精读专题

BERT 论文逐段精读【论文精读】
BERT: 近 3 年 NLP 最火 CV: 大数据集上的训练好的 NN 模型,提升 CV 任务的性能 —— ImageNet 的 CNN 模型 NLP: BERT 简化了 NLP 任务的训练,提升了 NLP 任务的性能 BERT 如何站在巨人的肩膀上的?使用了哪些 NLP 已有的技术和思想?哪些是 BERT 的创新? 1标题 + 作者 BERT: Pre-trainin

论文精读-Supervised Raw Video Denoising with a Benchmark Dataset on Dynamic Scenes
论文精读-Supervised Raw Video Denoising with a Benchmark Dataset on Dynamic Scenes 优势 1、构建了一个用于监督原始视频去噪的基准数据集。为了多次捕捉瞬间,我们手动为对象s创建运动。在高ISO模式下捕获每一时刻的噪声帧,并通过对多个噪声帧进行平均得到相应的干净帧。 2、有效的原始视频去噪网络(RViDeNet),通过探

天然药物化学史话:“四大光谱”在天然产物结构鉴定中的应用-文献精读46
天然药物化学史话:“四大光谱”在天然产物结构鉴定中的应用,天然产物化学及其生物合成必备基础知识~ 摘要 天然产物化学研究在药物研发中起着非常重要的作用,结构研究又是天然产物化学研究中最重要的工作之一。在天然药物化学史话系列文章的基础上,对在天然产物结构研究中起绝对主导作用的“四大光谱”分析技术,即红外光谱、紫外光谱、质谱、核磁共振波谱在天然产物结构鉴定中的应用历史进行回顾与总结,并对其发展

Spark Core源码精读计划7 | Spark执行环境的初始化
推荐阅读 《Spark源码精度计划 | SparkConf》 《Spark Core源码精读计划 | SparkContext组件初始化》 《Spark Core源码精读计划3 | SparkContext辅助属性及后初始化》 《Spark Core源码精读计划4 | SparkContext提供的其他功能》 《Spark Core源码精读计划5 | 事件总线及ListenerBus》 《Spa
Spark Core源码精读计划3 | SparkContext辅助属性及后初始化
推荐阅读 《关于MQ面试的几件小事 | 消息队列的用途、优缺点、技术选型》 《关于MQ面试的几件小事 | 如何保证消息队列高可用和幂等》 《关于MQ面试的几件小事 | 如何保证消息不丢失》 《关于MQ面试的几件小事 | 如何保证消息按顺序执行》 《关于MQ面试的几件小事 | 消息积压在消息队列里怎么办》 《关于Redis的几件小事 | 使用目的与问题及线程模型》 《关于Red

【文献精读】基于驱动力表的无人车终端无约束预测纵向控制(TVT)
写在前面: 🌟 欢迎光临 清流君 的博客小天地,这里是我分享技术与心得的温馨角落。📝 个人主页:清流君_CSDN博客,期待与您一同探索 移动机器人 领域的无限可能。 🔍 本文系 清流君 原创之作,荣幸在CSDN首发🐒 若您觉得内容有价值,还请评论告知一声,以便更多人受益。 转载请注明出处,尊重原创,从我做起。 👍 点赞、评论、收藏,三连走一波,让我们一起养成好习惯😜 在这里,您将

向沐神学习笔记:GPT,GPT-2,GPT-3 论文精读【论文精读】GPT部分
系列文章目录 例如: 文章目录 系列文章目录一、GPT1、Abstract 二、1、2、3、 三、1、2、3、 四、1、2、3、 五、1、2、3、 六、1、2、3、 七、1、2、3、 八、1、2、3、 一、GPT 同样模型大小,比如一个亿模型大小的时候,bert的性能表现优于gpt,也就是未来的工作更愿意用bert这篇文章,因为我咬咬牙还能跑起来,但是gpt的实验实

杨树84K品种的单细胞测序发现转录因子PagMYB31的功能-文献精读44
Transcription factor PagMYB31 positively regulates cambium activity and negatively regulates xylem development in poplar 转录因子PagMYB31正向调控杨树84K品种的形成层活动,并负向调控木质部的发育。 同样有篇文献,二倍体毛白杨基因组~ 二倍体毛白杨(Populus


茄科四个参考基因组-文献精读41
Multiple independent losses of the biosynthetic pathway for two tropane alkaloids in the Solanaceae family 茄科植物中两种莨菪烷生物合成途径的多次独立丧失 摘要 东莨菪碱和莨菪碱(HS)是两种具有重要药用价值的莨菪烷生物碱,它们存在于茄科家族中多个关系较远的谱系中。在本研究中,我们测

前胡基因组与伞形科香豆素的进化-文献精读42
The gradual establishment of complex coumarin biosynthetic pathway in Apiaceae 伞形科中复杂香豆素生物合成途径的逐步建立 羌活基因组--文献精读-36 摘要:复杂香豆素(CCs)是伞形科植物中的特征性代谢产物,具有重要的药用价值。它们的重要功能可能是作为病原体防护剂并调节响应环境刺激。利用包括我们新近测序的前胡
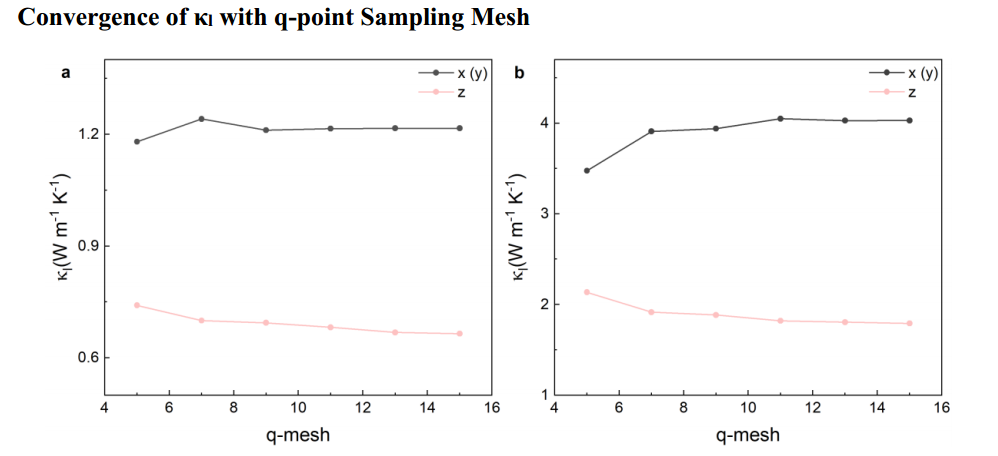
论文精读:JACS —— Sb2Si2Te6与Sc2Si2Te6热电性能
摘要节选: 本文以层状Sb2Si2Te6和Sc2Si2Te6为模型体系,采用密度泛函理论结合半经典玻尔兹曼输运理论,全面研究和比较了它们的热电性能。 由于较低的散射率和更明显的带色散,Sb2Si2Te6与Sc2Si2Te6相比具有优越的导电性。 在将导带轨道特性从Sb-p切换到Sc-d时,带(谷)简并和各向异性的共同增加,从而显著提高了塞贝克系数。 引言节选

分歧时间估计与被子植物的年代-文献精读43
Ad fontes: divergence-time estimation and the age of angiosperms 回归本源:分歧时间估计与被子植物的年代 摘要 准确的分歧时间对于解释和理解谱系演化的背景至关重要。在过去的几十年里,有关冠被子植物推测的分子年龄(通常估计为晚侏罗世至二叠纪)与化石记录(将被子植物置于早白垩纪)之间的差异,引发了广泛的争论。如果冠被子植物早在二

贴梗海棠T2T基因组-文献精读40
A telomere-to-telomere reference genome provides genetic insight into the pentacyclic triterpenoid biosynthesis in Chaenomeles speciosa 端粒到端粒参考基因组为贴梗海棠中五环三萜生物合成提供了遗传学见解 摘要 贴梗海棠(Chaenomeles specio
NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis 精读
1 传统视图合成和NeRF(Neural Radiance Fields) 1.1 联系 传统视图合成和NeRF的共同目标都是从已有的视角图像中生成新的视角图像。两者都利用已有的多视角图像数据来预测或合成从未见过的视角。 1.2 区别 1.2.1 几何表示方式 传统视图合成:通常使用显式几何模型(如深度图、网格、点云)或其他图像处理方法(如基于图像拼接或光流的方法)来生成新的视图。这些

【Datawhale AI夏令营第四期】 浪潮源大模型应用开发方向笔记 Task05 源大模型微调实战代码精读 RAG测试 AI简历助手代码优化 网课剩余部分
【Datawhale AI夏令营第四期】 浪潮源大模型应用开发方向笔记 Task05 源大模型微调实战代码精读 RAG测试 AI简历助手代码优化 网课剩余部分 教程基础背景知识: 微调能解决的问题正好是我需要的——模型在某个特定方面上能力不够。我感觉这种情况适用于让模型去完成特定小众的任务,比如原神数值分析,原神剧情梳理啥的,不属于普罗大众知识库的专精小微领域?我感觉也能用在我们草台班子的人话

graphrag论文精读
论文精读:From Local to Global: A Graph RAG Approach to Query-Focused Summarization 1. 研究背景与问题 在大语言模型(LLMs)的应用中,检索增强生成(RAG)方法通常用于从外部知识源检索相关信息,从而回答用户的问题。然而,RAG方法在处理涉及整个文本语料库的全局问题时效果不佳,比如“数据集中主要的主题是什么?”这些问
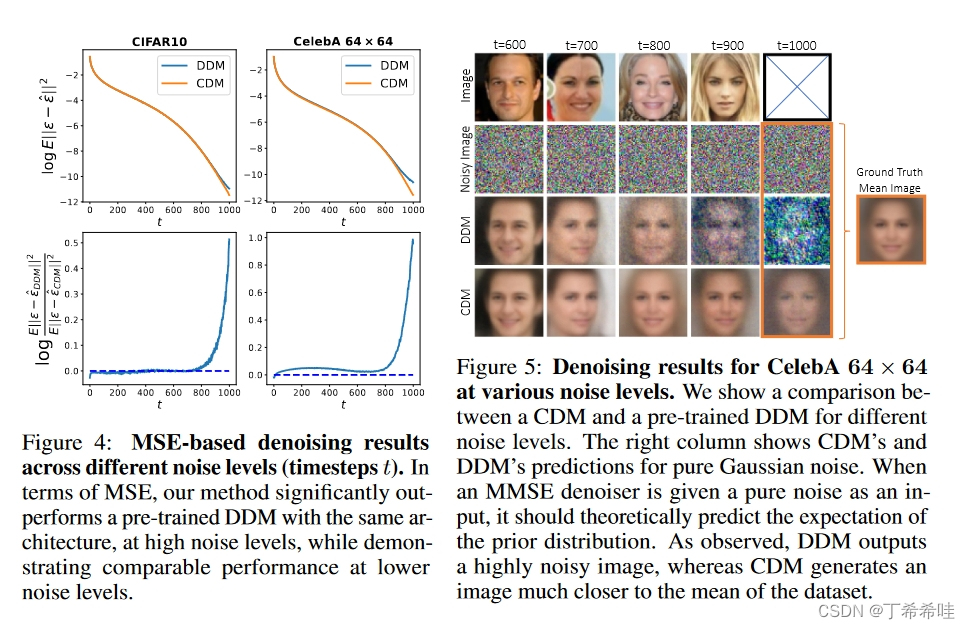
【论文精读】分类扩散模型:重振密度比估计(Revitalizing Density Ratio Estimation)
文章目录 一、文章概览(一)问题的提出(二)文章工作 二、理论背景(一)密度比估计DRE(二)去噪扩散模型 三、方法(一)推导分类和去噪之间的关系(二)组合训练方法(三)一步精确的似然计算 四、实验(一)使用两种损失对于实现最佳分类器的重要性(二)去噪结果、图像质量和负对数似然 论文:Classification Diffusion Models: Revitalizing

Michael.W基于Foundry精读Openzeppelin第59期——Proxy.sol
Michael.W基于Foundry精读Openzeppelin第59期——Proxy.sol 0. 版本0.1 Proxy.sol 1. 目标合约2. 代码精读2.1 _delegate(address implementation) internal2.2 _implementation() internal && _beforeFallback() internal2.3 fallba
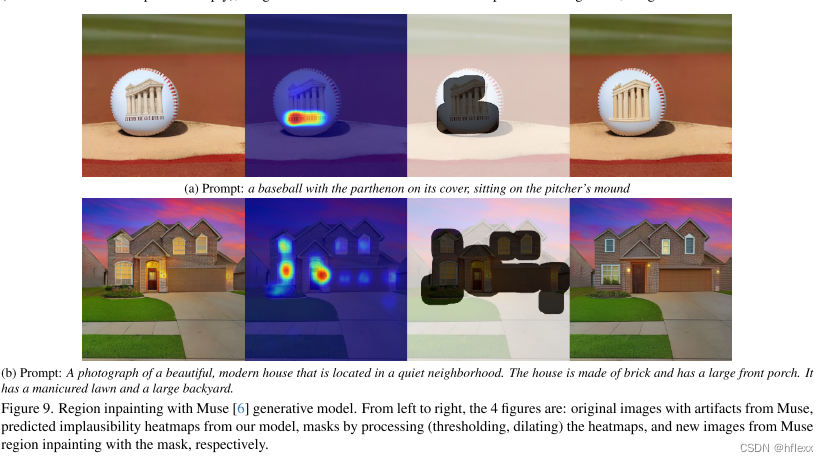
AIGC-CVPR2024best paper-Rich Human Feedback for Text-to-Image Generation-论文精读
Rich Human Feedback for Text-to-Image Generation斩获CVPR2024最佳论文!受大模型中的RLHF技术启发,团队用人类反馈来改进Stable Diffusion等文生图模型。这项研究来自UCSD、谷歌等。 在本文中,作者通过标记不可信或与文本不对齐的图像区域,以及注释文本提示中的哪些单词在图像上被歪曲或丢失来丰富反馈信号。 在 18K 生成图像 (R
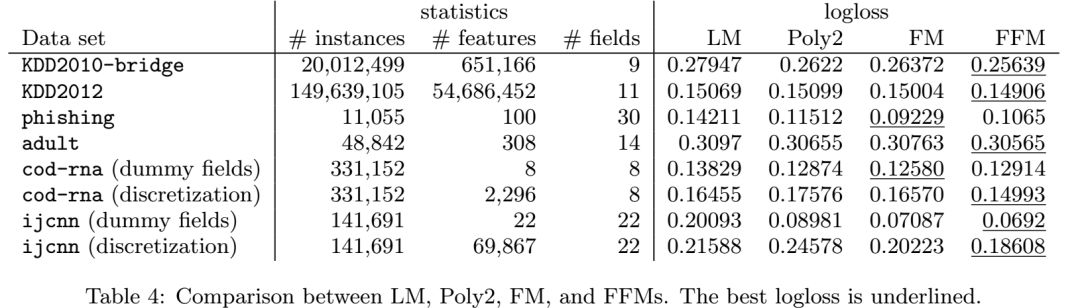
点击率预测《Field-aware Factorization Machines for CTR Prediction》论文精读
请点击上方“AI公园”,关注公众号 上次发的这篇文章,由于排版的问题,导致了部分手机无法正常显示公式,经过几个朋友提醒才发现,今天重新发布一次。 摘要:点击率预测在计算机广告中有着重要的作用。在这个应用中,二阶多项式映射和因子分解模型应用的非常广泛。最近,各种种类的因子分解机(FM),领域因子分解机(FFM)在各个点击率预测的竞赛中表现出了其他模型都好的效果。基于我们获胜的经验,本文我们建立了
推荐系统《Field-aware Factorization Machines for CTR Prediction》 论文精读
之前一篇文中说提到了FFM,那么我们今天就来看看FFM是个什么东西,它和FM又是什么关系。 摘要:点击率预测在计算机广告中有着重要的作用。在这个应用中,二阶多项式映射和因子分解模型应用的非常广泛。最近,各种种类的因子分解机(FM),领域因子分解机(FFM)在各个点击率预测的竞赛中表现出了其他模型都好的效果。基于我们获胜的经验,本文我们建立了对大型的稀疏数据集进行点击率预测的方法FFM。首先,我们
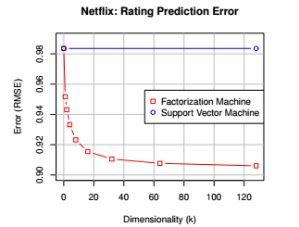
推荐系统之《Factorization Machines》论文精读
本文是AI公园公众号的第一篇,希望从今天开始,AI公园能够陪伴大家一起学习和工作。 本公众号将以原创为主,如果大家喜欢的话,请点击上方“AI公园”并关注。谢谢大家支持! 推荐系统是目前AI应用的非常成熟的领域,而且也取得了非常好的效果,而在很多推荐系统的场景中,我们会非常普遍的用到one-hot编码之类的方法,这就导致了我们的输入特征会变的非常的稀

【论文精读】树环水印Tree-Ring Watermarks:隐形且稳健的扩散图像的指纹
文章目录 一、文章概览(一)主要工作(二)相关工作 二、具体方法(一)威胁模型(二)树轮水印概述(三)构造树轮水印键(四)提取用于水印检测的 P 值 三、实验(一)实验设置(二)水印精度和图像质量基准测试(三)水印稳健性基准测试(四)消融实验 四、局限性和未来的工作 论文:Tree-Ring Watermarks: Fingerprints for Diffusion Imag
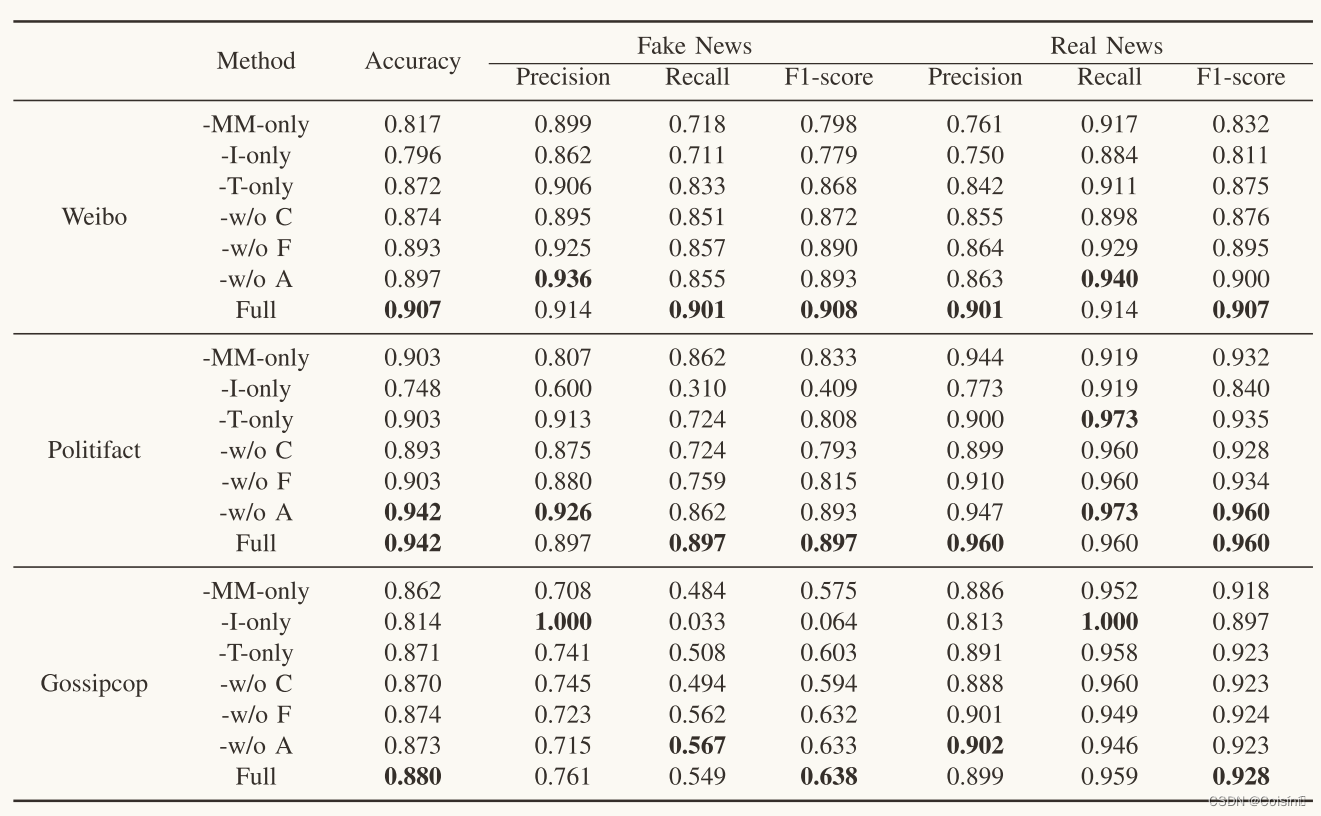
(一篇Blog证明还在地球)论文精读:基于CLIP引导学习的多模态虚假新闻检测
摘要 假新闻检测在社会取证领域引起了广泛的研究兴趣。许多现有的方法引入了定制的注意机制来融合单峰特征。然而,它们忽略了模式之间的跨模式相似性的影响。同时,预训练的多模式特征学习模型在FND中的潜力还没有得到很好的开发。这篇论文提出了一种FND-CLIP框架,即基于对比语言图像预训练(CLIP)的多模式假新闻检测网络。FND-CLIP使用两个单峰编码器和两个成对的CLIP编码器一起从新闻中提取深层

为什么用SDE(随机微分方程)来描述扩散过程【论文精读】
为什么用SDE(随机微分方程)来描述扩散过程【论文精读】 B站视频:为什么用SDE(随机微分方程)来描述扩散过程 论文:Score-Based Generative Modeling through Stochastic Differential Equations 地址:https://doi.org/10.48550/arXiv.2011.13456 视频讲解内容目录 扩散过程就