本文主要是介绍交叉注意力一脚踹进医学图像分割!新成果精度、效率表现SOTA,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
为解决传统方法的局限性,研究者们提出了将交叉注意力机制应用于医学图像分割。
交叉注意力机制能更有效地整合来自不同模态/尺度的特征,让模型同时捕捉全局和局部信息,加速学习并减少干扰。这样不仅可以提高分割的精度,还可以减少训练时间,提高分割的效率。
因此这种策略成为了目前医学图像领域的重要研究方向,为我们实现更高的综合性能提供了新的解决思路。
本次分享8种最新的用交叉注意力做医学图像分割的创新方案,开源代码已附,论文创新点做了简单提炼,供大家参考学习寻找灵感。
论文原文以及开源代码需要的同学看文末
Dual Cross-Attention for Medical Image Segmentation
方法:论文介绍了一种用于医学图像分割的基于U-Net的架构中加强跳跃连接的Dual Cross-Attention (DCA)方法。DCA包括通道交叉注意力(CCA)和空间交叉注意力(SCA)模块,分别在通道和空间维度上捕捉远距离依赖关系。

创新点:
-
提出了Dual Cross-Attention (DCA)机制,通过顺序捕捉通道和空间维度上的长程依赖关系,加强了U-Net-based架构中的跳跃连接。
-
在融合策略上,通过比较三种融合策略(求和、串联和顺序融合),发现顺序融合策略的性能最好。顺序融合策略先进行CCA,再进行SCA,能够更好地提升性能。
-
在补丁嵌入方面,通过比较简单的2D平均池化和卷积补丁嵌入,发现2D平均池化在性能上稍微优于卷积补丁嵌入。此外,卷积补丁嵌入需要额外的参数,而2D平均池化是无参数的,并且与1×1深度卷积投影结合时效果更好。

BEFUnet: A Hybrid CNN-Transformer Architecture for Precise Medical Image Segmentation
方法:本文提出了一种新的医学图像分割结构BEFUnet,BEFUnet包含三个主要模块:局部交叉注意力特征融合模块、双层融合模块和双分支编码器,实现了边缘分割的鲁棒性和精确性。BEFUnet模型能够准确地分割边界模糊、不规则和受干扰的器官区域,并具有强大的泛化能力。

创新点:
-
引入了像素差异卷积的概念,将传统边缘编码器和深度CNN的优势结合起来。这种整合使得边缘分割更加稳健和精确。
-
提出了一种名为BEFUnet的新型医学图像分割结构,该结构提取了身体和边缘特征,并有效地将它们集成在一起以增强分割性能。

CKD-TransBTS: Clinical Knowledge-Driven Hybrid Transformer With Modality-Correlated Cross-Attention for Brain Tumor Segmentation
方法:论文提出了一种新颖的基于临床知识驱动的脑肿瘤分割模型CKD-TransBTS。模型结构由双分支混合编码器和特征校准解码器组成。设计了一个具有所提出的模态相关交叉注意力块的双分支混合编码器来提取多模态图像特征。双分支混合编码器利用Transformer和CNN的优势,通过Modality-Correlated Cross-Attention模块进行跨模态特征提取。

创新点:
-
提出了一种根据影像学原理对不同MRI序列进行重新分组的方法,将相关的图像模态组合在一起,使模型能够学习到更好的跨模态特征表示。
-
提出了一种混合编码器的设计,将Transformer和CNN的优势相结合,通过引入卷积层在Transformer模型中实现归纳偏置和更好的局部特征表示。
-
设计了一种特征校准解码器,通过Trans&CNN特征校准模块来弥合Transformer和CNN提取的特征之间的差距,从而获得更精确的分割结果。
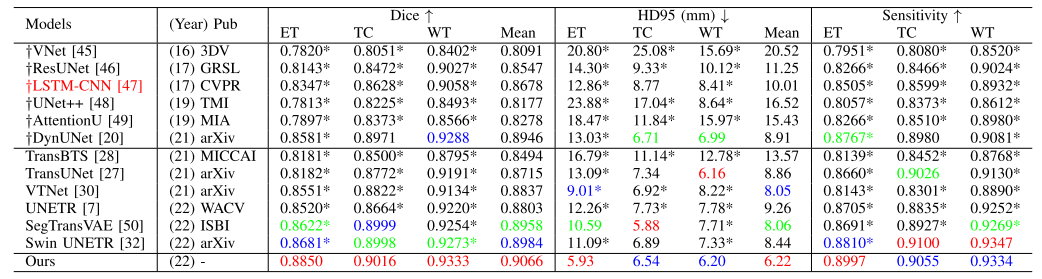
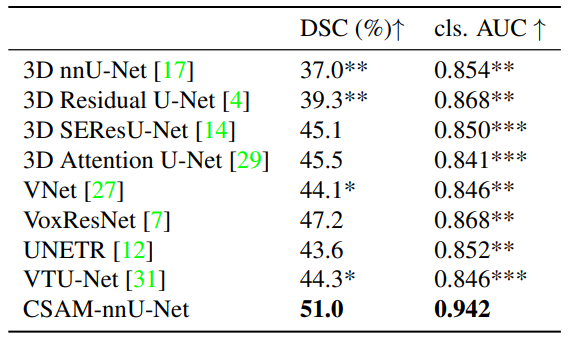
CSAM: A 2.5D Cross-Slice Attention Module for Anisotropic Volumetric Medical Image Segmentation
方法:论文比较不同模型在医学图像分割中的性能,并提出了一种新的2.5D交叉切片注意机制(CSAM),该机制在前列腺分区分割中表现出优越性能,并且具有更少的参数。

创新点:
-
引入了CSAM,该机制可以有效地学习和利用3D图像体积中的跨切片信息,从而改善体积分割的性能。
-
CSAM可以方便地插入到现有的2D CNN网络中,实现体积图像分割。通过对前列腺、胎盘和心脏MRI分割的广泛验证研究,证明了CSAM模型在性能上优于相应的2D、3D和之前最先进的2.5D方法。
关注下方《学姐带你玩AI》🚀🚀🚀
回复“注意力医学”获取全部论文+代码
码字不易,欢迎大家点赞评论收藏
这篇关于交叉注意力一脚踹进医学图像分割!新成果精度、效率表现SOTA的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





