本文主要是介绍离线强化学习Offline Reinforcement Learning,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
离线强化学习(Offline Reinforcement Learning,简称Offline RL)是深度强化学习的一个子领域,它不需要与模拟环境进行交互,而是直接从已有的数据中学习一套策略来完成相关任务。这种方法被认为是强化学习落地的重要技术之一。
Offline RL 可以被定义为 data-driven 形式的强化学习问题,即在智能体(policy函数?)不和环境交互的情况下,来从获取的轨迹中学习经验知识,达到使目标最大化!!

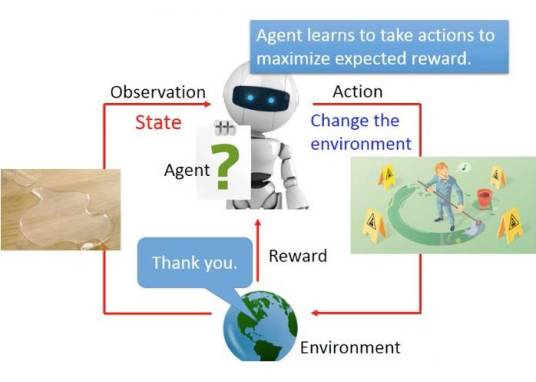
Offline RL最初被称为Batch Reinforcement Learning,后来Sergey Levine等人在其2020年的综述中开始使用Offline Reinforcement Learning这一术语,现在普遍使用后者表示。Offline RL可以被定义为data-driven形式的强化学习问题,即智能体在缺乏仿真且与环境交互成本高昂时,利用之前收集的数据为后续在线地强化学习奠定基础。
通过Offline RL,我们可以自动获得以策略为代表的接近最优的行为技能,以优化用户指定的奖励函数。奖励函数定义了智能体应该做什么,而Offline RL算法决定了如何做。与传统的在线强化学习相比,Offline RL的主要优势在于它不需要实时与环境进行交互,从而降低了学习成本并提高了学习效率。
然而,Offline RL也面临一些挑战,如数据分布偏移、外推误差等问题。为了克服这些挑战,研究者们正在探索各种方法,如数据筛选、模型正则化等,以提高Offline RL的性能和稳定性。
参考文献:
离线强化学习系列博客专栏 - 知乎介绍Offline RL相关技术及发展。![]() https://www.zhihu.com/column/c_1487193754071617536
https://www.zhihu.com/column/c_1487193754071617536
万字离线强化学习总结!(原理、数据集、算法、复杂性分析、超参数调优等)|轨迹|智能体_网易订阅万字离线强化学习总结!(原理、数据集、算法、复杂性分析、超参数调优等),强化学习,轨迹,算法,智能体,原理![]() https://www.163.com/dy/article/H7DO8OSI0511DPVD.html
https://www.163.com/dy/article/H7DO8OSI0511DPVD.html
这篇关于离线强化学习Offline Reinforcement Learning的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









