本文主要是介绍Defog发布Llama-3-SQLCoder-8B,文本转SQL模型,性能比肩GPT-4,准确率超90%,消费级硬件可运行,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
前言
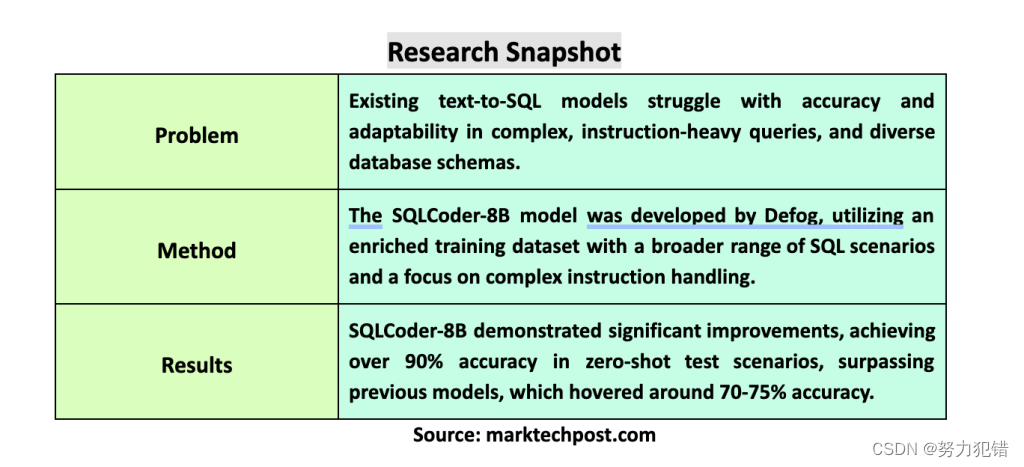
在计算语言学领域,将自然语言转化为可执行的SQL查询是一个重要的研究方向。这对于让那些没有编程或SQL语法知识的用户也能轻松访问数据库信息至关重要。Defog团队近日发布了基于Llama-3的SQLCoder-8B模型,它在文本转SQL模型领域取得了显著突破,在准确率和易用性方面都达到了新的高度。
-
Huggingface模型下载:https://huggingface.co/defog/llama-3-sqlcoder-8b
-
AI快站模型免费加速下载:https://aifasthub.com/models/defog

技术特点
SQLCoder-8B模型拥有以下关键技术特点:
-
基于Llama-3,性能强劲
SQLCoder-8B模型基于强大的Llama-3架构,并经过了精心训练,使其在理解自然语言指令和生成准确的SQL查询方面拥有出色的能力。
-
丰富的训练数据,涵盖各种复杂场景
SQLCoder-8B模型在训练过程中使用了大量包含各种指令和复杂SQL生成任务的数据集,使其能够应对更加复杂的现实应用场景。
-
优化的评估框架
SQLCoder-8B模型采用了一种更加严谨的评估框架,能够识别包含多个正确答案的查询,这在实际应用中至关重要,因为它允许模型根据用户的需求和数据库的设计,灵活地生成不同的SQL查询。
-
轻量级设计,消费级硬件可运行
SQLCoder-8B模型拥有80亿个参数,但其设计十分轻巧,可以在消费级硬件设备上运行。这意味着用户无需高性能的服务器,就可以使用SQLCoder-8B模型进行文本转SQL的转化。
-
开源且可商用
Defog团队已将SQLCoder-8B模型的权重开源,并采用商业友好型的cc-by-sa许可证。这意味着用户可以自由使用该模型进行研究或商业应用。
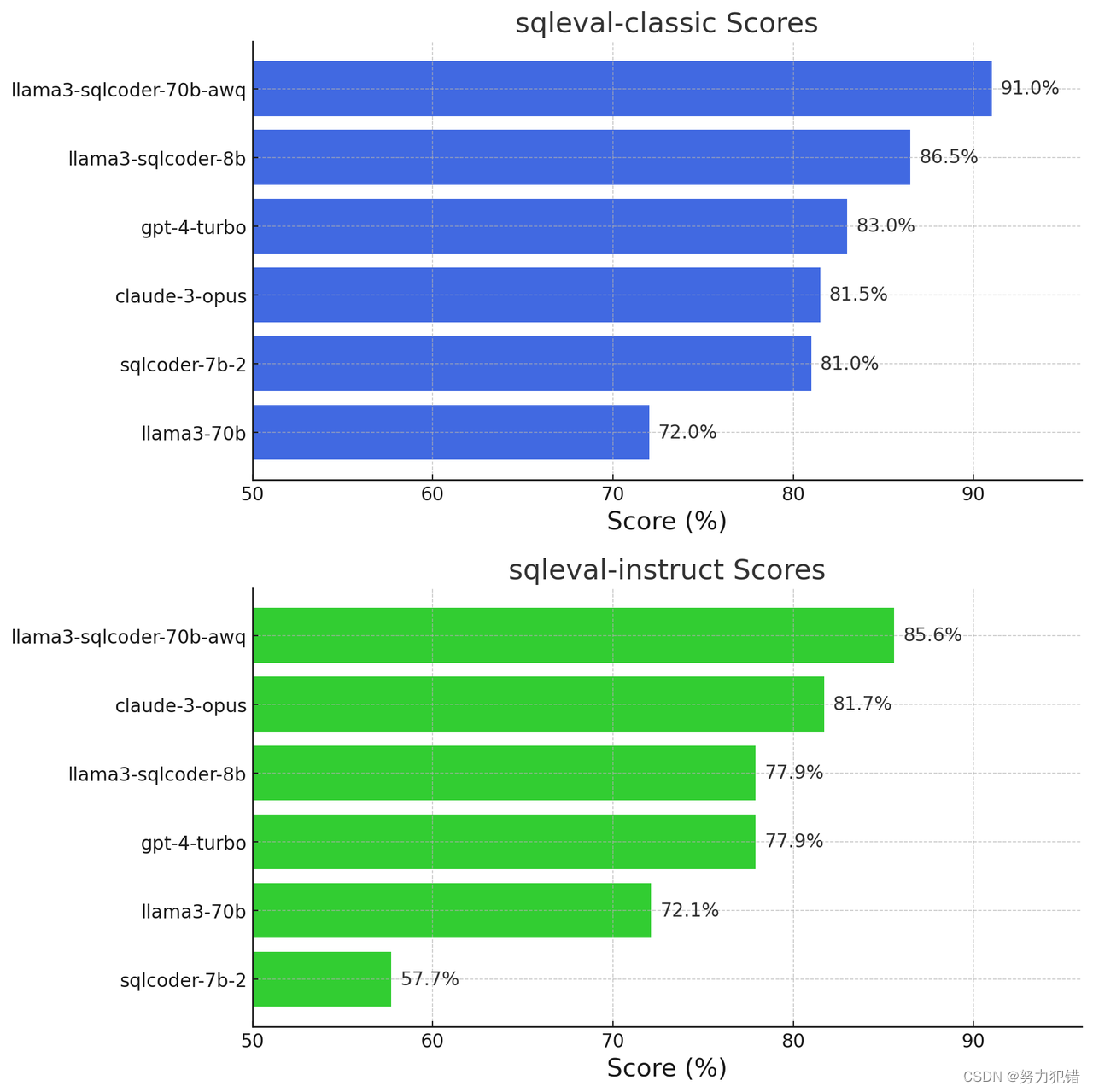
性能表现
SQLCoder-8B模型在基准测试中表现出色,性能与GPT-4和Claude Opus等大型语言模型相媲美:
-
在零样本场景下,SQLCoder-8B模型的准确率超过了90%,远超之前的文本转SQL模型。 这意味着用户可以使用自然语言直接向SQLCoder-8B模型发出指令,它能够直接理解并生成相应的SQL代码。
-
在遵循指令的场景下,SQLCoder-8B模型的性能也接近GPT-4和Claude Opus。 这意味着SQLCoder-8B模型能够根据用户复杂的指令,生成符合预期结果的SQL查询。
应用场景
SQLCoder-8B模型可以广泛应用于各种需要文本转SQL功能的场景:
-
数据分析: 用户可以使用自然语言直接向数据库发出查询请求,获取所需数据。
-
数据自动化: 通过将自然语言转化为SQL查询,用户可以自动化数据处理流程。
-
数据库管理: SQLCoder-8B模型可以帮助数据库管理员更轻松地维护和管理数据库。
-
数据可视化: 用户可以使用自然语言生成SQL查询,并将数据转化为图表或其他可视化形式。
总结
SQLCoder-8B模型的发布是文本转SQL模型领域的一项重大进展,它不仅拥有媲美GPT-4的强大性能,而且开源且可商用,这将为更多用户带来便捷和高效的数据访问体验。随着技术的不断进步,相信SQLCoder-8B模型将进一步推动文本转SQL技术的发展,并在更多场景中发挥重要作用,助力人们更好地利用数据,获取洞察力,并做出更明智的决策。
模型下载
Huggingface模型下载
https://huggingface.co/defog/llama-3-sqlcoder-8b
AI快站模型免费加速下载
https://aifasthub.com/models/defog
这篇关于Defog发布Llama-3-SQLCoder-8B,文本转SQL模型,性能比肩GPT-4,准确率超90%,消费级硬件可运行的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






