本文主要是介绍Multi-objective reinforcement learning approach for trip recommendation,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Multi-objective reinforcement learning approach for trip recommendation

A B S T R A C T
行程推荐是一项智能服务,为游客在陌生的城市提供个性化的行程规划。 它旨在构建一系列有序的 POI,在时间和空间限制下最大化用户的旅行体验。 将候选 POI 添加到推荐行程时,根据实时上下文捕获用户的动态偏好至关重要。 同时,个性化出行中POI的多样性和流行度对用户的选择起着重要作用。 为了应对这些挑战,在本文中,我们提出了 **MORL-Trip(旅行推荐多目标强化学习的缩写)**方法。 MORL-Trip 将个性化旅行推荐建模为马尔可夫决策过程 (MDP),并在 Actor-Critic 框架上实现。 MORL-Trip 通过顺序信息、地理信息和顺序信息增强状态表示,以从实时位置了解用户的上下文。 此外,MORL-Trip 通过设计复合奖励函数来增强标准 Critic 组件,以实现三个主要目标:准确性、流行度和多样性。
1. Introduction
随着移动设备和无线网络的普及,基于位置的社交网络(LBSNs)如Flickr, Foursquare和Gowalla在全球范围内广泛应用。在这些LBSNs中,用户可以分享他们的体验和兴趣点(POI)访问信息。用户在LBSNs中主动或被动地留下地理位置信息,生成大规模的时空轨迹数据。通过挖掘这些数据记录,智能旅游服务可以分析用户的潜在需求,并建议未访问过的地点以匹配用户的兴趣。这不仅有助于用户更好地探索吸引人的POIs,还可以帮助公司识别更多潜在用户,从而提高经济效益。
作为一种流行的智能旅游服务,行程推荐在工业界和学术界受到了广泛关注。行程推荐是一个复杂且具有挑战性的任务,需要发现符合用户偏好的吸引人的POIs,并在多个约束条件下将这些POIs连接成有序的序列。近年来,许多方法被提出以解决行程推荐问题。例如,Lim等(2018)利用POI的受欢迎程度和用户偏好为游客生成合适的行程。用户偏好根据POI类别的访问频率计算。然而,这种方法无法为训练集中从未访问过某类POI的用户推荐个性化的行程。为解决这一问题,Chen, Zhang等(2020)将POI类别和POI文本信息融合到行程推荐中,并利用无监督深度神经网络框架生成个性化行程。为了学习行程中POIs之间的语义顺序信息,Gao等(2021)提出了一个结合地理和时间信息的编码-解码框架。为了捕捉行程中POI转换模式的语义,Zhou, Wu等(2020)开发了基于RNN的行程生成方法,使用轨迹-轨迹深度神经网络(Ma等,2022)。尽管现有方法在推荐结果上取得了不错的成绩,但在行程推荐中仍然存在以下挑战:
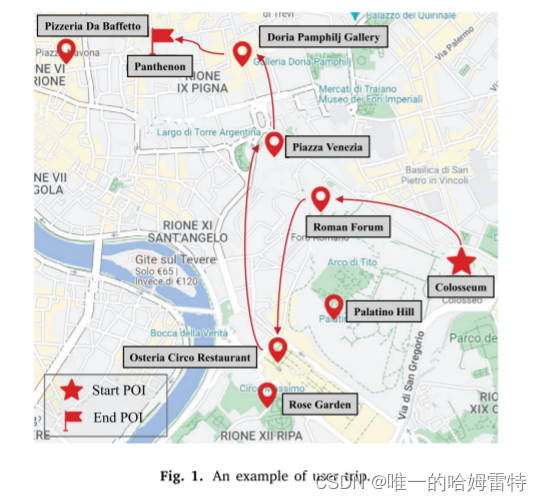
首先,行程推荐是一个动态过程,地理信息和用户偏好会随时间变化。为了说明这一点,给出了图1中的一个示例。在参观了“Colosseum”和“Roman Forum”之后,长时间的步行可能会让游客感到疲惫并改变其偏好。与附近的POI“Palatino Hill”相比,该用户更倾向于选择一家餐厅(例如“Pizzeria Da Baffetto”或“Osteria Circo Restaurant”)进行晚餐和休息。同时,受当前地理位置的影响,他/她决定访问离“Roman Forum”更近的“Osteria Circo Restaurant”。因此,在行程推荐中获取实时信息并根据用户当前的上下文信息推荐下一个POI可以帮助提高推荐的准确性。
其次,当前POI的选择对后续POIs的选择有重要影响。大多数个性化行程推荐方法(Gao等,2019)关注即时奖励,即让用户访问推荐的POIs,而忽略了推荐POIs对长期奖励的影响。例如,在参观了POI“Osteria Circo Restaurant”之后,尽管POI“Rose Garden”比POI“Piazza Venezia”更近,用户仍然选择访问POI“Piazza Venezia”,因为在参观了POI“Piazza Venezia”之后,他/她可以参观附近的POIs“Doria Pamphilj Gallery”和“Pantheon”,从而获得更好的旅行体验。因此,从长远来看,考虑未来奖励可以帮助用户享受更好的旅行体验。
第三,虽然大多数行程推荐方法侧重于提高推荐的准确性,但推荐质量的其他重要方面(如行程多样性和行程受欢迎程度)通常被忽视。行程中POIs的多样性和受欢迎程度也会影响游客的旅行体验。由于游客通常希望在同一行程中探索不同类别的POIs,一个包含类别过少的POI的行程会让游客感到无聊。然而,绝大多数行程推荐方法(Fu等,2022;Sarkar等,2020;Zhou等,2021)关注POI相关性,并在多样性和新颖性方面付出了显著代价。它们通常根据用户访问频率推荐POI类别,这将使行程中的POI类别非常单一,降低游客的旅行体验质量。
为了解决上述挑战,本文提出了一种多目标强化学习方法用于行程推荐(称为MORL-Trip)。具体来说,我们将个性化行程推荐建模为马尔可夫决策过程(MDP),并利用基于强化学习的方法自动训练和更新最优推荐策略。首先,我们设计了序列级、地理级和顺序级表示来学习更准确的用户实时上下文。然后,我们提出创建一个包含准确性、受欢迎程度和多样性奖励的奖励函数,以做出更准确、受欢迎和多样的推荐。最后,我们利用深度确定性策略梯度(DDPG)算法训练所提出的模型。总之,本文的贡献如下:
- 我们将行程推荐任务建模为MDP,用户偏好基于实时上下文是复杂且动态的,并实现了一个RL框架来形成整个过程。
- 我们通过设计新的状态表示和奖励函数扩展了MDP框架用于个性化行程推荐。通过这些扩展,MORL-Trip可以做出更准确、受欢迎和多样的行程推荐。
- 在公共数据集上进行了综合实验评估,结果表明MORL-Trip在行程推荐中能够持续优于基线方法。
2. Related work
2.1. Trip recommender systems
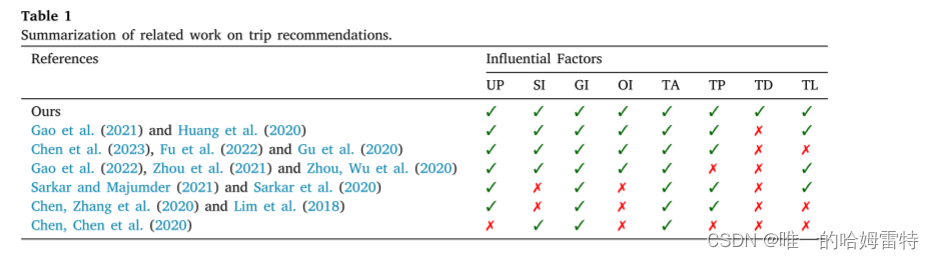
行程推荐系统尝试设计由一些有序 POI 组成的行程,在预定义的约束下最大限度地提高用户满意度。 个性化行程推荐是一项复杂的任务,因为它需要考虑很多因素,如用户偏好(UP)、顺序信息(SI)、地理信息(GI)、订单信息(OI)、行程准确度(TA)、行程流行度(TA)等。 TP)、行程多样性(TD)和行程长度(TL)。 表1概述了个性化旅行推荐的相关工作,并展示了我们的论文与现有研究之间的差异。 在这些因素中,用户偏好对于设计个性化出行起着决定性作用。 早期的工作(Yahi et al., 2015)要求用户明确说明他们对旅行推荐的偏好。 然而,这个过程非常耗时且不方便。 为了解决这个问题,一些研究引入POI类别信息来计算用户偏好。 这些研究的想法是,用户对 POI 类别的偏好与用户访问此类 POI 的频率或在此类 POI 上花费的时间有关。 例如,Lim 等人。 (2018)提出了基于类别的用户偏好的旅行推荐概念,其中访问持续时间也通过基于类别的用户偏好来预测,以更准确地反映现实生活。 布里兰特等人。 (2015) 引入 TripBuilder 算法来规划包含 POI 的个性化旅行,根据 POI 类别最大化用户偏好。 然而,如果用户没有访问过训练集中某个类别的任何POI,则上述方法无法为该用户推荐个性化旅行。
2.2. Deep reinforcement learning for recommendations
3. Background and motivation
3.1. Preliminaries



3.2. Motivation
目前研究方法的不足

强化学习在推荐系统中展示了其神奇之处,自然适合动态跟踪用户偏好变化。因此,我们通过强化学习框架来形式化行程推荐任务。同时,与仅专注于提高推荐准确性的现有行程推荐方法不同,我们提出的方法还考虑了行程多样性和行程热度。在这个多目标问题中,下一个访问的 POI 被视为一个变量,并且奖励值将根据 POI 的准确性、行程热度和行程多样性来计算。我们将推荐行程的长度限制在实际行程的长度内。
4. The MORL-Trip approach
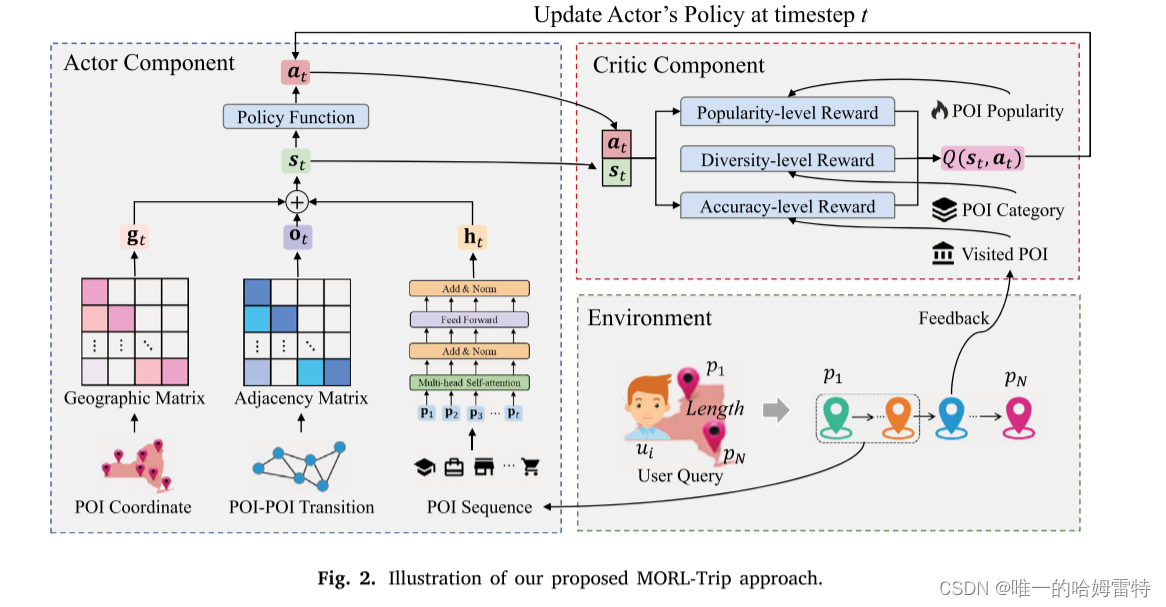
大多数现有的行程推荐方法尝试以具有多重约束的旅行序列形式推荐一组POI。然而,它们忽略了用户当前状态对选择下一个POI的影响,无法跟踪用户偏好的动态变化。为了建模用户偏好变化并考虑个性化行程的准确性、热度和多样性,我们提出了一种多目标强化学习方法。
如图2所示,MORL-Trip方法由演员(Actor)和评论者(Critic)组件组成。演员组件旨在根据用户的实时状态适当地生成下一个POI。评论者组件用于评估演员推荐策略的偏好。
4.1. The architecture of actor framework
Actor组件用于根据用户当前状态获取最合适的POI。构建Actor组件的关键在于获取用户的状态。在本文中,我们考虑了用户的历史旅行记录、地理信息和POI-POI转移模式,以设计一个全面的状态表示。这种用户状态表示是通过结合序列级、地理级和顺序级状态表示来计算的。
4.1.1. Sequence-level state representations
Transformer 已广泛应用于顺序或时间序列数据,其中每个元素通过自注意力机制由其他元素及其自身表示(Fu et al., 2020)。 我们使用 Transformer Encoder 来学习用户之前 POI 访问序列的顺序特征。 具体来说,给定一个 POI 访问序列 𝑃1∶𝑡 = {𝑝1, 𝑝2,…, 𝑝𝑡}, 𝐏𝑡 = {𝐩1, 𝐩2,…, 𝐩𝑡} 是序列表示,𝐩𝑖 是维度 𝑑 的 POI 嵌入向量,由 Word2vec 计算 模型(Mikolov et al., 2013; Ye et al., 2021),最初是为词嵌入而设计的。 为了利用 POI 顺序信息,我们通过串联运算符将位置嵌入(Vaswani 等人,2017)进一步融合到 POI 嵌入中。
4.1.2. Geography-level state representations
用户当前位置与其他 POI 之间的地理关系对于选择下一个 POI 起着重要作用。 用户倾向于前往距离当前位置不远的 POI 进行观光游览。 因此,我们设计地理级状态表示来捕获当前位置的地理信息。 地理级状态表示的设计基于这样的直觉:POI距离当前位置越远,被访问的概率越低。


4.1.3. Order-level state representations
除了地理因素外,POI-POI的公交模式也会影响用户对下一个POI的选择。 流行且有吸引力的参观模式可能涉及商业活动、商业展位、表演和展览,这可以改善用户体验。 因此,从一个访问过的 POI 到其他 POI 的转移概率是一种非均匀分布。 订单级状态表示的设计是根据直觉,即POI与当前位置之间的转移概率越大,该POI被访问的概率就越大。

4.1.4. Recommendation policy learning

4.2. The architecture of critic framework

4.3. Reward decomposition

4.3.1. Accuracy-level reward

4.3.2. Popularity-level reward

4.3.3. Diversity-level reward

4.4. Training algorithm
MORL-Trip 旨在联合优化与用户满意度密切相关的三个相互冲突的目标。 我们设计了一个复合奖励函数,能够计算这三个目标,即 POI 相关性、旅行受欢迎程度和旅行多样性。 我们还建议使用顺序信息、地理信息和顺序信息来增强状态表示,以从实时位置了解用户的上下文。 考虑到高维和连续动作空间的问题,我们采用深度确定性策略梯度(DDPG)来训练演员-评论家网络。 DDPG在DPG的基础上结合了DQN的概念。 具体来说,Critic 是通过最小化以下损失函数来训练的



这篇关于Multi-objective reinforcement learning approach for trip recommendation的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







