意力机制。同时,还提出了一种新的复合损失函数DTVLoss,可以解决传统U型网络预测图像边界模糊和病变区域与背景之间对比度弱的问题。

创新点:
-
提出了一种新的COVID-19分割网络SCTV-UNet,结合了编码器上的注意机制。通过引入SC注意力到编码器中,可以捕获更多的语义信息,突出病变区域的特征,并抑制其他区域。因此,SCTV-UNet比TV-UNet有更好的分割效果和分割准确性。
-
提出了一种新的复合损失函数DTVLoss。它可以解决传统U型网络预测图像边界模糊和病变区域与背景之间对比度弱的问题。通过将DTVLoss替换TVLoss,可以解决TV-UNet预测图像中边界模糊和病变区域与背景之间对比度弱的问题。

Road Extraction From Satellite Images Using Attention-Assisted UNet
方法:作者采用了UNet模型,并在解码器部分辅助使用了注意力机制,同时使用了经过补丁、旋转和增强的数据集进行训练。预处理步骤包括图像和掩模的补丁化、旋转、排除仅包含背景的图像以及排除道路面积很小的图像。
为了解决数据集固有的偏差问题,预处理中采用了补丁化和背景排除技术,模型中采用了注意力机制。通过这些技术的组合,提出的模型在遥感图像分割方面取得了98.33%的准确率。

创新点:
-
使用UNet和注意力机制在模型中,通过数据准备、背景排除和旋转等预处理步骤,克服了数据集偏差问题并实现了更好的性能。
-
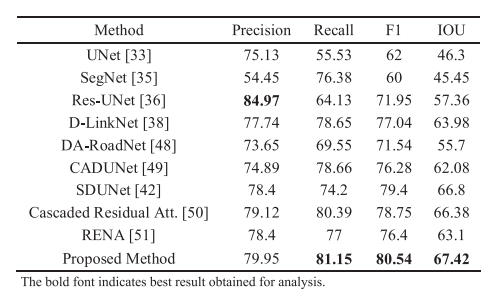
在结果分析步骤中,重点关注精确度和召回率,以更好地评估性能并找出应考虑的缺点。
关注下方《学姐带你玩AI》🚀🚀🚀
回复“UNet结合”获取全部论文+代码
码字不易,欢迎大家点赞评论收藏
这篇关于性能再升级!UNet+注意力机制,新SOTA分割准确率高达99%的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



