本文主要是介绍DEiT中如何处理mask数据的?与MAE的不同,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
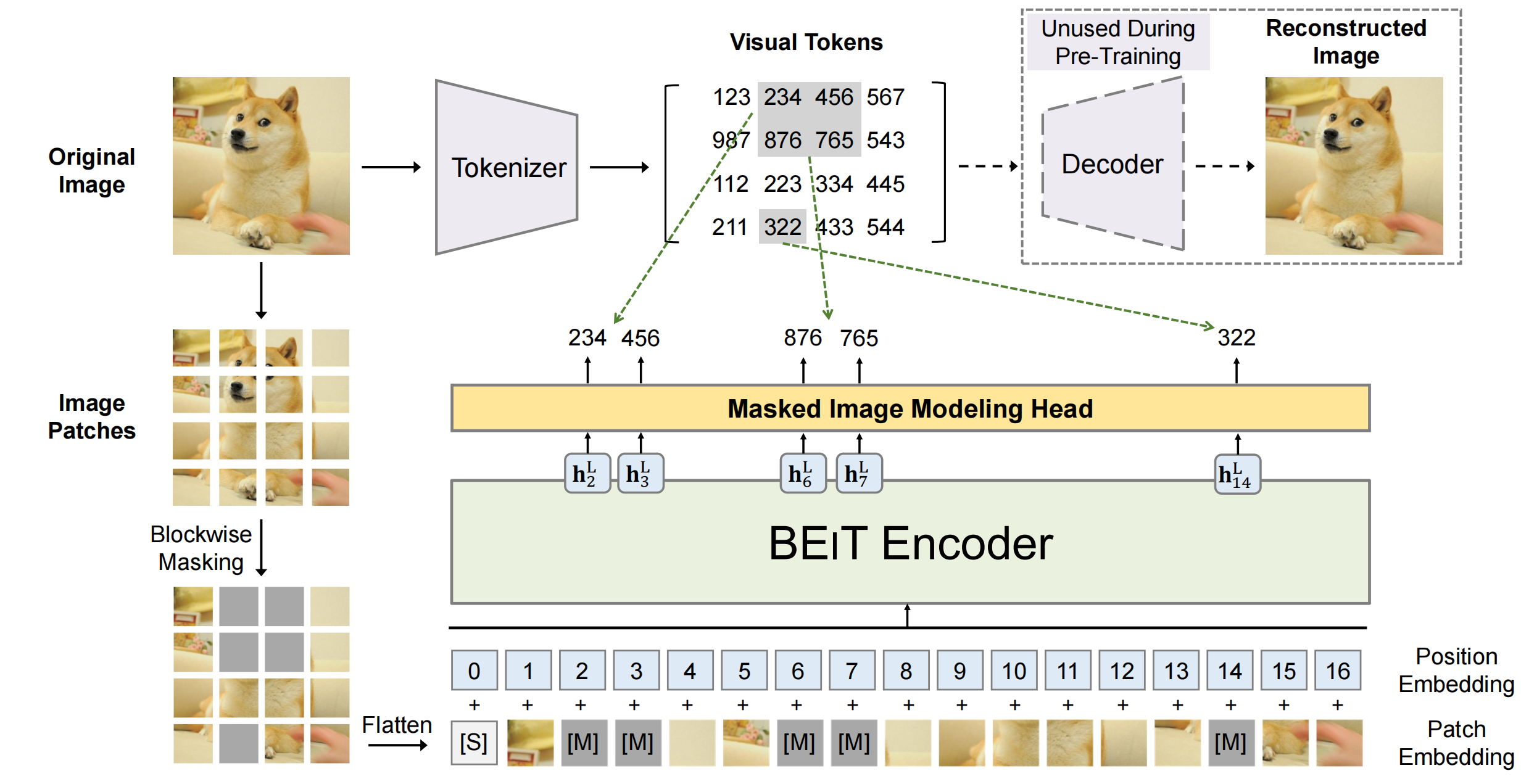
在DeiT里面,是通过mask的方式,将mask+unmasked的patches输出进ViT中,但其实在下游任务输入的patches还是和训练时patches的数量N是一致的(encoder所有的patches)。
而MAE是在encoder中只encoder未被mask的patches
通过什么方式支持的?
- 在处理文本时,可以根据最长的句子在批次中动态padding或截断长句子
- 而在处理图像(如使用ViT)时,可以将图像划分为大小相等的patches,数量可以根据图像的大小动态变化。
在训练阶段,部分patches被mask为0,但是处理的所有patches加起来的总长度还是一样的。被mask的位置在模型内部仍然占位,保持了输入序列的“框架”。这样,即使实际参与计算的只是部分元素,模型也能够适应在推理时使用全部元素的情况。
具体的计算步骤如下:
- 确定mask哪些patches
- 将mask的patches位置设置为0
- 这些被mask和未被mask的所有patches一起被输入进attention模块
- 将被mask的patches的注意力分数手动设置为“无穷大负数”(-inf)
- 这些被mask的patches的softmax值就会变为0,也就意味着这些patches并未参与注意力的计算
import torch
import torch.nn as nn
import torch.nn.functional as Fclass MaskedSelfAttention(nn.Module):def __init__(self, embed_size):super(MaskedSelfAttention, self).__init__()self.query = nn.Linear(embed_size, embed_size)self.key = nn.Linear(embed_size, embed_size)self.value = nn.Linear(embed_size, embed_size)def forward(self, x, mask=None):Q = self.query(x)K = self.key(x)V = self.value(x)# 计算自注意力得分attention_scores = torch.matmul(Q, K.transpose(-2, -1)) / torch.sqrt(torch.tensor(Q.size(-1), dtype=torch.float32))# 将mask值为0的位置在attention_scores中设置为一个非常大的负数attention_scores = attention_scores.masked_fill(mask == 0, float('-inf'))# 使得这些位置的softmax结果接近0attention_weights = F.softmax(attention_scores, dim=-1)# 算最终的注意力加权和output = torch.matmul(attention_weights, V)return output# 假设嵌入大小为512
embed_size = 512
# 创建一个mask,假设我们有4个patches,我们想要mask掉第2个和第4个patches
mask = torch.tensor([[1, 0, 1, 0]])
# 扩展mask维度以适应attention_scores的形状(假设批大小为1,序列长度为4),mask需要与attention_scores形状匹配,即(batch_size, 1, 1, seq_length)
mask = mask.unsqueeze(1).unsqueeze(2)# 初始化模型和数据
sa = MaskedSelfAttention(embed_size)
x = torch.randn(1, 4, embed_size) # 假设有一个批大小为1,序列长度为4的输入output = sa(x, mask)
print(output)
这篇关于DEiT中如何处理mask数据的?与MAE的不同的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







