本文主要是介绍论文精读--MAE,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
BERT在Transformer的架构上进行了掩码操作,取得了很好的效果。如果对ViT进行掩码操作呢?

分成patch后灰色表示遮盖住,再将可见的patch输入encoder,把encoder得到的特征拉长放回原本在图片中的位置,最后由decoder去重构图片

图二的图片来自ImageNet,没有经过训练,是验证集。左边一列是mask了80%的图片,中间是得到的结果,右边是原图

来自COCO数据集,同上
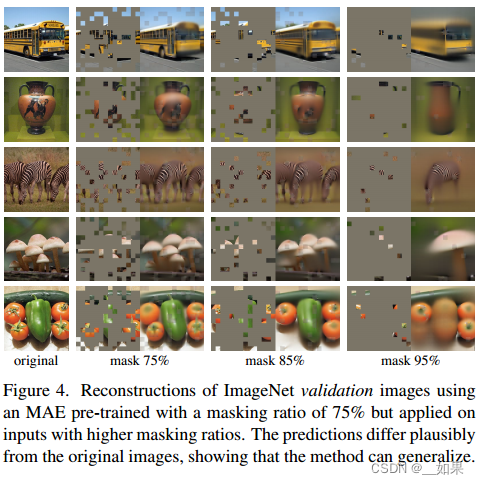
对同一张图片遮盖不同比例的结果,最右边遮盖了95%
Abstract
This paper shows that masked autoencoders (MAE) are scalable self-supervised learners for computer vision. Our MAE approach is simple: we mask random patches of the input image and reconstruct the missing pixels. It is based on two core designs. First, we develop an asymmetric encoder-decoder architecture, with an encoder that operates only on the visible subset of patches (without mask tokens), along with a lightweight decoder that reconstructs the original image from the latent representation and mask tokens. Second, we find that masking a high proportion of the input image, e.g., 75%, yields a nontrivial and meaningful self-supervisory task. Coupling these two designs enables us to train large models efficiently and effectively: we accelerate training (by 3× or more) and improve accuracy. Our scalable approach allows for learning high-capacity models that generalize well: e.g., a vanilla ViT-Huge model achieves the best accuracy (87.8%) among methods that use only ImageNet-1K data. Transfer performance in downstream tasks outperforms supervised pretraining and shows promising scaling behavior
翻译:
本文证明了掩码自编码器(MAE)是一种可扩展的计算机视觉自监督学习算法。我们的MAE方法很简单:我们屏蔽输入图像的随机patch并重建缺失的像素。它基于两个核心设计。首先,我们开发了一个非对称编码器-解码器架构,其中一个编码器仅对patch的可见子集(没有掩码令牌)进行操作,以及一个轻量级解码器,该解码器从潜在表示和掩码token重建原始图像。其次,我们发现掩盖输入图像的高比例,例如75%,产生了一个重要的和有意义的自我监督任务。这两种设计的结合使我们能够高效地训练大型模型:我们加速了训练(3倍或更多)并提高了准确性。我们的可扩展方法允许学习泛化良好的大容量模型:例如,在仅使用ImageNet-1K数据的方法中,vanilla ViT-Huge模型达到了最好的准确率(87.8%)。下游任务的迁移性能优于监督预训练,并显示出有希望的缩放行为
总结:
随机盖住图片中的一些patch,再去重构被盖住的像素
非对称编码器-解码器结构,编码器只作用在可见的patch上
遮盖太少效果不明显,遮盖大量patch可以迫使模型学习更好,并且学习更快
ViT论文中提到自监督学习方面仍有不足,而MAE解决了这个问题
在迁移学习上表现也很好
Introduction
Deep learning has witnessed an explosion of architectures of continuously growing capability and capacity[33, 25, 57]. Aided by the rapid gains in hardware, models today can easily overfit one million images [13] and begin to demand hundreds of millions of—often publicly inaccessible—labeled images [16].
This appetite for data has been successfully addressed in natural language processing (NLP) by self-supervised pretraining. The solutions, based on autoregressive language modeling in GPT [47, 48, 4] and masked autoencoding in BERT [14], are conceptually simple: they remove a portion of the data and learn to predict the removed content. These methods now enable training of generalizable NLP models containing over one hundred billion parameters [4].
The idea of masked autoencoders, a form of more general denoising autoencoders [58], is natural and applicable in computer vision as well. Indeed, closely related research in vision [59, 46] preceded BERT. However, despite significant interest in this idea following the success of BERT, progress of autoencoding methods in vision lags behind NLP. We ask: what makes masked autoencoding different between vision and language? We attempt to answer this question from the following perspectives:
翻译:
深度学习见证了能力和容量不断增长的架构的爆炸式增长[33,25,57]。在硬件快速发展的帮助下,今天的模型可以很容易地过拟合一百万张图像[13],并开始需要数亿张通常是公开无法访问的标记图像[16]。
这种对数据的需求已经在自然语言处理(NLP)中通过自监督预训练成功地解决了。基于GPT[47,48,4]中的自回归语言建模和BERT[14]中的掩码自编码的解决方案在概念上很简单:它们删除部分数据并学习预测被删除的内容。这些方法现在可以训练包含超过一千亿个参数的可泛化NLP模型[4]。
掩码自编码器是一种更通用的去噪自编码器[58],它的想法很自然,也适用于计算机视觉。事实上,在BERT之前,在视觉方面就有了密切相关的研究[59,46]。然而,尽管随着BERT的成功,人们对这一想法产生了浓厚的兴趣,但视觉领域的自动编码方法的进展落后于NLP。我们的问题是:是什么让隐藏自动编码在视觉和语言之间有所不同?我们试图从以下几个角度来回答这个问题:
(i) Until recently, architectures were different. In vision, convolutional networks [34] were dominant over the last decade [33]. Convolutions typically operate on regular grids and it is not straightforward to integrate ‘indicators’ such as mask tokens [14] or positional embeddings [57] into convolutional networks. This architectural gap, however, has been addressed with the introduction of Vision Transformers (ViT) [16] and should no longer present an obstacle.
翻译:
(i)直到最近,架构是不同的。在视觉领域,卷积网络[34]在过去十年中占据主导地位[33]。卷积通常在规则网格上运行,将“指标”(如掩码token[14]或位置嵌入[57])集成到卷积网络中并不简单。然而,这种架构上的差距已经通过视觉转换器(ViT)[16]的引入得到了解决,并且不再是一个障碍。
(ii) Information density is different between language and vision. Languages are human-generated signals that are highly semantic and information-dense. When training a model to predict only a few missing words per sentence, this task appears to induce sophisticated language understanding. Images, on the contrary, are natural signals with heavy spatial redundancy—e.g., a missing patch can be recovered from neighboring patches with little high-level understanding of parts, objects, and scenes. To overcome this difference and encourage learning useful features, we show that a simple strategy works well in computer vision: masking a very high portion of random patches. This strategy largely reduces redundancy and creates a challenging selfsupervisory task that requires holistic understanding beyond low-level image statistics. To get a qualitative sense of our reconstruction task, see Figures 2 – 4.
翻译:
(ii)语言和视觉的信息密度不同。语言是人类产生的具有高度语义和信息密集的信号。当训练一个模型来预测每句话中只缺几个单词时,这项任务似乎可以诱导复杂的语言理解。相反,图像是具有大量空间冗余的自然信号。一个缺失的patch可以从邻近的patch中恢复,而对局部、对象和场景几乎没有高层次的理解。为了克服这种差异并鼓励学习有用的特征,我们展示了一个简单的策略在计算机视觉中很有效:掩盖非常高比例的随机patch。这种策略在很大程度上减少了冗余,并创建了一个具有挑战性的自监督任务,该任务需要超越低级图像统计的整体理解。要对我们的重建任务有一个定性的认识,请参见图2 - 4。
总结:
文字语音信息多,图片语义信息少,少量掩码对图片影响不大,甚至可以通过简单的插值还原
(iii) The autoencoder’s decoder, which maps the latent representation back to the input, plays a different role between reconstructing text and images. In vision, the decoder reconstructs pixels, hence its output is of a lower semantic level than common recognition tasks. This is in contrast to language, where the decoder predicts missing words that contain rich semantic information. While in BERT the decoder can be trivial (an MLP) [14], we found that for images, the decoder design plays a key role in determining the semantic level of the learned latent representations.
翻译:
(iii)自编码器的解码器,将潜在表示映射回输入,在重建文本和图像之间起着不同的作用。在视觉上,解码器重建像素,因此其输出的语义水平低于普通识别任务。这与语言相反,在语言中,解码器预测包含丰富语义信息的缺失单词。虽然在BERT中,解码器可能是微不足道的(一个MLP)[14],但我们发现,对于图像,解码器的设计在决定学习到的潜在表征的语义水平方面起着关键作用。
总结:
在nlp中,decoder还原的是词或句子,语义信息丰富,因此只需要简单的MLP;而图片的decoder还原的是像素,语义信息少,需要精心设计decoder。例如做语义分割任务时,需要转置的卷积神经网络做一个比较大的decoder。(在较高的语义层次,信息往往更加抽象,解码器不需要关注字或词层面的细节,因此简化的结构就足够了)
Driven by this analysis, we present a simple, effective, and scalable form of a masked autoencoder (MAE) for visual representation learning. Our MAE masks random patches from the input image and reconstructs the missing patches in the pixel space. It has an asymmetric encoderdecoder design. Our encoder operates only on the visible subset of patches (without mask tokens), and our decoder is lightweight and reconstructs the input from the latent representation along with mask tokens (Figure 1). Shifting the mask tokens to the small decoder in our asymmetric encoder-decoder results in a large reduction in computation.
Under this design, a very high masking ratio (e.g., 75%) can achieve a win-win scenario: it optimizes accuracy while allowing the encoder to process only a small portion (e.g., 25%) of patches. This can reduce overall pre-training time by 3× or more and likewise reduce memory consumption, enabling us to easily scale our MAE to large models.
翻译:
在此分析的推动下,我们提出了一种简单、有效、可扩展的掩码自编码器(MAE)用于视觉表示学习。我们的MAE从输入图像中屏蔽随机patch,并在像素空间中重建缺失的patch。它具有非对称编解码器设计。我们的编码器仅对patch的可见子集(没有掩码token)进行操作,我们的解码器是轻量级的,可以从潜在表示和掩码token一起重建输入(图1)。将掩码token转移到我们的非对称编码器-解码器中的小型解码器中,可以大大减少计算量。
在这种设计下,非常高的掩蔽比(例如,75%)可以实现双赢:它优化了精度,同时允许编码器只处理一小部分(例如,25%)的patch。这可以将总体预训练时间减少3倍或更多,同样减少内存消耗,使我们能够轻松地将MAE扩展到大型模型。
Our MAE learns very high-capacity models that generalize well. With MAE pre-training, we can train datahungry models like ViT-Large/-Huge [16] on ImageNet-1K with improved generalization performance. With a vanilla ViT-Huge model, we achieve 87.8% accuracy when finetuned on ImageNet-1K. This outperforms all previous results that use only ImageNet-1K data. We also evaluate transfer learning on object detection, instance segmentation, and semantic segmentation. In these tasks, our pre-training achieves better results than its supervised pre-training counterparts, and more importantly, we observe significant gains by scaling up models. These observations are aligned with those witnessed in self-supervised pre-training in NLP [14, 47, 48, 4] and we hope that they will enable our field to explore a similar trajectory.
翻译:
我们的MAE学习非常高容量的模型,泛化得很好。通过MAE预训练,我们可以在ImageNet-1K上训练像ViT-Large/-Huge[16]这样的数据渴求模型,并提高泛化性能。使用普通的ViT-Huge模型,在ImageNet-1K上进行微调时,我们达到了87.8%的准确率。这优于以前仅使用ImageNet-1K数据的所有结果。我们还评估了迁移学习在物体检测、实例分割和语义分割方面的应用。在这些任务中,我们的预训练比有监督的预训练取得了更好的结果,更重要的是,我们通过缩放模型观察到显著的收益。这些观察结果与NLP中自我监督预训练中的观察结果一致[14,47,48,4],我们希望它们将使我们的领域能够探索类似的轨迹。
Related Work
Masked language modeling and its autoregressive counterparts, e.g., BERT [14] and GPT [47, 48, 4], are highly successful methods for pre-training in NLP. These methods hold out a portion of the input sequence and train models to predict the missing content. These methods have been shown to scale excellently [4] and a large abundance of evidence indicates that these pre-trained representations generalize well to various downstream tasks.
翻译:
掩码语言模型与其自回归模型,如BERT[14]和GPT[47,48,4],是NLP中非常成功的预训练方法。这些方法保留输入序列的一部分,并训练模型来预测缺失的内容。这些方法已被证明具有出色的扩展性[4],大量证据表明,这些预训练的表征可以很好地推广到各种下游任务。
Autoencoding is a classical method for learning representations. It has an encoder that maps an input to a latent representation and a decoder that reconstructs the input. For example, PCA and k-means are autoencoders [29]. Denoising autoencoders (DAE) [58] are a class of autoencoders that corrupt an input signal and learn to reconstruct the original, uncorrupted signal. A series of methods can be thought of as a generalized DAE under different corruptions, e.g., masking pixels [59, 46, 6] or removing color channels [70].
Our MAE is a form of denoising autoencoding, but different from the classical DAE in numerous ways.
翻译:
自编码是学习表征的经典方法。它有一个将输入映射到潜在表示的编码器和一个重建输入的解码器。例如,PCA和k-means是自编码器[29]。去噪自编码器(DAE)[58]是一类破坏输入信号并学习重建原始未损坏信号的自编码器。一系列方法可以被认为是不同破坏下的广义DAE,例如,屏蔽像素[59,46,6]或去除颜色通道[70]。我们的MAE是一种去噪的自编码形式,但与经典的DAE有许多不同之处。
总结:
MAE其实也是一种形式上的带去噪的自编码,mask相当于噪音
Masked image encoding methods learn representations from images corrupted by masking. The pioneering work of [59] presents masking as a noise type in DAE. Context Encoder [46] inpaints large missing regions using convolutional networks. Motivated by the success in NLP, related recent methods [6, 16, 2] are based on Transformers [57].
iGPT [6] operates on sequences of pixels and predicts unknown pixels. The ViT paper [16] studies masked patch prediction for self-supervised learning. Most recently, BEiT [2] proposes to predict discrete tokens [44, 50].
翻译:
遮罩图像编码方法从被遮罩损坏的图像中学习表示。[59]的开创性工作将掩蔽作为DAE中的一种噪声类型。上下文编码器[46]使用卷积网络绘制大型缺失区域。受NLP成功的影响,最近的相关方法[6,16,2]都是基于Transformers[57]。
iGPT[6]对像素序列进行操作,并预测未知像素。ViT论文[16]研究了自监督学习的掩码patch预测。最近,BEiT[2]提出预测离散token[44,50]。
Self-supervised learning approaches have seen significant interest in computer vision, often focusing on different pretext tasks for pre-training [15, 61, 42, 70, 45, 17]. Recently, contrastive learning [3, 22] has been popular, e.g., [62, 43, 23, 7], which models image similarity and dissimilarity (or only similarity [21, 8]) between two or more views. Contrastive and related methods strongly depend on data augmentation [7, 21, 8]. Autoencoding pursues a conceptually different direction, and it exhibits different behaviors as we will present.
翻译:
自监督学习方法在计算机视觉领域引起了极大的兴趣,通常关注于预训练的不同任务[15,61,42,70,45,17]。最近,对比学习[3,22]很受欢迎,例如[62,43,23,7],它对两个或多个视图之间的图像相似性和不相似性(或仅相似性[21,8])进行建模。对比和相关方法强烈依赖于数据增强[7,21,8]。自编码追求一个概念上不同的方向,它表现出不同的行为,正如我们将要介绍的。
Approach
Our masked autoencoder (MAE) is a simple autoencoding approach that reconstructs the original signal given its partial observation. Like all autoencoders, our approach has an encoder that maps the observed signal to a latent representation, and a decoder that reconstructs the original signal from the latent representation. Unlike classical autoencoders, we adopt an asymmetric design that allows the encoder to operate only on the partial, observed signal (without mask tokens) and a lightweight decoder that reconstructs the full signal from the latent representation and mask tokens. Figure 1 illustrates the idea, introduced next.
翻译:
我们的掩码自编码器(MAE)是一种简单的自编码方法,可以在给定部分观测值的情况下重建原始信号。像所有的自编码器一样,我们的方法有一个编码器,将观察到的信号映射到潜在表示,以及一个解码器,从潜在表示重建原始信号。与经典的自编码器不同,我们采用非对称设计,允许编码器仅对部分观察到的信号(没有掩码token)进行操作,并采用轻量级解码器,从潜在表示和掩码token重建完整信号。图1说明了下面介绍的思想。
Masking
Following ViT [16], we divide an image into regular non-overlapping patches. Then we sample a subset of patches and mask (i.e., remove) the remaining ones. Our sampling strategy is straightforward: we sample random patches without replacement, following a uniform distribution. We simply refer to this as “random sampling”.
Random sampling with a high masking ratio (i.e., the ratio of removed patches) largely eliminates redundancy, thus creating a task that cannot be easily solved by extrapolation from visible neighboring patches (see Figures 2 – 4). The uniform distribution prevents a potential center bias (i.e., more masked patches near the image center). Finally, the highly sparse input creates an opportunity for designing an efficient encoder, introduced next.
翻译:
根据ViT[16],我们将图像划分为规则的不重叠的小块。然后我们对patch的子集进行采样,并掩码(即删除)剩余的patch。我们的采样策略很简单:我们对随机patch进行采样,不进行替换,遵循均匀分布。我们简单地称之为“随机抽样”。
具有高掩蔽比(即去除斑块的比例)的随机采样在很大程度上消除了冗余,从而创建了一个不能通过从可见的邻近patch外推轻松解决的任务(见图2 - 4)。均匀分布防止了潜在的中心偏差(即在图像中心附近有更多的掩蔽斑块)。最后,高度稀疏的输入为设计高效的编码器创造了机会,下面将介绍。
MAE encoder
Our encoder is a ViT [16] but applied only on visible, unmasked patches. Just as in a standard ViT, our encoder embeds patches by a linear projection with added positional embeddings, and then processes the resulting set via a series of Transformer blocks. However, our encoder only operates on a small subset (e.g., 25%) of the full set.Masked patches are removed; no mask tokens are used.This allows us to train very large encoders with only a fraction of compute and memory. The full set is handled by a lightweight decoder, described next.
翻译:
我们的编码器是一个ViT[16],但只应用于可见的,未遮挡的patch。就像在标准ViT中一样,我们的编码器通过添加位置嵌入的线性投影嵌入patch,然后通过一系列Transformer块处理结果集。然而,我们的编码器只在完整集合的一小部分(例如,25%)上运行。遮罩patch被移除;不使用掩码token。这允许我们只用一小部分的计算和内存训练非常大的编码器。完整的集合由一个轻量级解码器处理,下面将介绍。
MAE decoder
The input to the MAE decoder is the full set of tokens consisting of (i) encoded visible patches, and (ii) mask tokens. See Figure 1. Each mask token [14] is a shared, learned vector that indicates the presence of a missing patch to be predicted. We add positional embeddings to all tokens in this full set; without this, mask tokens would have no information about their location in the image. The decoder has another series of Transformer blocks.
翻译:
MAE解码器的输入是一整套token,由(i)编码的可见patch和(ii)掩码token组成。参见图1。每个掩码token[14]是一个共享的学习向量,表示存在待预测的缺失patch。我们为这个完整集合中的所有标记添加位置嵌入;如果没有这个,掩码token将没有关于它们在图像中的位置的信息。解码器有另一系列的Transformer块。
总结:
每一个被盖住的块都表示成同一个向量,这个向量是可学习的
对被盖住的块进入decoder时加入位置信息;而对于encoder的结果,也就是可见的块则不那么确定是否需要在decoder部分再次加入位置信息,因为在encoder时已经添加过一次
The MAE decoder is only used during pre-training to perform the image reconstruction task (only the encoder is used to produce image representations for recognition).Therefore, the decoder architecture can be flexibly designed in a manner that is independent of the encoder design. We experiment with very small decoders, narrower and shallower than the encoder. For example, our default decoder has <10% computation per token vs. the encoder. With this asymmetrical design, the full set of tokens are only processed by the lightweight decoder, which significantly reduces pre-training time.
翻译:
MAE的解码器仅在预训练期间用于执行图像重建任务(仅编码器用于生成用于识别的图像表示)。因此,解码器架构可以以一种独立于编码器设计的方式灵活设计。我们用非常小的解码器做实验,比编码器更窄更浅。例如,与编码器相比,我们的默认解码器每个token的计算量<10%。通过这种不对称设计,整个标记集只由轻量级解码器处理,这大大减少了预训练时间。
总结:
decoder主要是在预训练时使用,在其他任务大多时候只需要encoder对图片进行编码
Reconstruction target
Our MAE reconstructs the input by predicting the pixel values for each masked patch. Each element in the decoder’s output is a vector of pixel values representing a patch. The last layer of the decoder is a linear projection whose number of output channels equals the number of pixel values in a patch. The decoder’s output is reshaped to form a reconstructed image. Our loss function computes the mean squared error (MSE) between the reconstructed and original images in the pixel space. We compute the loss only on masked patches, similar to BERT [14].1 We also study a variant whose reconstruction target is the normalized pixel values of each masked patch. Specifically, we compute the mean and standard deviation of all pixels in a patch and use them to normalize this patch. Using normalized pixels as the reconstruction target improves representation quality in our experiments.
翻译:
我们的MAE通过预测每个被屏蔽patch的像素值来重建输入。解码器输出中的每个元素都是代表一个patch的像素值向量。解码器的最后一层是一个线性投影,其输出通道的数量等于一个patch中的像素值的数量。对解码器的输出进行重构以形成重构图像。我们的损失函数在像素空间中计算重建图像和原始图像之间的均方误差(MSE)。我们只计算掩码patch上的损失,类似于BERT [14].1我们还研究了一种变体,其重建目标是每个被屏蔽patch的归一化像素值。具体来说,我们计算一个patch中所有像素的均值和标准差,并使用它们对该patch进行归一化。在我们的实验中,使用归一化像素作为重建目标提高了表示质量。
总结:
decoder的最后一层是线性层,如果patch是16x16,那么线性层的输出为256维,再reshape成16x16
MSE做像素级损失;只对掩盖部分计算损失,因为可见部分的像素都看见了
Simple implementation
Our MAE pre-training can be implemented efficiently, and importantly, does not require any specialized sparse operations. First we generate a token for every input patch (by linear projection with an added positional embedding). Next we randomly shuffle the list of tokens and remove the last portion of the list, based on the masking ratio. This process produces a small subset of tokens for the encoder and is equivalent to sampling patches without replacement. After encoding, we append a list of mask tokens to the list of encoded patches, and unshuffle this full list (inverting the random shuffle operation) to align all tokens with their targets. The decoder is applied to this full list (with positional embeddings added). As noted, no sparse operations are needed. This simple implementation introduces negligible overhead as the shuffling and unshuffling operations are fast
翻译:
我们的MAE预训练可以有效地实现,重要的是,它不需要任何专门的稀疏操作。首先,我们为每个输入patch生成一个标记(通过添加位置嵌入的线性投影)。接下来,我们随机打乱token列表,并根据屏蔽比率删除列表的最后一部分。这个过程为编码器生成一小部分标记,相当于采样patch而不进行替换。编码后,我们将一个掩码token列表添加到编码patch列表中,并取消这个完整列表(反转随机洗牌操作),以使所有token与其目标对齐。解码器应用于这个完整的列表(添加了位置嵌入)。如前所述,不需要稀疏操作。这个简单的实现引入的开销可以忽略不计,因为变换和解变换操作非常快
总结:
patch过linear embedding加上position embedding得到token列,打乱token列后只保留前面的token,实现随机采样
decoder时在后面附上跟以前长度一样的masked token(遮盖部分直接放回去),它是一个可学习的向量,再加上位置信息后再unshuffle(还原到原来的顺序),保证前后的patch是一一对应的
shuffle与unshuffle是特别快的
ImageNet Experiments
We do self-supervised pre-training on the ImageNet-1K (IN1K) [13] training set. Then we do supervised training to evaluate the representations with (i) end-to-end fine-tuning or (ii) linear probing. We report top-1 validation accuracy of a single 224×224 crop. Details are in Appendix A.1.
Baseline: ViT-Large. We use ViT-Large (ViT-L/16) [16] as the backbone in our ablation study. ViT-L is very big (an order of magnitude bigger than ResNet-50 [25]) and tends to overfit. The following is a comparison between ViT-L trained from scratch vs. fine-tuned from our baseline MAE:
We note that it is nontrivial to train supervised ViT-L from scratch and a good recipe with strong regularization is needed (82.5%, see Appendix A.2). Even so, our MAE pretraining contributes a big improvement. Here fine-tuning is only for 50 epochs (vs. 200 from scratch), implying that the fine-tuning accuracy heavily depends on pre-training.
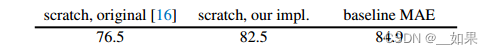
翻译:
我们在ImageNet-1K (IN1K)[13]训练集上进行自监督预训练。然后我们通过(i)端到端微调或(ii)线性探测来进行监督训练来评估表征。我们报告了单个224×224中心剪裁的图片的top1验证精度。详情见附录A.1。
基线模型:ViT-Large。我们使用vit - large (vit - L /16)[16]作为消融研究的主干。vit - L非常大(比ResNet-50[25]大一个数量级),容易过拟合。以下是从头开始训练的ViT-L与根据基线MAE进行微调的ViT-L的比较:
我们注意到,从头开始训练有监督的ViT-L是很重要的,需要一个具有强正则化的好配方(82.5%,见附录a .2)。即便如此,我们的MAE预训练还是做出了很大的改进。这里的微调只进行了50次(从零开始进行了200次),这意味着微调的准确性很大程度上取决于预训练。
总结:
用了两种自监督预训练方法:end to end微调整个模型的参数;linear probe微调最后一个线性输出层
图中可以看出,ViT本身是需要大量的数据支持的,但如果对其加上合适的正则化限制,则可以减少所需的数据量
Main Properties
We ablate our MAE using the default settings in Table 1 (see caption). Several intriguing properties are observed.
翻译:
我们使用表1中的默认设置(见标题)删除MAE。观察到几个有趣的性质。
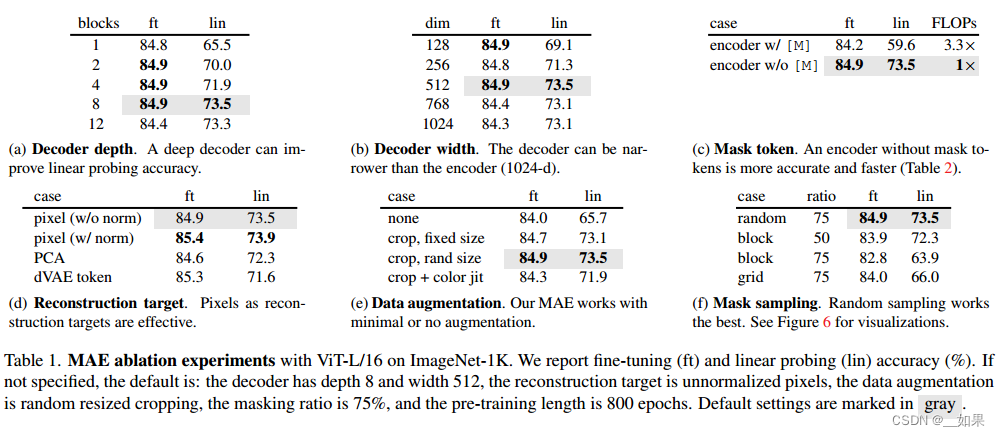
ft是fine tune全调,lin是linear probe调线性输出层
(a)解码器深度:用了多少个transformer块
(b)解码器宽度:每个token表示出多长的向量
(c)在编码器中要不要加入被遮住的块,发现不加入效果更好
(d)像素损失与patch归一化损失,其中dVAE token是BEiT的做法,即通过ViT把每一个块映射到一个离散的token上
(e)数据增强,MAE对数据增强不是很敏感
(f)mask的采样方法,随机采样效果最好
Masking ratio
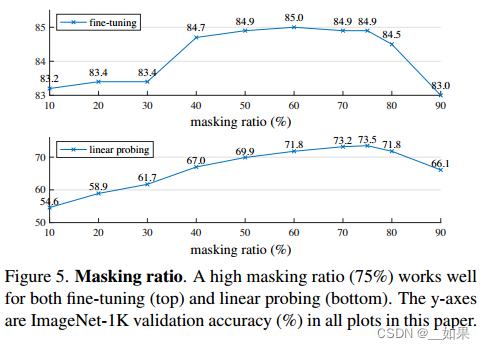
Figure 5 shows the influence of the masking ratio. The optimal ratios are surprisingly high. The ratio of 75% is good for both linear probing and fine-tuning.
This behavior is in contrast with BERT [14], whose typical masking ratio is 15%. Our masking ratios are also much higher than those in related works [6, 16, 2] in computer vision (20% to 50%).
The model infers missing patches to produce different, yet plausible, outputs (Figure 4). It makes sense of the gestalt of objects and scenes, which cannot be simply completed by extending lines or textures. We hypothesize that this reasoning-like behavior is linked to the learning of useful representations.
Figure 5 also shows that linear probing and fine-tuning results follow different trends. For linear probing, the accuracy increases steadily with the masking ratio until the sweet point: the accuracy gap is up to ∼20% (54.6% vs.73.5%). For fine-tuning, the results are less sensitive to the ratios, and a wide range of masking ratios (40–80%) work well. All fine-tuning results in Figure 5 are better than training from scratch (82.5%).
翻译:
图5显示了掩蔽比的影响。最佳比例高得惊人。75%的比例对线性探测和微调都很好。
这种行为与BERT[14]相反,BERT的典型掩蔽比为15%。我们的掩蔽率也远高于计算机视觉领域的相关研究[6,16,2](20% ~ 50%)。
该模型推断缺失的patch,以产生不同的但似乎合理的输出(图4)。它能够理解物体和场景的整体形式,这不仅仅是通过延伸线条或纹理来完成的。我们假设这种类似推理的行为与学习有用的表征有关。
图5还显示了线性探测和微调结果遵循不同的趋势。对于线性探测,精度随着掩蔽比的增加而稳步增加,直到达到最佳点:精度差距高达20% (54.6% vs 73.5%)。对于微调,结果对比率不太敏感,并且遮罩比率范围很广(40-80%)。图5中的所有微调结果都优于从头开始训练(82.5%)。
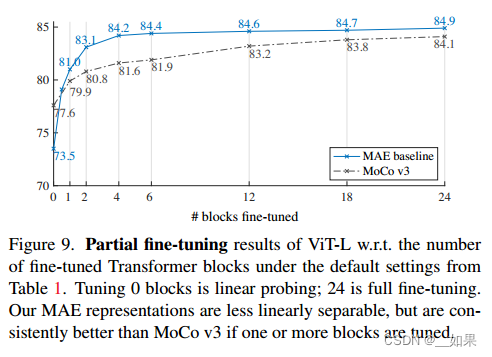
Partial Fine-tuning
Figure 9 shows the results. Notably, fine-tuning only one Transformer block boosts the accuracy significantly from 73.5% to 81.0%. Moreover, if we fine-tune only “half” of the last block (i.e., its MLP sub-block), we can get 79.1%, much better than linear probing. This variant is essentially fine-tuning an MLP head. Fine-tuning a few blocks (e.g., 4 or 6) can achieve accuracy close to full fine-tuning.
翻译:
图9显示了结果。值得注意的是,仅微调一个Transformer块就可以将精度从73.5%显著提高到81.0%。此外,如果我们只微调最后一个块的“一半”(即它的MLP子块),我们可以得到79.1%,比线性探测好得多。这种变体本质上是对MLP头进行微调。微调几个块(例如,4或6)可以达到接近完全微调的精度。
Transfer Learning Experiments
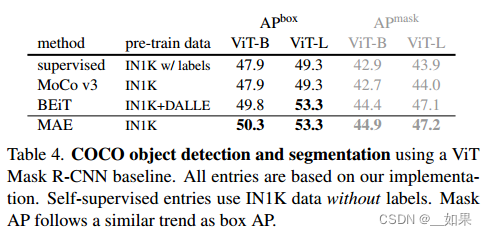
迁移到COCO数据集上的表现
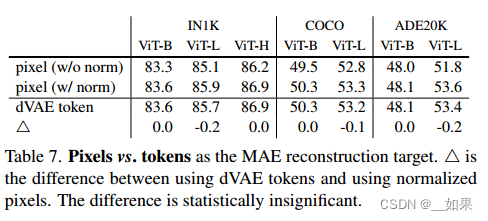
MAE重构像素vs像BEiT一样重构 (用dVAE学出来的标号比) :可以看出二者几乎没有差别,但MAE更简单
Discussion and Conclusion
Simple algorithms that scale well are the core of deep learning. In NLP, simple self-supervised learning methods (e.g., [47, 14, 48, 4]) enable benefits from exponentially scaling models. In computer vision, practical pre-training paradigms are dominantly supervised (e.g. [33, 51, 25, 16]) despite progress in self-supervised learning. In this study, we observe on ImageNet and in transfer learning that an autoencoder—a simple self-supervised method similar to techniques in NLP—provides scalable benefits. Selfsupervised learning in vision may now be embarking on a similar trajectory as in NLP.
翻译:
可扩展性好的简单算法是深度学习的核心。在NLP中,简单的自监督学习方法可以从指数缩放模型中获益。在计算机视觉中,尽管在自监督学习方面取得了进展,但实际的预训练范式主要是监督的。在本研究中,我们在ImageNet和迁移学习中观察到,自编码器——一种类似于nlp技术的简单自监督方法——提供了可扩展的好处。视觉领域的自监督学习现在可能走上了与NLP类似的轨道。
On the other hand, we note that images and languages are signals of a different nature and this difference must be addressed carefully. Images are merely recorded light without a semantic decomposition into the visual analogue of words. Instead of attempting to remove objects, we remove random patches that most likely do not form a semantic segment. Likewise, our MAE reconstructs pixels, which are not semantic entities. Nevertheless, we observe (e.g., Figure 4) that our MAE infers complex, holistic reconstructions, suggesting it has learned numerous visual concepts, i.e., semantics. We hypothesize that this behavior occurs by way of a rich hidden representation inside the MAE. We hope this perspective will inspire future work.
翻译:
另一方面,我们注意到图像和语言是不同性质的信号,必须仔细处理这种差异。图像仅仅是记录下来的光,没有将语义分解为文字的视觉模拟。并非试图删除物体,我们删除随机patch,最有可能不形成一个语义段。同样,我们的MAE重建像素,而像素不是语义实体。然而,我们观察到(例如,图4),我们的MAE推断出复杂的、整体的重建,这表明它已经学习了许多视觉概念,即语义。我们假设这种行为是通过MAE内部丰富的隐藏表示发生的。我们希望这一观点将启发未来的工作。
总结:
在nlp中,一个词是一个语义的单元,其中包含的语义信息很多;而在patch中,虽然一个patch中包含一定的语义信息,但patch并不一定含有一个物体的全部像素,即语义信息不完整。但即便如此MAE还是取得了很好的成果,确实学到了比较好的语义表达
Broader impacts
The proposed method predicts content based on learned statistics of the training dataset and as such will reflect biases in those data, including ones with negative societal impacts. The model may generate inexistent content. These issues warrant further research and consideration when building upon this work to generate images.
翻译:
所提出的方法基于训练数据集的学习统计来预测内容,因此将反映这些数据中的偏向,包括具有负面社会影响的偏向。模型可能生成不存在的内容。当利用这项工作产生图像时,这些问题需要进一步的研究和考虑。
这篇关于论文精读--MAE的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






![[论文笔记]LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale](https://img-blog.csdnimg.cn/img_convert/172ed0ed26123345e1773ba0e0505cb3.png)


