本文主要是介绍十六、强化学习-Reinforcement Learning,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
强化学习(Reinforcement Learning):
- 机器学习的一个分支:监督学习、无监督学习、强化学习
- 强化学习的思路和人比较类似,是在实践中学习
- 比如学习走路,如果摔倒了,那么我们大脑后面会给一个负面的奖励值 => 这个走路姿势不好;如果后面正常走了一步,那么大脑会给一个正面的奖励值 => 这是一个好的走路姿势
- 与监督学习的区别,没有监督学习已经准备好的训练数据输出值,强化学习只有奖励值,但是这个奖励值和监督学习的输出值不一样,它不是事先给出的,而是延后给出的(比如走路摔倒)
- 与非监督学习的区别,在非监督学习中既没有输出值也没有奖励值的,只有数据特征,而强化学习有奖励值(为负是为惩罚),此外非监督学习与监督学习一样,数据之间也都是独立的,没有强化学习这样的前后依赖关系
- 可以应用于不同领域:神经科学、心理学、计算机科学、工程领域、数学、经济学等

强化学习的特点:
- 没有监督数据、只有奖励信号
- 奖励信号不一定是实时的,很可能是延后的,甚至延后很多
- 时间(序列)是一个重要因素
- 时间(序列)是一个重要因素
- 强化学习有广泛的应用:游戏AI,推荐系统,机器人仿真,投资管理,发电站控制
强化学习与机器学习:
- 强化学习没有教师信号,也没有label,即没有直接指令告诉机器该执行什么动作
- 反馈有延时,不能立即返回
- 输入数据是序列数据,是一个连续的决策过程
比如AlphaGo下围棋的Agent,可以不使用监督学习:
- 请一位围棋大师带我们遍历许多棋局,告诉我们每个位置的最佳棋步,这个代价很贵expensive
- 很多情况下,没有最佳棋步,因为一个棋步的好坏依赖于其后的多个棋步
- 使用强化学习,整个过程唯一的反馈是在最后(赢or输)
基本概念:
- 个体,Agent,学习器的角色,也称为智能体
- 环境,Environment,Agent之外一切组成的、与之交互的事物
- 动作,Action,Agent的行为
- 状态,State,Agent从环境获取的信息
- 奖励,Reward,环境对于动作的反馈
- 策略,Policy,Agent根据状态进行下一步动作的函数
- 状态转移概率,Agent做出动作后进入下一状态的概率
四个重要的要素:状态(state)、动作(action)、策略(policy)、奖励(reward)
强化学习:
- RL考虑的是个体(Agent)与环境(Environment)的交互问题
- 目标是找到一个最优策略,使Agent获得尽可能多的来自环境的奖励
- 比如赛车游戏,游戏场景是环境,赛车是Agent,赛车的位置是状态,对赛车的操作是动作,怎样操作赛车是策略,比赛得分是奖励
- 很多情况下,Agent无法获取全部的环境信息,而是通过观察(Observation)来表示环境(environment),也就是得到的是自身周围的信息
- 奖励(Reward)
R t R_t Rt是信号的反馈,是一个标量,它反映个体在t时刻做得怎么样,个体的工作就是最大化累计奖励,强化学习假设是,所有问题解决都可以被描述成最大化累积奖励 - 序列决策(Sequential Decision Making)
目标:选择一定的行为系列以最大化未来的总体奖励
这些行为可能是一个长期的序列
奖励可能而且通常是延迟的
有时候宁愿牺牲短期奖励,从而获取更多的长期奖励 - 个体与环境的交互(Agent & Environment)
从个体的视角:
在 t时刻,Agent可以:有一个对于环境的观察评估 Q t Q_t Qt,做出一个行为 A t A_t At,从环境得到一个奖励信号 R t + 1 R_{t+1} Rt+1
环境可以:接收个体的动作 A t A_t At,更新环境信息,同时使得个体可以得到下一个观测 Q t + 1 Q_{t+1} Qt+1,给个体一个奖励信号 R t + 1 R_{t+1} Rt+1

QLearning:
- Q函数,也称为动作值函数,有两个输入:「状态」和「动作」,它将返回在这个状态下执行该动作的未来奖励期望
- 将agent随机放在任一房间内,每打开一个房门返回一个reward
- 根据房间之间连通性的关系,可以得到Reward矩阵(R矩阵)
- 可以把 Q 函数视为一个在 Q-table 上滚动的读取器
Q-learning是典型的基于价值(Value)函数的强化学习方法
其中Q是一个数值(即价值value),在初始化时可能被赋予一个任意数值
在迭代时刻t,我们有状态 S t S_t St ,此时代理做出动作 α t \alpha_t αt ,然后得到奖励 γ t \gamma_t γt,从而进入到一个更新的状态 S t + 1 S_{t+1} St+1,然后对Q值进行更新,更新公式为

使用QLearning:
- 初始化Q表,用于记录状态-动作对的值,每个episode中的每一步都会根据公式更新一次Q表
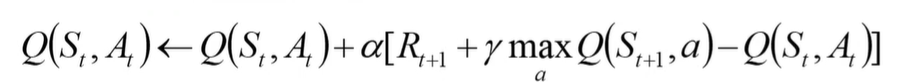
- 为了简便,将学习率 设为1,更新公式为:
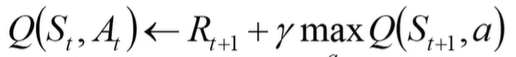
当前状态s的最大将来奖励等于下一状态 s’ 的最大将来奖励乘以折扣因子

例1:迷宫问题
迷宫为5个房间(实际可以为N个房间),房间与房间之间通过门连接,编号0到4,5号是房子外边,即我们想要达到的终点
将AI随机放在任一房间内,如何找到终点的路径



Qlearning:
一个(s, a)a对应一个Q值,可以把Q值看作一个很大的表格
横列代表s,纵列代表a,数值为Q值
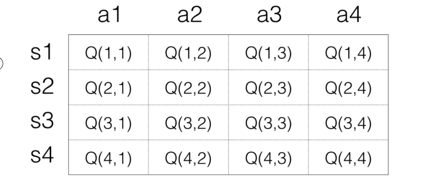

代码
# 模拟迷宫问题
import numpy as np
GAMMA = 0.8
# 动作价值函数
Q = np.zeros((6,6))
R=np.asarray([[-1,-1,-1,-1,0,-1],[-1,-1,-1,0,-1,100],[-1,-1,-1,0,-1,-1],[-1,0, 0, -1,0,-1],[0,-1,-1,0,-1,100],[-1,0,-1,-1,0,100]])# 取每一行的最大值
def getMaxQ(state):print(state)# 通过选取最大动作值来进行最优策略学习return max(Q[state, :])# QLearning函数
def QLearning(state):# 选择的动作curAction = None# 0-5的节点for action in range(6):if(R[state][action] == -1):Q[state, action] = 0else:curAction = action# 选择动作最大的Q[state, action] = R[state][action] + GAMMA * getMaxQ(curAction)for count in range(1000):# 0-5的节点for i in range(6):QLearning(i)
# 显示保留小数点后一位
np.set_printoptions(precision=1)
print(Q/5)

这篇关于十六、强化学习-Reinforcement Learning的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







