准确率专题

uni-app 扫码优化:谈谈我是如何提升安卓 App 扫码准确率的
一. 前言 之前的一个项目遭到用户吐槽:“你们这个 App 扫码的正确率太低了,尤其是安卓的设备。经常性的扫码扫不出来,就算是扫出来了,也是错误的结果!” 由于之前是扫描二维码的需求,所以没有对扫描条形码做严格的测试,客户提示说是条形码扫描效率低下。随即,我用自己的手机测试了一下,在安卓手机上确实有这样的问题,扫码准确率确实是低,尤其是条形码,扫码效率慢且不准确。扫描二维码的的效率还算可以

Hinton等人最新研究:大幅提升模型准确率,标签平滑技术 2019-7-8
导读:损失函数对神经网络的训练有显著影响,也有很多学者人一直在探讨并寻找可以和损失函数一样使模型效果更好的函数。后来,Szegedy 等学者提出了标签平滑方法,该方法通过计算数据集中 hard target 的加权平均以及平均分布来计算交叉熵,有效提升了模型的准确率。近日,Hinton 团队等人在新研究论文《When Does Label Smoothing Help?》中,就尝试对标签平滑技术对

深度学习基础案例4--构建CNN卷积神经网络实现对猴痘病的识别(测试集准确率86.5%)
🍨 本文为🔗365天深度学习训练营 中的学习记录博客🍖 原作者:K同学啊 前言 下一周会很忙,更新可能不及时,请大家见谅这个项目我感觉是一个很好的入门案例,但是自己测试的时候测试集准确率只比较稳定的达到了86.5%附近,说明对神经网络结构的添加还不是很熟,后期还需要多看论文积累😢😢😢😢😢😢😢😢😢图片看着有点渗人😨😨😨😨

准确率,召回率,mAP,ROC,AUC,特异性,敏感性,假阴性,假阳性
P/R和ROC是两个不同的评价指标和计算方式,一般情况下,检索用准确率、召回率、F1、AP和mAP,分类、识别等用ROC和AUC(特异性和敏感性是ROC当中的一个部分)。 准确率、召回率、F1、AP和mAP这几个指标需要依次看,不然直接看AP和mAP看不明白。而ROC和AUC可以直接看不需要看前面的指标。 PR曲线和ROC曲线上点都是对预测的数据进行划分,首先都是按照置信度排序,而PR

vllm 部署GLM4模型进行 Zero-Shot 文本分类实验,让大模型给出分类原因,准确率可提高6%
文章目录 简介数据集实验设置数据集转换模型推理评估 简介 本文记录了使用 vllm 部署 GLM4-9B-Chat 模型进行 Zero-Shot 文本分类的实验过程与结果。通过对 AG_News 数据集的测试,研究发现大模型在直接进行分类时的准确率为 77%。然而,让模型给出分类原因描述(reason)后,准确率显著提升至 83%,提升幅度达 6%。这一结果验证了引入 reas

准确率、精确率、召回率、F1(F-Measure)都是什么?
机器学习ML、自然语言处理NLP、信息检索IR等领域,评估(Evaluation)是一个必要的工作,而其评论价值指标往往有如下几点: 准确率 Accuracy; 精准率 Precision; 召回率 Recal; F1-Measure; TP: True Positive 把正的判断为正的数目True Positive,判断正确,且判为了正,即正的预测为正的; FN:False N

如何利用Artemis和随机森林提高乳腺癌预测准确率
一、引言 乳腺癌是全球范围内最常见的癌症之一,也是女性癌症死亡的主要原因。根据世界卫生组织的数据,每年都有数百万女性被诊断为乳腺癌,这一数字在不断增长。乳腺癌的早期检测对于提高治愈率和降低死亡率至关重要。早期发现可以显著提高患者的生存率,并减少治疗的复杂性和费用。乳腺癌的常见早期检测方法包括乳腺X线摄影(乳腺钼靶)、超声检查和磁共振成像(MRI)。然而,这些方法的准确性受到多种因素的影响,包括影

yolov5和yolov7车牌识别检测(可检测黄牌、绿牌、双层车牌等各种车牌,准确率高,提供界面)
实现一个车牌识别系统,使用YOLOv5和YOLOv7这两种不同的模型来进行车牌的检测。下面我将提供一个完整的项目概述,包括模型训练脚本、车牌识别代码以及两个GUI界面,分别用于处理静态图片和实时视频流 1. 模型训练 YOLOv5 和 YOLOv7 的训练脚本。使用车牌数据集进行训练。 2. 车牌识别 Python 代码实现车牌的检测与识别。支持多种车牌类型,例如黄色、绿色、双层车牌等

混淆矩阵-召回率、精确率、准确率
混淆矩阵 1 混淆矩阵2 混淆矩阵指标2.1 准确率2.2 精确率2.3 召回率2.4 特异度2.4 假正率2.5 假负率2.6 F1 分数 3 总结 1 混淆矩阵 混淆矩阵是一种用于评估分类模型性能的重要工具。它通过矩阵形式清晰地展示了模型对样本进行分类的结果,帮助我们理解模型在不同类别上的表现。 ————预测为正类预测为负类实际为正类True Positive (TP)Fa
![[AI资讯·0612] AI测试高考物理题,最高准确率100%,OpenAI与苹果合作,将ChatGPT融入系统中,大模型在物理领域应用潜力显现](https://img-blog.csdnimg.cn/img_convert/3e1a115eb5bdf936d198273db44dc9bf.png)
[AI资讯·0612] AI测试高考物理题,最高准确率100%,OpenAI与苹果合作,将ChatGPT融入系统中,大模型在物理领域应用潜力显现
AI资讯 国产AI大战高考物理,第1题全对,第2题开始放飞终于放大招了,2024WWDC,苹果开启AI反击战苹果一夜重塑iPhone!GPT-4o加持Siri,AI深入所有APPOpenAI确认苹果集成ChatGPT 还任命了两位新高管GPT-4搞不定的图推理,港科大7B模型搞定拿下SOTA!最强中文Embedding模型对标OpenAI,技术路线公开具身智能赋能机器人,「AI+人形机器人」论坛
基于R语言的糖尿病检测模型准确率97%
使用R语言构建糖尿病检测模型的示例。我们将使用常见的机器学习算法(如逻辑回归)来构建模型,并使用Pima Indians Diabetes数据集进行训练和评估。 1. 安装和加载必要的包 首先,我们需要安装并加载必要的R包。我们将使用caret包来进行数据预处理、模型训练和评估。 # 安装必要的包(如果尚未安装)install.packages("caret")install.packa

AGI系列(1):掌握AI大模型提示词优化术,提问准确率飙升秘籍
当我们向AI大模型提问时,通常人们的做法是有什么问题,就直接去问,得到大模型的回复结果,时好时坏,完全没有可控性。 那么有没有一种方式或是一套方法,可以让我们向大模型提问时,得到的结果更准确,实际上是是有的,我们本文就来探讨下。 例子引入 我们来举个具体的例子: 场景: 假设你是一名社交媒体经理,你需要帮助起草一篇 Facebook 帖子来宣传你公司的新产品。 那么通常的做法,

我用LLaMA-Factory微调大模型来实现商品评论情感分析,准确率高达91.70%
大家好,我是程序锅。 最近在modelscope上闲逛的时候,在数据集板块发现有一个商品评论情感预测数据集。这个数据集源自一个比赛,它的目的是为了预测电商平台顾客的评论是好评还是差评。 数据示例如下所示(其中0代表差评,1代表好评): 这个比赛是2021年7月开始举办的。那个时候还没有ChatGPT,如果需要做商品评论情感预测,是需要分词、预处理、选择模型等等一系列机器学习方法。而我最近
模型准确率accuracy
以二分类问题为例: 假如:共有365个水果,只有两种类别,橙子和橘子. 准确率=分类正确数/365x100% 不足:假如365个水果当中有364个橙子,1个橘子。现有分类器,无论来什么水果都判定为橙子。准确率可达99.7%,但是显而易见这个模型根本没有判别能力。再换一组数据,准确率将直线下降。 上面这种现象称为label不平衡 以准确率判定模型是否优秀不够科学,所以引入ROC曲线。
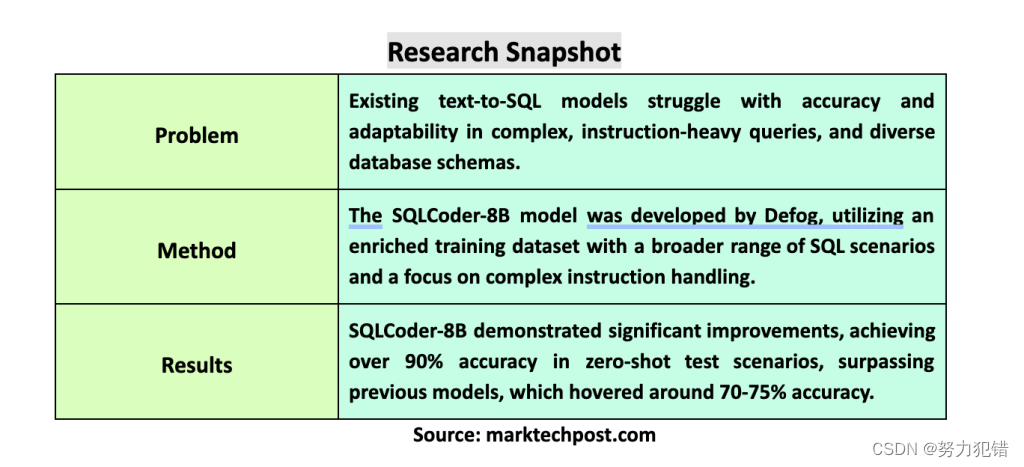
Defog发布Llama-3-SQLCoder-8B,文本转SQL模型,性能比肩GPT-4,准确率超90%,消费级硬件可运行
前言 在计算语言学领域,将自然语言转化为可执行的SQL查询是一个重要的研究方向。这对于让那些没有编程或SQL语法知识的用户也能轻松访问数据库信息至关重要。Defog团队近日发布了基于Llama-3的SQLCoder-8B模型,它在文本转SQL模型领域取得了显著突破,在准确率和易用性方面都达到了新的高度。 Huggingface模型下载:https://huggingface.co/defog
在prompt使用占位符实现提高信息替换成功率和替换位置准确率【prompt】【LLM】
文章目录 问题占位符解决 问题 造数据集的时候遇到的,llm不能很好的帮你替换,替换的内容不对,或者是替换的位置不对,比如这里就是替换位置不对,只盯着doc2替换,无视你的替换位置的变化。 待处理文本 {"question": "填空题,吊车检验合格证件及驾驶操作合格证件报审手续完备,合格证件在________ 内。\n{%doc1%}\n{%doc2%}\n{%doc

YOLOv3的NMS参数调整对模型的准确率和召回率分别有什么影响?
YOLOv3中的非极大值抑制(Non-Maximum Suppression, NMS)是一种关键的后处理步骤,用于从模型的预测中去除重叠的边界框,从而提高检测的准确性。NMS参数的调整直接影响到模型的准确率(Precision)和召回率(Recall),具体如下: 1. NMS阈值(`nms_thresh`): - 提高NMS阈值:会减少被抑制的边界框数量,从而保留更多的边界框。这可能会

用OpenCV先去除边框线,以提升OCR准确率
在OpenCV的魔力下,我们如魔法师般巧妙地抹去表格的边框线,让文字如诗如画地跃然纸上。 首先,我们挥动魔杖,将五彩斑斓的图像转化为单一的灰度世界,如同将一幅绚丽的油画化为水墨画,通过`cv2.cvtColor()`函数的施展,我们实现了这一华丽的转变。 接着,我们施展边缘检测的法术,运用Canny边缘检测算法,如同在黑夜中点亮的繁星,清晰地勾勒出表格的边界,让我们一览无余地看到其轮廓。然
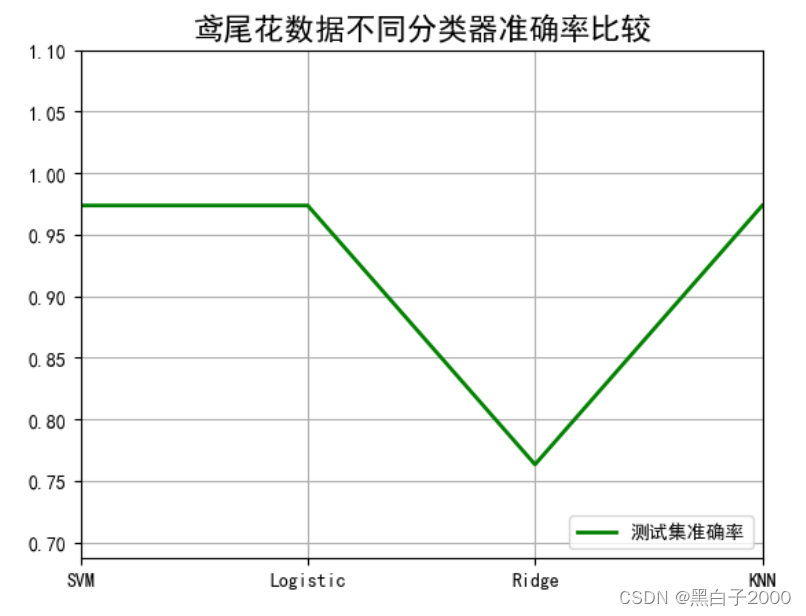
机器学习鸢尾花各种模型准确率对比
流程 获取数据集导入需要的包读取数据划分训练集和测试集调用各种模型比较准确率 获取数据集 链接:https://pan.baidu.com/s/1RzZyXsaiJB3e611itF466Q?pwd=j484 提取码:j484 --来自百度网盘超级会员V1的分享 导入需要的包 import pandas as pdimport numpy as npimport matplotl
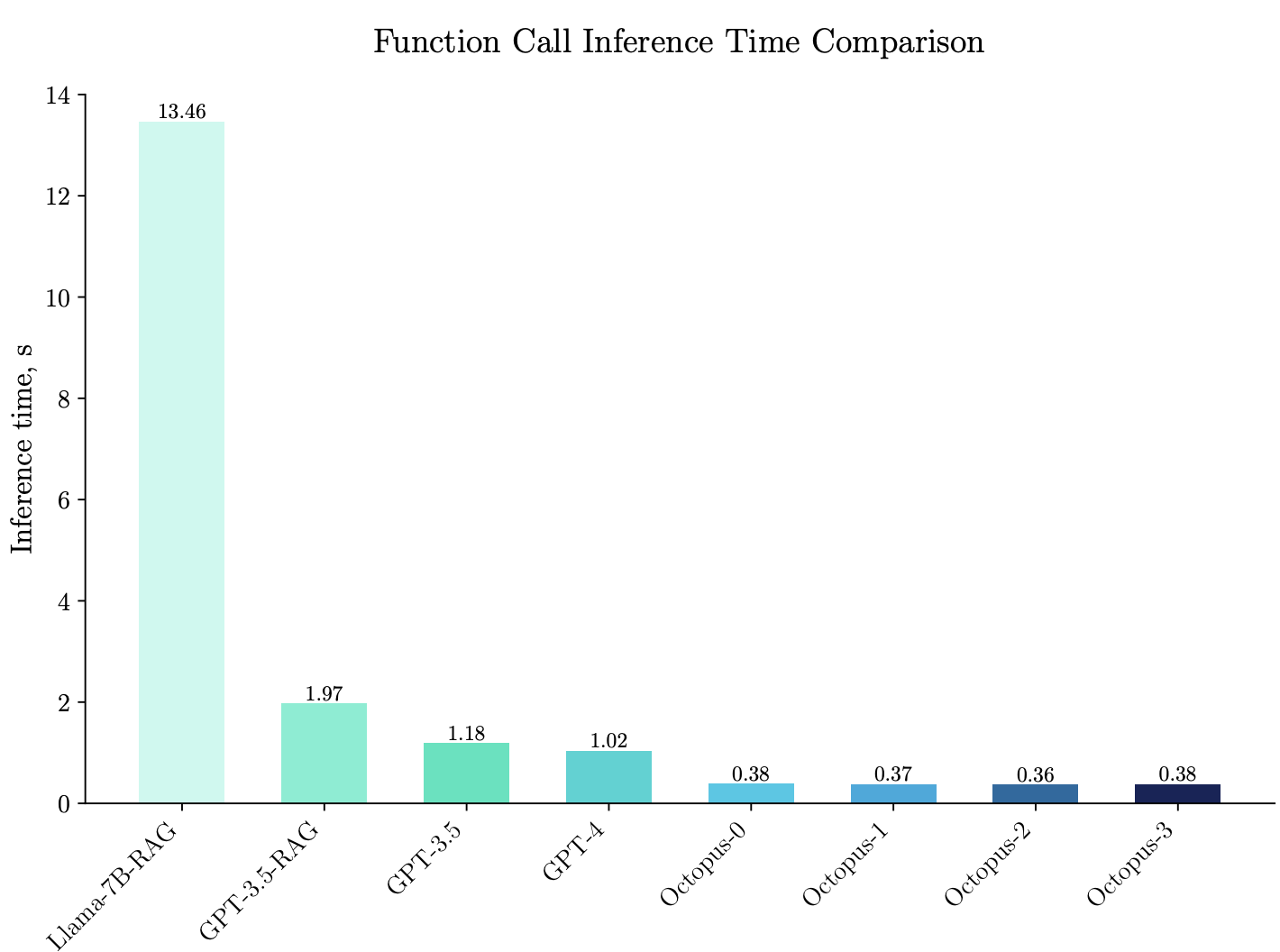
斯坦福发布端侧AI模型Octopus V2:推理比GPT-4快168%,准确率超Llama7B
斯坦福大学科研团队近期发布的Octopus V2端侧AI大模型犹如一颗璀璨的新星冉冉升起,凭借其卓越的性能和高效的推理能力,在业界引起了巨大轰动。 这款拥有20亿参数的端侧强大语言模型一亮相,便在开发者社群内迅速蹿红,首夜下载量即突破两千次大关,展现出前所未有的魅力。 Octopus V2的独特之处在于其能在智能手机、汽车和个人电脑等多种终端设备上流畅运行,尤其在涉及自动化工作流的任务中,它能
理论知识:Top-K 准确率
Top-1 Accuracy: 这是最常见的准确率评估方式,指的是模型预测的最有可能的类别(即概率最高的类别)是否正是真实的类别。换句话说,就是模型的预测结果中排名第一的类别是否正确。 Top-3 Accuracy: 这个评估标准比 Top-1 更宽松一些。它检查真实类别是否在模型预测的前三个最有可能的类别之中。这意味着即使模型的最有信心的预测(Top-1)是错误的,只要真实的类别位于模型给出
基于CNN的棉花不同病害叶识别(Python代码,pytorch框架,代码有详细中文注释,准确率在90%以上)
1.效果视频(训练过程:基于CNN模型的棉花不同病害叶识别(Python代码,pytorch框架)_哔哩哔哩_bilibili(为减小视频时长,epoch为30,准确率在85%左右,epoch为60后,稳定在90%以上), GUI识别过程:棉花也病害识别GUI运行界面_哔哩哔哩_bilibili) CNN模型介绍( CNN模型代码,可以替换为MobileNetV3Small, VGG16,
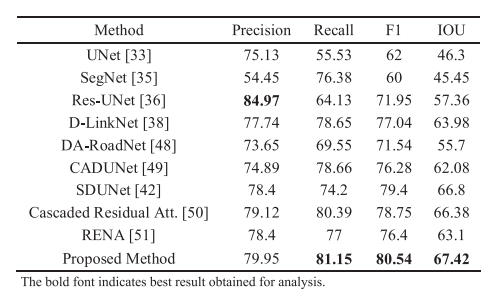
性能再升级!UNet+注意力机制,新SOTA分割准确率高达99%
UNet结合注意力机制能够有效提升图像分割任务的性能。 具体来说,通过将注意力模块集成到UNet的架构中,动态地重新分配网络的焦点,让其更集中在图像中对于分割任务关键的部分。这样UNet可以更有效地利用其跳跃连接特性,以精细的局部化信息来提升分割精度。 这种策略可以帮助UNet更精确地界定目标边界,提升分割精度和效率。同时引导网络关注更有信息量的局部区域,减少模型对计算资源的需求。 以CA
咳两声就能锁定新冠!MIT收集20万咳嗽样本,用AI辨别无症状感染者,准确率100%...
来源:大数据文摘 本文约2700字,建议阅读8分钟 最近发表在《IEEE医学与生物学工程学杂志》上的一篇论文中,麻省理工学院的研究人员表示,他们已经开发出可以识别COVID-19感染者咳嗽声的AI。 10月25日,喀什地区疏附县24日发现1例新冠肺炎无症状感染者后,新疆迅速对其密切接触者、密切接触者的接触者进行核酸检测,截至10月25日14时,检测出137人呈阳性,经专家诊断,均为无症状感染

植入大脑电极,晚期渐冻症患者通过神经信号交流!匹配准确率80%,有效时间仅1/3...
来源:大数据文摘本文约2300字,建议阅读6分钟"这是一个很大的责任" 神经系统疾病肌萎缩侧索硬化症(ALS),也叫渐冻症,这是一种渐进且致命的神经退行性疾病。 一般而言,渐冻症由中枢神经系统内控制骨骼肌的运动神经元退化所致。由于上、下运动神经元退化和死亡,肌肉逐渐衰弱、萎缩。最后,大脑完全丧失控制随意运动的能力,最终造成发音、吞咽,以及呼吸上的障碍。 2014年在海外盛行的“冰桶挑战”

智能助力:大模型自动填写工单准确率达95%
基于大模型优秀的问答、总结和话术生成能力,主流联络中心纷纷接入大模型升级智能知识库、智能工单、智能陪练等应用。 以智能填单为例,借助大模型能够轻松从对话中提取出实体信息、判定对话意图、识别情绪、生成沟通摘要等。通过简单的Prompt,完成工单字段的提取任务更是轻而易举。 然而在初期效果测试中,大模型获取的工单填单结果对比客服的真实填写结果准确率不足30%,且大模型的处理速度也达不到业务