deit专题
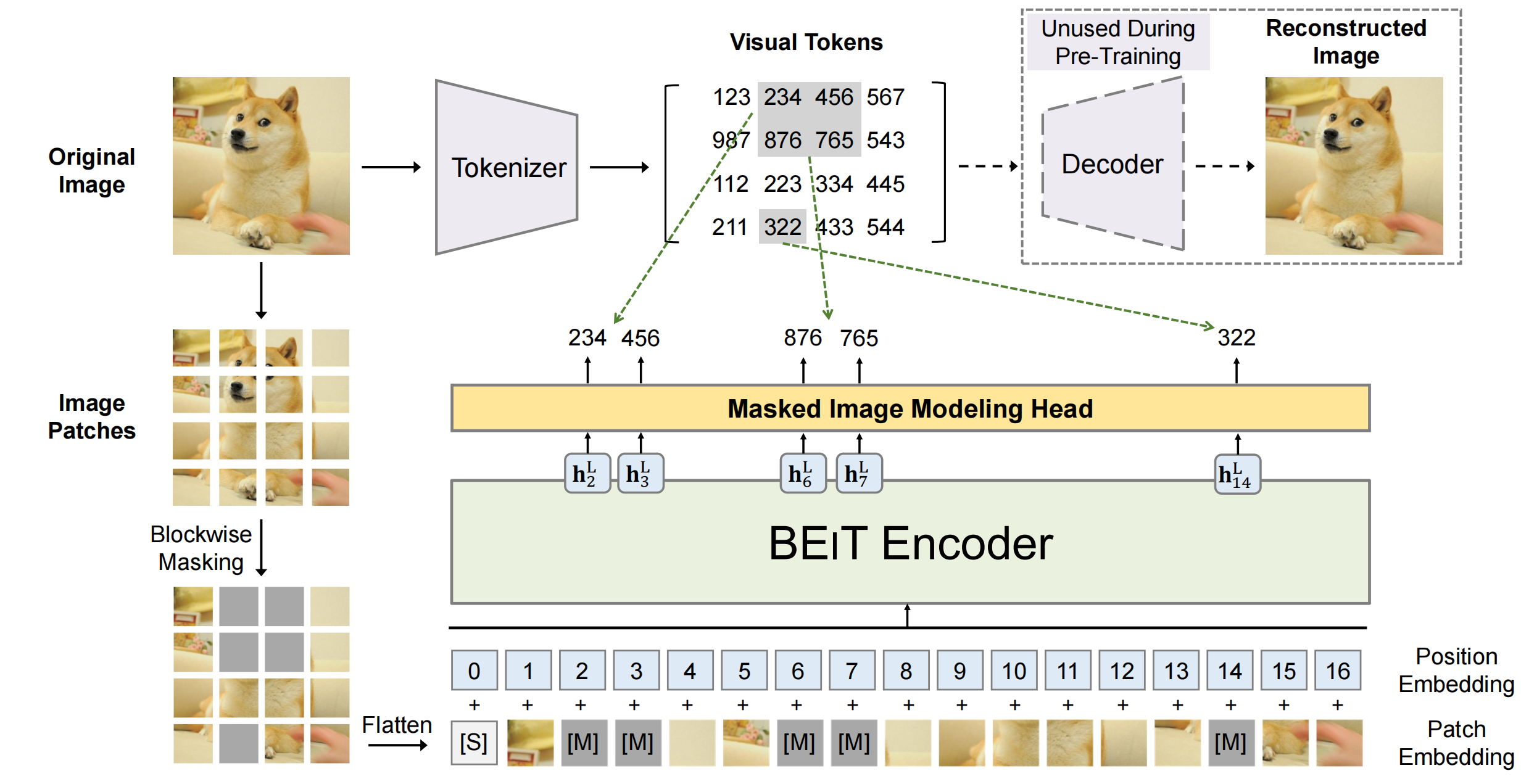
DEiT中如何处理mask数据的?与MAE的不同
在DeiT里面,是通过mask的方式,将mask+unmasked的patches输出进ViT中,但其实在下游任务输入的patches还是和训练时patches的数量N是一致的(encoder所有的patches)。 而MAE是在encoder中只encoder未被mask的patches 通过什么方式支持的? 在处理文本时,可以根据最长的句子在批次中动态padding或截断长句子而

Deit:知识蒸馏与vit的结合 学习笔记(附代码)
论文地址:https://arxiv.org/abs/2012.12877 代码地址:GitHub - facebookresearch/deit: Official DeiT repository 1.是什么? DeiT(Data-efficient Image Transformer)是一种用于图像分类任务的神经网络模型,它基于Transformer架构。这个模型的主要目标是在参数较少

DeiT III: Revenge of the ViT中文翻译
Abstract 视觉转换器(ViT)是一种简单的神经结构,适用于多个计算机视觉任务。它有有限的内置架构先验,而最近的架构则包含了关于输入数据或特定任务的先验。最近的研究表明,vit受益于自我监督的预训练,特别是像BeiT这样的bert式的预训练。 在本文中,我们回顾了ViTs的监督训练。我们的过程建立并简化了训练ResNet-50的配方。它包括一个新的简单的数据增强程序,只有3个增强,更接近在