文本专题

使用Python实现文本转语音(TTS)并播放音频
《使用Python实现文本转语音(TTS)并播放音频》在开发涉及语音交互或需要语音提示的应用时,文本转语音(TTS)技术是一个非常实用的工具,下面我们来看看如何使用gTTS和playsound库将文本... 目录什么是 gTTS 和 playsound安装依赖库实现步骤 1. 导入库2. 定义文本和语言 3
Python实现常用文本内容提取
《Python实现常用文本内容提取》在日常工作和学习中,我们经常需要从PDF、Word文档中提取文本,本文将介绍如何使用Python编写一个文本内容提取工具,有需要的小伙伴可以参考下... 目录一、引言二、文本内容提取的原理三、文本内容提取的设计四、文本内容提取的实现五、完整代码示例一、引言在日常工作和学

Java实现将Markdown转换为纯文本
《Java实现将Markdown转换为纯文本》这篇文章主要为大家详细介绍了两种在Java中实现Markdown转纯文本的主流方法,文中的示例代码讲解详细,大家可以根据需求选择适合的方案... 目录方法一:使用正则表达式(轻量级方案)方法二:使用 Flexmark-Java 库(专业方案)1. 添加依赖(Ma
Linux使用cut进行文本提取的操作方法
《Linux使用cut进行文本提取的操作方法》Linux中的cut命令是一个命令行实用程序,用于从文件或标准输入中提取文本行的部分,本文给大家介绍了Linux使用cut进行文本提取的操作方法,文中有详... 目录简介基础语法常用选项范围选择示例用法-f:字段选择-d:分隔符-c:字符选择-b:字节选择--c

C#使用DeepSeek API实现自然语言处理,文本分类和情感分析
《C#使用DeepSeekAPI实现自然语言处理,文本分类和情感分析》在C#中使用DeepSeekAPI可以实现多种功能,例如自然语言处理、文本分类、情感分析等,本文主要为大家介绍了具体实现步骤,... 目录准备工作文本生成文本分类问答系统代码生成翻译功能文本摘要文本校对图像描述生成总结在C#中使用Deep

通过C#获取PDF中指定文本或所有文本的字体信息
《通过C#获取PDF中指定文本或所有文本的字体信息》在设计和出版行业中,字体的选择和使用对最终作品的质量有着重要影响,然而,有时我们可能会遇到包含未知字体的PDF文件,这使得我们无法准确地复制或修改文... 目录引言C# 获取PDF中指定文本的字体信息C# 获取PDF文档中用到的所有字体信息引言在设计和出

Java操作xls替换文本或图片的功能实现
《Java操作xls替换文本或图片的功能实现》这篇文章主要给大家介绍了关于Java操作xls替换文本或图片功能实现的相关资料,文中通过示例代码讲解了文件上传、文件处理和Excel文件生成,需要的朋友可... 目录准备xls模板文件:template.xls准备需要替换的图片和数据功能实现包声明与导入类声明与

python解析HTML并提取span标签中的文本
《python解析HTML并提取span标签中的文本》在网页开发和数据抓取过程中,我们经常需要从HTML页面中提取信息,尤其是span元素中的文本,span标签是一个行内元素,通常用于包装一小段文本或... 目录一、安装相关依赖二、html 页面结构三、使用 BeautifulSoup javascript

Level3 — PART 3 — 自然语言处理与文本分析
目录 自然语言处理概要 分词与词性标注 N-Gram 分词 分词及词性标注的难点 法则式分词法 全切分 FMM和BMM Bi-direction MM 优缺点 统计式分词法 N-Gram概率模型 HMM概率模型 词性标注(Part-of-Speech Tagging) HMM 文本挖掘概要 信息检索(Information Retrieval) 全文扫描 关键词

超越IP-Adapter!阿里提出UniPortrait,可通过文本定制生成高保真的单人或多人图像。
阿里提出UniPortrait,能根据用户提供的文本描述,快速生成既忠实于原图又能灵活调整的个性化人像,用户甚至可以通过简单的句子来描述多个不同的人物,而不需要一一指定每个人的位置。这种设计大大简化了用户的操作,提升了个性化生成的效率和效果。 UniPortrait以统一的方式定制单 ID 和多 ID 图像,提供高保真身份保存、广泛的面部可编辑性、自由格式的文本描述,并且无需预先确定的布局。

使用亚马逊Bedrock的Stable Diffusion XL模型实现文本到图像生成:探索AI的无限创意
引言 什么是Amazon Bedrock? Amazon Bedrock是亚马逊云服务(AWS)推出的一项旗舰服务,旨在推动生成式人工智能(AI)在各行业的广泛应用。它的核心功能是提供由顶尖AI公司(如AI21 Labs、Anthropic、Cohere、Meta、Mistral AI、Stability AI以及亚马逊自身)开发的多种基础模型(Foundation Models,简称FMs)。

文本分类场景下微调BERT
How to Fine-Tune BERT for Text Classification 论文《How to Fine-Tune BERT for Text Classification?》是2019年发表的一篇论文。这篇文章做了一些实验来分析了如何在文本分类场景下微调BERT,是后面网上讨论如何微调BERT时经常提到的论文。 结论与思路 先来看一下论文的实验结论: BERT模型上面的

python tkinter 文本类组件
Label组件 Label(win,text='文本',justify='center) win指定Label组件的父容器;text指定标签中的文本;justify指定标签中拥有多行文本时,最后一行文本的对齐方式。 from tkinter import *from PIL import Image,ImageTkroot = Tk()root.title("compound")roo
一个C++程序运行,从点击运行到控制台打印文本,电脑硬件的资源是如何调动的
当点击运行一个 C++ 程序并看到控制台输出文本时,计算机硬件和操作系统之间协同工作,完成了多个步骤。这些步骤涉及 CPU、内存、存储设备、操作系统和输入输出设备的共同作用。下面是一个详细的过程描述: 1. 程序加载 启动:当你点击运行一个可执行文件时,操作系统(通常是 Windows、Linux 或 macOS)的文件系统管理器识别请求,并启动加载程序。读取可执行文件:加载程序将可执行文件从
AS3中的TextField文本事件 处理
textfield支持的html标签不多, a标签侦听事件: textFiled.htmlText = "<a href='event:typetext'>con</a>"; textFiled.addEventListener(TextEvent.LINK,linkhandle); function linkhandle(event:TextEvent):void{

三文带你轻松上手鸿蒙的AI语音03-文本合成声音
三文带你轻松上手鸿蒙的AI语音03-文本合成声音 前言 接上文 三文带你轻松上手鸿蒙的AI语音02-声音文件转文本 HarmonyOS NEXT 提供的AI 文本合并语音功能,可以将一段不超过10000字符的文本合成为语音并进行播报。 场景举例 手机在无网状态下,系统应用无障碍(屏幕朗读)接入文本转语音能力,为视障人士提供播报能力。类似微信读书,可以实现将文章内容通过语音朗读,可以
SpringBoot 集成 SpirePDF 实现文本替换
SpirePDF 10.6.2 很强大,API 也封装的很好,使用的时候及其舒适。但是需要购买许可,不然有很大限制,最大的问题在于会添加水印,这就导致基本上用不了。有钱真好,真是嘴馋。 好在 SpirePDF 也有版本较老的免费版本,有查到一个 5.1.0。接下来附上使用代码 1、在 pom.xml 文件中添加他们的源 <!-- 使用 huawei / aliyun 的 Maven 源,提升
【python 走进NLP】两两求相似度,得到一条文本和其他文本最大的相似度
应用场景: 一个数据框里面文本,两两求相似度,得到一条文本和其他文本最大的相似度。 content source_id0 丰华股份军阀割据发生的故事大概多少w 11 丰华股份军阀割据发生的故事大概多少 22 丰华股份军阀割据发生的故事大概多少 33 丰华股份军阀割据发生的故事大概多少
【自然语言处理 数据清洗】清洗文本中html标签
一段本文中既有文字,又有很多html标签,很乱,需要进行清洗,下面是用python 进行过滤辣鸡html的脚本。 # -*- coding:utf-8 -*-import pandas as pdimport reimport jiebadef filter_tags(htmlstr):"""# Python通过正则表达式去除(过滤)HTML标签:param htmlstr::return:"
【python 走进NLP】文本相似度各种距离计算
计算文本相似度有什么用? 1、反垃圾文本的捞取 “诚聘淘宝兼职”、“诚聘打字员”…这样的小广告满天飞,作为网站或者APP的运营者,不可能手动将所有的广告文本放入屏蔽名单里,挑几个典型广告文本,与它满足一定相似度就进行屏蔽。 2、推荐系统 在微博和各大BBS上,每一篇文章/帖子的下面都有一个推荐阅读,那就是根据一定算法计算出来的相似文章。 3、冗余过滤 我们每天接触过量的信息,信息之间存在大量
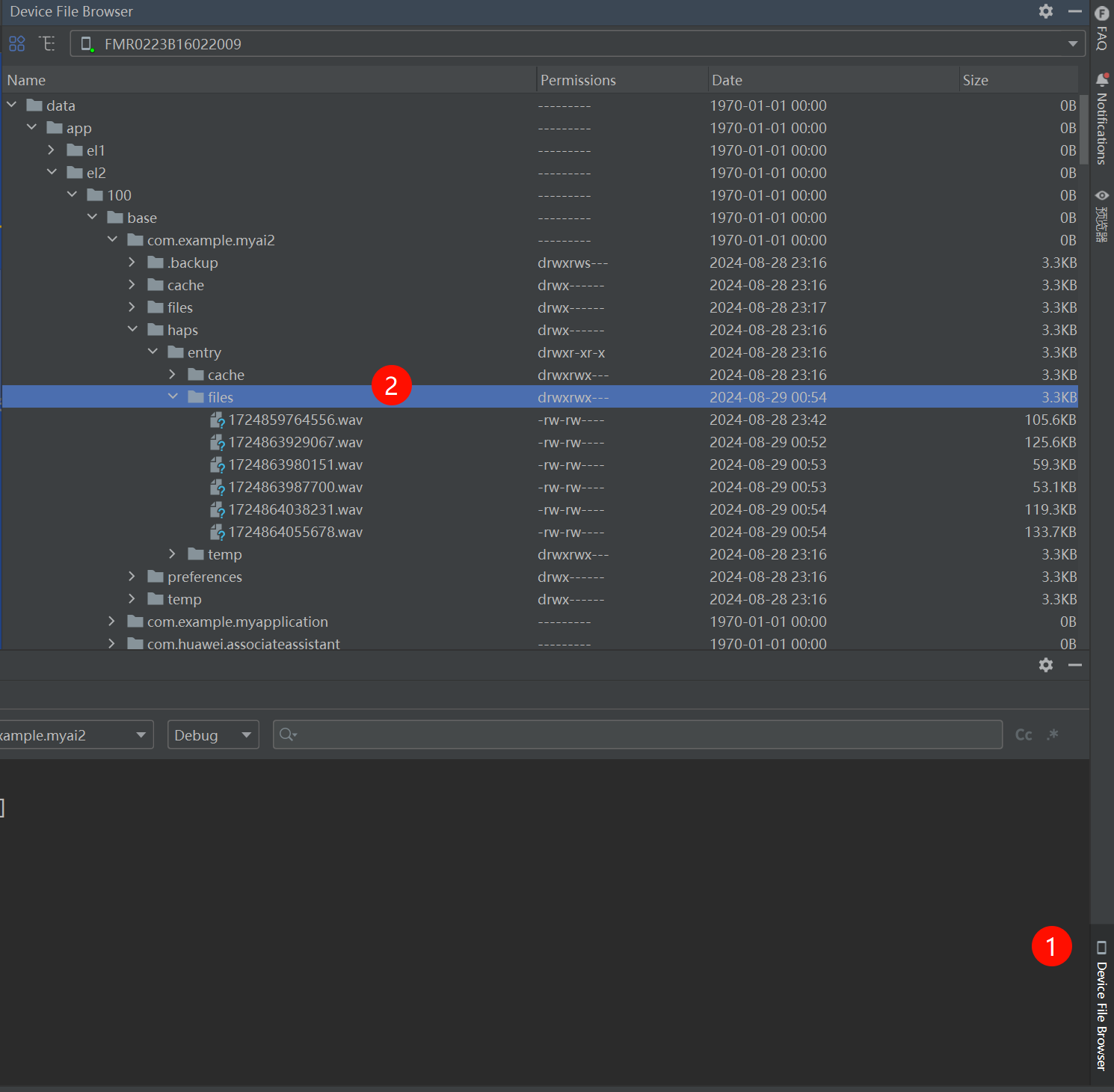
三文带你轻松上手鸿蒙的AI语音02-声音文件转文本
三文带你轻松上手鸿蒙的AI语音02-声音文件转文本 接上一文 前言 本文主要实现 使用鸿蒙的AI语音功能将声音文件识别并转换成文本 实现流程 利用AudioCapturer 录制声音,生成录音文件利用AI语音功能,实现识别 两个录音库介绍 在HarmonyOS NEXT 应用开中,实现录音的两个核心库分别为 AudioCapturerAVRecorder AVRecorder

第23周:使用Word2vec实现文本分类
目录 前言 一、数据预处理 1.1 加载数据 1.2 构建词典 1.3 生成数据批次和迭代器 二、模型构建 2.1 搭建模型 2.2 初始化模型 2.3 定义训练和评估函数 三、训练模型 3.1 拆分数据集并运行模型 3.2 测试指定数据 总结 前言 🍨 本文为[🔗365天深度学习训练营]中的学习记录博客🍖 原作者:[K同学啊] 说在前面 本周任务
NLP文本相似度之LCS
基础 LCS(Longest Common Subsequence)通常指的是最长公共子序列,区别最长公共字串(Longest Common Substring)。我们先从子序列的定义理解: 一个序列S任意删除若干个字符得到新的序列T,则T叫做S的子序列。 子序列和子串的一个很大的不同点是,子序列不要求连接,而子串要求连接。 两个序列X和Y的公共子序列中,长度最长的那个,定义为X和Y

NLP 文本相似度(一)
一份文本,从结构上划分可以是:字、词、句、段、篇。文本比较的粒度是词,一篇文章,可以划分成N个不同的词,选取其中包含重要信息的M个词作为这片文章的特征。M个词构成了M维的向量,两个文本之间的比较就是两个M维向量之间的比较。 余弦相似度 向量之间如何比较?我们可以采用余弦相似度,其描述如下: 一个向量空间中两个向量夹角的余弦值可以作为衡量两个个体之间差异的大小;余弦值越接近1,夹角趋于0,表明