本文主要是介绍MLM之CogVLM2:CogVLM2(基于Llama-3-8B-Instruct 模型进行微调)的简介、安装和使用方法、案例应用之详细攻略,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
MLM之CogVLM2:CogVLM2(基于Llama-3-8B-Instruct 模型进行微调)的简介、安装和使用方法、案例应用之详细攻略
目录
CogVLM2的简介
1、更新日志
2、CogVLM2 系列开源模型的详细信息
3、Benchmark
4、项目结构
5、模型协议
CogVLM2的安装和使用方法
1、模型微调
注意
最低配置
开始微调
下载数据集和安装依赖
运行微调程序
推理微调后的模型
2、模型推理
最低配置要求
CLI 调用模型
Web端在线调用模型
OpenAI API
3、模型使用
CogVLM2的案例应用
CogVLM2的简介
我们推出了新一代的 CogVLM2 系列模型并开源了两款基于 Meta-Llama-3-8B-Instruct 开源模型。与上一代的 CogVLM 开源模型相比,CogVLM2 系列开源模型具有以下改进:
- 在许多关键指标上有了显著提升,例如
TextVQA,DocVQA。 - 支持 8K 文本长度。
- 支持高达 1344 * 1344 的图像分辨率。
- 提供支持中英文双语的开源模型版本。
GitHub地址:https://github.com/THUDM/CogVLM2
1、更新日志
News:2024/5/24:我们发布了 Int4 版本模型,仅需要 16GB 显存即可进行推理。欢迎前来体验!
News:2024/5/20:我们发布了下一代模型 CogVLM2,它基于 llama3-8b,在大多数情况下与 GPT-4V 相当(或更好)!欢迎下载!
2、CogVLM2 系列开源模型的详细信息
| 模型名称 | cogvlm2-llama3-chat-19B | cogvlm2-llama3-chinese-chat-19B |
|---|---|---|
| 基座模型 | Meta-Llama-3-8B-Instruct | Meta-Llama-3-8B-Instruct |
| 语言 | 英文 | 中文、英文 |
| 模型大小 | 19B | 19B |
| 任务 | 图像理解,对话模型 | 图像理解,对话模型 |
| 模型链接 | 🤗 Huggingface 🤖 ModelScope 💫 Wise Model | 🤗 Huggingface 🤖 ModelScope 💫 Wise Model |
| 体验链接 | 📙 Official Page | 📙 Official Page 🤖 ModelScope |
| Int4 模型 | 🤗 Huggingface 🤖 ModelScope | 🤗 Huggingface 🤖 ModelScope |
| 文本长度 | 8K | 8K |
| 图片分辨率 | 1344 * 1344 | 1344 * 1344 |
3、Benchmark
我们的开源模型相较于上一代 CogVLM 开源模型,在多项榜单中取得较好的成绩。其优异的表现能与部分的非开源模型进行同台竞技,如下表所示:
| Model | Open Source | LLM Size | TextVQA | DocVQA | ChartQA | OCRbench | MMMU | MMVet | MMBench |
|---|---|---|---|---|---|---|---|---|---|
| CogVLM1.1 | ✅ | 7B | 69.7 | - | 68.3 | 590 | 37.3 | 52.0 | 65.8 |
| LLaVA-1.5 | ✅ | 13B | 61.3 | - | - | 337 | 37.0 | 35.4 | 67.7 |
| Mini-Gemini | ✅ | 34B | 74.1 | - | - | - | 48.0 | 59.3 | 80.6 |
| LLaVA-NeXT-LLaMA3 | ✅ | 8B | - | 78.2 | 69.5 | - | 41.7 | - | 72.1 |
| LLaVA-NeXT-110B | ✅ | 110B | - | 85.7 | 79.7 | - | 49.1 | - | 80.5 |
| InternVL-1.5 | ✅ | 20B | 80.6 | 90.9 | 83.8 | 720 | 46.8 | 55.4 | 82.3 |
| QwenVL-Plus | ❌ | - | 78.9 | 91.4 | 78.1 | 726 | 51.4 | 55.7 | 67.0 |
| Claude3-Opus | ❌ | - | - | 89.3 | 80.8 | 694 | 59.4 | 51.7 | 63.3 |
| Gemini Pro 1.5 | ❌ | - | 73.5 | 86.5 | 81.3 | - | 58.5 | - | - |
| GPT-4V | ❌ | - | 78.0 | 88.4 | 78.5 | 656 | 56.8 | 67.7 | 75.0 |
| CogVLM2-LLaMA3 (Ours) | ✅ | 8B | 84.2 | 92.3 | 81.0 | 756 | 44.3 | 60.4 | 80.5 |
| CogVLM2-LLaMA3-Chinese (Ours) | ✅ | 8B | 85.0 | 88.4 | 74.7 | 780 | 42.8 | 60.5 | 78.9 |
所有评测都是在不使用任何外部OCR工具(“only pixel”)的情况下获得的。
4、项目结构
本开源仓库将带领开发者快速上手 CogVLM2 开源模型的基础调用方式、微调示例、OpenAI API格式调用示例等。具体项目结构如下,您可以点击进入对应的教程链接:
- basic_demo - 基础调用方式,包含了 CLI, WebUI 和 OpenAI API 等模型推理调用方式,以及模型调用的最低配置要求。如果您是第一次使用 CogVLM2 开源模型,建议您从这里开始。
- finetune_demo - 微调示例,包含了微调语言模型的示例。
5、模型协议
该模型根据 CogVLM2 LICENSE 许可证发布。对于使用了Meta Llama 3基座模型构建的模型,需要同时遵守 LLAMA3_LICENSE 许可证。
CogVLM2的安装和使用方法
1、模型微调
运行本demo来使用Lora微调 CogVLM2 中的语言模型部分。
注意
- 本代码仅提供了 huggingface 版本模型
cogvlm2-llama3-chat-19B的微调示例。 - 仅提供了微调语言模型的示例。
- 仅提供Lora微调示例。
- 仅提供对话模型微调示例。
- 暂不支持使用
zero3微调,这可能出现 模型无法读取的情况。
最低配置
- 我们仅在具有80GB内存的A100 GPU上进行了微调测试。使用零冗余优化策略2(zero2)时,至少需要73GB的GPU内存,并且需要8个GPU。
- 暂不支持 Tensor 并行,即模型拆分到多张显卡微调。
开始微调
下载数据集和安装依赖
本demo中,开发者可以使用由我们提供CogVLM-SFT-311K 开源数据集或自行构建相同格式的数据集进行微调。
数据格式如下:
- 数据集由
images和labels两个文件夹组成 (在 CogVLM-SFT-311K 中 为labels_en和labels_zh,分别对应中英文标签。 在微调代码中,你可以修改这两行代码来修改文件夹名称。
self.image_dir = os.path.join(root_dir, 'images')
self.label_dir = os.path.join(root_dir, 'labels_en') # or 'labels_zh' or 'labels' 可以自行修改images文件夹中存放了图片文件,labels文件夹中存放了对应的标签文件。图片和标签文件的名称一一对应。图片文件的格式为jpg,标签文件的格式为json。- 每个标签文件中包含了一段对话,对话由
user和assistant两个角色组成,每个角色的对话内容由role和content两个字段组成。如下字段所示。
{"conversations": [{"role": "user","content": "What can be inferred about the zebras' behavior and surroundings?"},{"role": "assistant","content": "Based on the image, we can infer that the two zebras are likely seeking relief from the sun's heat, as they are standing side by side under the branches of a thorny tree. This shade-providing tree offers some respite from the sun, possibly during the hottest part of the day. The zebras are in a green field with grass, providing them with an ideal environment to graze and eat while staying near their source of shelter. This shows that the zebras' behavior is influenced by the conditions and available resources in their surroundings. It also highlights that these animals adopt strategies to adapt to the fluctuating conditions of their environment, such as cooperation and seeking shelter, to survive and thrive in their natural habitat."}]
}
在开始微调之前,需要安装相关的依赖。请注意,你还需要安装好 basic_demo 中的依赖。
pip install -r requirements.txt注意: mpi4py 可能需要安装别的 Linux 依赖包。请根据您的系统环境自行安装。
运行微调程序
我们提供了使用单机多卡(包含单卡)的微调脚本 peft_lora.py。您可以通过运行以下命令来启动微调。
deepspeed peft_lora.py --ds_config ds_config.yaml下图展现了微调过程中的显存占用情况
参数信息:
max_input_len: 512max_output_len: 512batch_size_per_gpus: 1lora_target: vision_expert_query_key_value
显存占用情况:
+-------------------------------------------------------------+ | Processes: | | GPU GI CI PID Type Process name GPU Memory | | ID ID Usage | |=============================================================| | 0 N/A N/A 704914 C python 72442MiB | | 1 N/A N/A 704915 C python 72538MiB | | 2 N/A N/A 704916 C python 72538MiB | | 3 N/A N/A 704917 C python 72538MiB | | 4 N/A N/A 704918 C python 72538MiB | | 5 N/A N/A 704919 C python 72538MiB | | 6 N/A N/A 704920 C python 72538MiB | | 7 N/A N/A 704921 C python 72442MiB | +-------------------------------------------------------------+
在代码运行中,Loss数据会被 tensorboard记录,方便可视化查看Loss收敛情况。
tensorboard --logdir=output注意: 我们强烈推荐您使用 BF16 格式进行微调,以避免出现 Loss 为 NaN的问题。
推理微调后的模型
运行 peft_infer.py,你可以使用微调后的模型生成文本。您需要按照代码中的配置要求,配置微调后的模型地址。然后运行:
python peft_infer.py即可使用微调的模型进行推理。
2、模型推理
最低配置要求
Python: 3.10.12 以上版本。
操作系统: 建议使用 Linux 操作系统运行以避免xformers库安装问题。建议使用 NVIDIA GPU 以防止兼容性问题。
GPU要求如下表格所示
| 模型名称 | 19B 系列模型 | 备注 |
|---|---|---|
| BF16 / FP16 推理 | 42GB | 测试对话文本长度为2K |
| Int4 推理 | 16GB | 测试对话文本长度为2K |
| BF16 Lora Tuning (带有视觉专家微调) | 73GB (使用8卡A100 80G显卡并使用 Zero 2) | 训练对话文本长度为 2K |
在运行任何代码之前,请确保你已经安装好了所有的依赖包。你可以通过以下命令来安装所有的依赖包:
pip install -r requirements.txtCLI 调用模型
运行本代码以开始在命令行中对话。请注意,模型必须在一张GPU上载入
CUDA_VISIBLE_DEVICES=0 python cli_demo.py如果您有多张GPU,您可以通过以下代码执行多卡拉起模型,并将模型的不同层分布在不同的GPU上。
python cli_demo_multi_gpu.py在 cli_demo_multi_gpu.py 中,我们使用了 infer_auto_device_map 函数来自动分配模型的不同层到不同的GPU上。你需要设置 max_memory 参数来指定每张GPU的最大内存。例如,如果你有两张GPU,每张GPU的内存为23GiB,你可以这样设置:
device_map = infer_auto_device_map(model=model,max_memory={i: "23GiB" for i in range(torch.cuda.device_count())},# set 23GiB for each GPU, depends on your GPU memory, you can adjust this valueno_split_module_classes=["CogVLMDecoderLayer"]
)Web端在线调用模型
运行本代码以开始在 WebUI 中对话。
chainlit run web_demo.py拉起对话后,你将能和模型进行对话,效果如下:
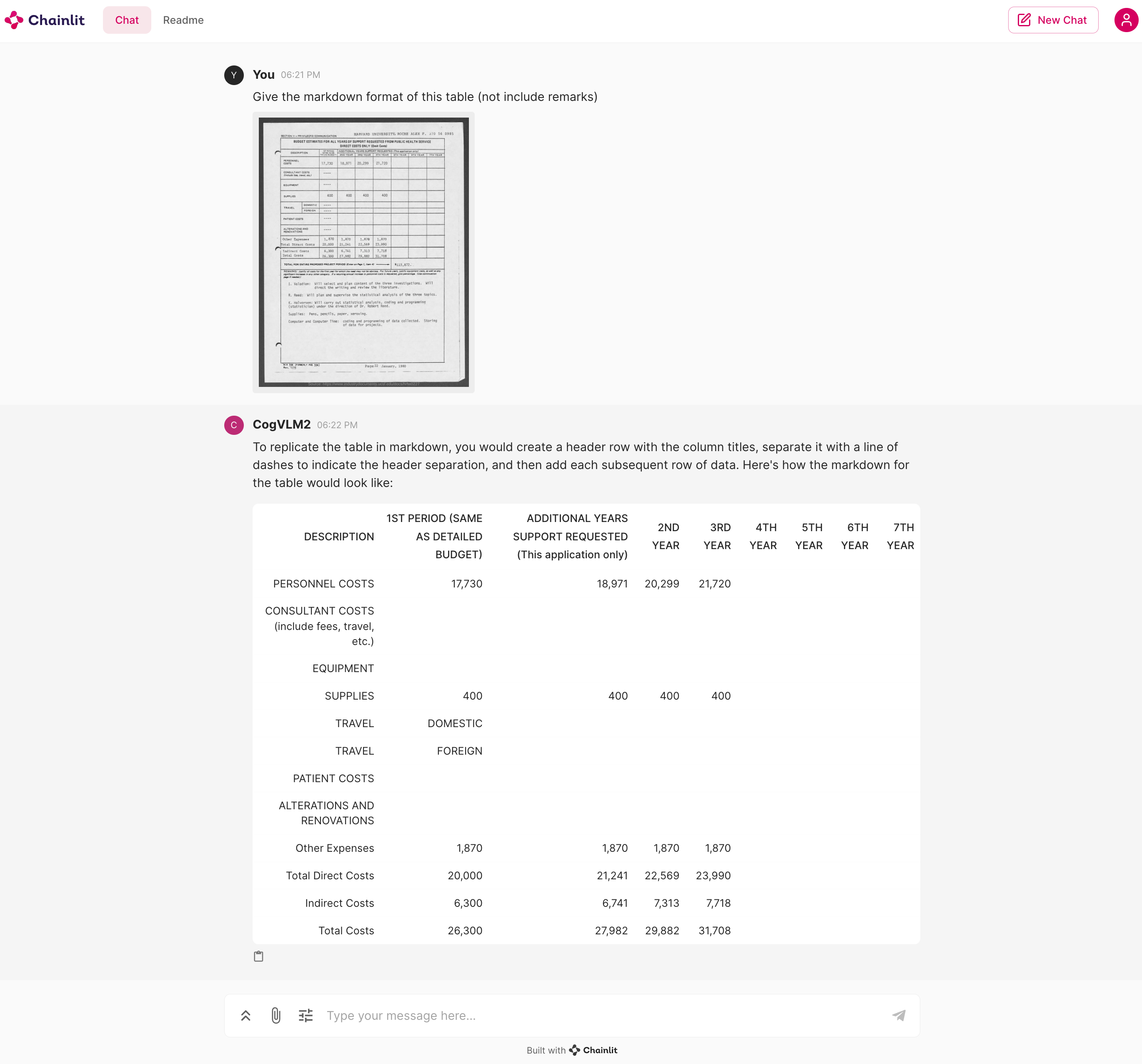
OpenAI API
我们提供了一个简单的示例,通过以下代码拉起模型,之后,您可以使用 OpenAI API格式的方式请求和模型的对话。
python openai_api_demo.py开发者可以通过以下代码来调用模型:
python openai_api_request.py3、模型使用
地址:Streamlit
CogVLM2的案例应用
持续更新中……
这篇关于MLM之CogVLM2:CogVLM2(基于Llama-3-8B-Instruct 模型进行微调)的简介、安装和使用方法、案例应用之详细攻略的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







