8b专题

LLAMA3.1 8B 本地部署并配合Obsidian建立本地AI知识管理系统
目前,LLAMA3.1模型分为8B、70B、405B三个版本,其中70B和405B对于显存的要求均已超过了一般家用电脑的配置(或者换个说法,用一张4090也是带不起来的),所以运行8B即可。LLAMA3.1 8B的性能约相当于ChatGPT3.5。 经过我的测试4080、2080、intel ultra 9 185H(无独立显卡,其能力约相当于1060)都是可以带得动8B模型的,当然显卡越好,响

最少钱学习并构建大模型ollama-llama3 8B
学习大模型时可能面临一些困难,这些困难可能包括: 计算资源限制:训练大模型通常需要大量的计算资源,包括CPU、GPU等。如果设备资源有限,可能会导致训练时间长、效率低下或无法完成训练。 内存限制:大模型通常需要大量内存来存储模型参数和计算中间结果。内存限制可能会导致内存不足错误或无法加载大模型。 数据集规模:训练大模型通常需要大规模的数据集来获得良好的性能。获取和处理大规模数据集可能需要大

MCT Self-Refine:创新集成蒙特卡洛树搜索 (MCTS)提高复杂数学推理任务的性能,超GPT4,使用 LLaMa-3 8B 进行自我优化
📜 文献卡 题目: Accessing GPT-4 level Mathematical Olympiad Solutions via Monte Carlo Tree Self-refine with LLaMa-3 8B作者: Di Zhang; Xiaoshui Huang; Dongzhan Zhou; Yuqiang Li; Wanli OuyangDOI: 10.48550/a

Llama3-8B-Chinese-Chat 聊天机器人
Llama3-8B-Chinese-Chat 聊天机器人 1. 创建虚拟环境2. 安装 pytorch3. 安装 transformers 和 gradio4. 开发 ui 代码5. 运行 ui 代码6. 访问 web ui 1. 创建虚拟环境 conda create -n llama3-chinese python=3.11 -yconda activate llama3-

使用Unsloth微调Llama3-Chinese-8B-Instruct中文开源大模型
微调Llama3-Chinese-8B-Instruct 微调是指在大规模预训练的基础模型上,使用特定领域或任务数据集进行少量迭代训练,以调整模型参数,提升其在特定任务上的表现。这种方法可以充分利用预训练模型的广泛知识,同时针对特定应用进行优化,达到更精准高效的效果。 Llama-3-Chinese-8B-Instruct Llama-2已经表现的很出色了,但其仅使用了2万亿Toke

Ollama+Open WebUI本地部署Llama3 8b(附踩坑细节)
先展示一下最终结果,如下图所示: 1. 添加环境变量 在下载 ollama 之前,先去配置环境变量,确保模型下载到我们想要的地方 win10 和 win11 输入path或者环境变量: 增加系统环境变量 变量名不可更改,必须是OLLAMA_MODELS,变量值可以自定义, 2. 下载ollama 下载网址:Download Ollama on macOS 下
![[大模型]Llama-3-8B-Instruct FastApi 部署调用](https://img-blog.csdnimg.cn/direct/ecbd9a6c64cc43cd9fa170d0e3fb8920.png#pic_center)
[大模型]Llama-3-8B-Instruct FastApi 部署调用
环境准备 在 Autodl 平台中租赁一个 3090 等 24G 显存的显卡机器,如下图所示镜像选择 PyTorch-->2.1.0-->3.10(ubuntu22.04)-->12.1。 接下来打开刚刚租用服务器的 JupyterLab,并且打开其中的终端开始环境配置、模型下载和运行演示。 pip 换源加速下载并安装依赖包 # 升级pippython -m pip install -
![[大模型]LLaMA3-8B-Instruct Lora 微调](https://img-blog.csdnimg.cn/direct/1620bcdf480942acb22a90f9350e16fb.png#pic_center)
[大模型]LLaMA3-8B-Instruct Lora 微调
本节我们简要介绍如何基于 transformers、peft 等框架,对 LLaMA3-8B-Instruct 模型进行 Lora 微调。Lora 是一种高效微调方法,深入了解其原理可参见博客:知乎|深入浅出 Lora。 这个教程会在同目录下给大家提供一个 nodebook 文件,来让大家更好的学习。 环境准备 在 Autodl 平台中租赁一个 3090 等 24G 显存的显卡机器,如下图所

智能数据分析(1)Lecture 6-8b
Lecture 6: Generative Models 生成模型 vs 判别模型 判别模型(Discriminative Models) 判别模型的主要任务是直接学习输入 x x x 和类别 y y y 之间的关系。它们不关心数据的生成过程,而是直接估计类别的边界。 定义:判别模型直接学习 p ( y ∣ x ) p(y|x) p(y∣x),即在给定输入 x x x 的情况下,属

使用ollama分别在我的window、mac、小米手机上部署体验llama3-8b
1、ollama到底是个什么玩意 一句话来说, Ollama 是一个基于 Go 语言开发的简单易用的本地大模型运行框架。可以将其类比为 docker(有类似docker中的一些常规命令list,pull,push,run 等等),事实上确实也制定了类似 docker 的一种模型应用标准,在后边的内容中,你能更加真切体会到这一点。 在管理模型的同时,它还基于 Go 语言中的 Web 框架 gin
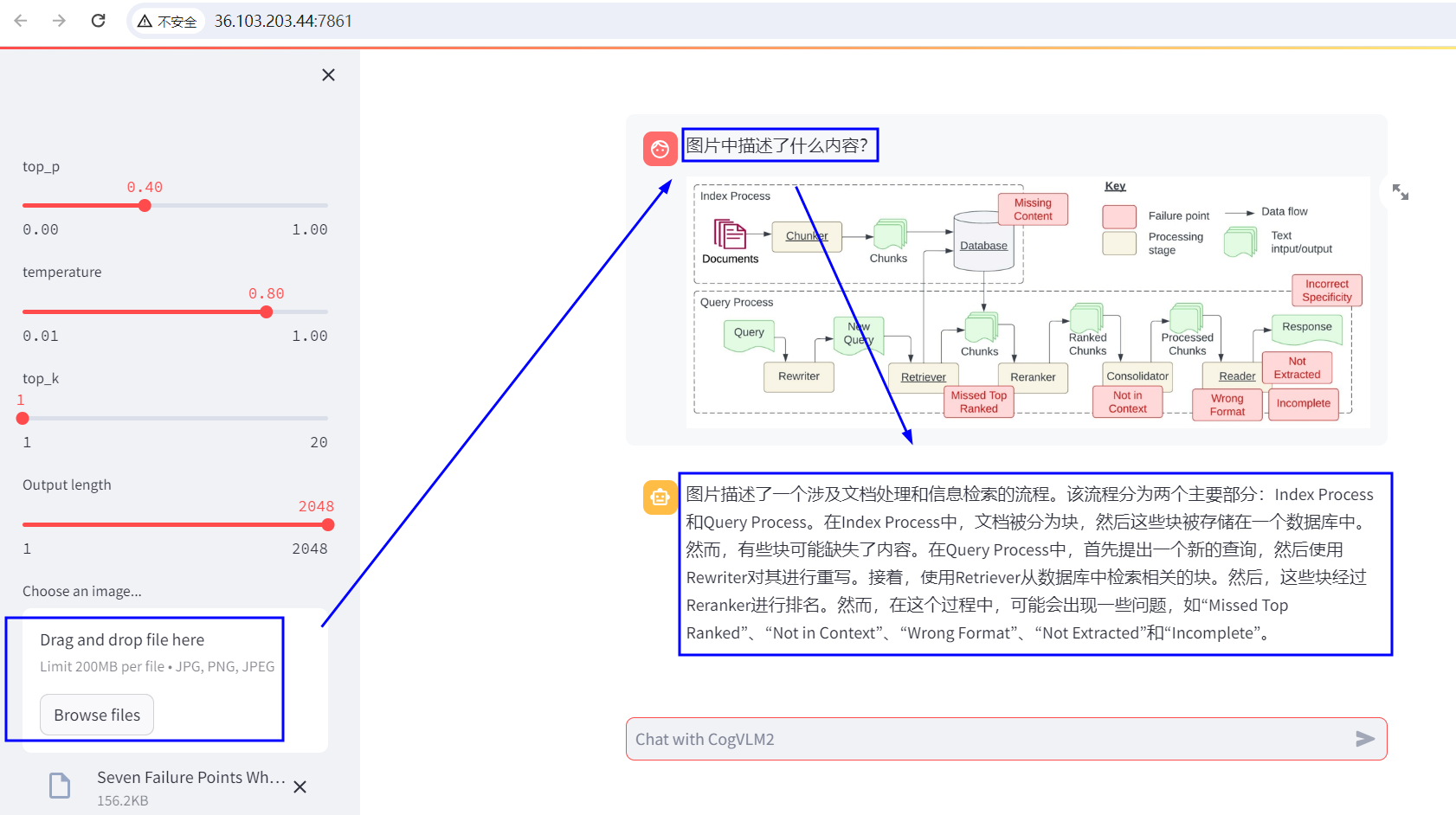
MLM之CogVLM2:CogVLM2(基于Llama-3-8B-Instruct 模型进行微调)的简介、安装和使用方法、案例应用之详细攻略
MLM之CogVLM2:CogVLM2(基于Llama-3-8B-Instruct 模型进行微调)的简介、安装和使用方法、案例应用之详细攻略 目录 CogVLM2的简介 1、更新日志 2、CogVLM2 系列开源模型的详细信息 3、Benchmark 4、项目结构 5、模型协议 CogVLM2的安装和使用方法 1、模型微调 注意 最低配置 开始微调 下载数据集和安
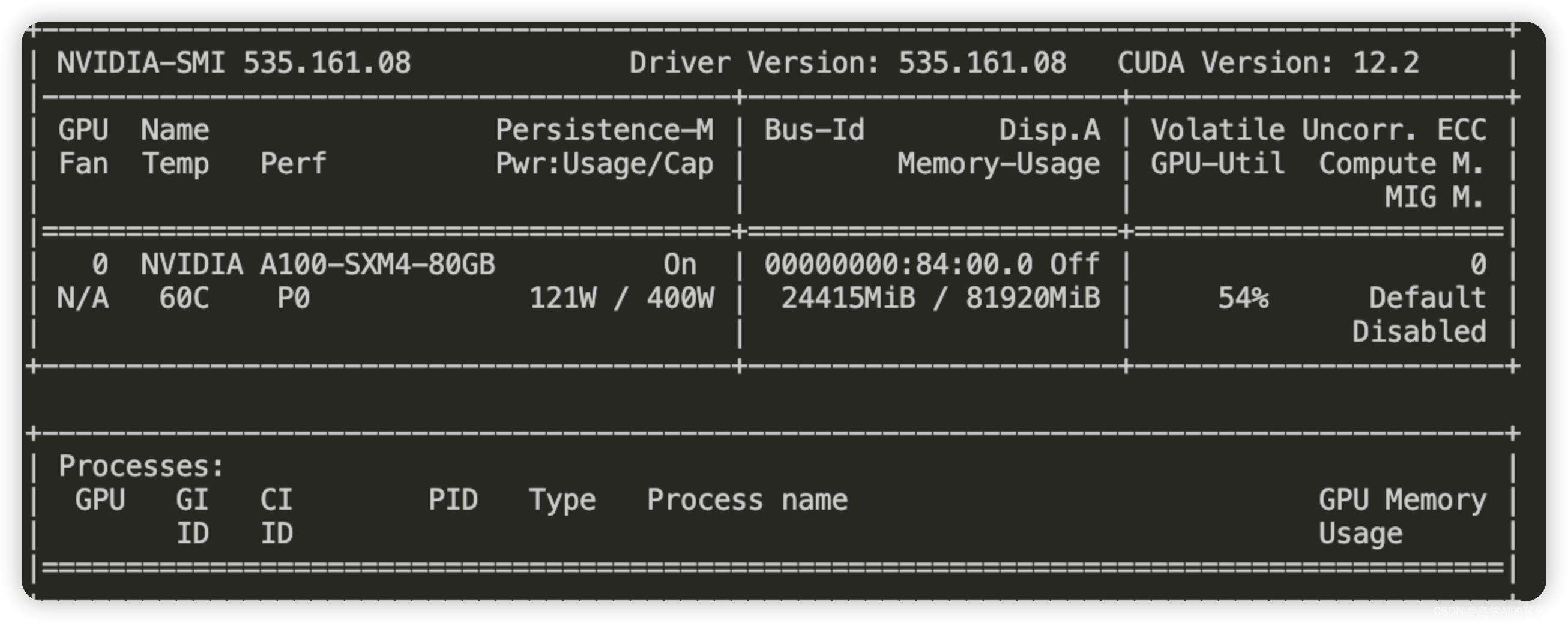
llama3-8b-instruct-262k微调过程的问题笔记(场景为llama论文审稿)
目录 一、环境配置 1.1、模型 1.2、微调环境 1.3、微调数据 二、发现的问题 2.1、过拟合问题 2.2、Qlora zero3 保存模型时OOM问题(已解决) 一、环境配置 1.1、模型 llama3-8b-instruct-262k (英文) 1.2、微调环境 Package Version-------------
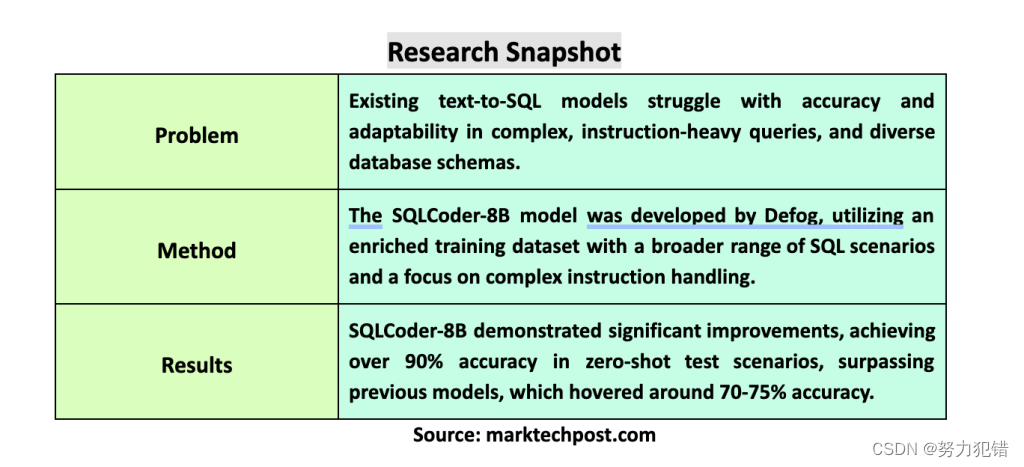
Defog发布Llama-3-SQLCoder-8B,文本转SQL模型,性能比肩GPT-4,准确率超90%,消费级硬件可运行
前言 在计算语言学领域,将自然语言转化为可执行的SQL查询是一个重要的研究方向。这对于让那些没有编程或SQL语法知识的用户也能轻松访问数据库信息至关重要。Defog团队近日发布了基于Llama-3的SQLCoder-8B模型,它在文本转SQL模型领域取得了显著突破,在准确率和易用性方面都达到了新的高度。 Huggingface模型下载:https://huggingface.co/defog
在电脑本地运行llama3-8b模型
文章目录 流程我的案例api调用llama.cpp 流程 ollama支持可运行的模型,图片这里只是一部分而已,只需要下载下面的软件和模型文件,即可直接运行,而无需配置其他 模型文件下载地址 https://ollama.com/library 支持的部分模型,实际上更多,这里只是显示部分 登陆ollama官网 https://ollama.com/download 下载对

vivado Aurora 8B/10B IP核(11)- 共享逻辑(Share Logic)
Vivado IDE 中的共享逻辑选项配置核心,包括可收集的资源,如收发器四路 PLL(QPLL),收 发器差分缓冲区(IBUFDS_GTE2)以及核心或示例设计中的时钟和复位逻辑。 当选择了核心选项中的包含共享逻辑时,所有可共享的资源可用于核心的多个实例,从而最小化所需的 HDL 修改量,同时保 留灵活性来解决更多的用例。 共享逻辑层次结构称为<component_name>_sup
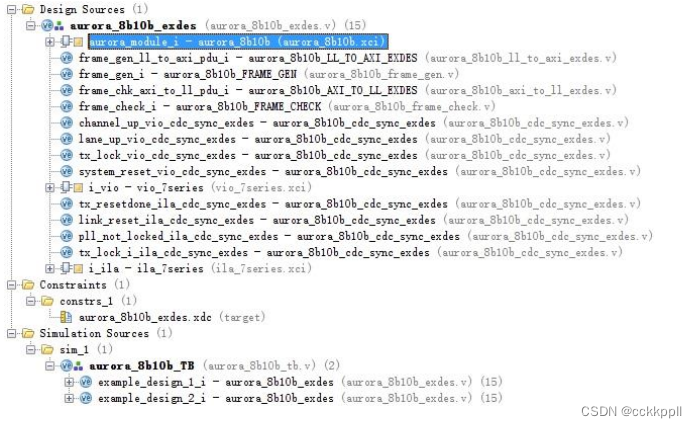
vivado Aurora 8B/10B IP核(12)- Setp By Step搭建FPGA工程
Step1:任意创建一个新的空的工程(创建工程的具体工程如果还不清楚的看我们教程第一季部分), 并且进入IP CORE列表 右击Customize ip Step2:配置 IP CORE-Core options Step3:配置 IP CORE-GT Selections Step4:配置 IP CORE-Shared Logic 为 include
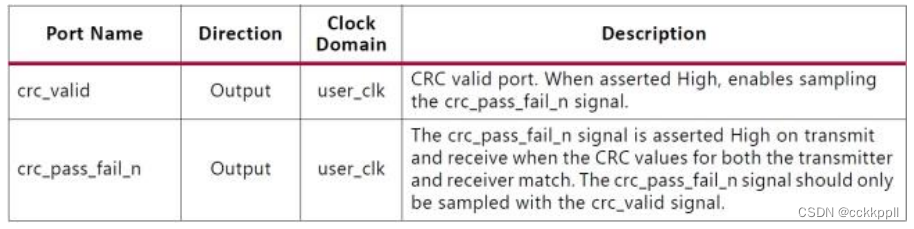
vivado Aurora 8B/10B IP核(9)- CRC、 Aurora 8B/10B内核的时钟接口端口
CRC 模块提供 16 位或 32 位 CRC,用于用户数据。 Aurora 8B/10B 内核的时钟接口端口 从相邻收发器四边形的时钟Xilinx 实现工具可以根据需要对南北路由和引脚交换到收发器时钟输入进行必要的调整,以将时钟从一个四线到另一个。 重要信息:共享参考时钟时必须遵守以下规则,以确保满足高速设计的抖动余量: •7 系列 FPGA 中由外部时钟

LLaMA3(Meta)微调SFT实战Meta-Llama-3-8B-Instruct
LlaMA3-SFT LlaMA3-SFT, Meta-Llama-3-8B/Meta-Llama-3-8B-Instruct微调(transformers)/LORA(peft)/推理 项目地址 https://github.com/yongzhuo/LLaMA3-SFT默认数据类型为bfloat6 备注 1. 非常重要: weights要用bfloat16/fp32/tf32(第二版
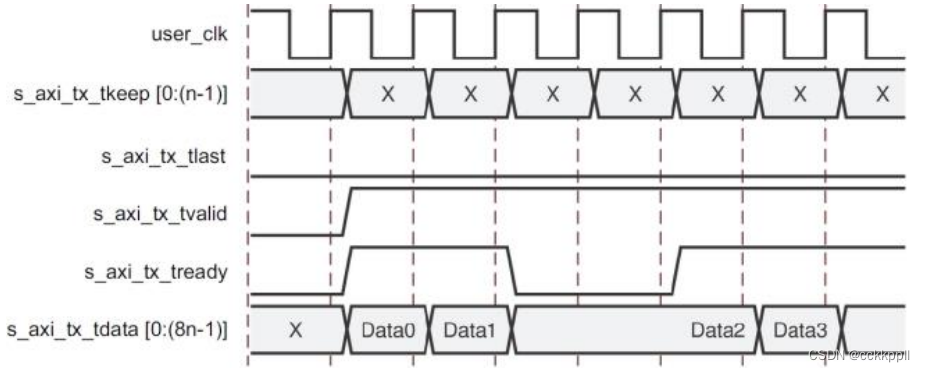
vivado Aurora 8B/10B IP核(6)-本地流量控制(Native Flow Control)
Aurora 8B/10B 协议包括本地流控制(NFC)接口,其允许接收机通过指定必须 放入数据流的空闲数据跳数来控制接收数据的速率。 甚至可以通过请求发送器临时发送空闲(XOFF) 来完全关闭数据流.NFC 通常用于防止 FIFO 溢出条件。有关 NFC 操作和代码的详细说明,请参阅 Aurora 8B/10B 协议规范(SP002)。 当 NFC 选项启用时生成

vivado Aurora 8B/10B IP核(5)-流量控制(Flow Control)
使用框架接口的内核上提供了两个可选的流控制接口。 本地流控制(NFC)调节全双工信道接收端的数据传输速率。 用户流控制(UFC)容纳用于控制操作的高优先级消息。 User Flow Control Interface(用户流控制接口) UFC 接口是在启用 UFC 生成 IPCORE 时创建的.UFC s_axi_ufc_tx_tvalid 和 TX 侧的 s_axi_ufc
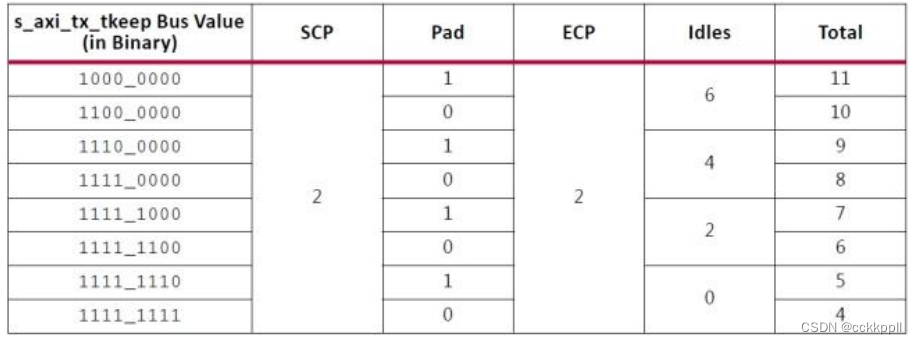
vivado Aurora 8B/10B IP核(3)-Aurora 8B/10B 帧(Frames)
TX 子模块将每个接收的用户帧通过 TX 接口转换为 Aurora 8B / 10B 帧。 帧开始(SOF)通过 在帧开始处添加 2 字节的 SCP 代码组来指示。 帧结束(EOF)是通过在帧的末尾添加一个 2 字节的信道结束通道协议(ECP)码组来确定的。 数据不可用时插入空闲代码组。 代码组是 8B / 10B 编码字节对,所有数据都作为代码组发送,因此具有奇数个字节的用户帧具有称为 PA
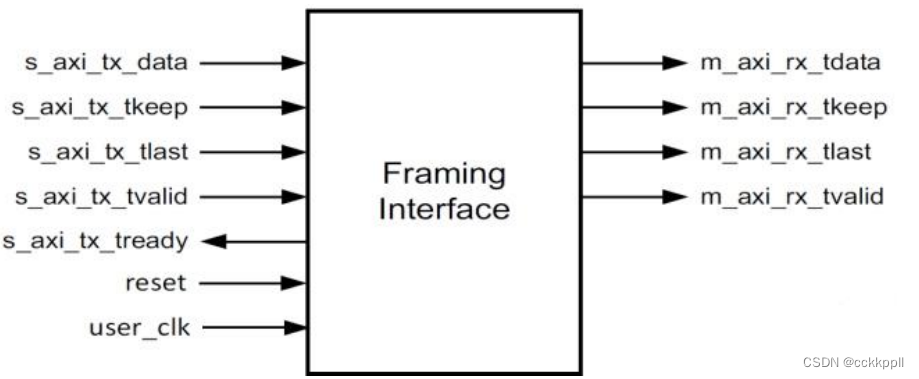
vivado Aurora 8B/10B IP核(2)
端口说明 ( Port Descriptions ) 用于生成每个 Aurora 8B/10B 内核的参数决定了可用于该特定内核的接口。 接口在 IP 符号中 可见。 在 IP 符号中,如果左键单击界面旁边的+号,可以看到分组在其中的端口。 在 本节中,也就是端口描述,一般来说,界面显示为单行条目,后面是分组在其中的端口。 例如,USER_DATA_S_AXIS_TX 是接

一键部署 Llama3 8B/70B!最高仅占1.07GB存储;COCONut上线,字节跳动推出的首个大规模全景图像分割数据集
近日,Meta 震撼发布了号称「开源 GPT-4」的大模型 Llama3,该模型惊动了整个 AI 圈,HyperAI超神经也迫不及待想要体验一下!hyper.ai 官网现已在公共教程上线「一键部署 Llama3」! 有没有人和我一样激动的搓手手?赶紧来运行一下~ 4 月 22 日-4 月 26 日,hyper.ai 官网更新速览: 优质公共数据集:10 个 优质教程精选:3 个 社区文章
使用SFT和VLLM微调和部署Llama3-8b模型
目录 1. 环境安装2. accelerator准备3. 加载llama3和数据4. 训练参数配置5. 微调6. vllm部署7. Llama-3-8b-instruct的使用参考 1. 环境安装 pip install -q -U bitsandbytespip install -q -U git+https://github.com/huggingface/transfor
使用 vllm 运行 Llama3-8b-Instruct
使用 vllm 运行 Llama3-8b-Instruct 0. 引言1. 安装 vllm2. 运行 Llama3-8b-Instruct 0. 引言 此文章主要介绍使用 vllm 运行 Llama3-8b。 1. 安装 vllm 创建虚拟环境, conda create -n myvllm python=3.11 -yconda activate myvllm 安装
本地部署 Meta Llama3-8b 和 Llama3-70b
本地部署 Meta Llama3-8b 和 Llama3-70b 0. 引言1. Meta对Llama 3的目标2. Llama 3的性能3. 下载和安装 Ollama4. 使用 Ollama 运行 Llama3 0. 引言 今天,Meta 正式介绍Meta Llama 3,Meta 开源大型语言模型的下一代产品。 这次发布包括具有80亿(8B)和700亿(70B)参数的预训