mae专题


密文域可逆信息隐藏与掩码自动编码器(MAE)
原文题目:Reversible data hiding in encrypted images based on pixel-level masked autoencoder and polar code Source: Signal Processing Authors: Zhangpei Cheng, Kaimeng Chen , Qingxiao Guan 发表年份:2024年
将MAE方法用于reflacx数据集--MMpretrain/slurm
MAE—reflacx 问题问题一 === 对数据集reflacx的了解问题二 === MAE实现的是有监督,还是无监督任务问题三 === 实验流程问题四 === 实验目的 一、从github上fork我师兄的项目30min(github账号的注册什么的,可以去参考b站)1.1 点开下面这个链接1.2 看到页面的上方,跟随我们的小兔子fork一下1.3 根据这个指引,填好之后,点击绿色的Cr
NeuralForecast VanillaTransformer MAE损失函数
NeuralForecast VanillaTransformer MAE损失函数 flyfish nn.L1Loss() 和 自定义的class MAE(BasePointLoss): 在本质上都是计算 Mean Absolute Error (MAE),但是它们有一些不同之处,主要在于定制化和功能上的差异。 写一个自定义的MAE完整示例代码 import mathfrom typing

基于项目的协同过滤推荐算法单机版代码实现(包含输出电影-用户评分矩阵模型、项目相似度、推荐结果、平均绝对误差MAE)
基于项目的协同过滤推荐算法单机版代码实现(包含输出电影-用户评分矩阵模型、项目相似度、推荐结果、平均绝对误差MAE) 一、开发工具及使用技术 MyEclipse10、jdk1.7、movielens数据集。 二、实现过程 1、定义电影-用户评分矩阵。通过二维数组存放电影-用户评分数据,代码如下图: 2、计算电影之间的相似度。采用余弦算法计算电影之间的相似度,代码如下图: 3、定

基于用户的协同过滤推荐算法单机版代码实现(包含输出用户-评分矩阵模型、用户间相似度、最近邻居、推荐结果、平均绝对误差MAE、查准率、召回率)
基于用户的协同过滤推荐算法单机版代码实现(包含输出用户-评分矩阵模型、用户间相似度、最近邻居、推荐结果、平均绝对误差MAE、查准率、召回率) 一、开发工具及使用技术 MyEclipse10、jdk1.7、mahout API、movielens数据集。 二、实现过程 1、定义用户-电影评分矩阵: /** * 用户-电影评分矩阵工具类 */ public class DataMo
残差平方和(RSS)、均方误差(MSE)、均方根误差(RMSE)、平均绝对误差(MAE)
残差平方和(RSS) 等同于SSE(误差项平方和) 实际值与预测值之间差的平方之和。 MSE: Mean Squared Error 均方误差是RSS的期望值(或均值); MSE可以评价数据的变化程度,MSE的值越小,说明预测模型描述实验数据具有更好的精确度。 RMSE 均方根误差:均方根误差是均方误差的算术平方根 MAE :Mean Absolute Error 平均绝对误差是绝对

【科研】常用的实验结果评价指标(2) —— MAE 是什么? !
了解MAE 提示:先说概念,后续再陆续上代码 文章目录 了解MAE前言一、MAE 基本概念1. MAE 是什么?2. MAE 的起源3. MAE 的计算公式 二、MAE的适用场景是什么?三、MAE 的劣势,或 不适用于那些场景或者数据?四、MAE的取值特点(取值范围) 前言 各类论文的实验结果中经常会有MAE作为评价指标,本篇就是为了搞清楚MAE究竟是什么,什么时候

让 计算机 将 数学 公式 表达式 的计算过程绘制出来 【mathematical-expression(MAE)】
目录 文章目录 目录介绍开始实战引入数学表达式计算库引入流程图代码生成库开始进行生成 介绍 大家好 今天我们来分享一个新知识,将数学表达式的整个计算过程,以及计算繁多结果在 Java 中绘制出来,计算机中的数学表达式计算的功能很常见了,但是今天我们要使用一个工具,它可以将 整个计算过程 使用 Java 绘制成为 mermaid 的流程图!!! 开始实战 引入数学表

当CV遇上transformer(二)MAE模型及源码分析
当CV遇上transformer(二)MAE模型 2020年10月,Dosovitskiy首次将纯Transformer的网络结构应用于图像分类任务中(ViT),并取得了当时最优的分类效果,其研究成果是Transformer完全替代标准卷积的首次尝试。大神何恺明在2021年11月基于(ViT)架构,提出了用于CV领域的自监督学习模型MAE(Masked Autoencoders)。MAE想法很简
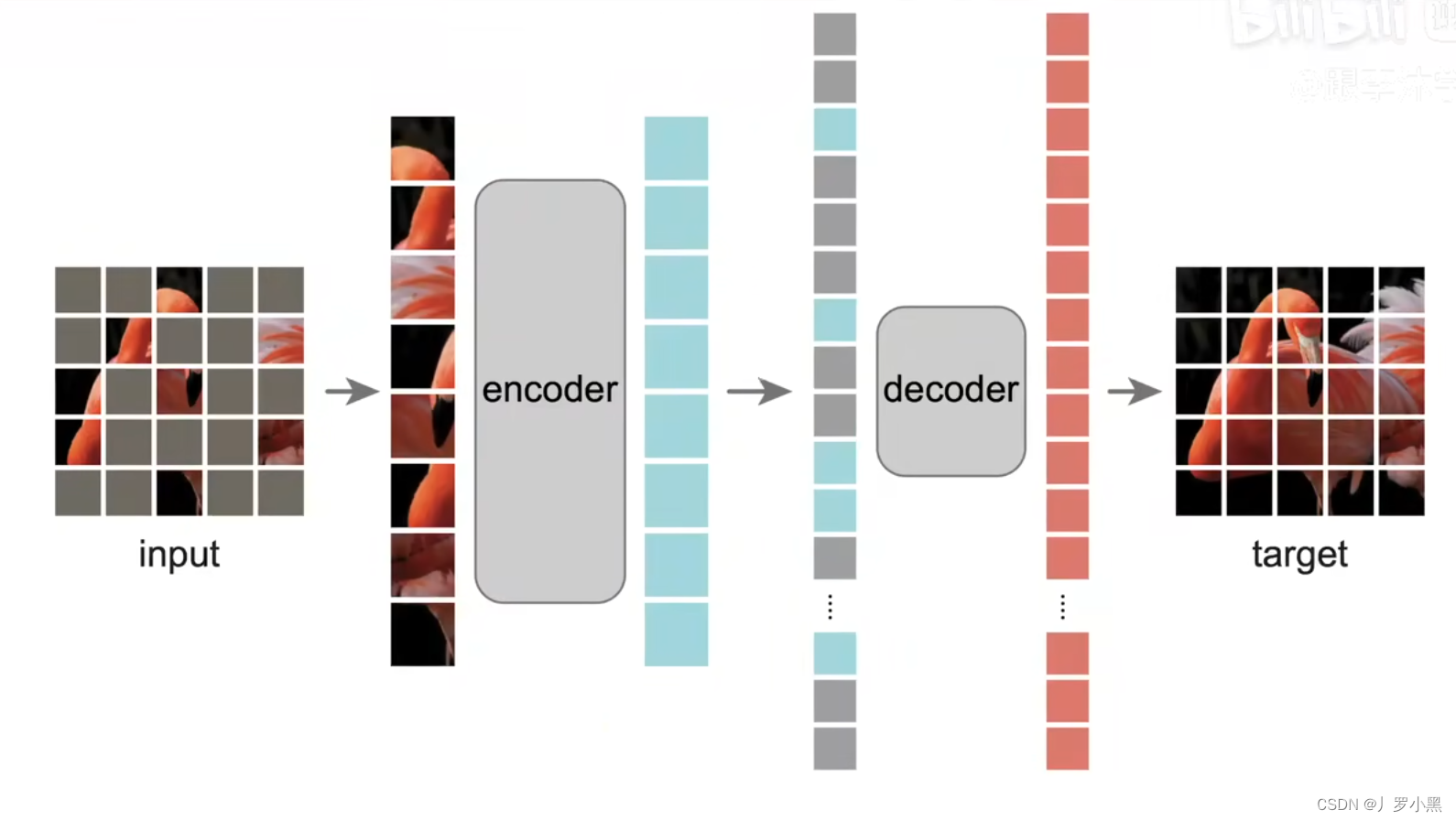
场景文本检测识别学习 day06(Vi-Transformer论文精读、MAE论文阅读)
Vi-Transformer论文精读 在NLP领域,基于注意力的Transformer模型使用的非常广泛,但是在计算机视觉领域,注意力更多是和CNN一起使用,或者是单纯将CNN的卷积替换成注意力,但是整体的CNN 架构没有发生改变VIT说明,纯Transformer不使用CNN也可以在视觉领域表现很好,尤其是当我们在大规模数据集上做预训练,再去小数据集上做微调,可以获得跟最好的CNN相媲美的结果
人工智能中两个较为常见的评估模型性能指标(EVS、MAE)
1、解释方差(EVS) 官方社区链接:sklearn.metrics.explained_variance_score-scikit-learn中文社区 explained_variance_score是一个用于评估回归模型性能的指标,它衡量的是模型预测值与实际值之间关系的密切程度。具体来说,解释方差分数表示模型预测值中有多少方差可以通过实际数据的方差来解释。 解释方差(Explained

【MATLAB源码-第184期】基于matlab的FNN预测人民币美元汇率 输出预测图误差图RMSE R2 MAE MBE等指标
操作环境: MATLAB 2022a 1、算法描述 前馈神经网络(Feedforward Neural Network, FNN)是最简单也是应用最广泛的人工神经网络之一。在许多领域,尤其是数据预测方面,FNN已经展现出了卓越的性能和强大的适应性。 一、FNN基本结构与原理 前馈神经网络的基本结构包括输入层、一个或多个隐藏层和输出层。每层包含若干个神经元,每个神经元与下一层的每个神经元都
计算psnr ssim niqe fid mae lpips等指标的代码
以下代码仅供参考,路径处理最好自己改一下 # Author: Wu# Created: 2023/8/15# module containing metrics functions# using package in https://github.com/chaofengc/IQA-PyTorchimport torchfrom PIL import Imageimport nump

【论文精读】MAE:Masked Autoencoders Are Scalable Vision Learners 带掩码的自动编码器是可扩展的视觉学习器
系列文章目录 【论文精读】Transformer:Attention Is All You Need 【论文精读】BERT:Pre-training of Deep Bidirectional Transformers for Language Understanding 【论文精读】VIT:vision transformer论文 文章目录 系列文章目录一、前言二、文章概览(一)研究背

MAE——「Masked Autoencoders Are Scalable Vision Learners」
这次,何凯明证明让BERT式预训练在CV上也能训的很好。 论文「Masked Autoencoders Are Scalable Vision Learners」证明了 masked autoencoders(MAE) 是一种可扩展的计算机视觉自监督学习方法。 这项工作的意义何在? 讨论区 Reference MAE 论文逐段精读【论文精读】_哔哩哔哩_bilibili //
MAE实战:使用MAE提高主干网络的精度(一)
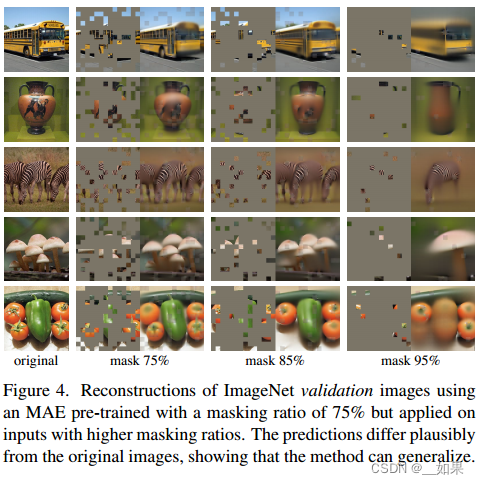
摘要 MAE已经出来有几年了,很多人还不知道怎么去使用,本文通过两个例子说明一下。分两部分,一部分介绍一个简单的例子,让大家了解MAE训练的流程。一部分是一个新的模型,让大家了解如何将自己的模型加入MAE。 论文标题: Masked Autoencoders Are Scalable Vision Learners 论文地址:https://arxiv.org/abs/2111.06377

PyTorch随笔 - MAE(Masked Autoencoders)推理脚本
MAE推理脚本: 需要安装:pip install timm==0.4.5需要下载:mae_visualize_vit_base.pth,447M 源码: #!/usr/bin/env python# -- coding: utf-8 --"""Copyright (c) 2022. All rights reserved.Created by C. L. Wang on 202

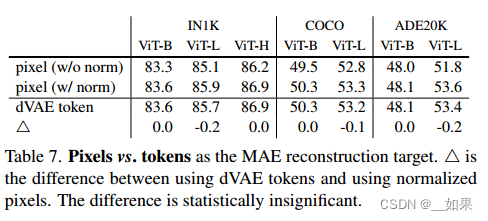
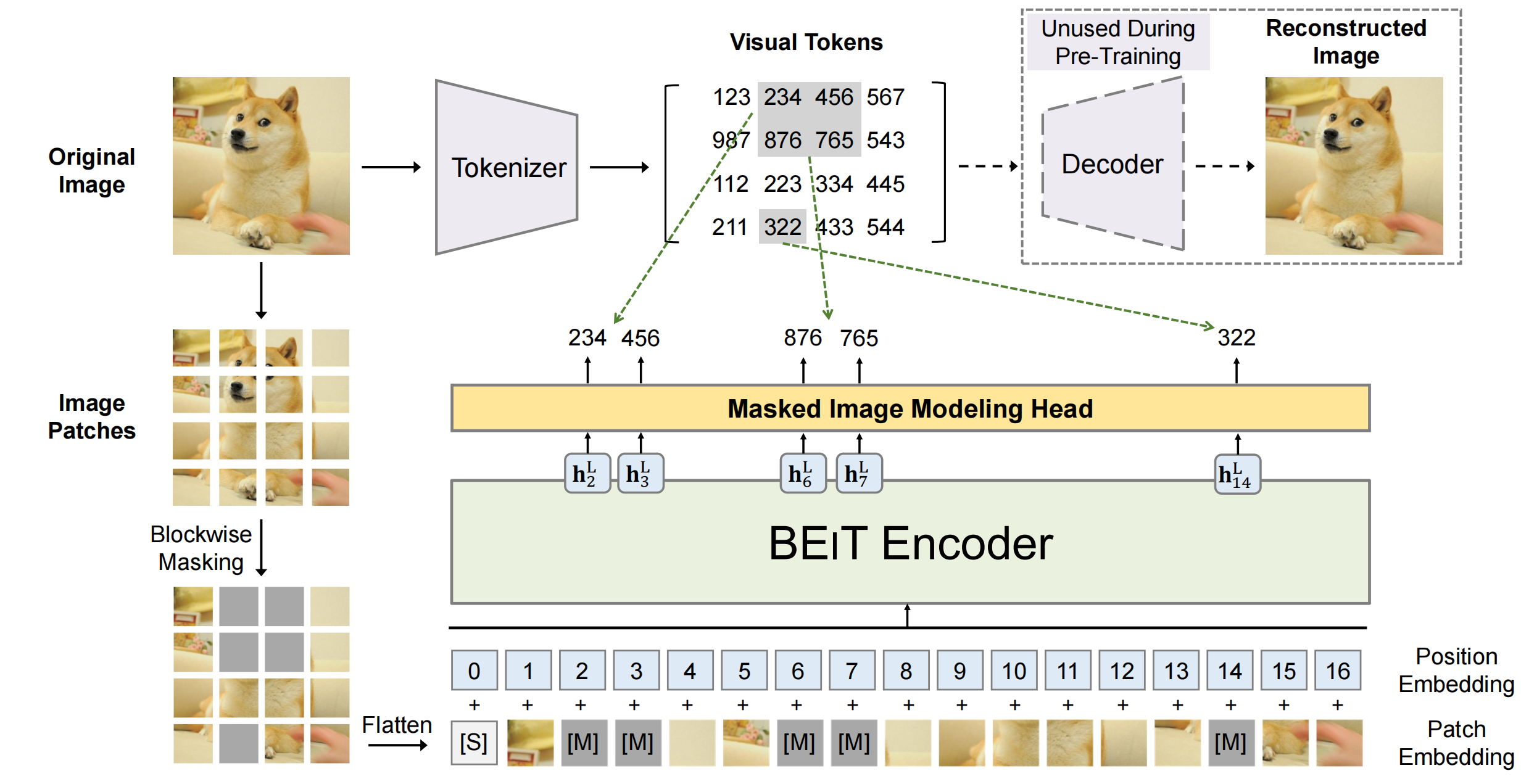
DEiT中如何处理mask数据的?与MAE的不同
在DeiT里面,是通过mask的方式,将mask+unmasked的patches输出进ViT中,但其实在下游任务输入的patches还是和训练时patches的数量N是一致的(encoder所有的patches)。 而MAE是在encoder中只encoder未被mask的patches 通过什么方式支持的? 在处理文本时,可以根据最长的句子在批次中动态padding或截断长句子而

ConvNeXt V2:用MAE训练CNN
论文名称:ConvNeXt V2: Co-designing and Scaling ConvNets with Masked Autoencoders 发表时间:CVPR2023 code链接:代码 作者及组织: Sanghyun Woo,Shoubhik Debnath来自KAIST和Meta AI。 前言 ConvNextV2是借助MAE的思想来训练ConvnextV1。关于Conv

ai讲师老师人工智能培训讲师计算机视觉讲师叶梓:计算机视觉领域的自监督学习模型——MAE-11
接上一篇 P24P25 MAE的编码器部分 n Our encoder is a ViT but applied only on visible, unmasked patches . n Just as in a standard ViT , our encoder embeds patches by a linear projection with added pos

带掩码的自编码器MAE详解和代码实现
监督学习是训练机器学习模型的传统方法,它在训练时每一个观察到的数据都需要有标注好的标签。如果我们有一种训练机器学习模型的方法不需要收集标签,会怎么样?如果我们从收集的相同数据中提取标签呢?这种类型的学习算法被称为自监督学习。这种方法在自然语言处理中工作得很好。一个例子是BERT¹,谷歌自2019年以来一直在其搜索引擎中使用BERT¹。不幸的是,对于计算机视觉来说,情况并非如此。 Facebook

【论文解读】SiamMAE:用于从视频中学习视觉对应关系的 MAE 简单扩展
来源:投稿 作者:橡皮 编辑:学姐 论文链接:https://siam-mae-video.github.io/resources/paper.pdf 项目主页:https://siam-mae-video.github.io/ 1.背景 时间是视觉学习背景下的一个特殊维度,它提供了一种结构,在该结构中,可以感知顺序事件、学习因果关系、跟踪物体在空间中的移动,以及预测未来事件