reinforcement专题
Policy-Based Reinforcement Learning(1)
之前提到过Discount Return: Action-value Function : State-value Function: (这里将action A积分掉)这里如果策略函数很好,就会很大;反之策略函数不好,就会很小。 对于离散类型: 用神经网络近似策略, 即 学习参数,使得越来越大。这里使用梯度上升的方法,对于一个可观测状态s,更新 这里称为策略梯度(P

Reinforcement Learning学习(三)
前言 最近在学习Mujoco环境,学习了一些官方的Tutorials以及开源的Demo,对SB3库的强化学习标准库有了一定的了解,尝试搭建了自己的环境,基于UR5E机械臂,进行了一个避障的任务,同时尝试接入了图像大模型API,做了一些有趣的应用,参考资料如下: https://mujoco.readthedocs.io/en/stable/overview.html https://pab4
Value-Based Reinforcement Learning(1)
Action-Value Functions Discounted Return(未来的reward,由于未来存在不确定性,所以未来的reward 要乘以进行打折) 这里的依赖actions ,和states 这里 Policy Function : ,表达了action的随机性 State Transition : ,表达了转移状态的随机性 由于存在action,和sta
Value-Based Reinforcement Learning(2)
Temporal Difference (TD) Learning 上节已经提到了如果我们有DQN,那么agent就知道每一步动作如何做了,那么DQN如何训练那?这里面使用TD算法。 简略分析: 是的估计 是的估计 所以: Deep Reinforcement Learning : Prediction : TD Target : Loss : Gradient

Multi-objective reinforcement learning approach for trip recommendation
Multi-objective reinforcement learning approach for trip recommendation A B S T R A C T 行程推荐是一项智能服务,为游客在陌生的城市提供个性化的行程规划。 它旨在构建一系列有序的 POI,在时间和空间限制下最大化用户的旅行体验。 将候选 POI 添加到推荐行程时,根据实时上下文捕获用户的动态偏好至关重要。

Online RL + IL : TGRL: An Algorithm for Teacher Guided Reinforcement Learning
ICML 2023 Poster paper Intro 文章设定一个专家策略,给出两种优化目标。一个是基于专家策略正则的累计回报,一个是原始累计回报。通过比较二者动态的衡量专家策略对智能体在线学习的影响程度,进而实现在线引导过程。 Method 原始的RL目标是最大化累计奖励: π ∗ = arg max π J R ( π ) : = E [ ∑ t = 0 ∞ γ t r t
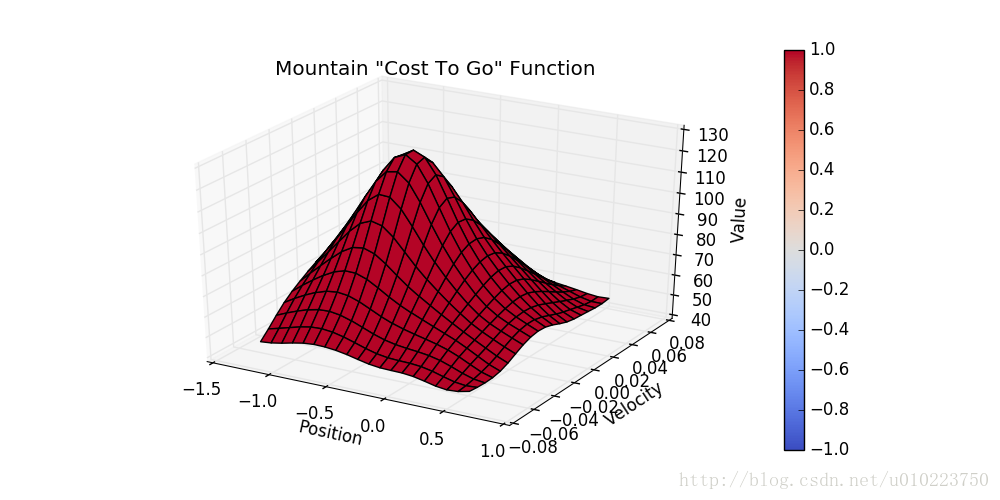
Reinforcement Learning强化学习系列之五:值近似方法Value Approximation
引言 前面说到了强化学习中的蒙特卡洛方法(MC)以及时序差分(TD)的方法,这些方法针对的基本是离散的数据,而一些连续的状态则很难表示,对于这种情况,通常在强化学习里有2中方法,一种是针对value function的方法,也就是本文中提到的值近似(value approximation);另一种则是后面要讲到的policy gradient。 值近似的方法 值近似的方法根本上是使用一个

Reinforcement Learning强化学习系列之三:MC Control
引言 前面一篇文章中说到了MC prediction,主要介绍的是如何利用采样轨迹的方法计算Value函数,但是在强化学习中,我们主要想学习的是Q函数,也就是计算出每个state对应的action以及其reward值,在这篇文章中,将会介绍。 MC control with epsilon-greedy 这一部分将会介绍基于 ϵ−greedy ϵ − g r e e d y \epsil

Reinforcement Learning强化学习系列之一:model-based learning
前言 在机器学习和深度学习坑里呆了有一些时日了,在阿里实习过程中,也感觉到了工业界和学术界的一些迥异,比如强化学习在工业界用的非常广泛,而自己之前没有怎么接触过强化学习的一些知识,所以感觉还是要好好的补一补更新一下自己的知识库,以免被AI时代抛弃。 强化学习初识 强化学习要素 强化学习可以用下面这张图表示: 从上图可以看出,强化学习的要素是: 1. Agent(图中指大脑) 2.
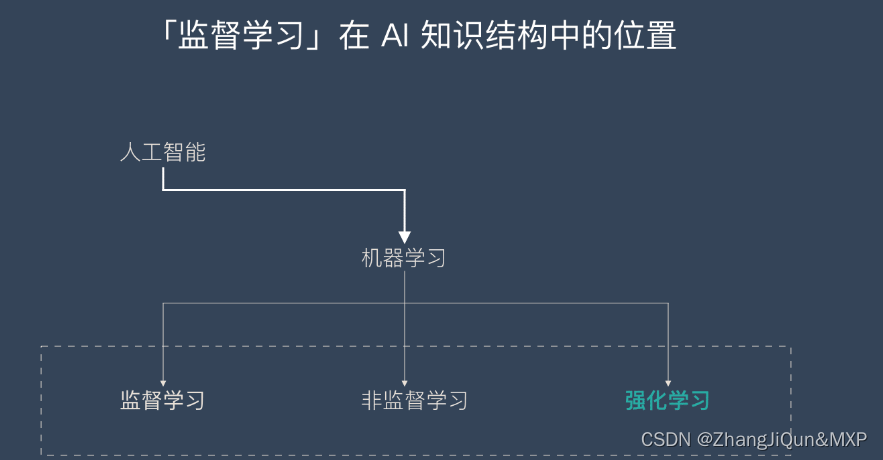
强化学习-Reinforcement learning | RL
目录 什么是强化学习? 强化学习的应用场景 强化学习的主流算法 强化学习是机器学习的一种学习方式,它跟监督学习、无监督学习是对应的。本文将详细介绍强化学习的基本概念、应用场景和主流的强化学习算法及分类。 什么是强化学习? 强化学习并不是某一种特定的算法,而是一类算法的统称。 如果用来做对比的话,他跟监督学习,无监督学习 是类似的,是一种统称的学习方式。

论文笔记 | MathDQN: Solving Arithmetric Word Problems via Deep Reinforcement Learning
简介 Lei Wang 和 Dongxiang Zhang团队在AAAI18上发表的文章,使用了DQN来解决MWP(Math Word Problem)问题。 Motivation 在将问题表达成一个表达式树的时候,有一种方法是枚举所有的操作数,组成树的叶子节点。这种方法所需的搜索空间很大,虽然有一些剪枝的算法可以运用,但仍不能满足需求。 在实践中,可以发现Deep Q-netwrok能够

RLHF(Reinforcement Learning from Human Feedback)的故事:起源、动机、技术及现代应用
RLHF(Reinforcement Learning from Human Feedback)的故事:起源、动机、技术及现代应用 自2018年BERT模型的提出以来,AI研究领域见证了自动语言任务处理技术的快速发展。BERT结合了变压器架构、自监督预训练及监督式迁移学习的强大能力,改写了多个性能基准测试的记录。尽管BERT不适用于生成任务,T5模型证明了监督式迁移学习在此类任务中同样有效。然而
离线强化学习Offline Reinforcement Learning
离线强化学习(Offline Reinforcement Learning,简称Offline RL)是深度强化学习的一个子领域,它不需要与模拟环境进行交互,而是直接从已有的数据中学习一套策略来完成相关任务。这种方法被认为是强化学习落地的重要技术之一。 Offline RL 可以被定义为 data-driven 形式的强化学习问题,即在智能体(policy函数?)不和环境交互的情况下,来从获取的

十六、强化学习-Reinforcement Learning
强化学习(Reinforcement Learning): 机器学习的一个分支:监督学习、无监督学习、强化学习强化学习的思路和人比较类似,是在实践中学习比如学习走路,如果摔倒了,那么我们大脑后面会给一个负面的奖励值 => 这个走路姿势不好;如果后面正常走了一步,那么大脑会给一个正面的奖励值 => 这是一个好的走路姿势与监督学习的区别,没有监督学习已经准备好的训练数据输出值,强化学习只有奖励值,但

O2O:Sample Efficient Offline-to-Online Reinforcement Learning
IEEE TKDE 2024 paper Introduction O2O存在策略探索受限以及分布偏移问题,进而导致在线微调阶段样本效率低。文章提出OEMA算法首先使用离线数据训练乐观的探索策略,然后提出基于元学习的优化方法,减少分布偏移并提高O2O的适应过程。 Method optimistic exploration strategy 离线学习方法TD3+BC的行为策略 π e

O2O:Offline Meta-Reinforcement Learning with Online Self-Supervision
ICML 2022 paper Introduction 元强化学习(Meta RL)结合O2O。元RL需要学习一个探索策略收集数据,同时还需学习一个策略快速适应新任务。由于策略是在固定的离线数据集上进行元训练的,因此在适应探索策略收集的数据时,它可能表现得不可预测,该策略与离线数据可能存在系统性差异,从而导致分布偏移。 本文提出两阶段的Meta offline RL算法SMAC,该算法利用
论文阅读--Diffusion Models for Reinforcement Learning: A Survey
一、论文概述 本文主要内容是关于在强化学习中应用扩散模型的综述。文章首先介绍了强化学习面临的挑战,以及扩散模型如何解决这些挑战。接着介绍了扩散模型的基础知识和在强化学习中的应用方法。然后讨论了扩散模型在强化学习中的不同角色,并对其在多个应用领域的贡献进行了探讨。最后总结了目前的研究方向和未来的发展趋势。 二、内容 绪论:这篇调查论文主要关注在强化学习(RL)中应用扩散模型的研究。这类模型具有

机器学习专项课程03:Unsupervised Learning, Recommenders, Reinforcement Learning笔记 Week02
Week 02 of Unsupervised Learning, Recommenders, Reinforcement Learning 课程地址: https://www.coursera.org/learn/unsupervised-learning-recommenders-reinforcement-learning 本笔记包含字幕,quiz的答案以及作业的代码,仅供个人学习使

李宏毅机器学习课程笔记10:Ensemble、Deep Reinforcement Learning
台湾大学李宏毅老师的机器学习课程是一份非常好的ML/DL入门资料,李宏毅老师将课程录像上传到了YouTube,地址:NTUEE ML 2016 。 这篇文章是学习本课程第27-28课所做的笔记和自己的理解。 Lecture 27: Ensemble Ensemble类似于“打群架”“大家一起上”,在Kaggle中是重要的方法。 Ensemble的Framework是: 先找到若干分
机器学习专项课程03:Unsupervised Learning, Recommenders, Reinforcement Learning笔记 Week01
Week 01 of Unsupervised Learning, Recommenders, Reinforcement Learning 本笔记包含字幕,quiz的答案以及作业的代码,仅供个人学习使用,如有侵权,请联系删除。 课程地址: https://www.coursera.org/learn/unsupervised-learning-recommenders-reinforce
Action-Decision Networks for Visual Tracking with Deep Reinforcement Learning
题目:Action-Decision Networks for Visual Tracking with Deep Reinforcement Learning 来源:CVPR 2017 Abstract 本文用强化学习来做跟踪。与现有的使用深度网络的方法相比,所提的tracker可以实现a light computation,并且在location和scale方面可以满足跟踪accurac

DL学习笔记【22】增强学习(Reinforcement Learning)
据说了解增强学习首先要了解马尔可夫性 马尔可夫性 在已知目前状态 (现在)的条件下,它未来的演变(将来)不依赖于它以往的演变 (过去 ) 马尔可夫过程按照其状态和时间参数是否连续或者离散分为三种: 时间和状态都离散的叫做马尔科夫链 时间和状态都是连续的叫做马尔科夫过程 时间连续,状态离散的叫做连续时间的马尔科夫链。 N步转移概率矩阵: P(n)=

论文笔记《Neural Architecture Search With Reinforcement Learning》
摘要 神经网络是一种强大而灵活的模型,能够很好地解决图像、语音和自然语言理解中的许多困难学习任务。尽管成功,神经网络仍然很难设计。在本文中,我们使用一个循环网络来生成神经网络的模型描述,并通过强化学习训练该RNN,以最大限度地提高生成的架构在验证集上的预期精度。在cifar-10数据集上,我们的方法从无到可以设计出一种新的网络体系结构,在测试集精度方面可以与人类发明的最佳体系结构相媲美。我们的c

【RL】Basic Concepts in Reinforcement Learning
Lecture1: Basic Concepts in Reinforcement Learning MDP(Markov Decision Process) Key Elements of MDP Set State: The set of states S \mathcal{S} S(状态 S \mathcal{S} S的集合) Action: the set of actions
强化学习 - Deep Reinforcement Learning from Human Preferences (DRLHP)
什么是机器学习 “Deep Reinforcement Learning from Human Preferences” (DRLHP) 这个具体的方法可能是一种在深度强化学习中使用人类偏好信息的技术。以下是对这个领域的一般理解: 1. 背景 在传统的强化学习中,代理通过与环境的交互来学习最优的策略。但在某些情况下,环境可能过于复杂或危险,无法直接提供有效的奖励信号。此时,使用人类偏好信息成
![[机器学习入门] 李宏毅机器学习笔记-37 (Deep Reinforcement Learning;深度增强学习入门)](https://img-blog.csdn.net/20170804202354206?watermark/2/text/aHR0cDovL2Jsb2cuY3Nkbi5uZXQvc291bG1lZXRsaWFuZw==/font/5a6L5L2T/fontsize/400/fill/I0JBQkFCMA==/dissolve/70/gravity/SouthEast)
[机器学习入门] 李宏毅机器学习笔记-37 (Deep Reinforcement Learning;深度增强学习入门)
[机器学习入门] 李宏毅机器学习笔记-37(Deep Reinforcement Learning;深度增强学习入门) PDFVIDEO Deep Reinforcement Learning 深度增强学习是一套很复杂的方法,在这里只了解皮毛。 Scenario of Reinforcement Learning 有个傻傻的机器人小白(Agent)去闯荡世界(Envi