本文主要是介绍MAE实战:使用MAE提高主干网络的精度(一),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
摘要
MAE已经出来有几年了,很多人还不知道怎么去使用,本文通过两个例子说明一下。分两部分,一部分介绍一个简单的例子,让大家了解MAE训练的流程。一部分是一个新的模型,让大家了解如何将自己的模型加入MAE。
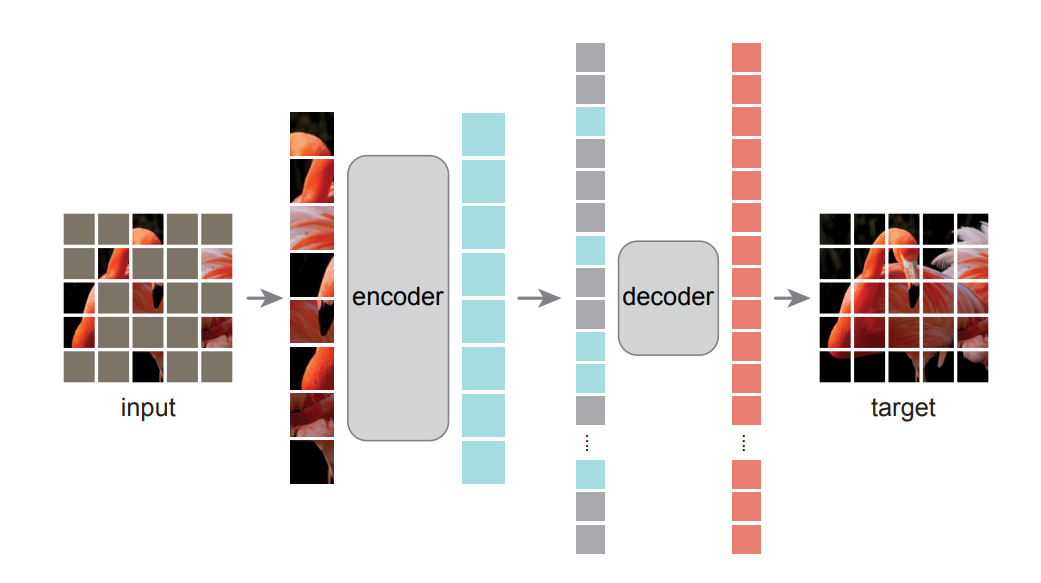
论文标题: Masked Autoencoders Are Scalable Vision Learners
论文地址:https://arxiv.org/abs/2111.06377
代码地址:https://github.com/facebookresearch/mae
MAE的两个核心设计:
- 第一,首先MAE是一个非对称的编码—解码结构,这种不对称是因为encoder只作用在可见的patches,也就没有mask的patches,同时也还有一个轻量级的解码器来重构原始图像。
- 第二,作者发现,mask比较高的比例,比如说mask75%的patches,这样就会产生一个有意义的自监督任务。这两者结合起来,加速了训练次数,因为原来需要整个图像,当我们mask掉75%的patches以后,我们只剩下了25%的像素,所以训练速度提高了3倍或更多,并且提高了准确性。在论文中,作者利用ImageNet-1K的数据集进行训练,一个普通的v-huge的模型获得了最好的准确率87.8%。在一些目标检测、分类、分割的任务中,效果超过了一些有监督学习预训练的效果,显示了良好的可扩展性。
参考文章:https://blog.csdn.net/weixin_45508265/article/details/130287752
简单的Demo热身
github链接:https://github.com/Kedreamix/MAE-for-CIFAR。项目结构:
MAE-for-CIFAR-main
├─ mae_pretrain.py
├─ model.py
├─ README.md
├─ requirements.txt
├─ train_classifier.py
├─ utils.py
├─ vit-t-classifier-from_pretrained.pth
└─ vit-t-mae.pthmodel详解
class PatchShuffle(torch.nn.Module):def __init__(self, ratio) -> None:super().__init__()self.ratio = ratio def forward(self, patches : torch.Tensor):T, B, C = patches.shape # length, batch, dimremain_T = int(T * (1 - self.ratio))indexes = [random_indexes(T) for _ in range(B)]forward_indexes = torch.as_tensor(np.stack([i[0] for i in indexes], axis=-1), dtype=torch.long).to(patches.device)backward_indexes = torch.as_tensor(np.stack([i[1] for i in indexes], axis=-1), dtype=torch.long).to(patches.device)patches = take_indexes(patches, forward_indexes) # 随机打乱了数据的patch,这样所有的patch都被打乱了patches = patches[:remain_T] #得到未mask的pacth [T*0.25, B, C]return patches, forward_indexes, backward_indexes
代码详解:
-
初始化方法 (
__init__):- 接受一个参数
ratio,表示要打乱的patch的比例。 - 将这个
ratio保存为类的属性。
- 接受一个参数
-
前向传播方法 (
forward):- 输入是一个三维的张量
patches,其形状为[T, B, C],其中T是序列长度,B是批量大小,而C是每个patch的维度。 - 首先,计算要保留的patch数量,即
remain_T = int(T * (1 - self.ratio))。这意味着我们要打乱前remain_T个patches。 - 接下来,为每个batch生成一个随机的索引列表。这意味着对于每个batch,我们都为其前
remain_T个patches生成一个随机的索引列表。 - 使用这些索引从原始patches中提取打乱的patches,并将它们存储在新的张量中。
- 最后,返回这些打乱的patches以及它们的原始和反向索引。
- 输入是一个三维的张量
class MAE_Encoder(torch.nn.Module):def __init__(self,image_size=32,patch_size=2,emb_dim=192,num_layer=12,num_head=3,mask_ratio=0.75,) -> None:super().__init__()self.cls_token = torch.nn.Parameter(torch.zeros(1, 1, emb_dim)) self.pos_embedding = torch.nn.Parameter(torch.zeros((image_size // patch_size) ** 2, 1, emb_dim))# 对patch进行shuffle 和 maskself.shuffle = PatchShuffle(mask_ratio)# 这里得到一个 (3, dim, patch, patch)self.patchify = torch.nn.Conv2d(3, emb_dim, patch_size, patch_size)self.transformer = torch.nn.Sequential(*[Block(emb_dim, num_head) for _ in range(num_layer)])# ViT的laynormself.layer_norm = torch.nn.LayerNorm(emb_dim)self.init_weight()# 初始化类别编码和向量编码def init_weight(self):trunc_normal_(self.cls_token, std=.02)trunc_normal_(self.pos_embedding, std=.02)def forward(self, img):patches = self.patchify(img)patches = rearrange(patches, 'b c h w -> (h w) b c')patches = patches + self.pos_embeddingpatches, forward_indexes, backward_indexes = self.shuffle(patches)patches = torch.cat([self.cls_token.expand(-1, patches.shape[1], -1), patches], dim=0)patches = rearrange(patches, 't b c -> b t c')features = self.layer_norm(self.transformer(patches))features = rearrange(features, 'b t c -> t b c')return features, backward_indexes
这段代码定义了一个名为MAE_Encoder的PyTorch模型,这是一个基于Transformer的自编码器(MAE)模型。代码详解:
-
初始化方法 (
__init__):- 定义了一些超参数,如图像大小(
image_size)、patch大小(patch_size)、嵌入维度(emb_dim)、Transformer的层数(num_layer)、注意力头的数量(num_head)和mask比例(mask_ratio)。 self.cls_token:这是一个类别编码,初始化为一个大小为(1, 1, emb_dim)的全0张量。self.pos_embedding:这是一个位置编码,初始化为一个大小为((image_size // patch_size) ** 2, 1, emb_dim)的全0张量。self.shuffle:这是前面定义的PatchShuffle模块,用于随机打乱patches。self.patchify:这是一个2D卷积层,用于将图像转化为patches,并对其进行线性变换以增加嵌入维度。self.transformer:这是一个由多个Block组成的Transformer模型,其中每个Block是一个Transformer的层。self.layer_norm:这是一个层归一化层。self.init_weight():这是一个方法,用于初始化权重。它使用截断的正态分布来初始化权重。
- 定义了一些超参数,如图像大小(
-
前向传播方法 (
forward):- 首先,使用
self.patchify将输入图像转化为patches。 - 然后,重新排列这些patches以适应Transformer的输入格式。
- 将位置编码加到patches上。
- 使用
self.shuffle随机打乱patches。 - 将类别编码与打乱的patches拼接在一起。
- 对拼接后的patches进行层归一化,然后通过Transformer进行处理。
- 最后,重新排列处理后的特征,并返回这些特征和反向索引。
- 首先,使用
class MAE_Decoder(torch.nn.Module):def __init__(self,image_size=32,patch_size=2,emb_dim=192,num_layer=4,num_head=3,) -> None:super().__init__()self.mask_token = torch.nn.Parameter(torch.zeros(1, 1, emb_dim))self.pos_embedding = torch.nn.Parameter(torch.zeros((image_size // patch_size) ** 2 + 1, 1, emb_dim))self.transformer = torch.nn.Sequential(*[Block(emb_dim, num_head) for _ in range(num_layer)])self.head = torch.nn.Linear(emb_dim, 3 * patch_size ** 2)self.patch2img = Rearrange('(h w) b (c p1 p2) -> b c (h p1) (w p2)', p1=patch_size, p2=patch_size, h=image_size//patch_size)self.init_weight()def init_weight(self):trunc_normal_(self.mask_token, std=.02)trunc_normal_(self.pos_embedding, std=.02)def forward(self, features, backward_indexes):T = features.shape[0]backward_indexes = torch.cat([torch.zeros(1, backward_indexes.shape[1]).to(backward_indexes), backward_indexes + 1], dim=0)features = torch.cat([features, self.mask_token.expand(backward_indexes.shape[0] - features.shape[0], features.shape[1], -1)], dim=0)features = take_indexes(features, backward_indexes)features = features + self.pos_embeddingfeatures = rearrange(features, 't b c -> b t c')features = self.transformer(features)features = rearrange(features, 'b t c -> t b c') features = features[1:]patches = self.head(features)mask = torch.zeros_like(patches) mask[T:] = 1mask = take_indexes(mask, backward_indexes[1:] - 1)img = self.patch2img(patches)mask = self.patch2img(mask)return img, mask
这段代码定义了一个名为MAE_Decoder的PyTorch模型,这是一个自编码器(MAE)的解码器部分,用于将patches重建为完整的图像。代码详解:
-
初始化方法 (
__init__):- 定义了一些超参数,如图像大小(
image_size)、patch大小(patch_size)、嵌入维度(emb_dim)、Transformer的层数(num_layer)和注意力头的数量(num_head)。 self.mask_token:这是一个掩码标记,初始化为一个大小为(1, 1, emb_dim)的全0张量。self.pos_embedding:这是一个位置编码,初始化为一个大小为((image_size // patch_size) ** 2 + 1, 1, emb_dim)的全0张量。self.transformer:这是一个由多个Block组成的Transformer模型,其中每个Block是一个Transformer的层。self.head:这是一个线性层,将嵌入维度转换为图像的像素值。self.patch2img:这是一个重排层,用于将patches重新排列为图像。self.init_weight():这是一个方法,用于初始化权重。它使用截断的正态分布来初始化权重。
- 定义了一些超参数,如图像大小(
-
前向传播方法 (
forward):- 首先,根据输入的特征和反向索引计算掩码标记的大小。
- 将掩码标记与特征拼接在一起。
- 使用反向索引从特征中提取patches的位置编码。
- 对拼接后的patches进行层归一化,然后通过Transformer进行处理。
- 使用线性层和重排层将patches转换为图像。
- 创建一个与patches大小相同的掩码,其中除了最后一行外所有元素都为0。
- 返回重建的图像和掩码。
这个模型的整体目的是根据编码的特征和反向索引重建原始图像。
class MAE_ViT(torch.nn.Module):def __init__(self,image_size=32,patch_size=2,emb_dim=192,encoder_layer=12,encoder_head=3,decoder_layer=4,decoder_head=3,mask_ratio=0.75,) -> None:super().__init__()self.encoder = MAE_Encoder(image_size, patch_size, emb_dim, encoder_layer, encoder_head, mask_ratio)self.decoder = MAE_Decoder(image_size, patch_size, emb_dim, decoder_layer, decoder_head)def forward(self, img):features, backward_indexes = self.encoder(img)predicted_img, mask = self.decoder(features, backward_indexes)return predicted_img, mask这段代码定义了一个名为MAE_ViT的PyTorch模型,它是基于Vision Transformer(ViT)的自编码器(MAE)模型。以下是代码的详细解释:
-
初始化方法 (
__init__):image_size:输入图像的大小。patch_size:将图像分解为patches的大小。emb_dim:嵌入维度。encoder_layer:编码器(ViT)的层数。encoder_head:编码器中注意力头的数量。decoder_layer:解码器的层数。decoder_head:解码器中注意力头的数量。mask_ratio:用于生成掩码的比例。self.encoder:使用给定参数定义的编码器(ViT)模块。self.decoder:使用给定参数定义的解码器模块。
-
前向传播方法 (
forward):- 输入图像首先通过编码器,输出特征和反向索引。
- 这些特征和反向索引随后传递给解码器,输出预测的图像和掩码。
- 最后,返回预测的图像和掩码。
这个模型的整体目的是使用给定的Vision Transformer编码器和解码器来对输入图像进行编码和解码,从而生成预测的图像。
class ViT_Classifier(torch.nn.Module):def __init__(self, encoder : MAE_Encoder, num_classes=10) -> None:super().__init__()self.cls_token = encoder.cls_tokenself.pos_embedding = encoder.pos_embeddingself.patchify = encoder.patchifyself.transformer = encoder.transformerself.layer_norm = encoder.layer_normself.head = torch.nn.Linear(self.pos_embedding.shape[-1], num_classes)def forward(self, img):patches = self.patchify(img)patches = rearrange(patches, 'b c h w -> (h w) b c')patches = patches + self.pos_embeddingpatches = torch.cat([self.cls_token.expand(-1, patches.shape[1], -1), patches], dim=0)patches = rearrange(patches, 't b c -> b t c')features = self.layer_norm(self.transformer(patches))features = rearrange(features, 'b t c -> t b c')logits = self.head(features[0])return logits
这段代码定义了一个名为ViT_Classifier的PyTorch模型,它是一个基于Vision Transformer(ViT)的分类器。代码详解:
-
初始化方法 (
__init__):- 输入参数包括一个
encoder(MAE_Encoder)和一个可选的num_classes(分类的数量,默认为10)。 self.cls_token:从编码器中获取的cls token。self.pos_embedding:从编码器中获取的位置嵌入。self.patchify:从编码器中获取的patches生成函数。self.transformer:从编码器中获取的Transformer模型。self.layer_norm:从编码器中获取的层归一化层。self.head:一个线性层,用于将位置嵌入的维度转换为分类的数量。
- 输入参数包括一个
-
前向传播方法 (
forward):- 首先,通过
self.patchify函数将输入图像转换为patches。 - 对patches进行重排,使其维度顺序变为
(h w) b c。 - 将patches与位置嵌入相加,并添加cls token。
- 对patches进行重新排列,使其维度顺序变为
b t c。 - 通过Transformer模型处理patches,并经过层归一化。
- 对处理后的patches进行重新排列,使其维度顺序变为
t b c。 - 通过线性层(即分类头)获取最终的logits。
- 返回logits作为分类器的输出。
- 首先,通过
这个模型的整体目的是使用Vision Transformer对输入图像进行编码,并通过分类头生成logits,用于后续的分类任务。
第一步 训练未用MAE的分类器
调用train_classifier.py从头开始训练分类器,用来和MAE训练出来的模型做对比,接下来对train_classifier脚本代码详解。
导入包和超参数设置
import os
import argparse
import math
import torch
import torchvision
from torch.utils.tensorboard import SummaryWriter
from torchvision.transforms import ToTensor, Compose, Normalize
from tqdm import tqdmfrom model import *
from utils import setup_seedif __name__ == '__main__':parser = argparse.ArgumentParser()parser.add_argument('--seed', type=int, default=2022)parser.add_argument('--batch_size', type=int, default=128)parser.add_argument('--max_device_batch_size', type=int, default=256)parser.add_argument('--base_learning_rate', type=float, default=1e-3)parser.add_argument('--weight_decay', type=float, default=0.05)parser.add_argument('--total_epoch', type=int, default=100)parser.add_argument('--warmup_epoch', type=int, default=5)parser.add_argument('--pretrained_model_path', type=str, default=None)parser.add_argument('--output_model_path', type=str, default='vit-t-classifier-from_scratch.pth')args = parser.parse_args()setup_seed(args.seed)batch_size = args.batch_sizeload_batch_size = min(args.max_device_batch_size, batch_size)assert batch_size % load_batch_size == 0steps_per_update = batch_size // load_batch_size
这段代码是一个主程序,用于设置和启动一个深度学习训练过程,具体是针对一个视觉Transformer(ViT)模型。以下是对代码的逐行解释:
-
导入必要的库和模块:
os: 操作系统相关的库,尽管在这段代码中没有直接使用。argparse: 用于处理命令行参数。math: 数学函数库,尽管在这段代码中没有直接使用。torch和torchvision: PyTorch库,用于深度学习。SummaryWriter: 用于在TensorBoard中记录训练信息。ToTensor,Compose,Normalize: 这些是torchvision.transforms中的预处理方法。tqdm: 一个进度条库,用于显示训练进度。
-
模型和工具的导入:
- 从
model模块导入视觉Transformer模型。 - 从
utils模块导入setup_seed函数。
- 从
-
定义命令行参数:
- 使用
argparse解析命令行参数。 --seed: 随机种子,用于确保实验可重复性。--batch_size: 批处理大小,即一次训练的数据量。--max_device_batch_size: 设备上最大的批处理大小。这通常是为了在分布式环境中分配数据,或者在GPU内存有限的情况下使用。--base_learning_rate: 基础学习率,用于优化算法。--weight_decay: 权重衰减,正则化的一部分,防止模型过拟合。--total_epoch: 总训练周期数。--warmup_epoch: 预热周期数,可能在开始时逐步增加学习率。--pretrained_model_path: 预训练模型的路径(如果提供的话)。--output_model_path: 训练后保存模型的路径。- 使用
parser.parse_args()获取用户输入的参数。
- 使用
-
设置随机种子:
- 使用
setup_seed(args.seed)确保实验的可重复性。
- 使用
-
确定批处理大小和其他参数:
batch_size是用户指定的批处理大小。load_batch_size是设备上实际使用的批处理大小,通常是batch_size和max_device_batch_size中的较小值。steps_per_update是每个模型更新所用的步数,它通过将batch_size除以load_batch_size来计算。这通常用于在分布式环境中同步模型参数。
数据加载和预处理
train_dataset = torchvision.datasets.CIFAR10('data', train=True, download=True, transform=Compose([ToTensor(), Normalize(0.5, 0.5)]))val_dataset = torchvision.datasets.CIFAR10('data', train=False, download=True, transform=Compose([ToTensor(), Normalize(0.5, 0.5)]))train_dataloader = torch.utils.data.DataLoader(train_dataset, load_batch_size, shuffle=True, num_workers=4)val_dataloader = torch.utils.data.DataLoader(val_dataset, load_batch_size, shuffle=False, num_workers=4)
用于加载CIFAR-10数据集,并将其分为训练集和验证集。代码详解:
-
train_dataset = torchvision.datasets.CIFAR10('data', train=True, download=True, transform=Compose([ToTensor(), Normalize(0.5, 0.5)]))torchvision.datasets.CIFAR10('data', train=True, download=True, transform=Compose([ToTensor(), Normalize(0.5, 0.5)])): 这行代码用于加载CIFAR-10数据集的训练集。'data':数据集的存储路径。train=True:表示加载训练集。download=True:如果数据集不在指定路径下,则自动下载数据集。transform=Compose([ToTensor(), Normalize(0.5, 0.5)]):定义数据预处理流程,包括将PIL图像转换为PyTorch张量(ToTensor())和归一化(Normalize(0.5, 0.5))。归一化的参数是均值和标准差,这里分别设为0.5和0.5。
-
val_dataset = torchvision.datasets.CIFAR10('data', train=False, download=True, transform=Compose([ToTensor(), Normalize(0.5, 0.5)]))- 这行代码与第一行类似,但是用于加载CIFAR-10数据集的验证集。
train=False表示加载验证集。
- 这行代码与第一行类似,但是用于加载CIFAR-10数据集的验证集。
-
train_dataloader = torch.utils.data.DataLoader(train_dataset, load_batch_size, shuffle=True, num_workers=4)torch.utils.data.DataLoader(...): 创建一个数据加载器,用于按批次加载数据。train_dataset:要加载的数据集。load_batch_size:每个批次的数据量大小。注意这里有一个错误:变量名应该是batch_size而不是load_batch_size。shuffle=True:在每个训练时代开始时打乱数据顺序。num_workers=4:使用4个子进程加载数据,可以加快数据加载速度。
-
val_dataloader = torch.utils.data.DataLoader(val_dataset, load_batch_size, shuffle=False, num_workers=4)- 这行代码与上一行类似,但是用于加载验证集,并且不进行数据打乱(
shuffle=False)。
- 这行代码与上一行类似,但是用于加载验证集,并且不进行数据打乱(
设置模型、优化器、损失函数、学习率
device = 'cuda' if torch.cuda.is_available() else 'cpu'if args.pretrained_model_path is not None:model = torch.load(args.pretrained_model_path, map_location='cpu')writer = SummaryWriter(os.path.join('logs', 'cifar10', 'pretrain-cls'))else:model = MAE_ViT()writer = SummaryWriter(os.path.join('logs', 'cifar10', 'scratch-cls'))model = ViT_Classifier(model.encoder, num_classes=10).to(device)if device == 'cuda':net = torch.nn.DataParallel(model)loss_fn = torch.nn.CrossEntropyLoss()acc_fn = lambda logit, label: torch.mean((logit.argmax(dim=-1) == label).float())optim = torch.optim.AdamW(model.parameters(), lr=args.base_learning_rate * args.batch_size / 256, betas=(0.9, 0.999), weight_decay=args.weight_decay)lr_func = lambda epoch: min((epoch + 1) / (args.warmup_epoch + 1e-8), 0.5 * (math.cos(epoch / args.total_epoch * math.pi) + 1))lr_scheduler = torch.optim.lr_scheduler.LambdaLR(optim, lr_lambda=lr_func, verbose=True)
这段代码主要关于使用PyTorch库设置和初始化一个深度学习模型(具体来说是一个视觉Transformer模型),并定义了优化器、损失函数、学习率调整器等。代码详解:
-
device = 'cuda' if torch.cuda.is_available() else 'cpu':- 这行代码检查是否有可用的CUDA设备(即GPU)。如果有,则使用CUDA设备(即GPU)进行计算;否则,使用CPU。
-
检查是否提供了预训练的模型路径:
- 如果提供了预训练模型路径 (
args.pretrained_model_path is not None),则从该路径加载预训练的模型,并初始化一个用于记录训练信息的SummaryWriter对象。 - 如果没有提供预训练模型路径,则创建一个新的视觉Transformer模型。
- 如果提供了预训练模型路径 (
-
model = ViT_Classifier(model.encoder, num_classes=10).to(device):- 这行代码初始化了一个分类器模型,该模型使用预定义的编码器(可能是从预训练模型中获取的)和10个类别。然后,它将模型移动到之前确定的设备(CPU或GPU)上。
-
if device == 'cuda': net = torch.nn.DataParallel(model):- 如果使用GPU(即
device == 'cuda'),则使用DataParallel来多GPU并行化模型。这允许你在多个GPU上运行模型。
- 如果使用GPU(即
-
loss_fn = torch.nn.CrossEntropyLoss():- 定义交叉熵损失函数,这是分类问题中常用的损失函数。
-
acc_fn = lambda logit, label: torch.mean((logit.argmax(dim=-1) == label).float()):- 定义一个lambda函数作为准确率计算函数。它取模型的输出(logits)和真实标签,计算分类的准确率。
-
optim = torch.optim.AdamW(model.parameters(), lr=args.base_learning_rate * args.batch_size / 256, betas=(0.9, 0.999), weight_decay=args.weight_decay):- 定义一个AdamW优化器,用于更新模型的权重。学习率、动量值和权重衰减都作为参数传递给这个优化器。
-
lr_func = lambda epoch: min((epoch + 1) / (args.warmup_epoch + 1e-8), 0.5 * (math.cos(epoch / args.total_epoch * math.pi) + 1)):- 定义一个学习率调整函数。这个函数在开始时线性增加(warm-up阶段),然后在训练过程中逐渐减少。
-
lr_scheduler = torch.optim.lr_scheduler.LambdaLR(optim, lr_lambda=lr_func, verbose=True):- 使用前面定义的学习率调整函数创建一个学习率调度器。这个调度器会在每个epoch时根据
lr_func来调整学习率。
- 使用前面定义的学习率调整函数创建一个学习率调度器。这个调度器会在每个epoch时根据
训练和验证
best_val_acc = 0step_count = 0optim.zero_grad()for e in range(args.total_epoch):model.train()losses = []acces = []train_step = len(train_dataloader)with tqdm(total=train_step,desc=f'Train Epoch {e+1}/{args.total_epoch}',postfix=dict,mininterval=0.3) as pbar:for img, label in iter(train_dataloader):step_count += 1img = img.to(device)label = label.to(device)logits = model(img)loss = loss_fn(logits, label)acc = acc_fn(logits, label)loss.backward()if step_count % steps_per_update == 0:optim.step()optim.zero_grad()losses.append(loss.item())acces.append(acc.item())pbar.set_postfix(**{'Train Loss' : np.mean(losses),'Tran accs': np.mean(acces)})pbar.update(1)lr_scheduler.step()avg_train_loss = sum(losses) / len(losses)avg_train_acc = sum(acces) / len(acces)model.eval()with torch.no_grad():losses = []acces = []val_step = len(val_dataloader)with tqdm(total=val_step,desc=f'Val Epoch {e+1}/{args.total_epoch}',postfix=dict,mininterval=0.3) as pbar2:for img, label in iter(val_dataloader):img = img.to(device)label = label.to(device)logits = model(img)loss = loss_fn(logits, label)acc = acc_fn(logits, label)losses.append(loss.item())acces.append(acc.item())pbar2.set_postfix(**{'Val Loss' : np.mean(losses),'Val accs': np.mean(acces)})pbar2.update(1) avg_val_loss = sum(losses) / len(losses)avg_val_acc = sum(acces) / len(acces)if avg_val_acc > best_val_acc:best_val_acc = avg_val_accprint(f'saving best model with acc {best_val_acc} at {e} epoch!') torch.save(model, args.output_model_path)writer.add_scalars('cls/loss', {'train' : avg_train_loss, 'val' : avg_val_loss}, global_step=e)writer.add_scalars('cls/acc', {'train' : avg_train_acc, 'val' : avg_val_acc}, global_step=e)
代码详解:
-
初始化变量:
best_val_acc:用于存储验证集上的最佳准确率,但在这段代码中并没有直接使用。step_count:记录训练步骤的总数,用于判断是否进行权重更新。optim.zero_grad():清除优化器中的梯度信息,为新的训练迭代做准备。
-
主训练循环:
for e in range(args.total_epoch):这行代码开始了一个循环,将遍历
args.total_epoch个训练周期(epochs)。 -
模型设置为训练模式:
model.train()将模型设置为训练模式,这将启用例如dropout等仅在训练时使用的层。
-
初始化用于记录每个epoch的损失和准确率的列表:
losses = [] acces = [] -
设置进度条:
with tqdm(total=train_step,desc=f'Train Epoch {e+1}/{args.total_epoch}',postfix=dict,mininterval=0.3) as pbar:使用
tqdm库显示训练进度条,total=train_step表示进度条的总长度(即数据加载器的长度),desc描述了当前的训练状态。 -
遍历训练数据加载器:
for img, label in iter(train_dataloader):从
train_dataloader中按批次获取图像(img)和标签(label)。 -
训练步骤:
- 将图像和标签移动到相应的设备上(CPU或GPU):
img = img.to(device) label = label.to(device) - 前向传播:计算模型的输出(logits)。
logits = model(img) - 计算损失:
loss = loss_fn(logits, label) - 计算准确率:
acc = acc_fn(logits, label) - 反向传播:计算梯度。
loss.backward() - 更新权重(根据
steps_per_update):
这里,权重不是每个批次都更新,而是每if step_count % steps_per_update == 0:optim.step()optim.zero_grad()steps_per_update步更新一次。
- 将图像和标签移动到相应的设备上(CPU或GPU):
-
记录损失和准确率:
losses.append(loss.item()) acces.append(acc.item()) -
更新进度条:
pbar.set_postfix(**{'Train Loss' : np.mean(losses), 'Tran accs': np.mean(acces)}) pbar.update(1)使用numpy计算到目前为止的平均损失和准确率,并更新进度条的后缀信息。
-
每个epoch结束后,更新学习率:
lr_scheduler.step() -
计算并存储该epoch的平均损失和准确率:
avg_train_loss = sum(losses) / len(losses) avg_train_acc = sum(acces) / len(acces) -
将模型设置为评估模式:
model.eval()
这将关闭模型中所有定义为训练专用的层,如dropout层,并确保它们在推理时不会改变数据。
- 禁用梯度计算:
with torch.no_grad():
在验证期间,不需要计算梯度,因为不会更新权重。使用torch.no_grad()可以节省内存并提高验证速度。
- 初始化用于记录验证损失的列表:
losses = []
acces = []
- 设置进度条以显示验证进度:
with tqdm(total=val_step, desc=f'Val Epoch {e+1}/{args.total_epoch}', postfix=dict, mininterval=0.3) as pbar2:
使用tqdm库来显示验证集的进度条。
- 遍历验证数据加载器:
for img, label in iter(val_dataloader):
从val_dataloader中按批次获取验证图像(img)和标签(label)。
- 进行前向传播并计算损失和准确率:
img = img.to(device)
label = label.to(device)
logits = model(img)
loss = loss_fn(logits, label)
acc = acc_fn(logits, label)
将图像和标签移动到相应的设备上,计算模型的输出(logits),然后根据输出和真实标签计算损失和准确率。
- 记录损失和准确率:
losses.append(loss.item())
acces.append(acc.item())
- 更新进度条信息:
pbar2.set_postfix(**{'Val Loss' : np.mean(losses), 'Val accs': np.mean(acces)})
pbar2.update(1)
使用numpy计算到目前为止的平均验证损失和准确率,并更新进度条的后缀信息。
- 计算并存储平均验证损失和准确率:
avg_val_loss = sum(losses) / len(losses)
avg_val_acc = sum(acces) / len(acces)
-
检查并保存最佳模型:
if avg_val_acc > best_val_acc:best_val_acc = avg_val_accprint(f'saving best model with acc {best_val_acc} at {e} epoch!')torch.save(model, args.output_model_path)如果当前验证准确率高于之前的最佳准确率,则更新最佳准确率,并保存当前模型。注意,这里
torch.save(model, args.output_model_path)应该保存模型的参数而不是整个模型对象,通常的做法是torch.save(model.state_dict(), args.output_model_path)。 -
使用TensorBoard记录损失和准确率:
writer.add_scalars('cls/loss', {'train' : avg_train_loss, 'val' : avg_val_loss}, global_step=e) writer.add_scalars('cls/acc', {'train' : avg_train_acc, 'val' : avg_val_acc}, global_step=e)这段代码将训练损失、验证损失、训练准确率和验证准确率记录到TensorBoard中,以便进行可视化分析。这里的
writer是torch.utils.tensorboard.SummaryWriter的一个实例,global_step=e表示当前的全局步骤(通常是当前的epoch数)。
第二步 训练MAE模型
训练MAE模型使用mae_pretrain.py脚本,执行运行脚本或者在命令行中运行都可以!
接下来对mae_pretrain.py里的代码做一些解释!
设置超参数
if __name__ == '__main__':parser = argparse.ArgumentParser()parser.add_argument('--seed', type=int, default=42)parser.add_argument('-bs','--batch_size', type=int, default=4096)parser.add_argument('--max_device_batch_size', type=int, default=128)parser.add_argument('--base_learning_rate', type=float, default=1.5e-4)parser.add_argument('--weight_decay', type=float, default=0.05)parser.add_argument('--mask_ratio', type=float, default=0.75)parser.add_argument('--total_epoch', type=int, default=2000)parser.add_argument('--warmup_epoch', type=int, default=200)parser.add_argument('--model_path', type=str, default='vit-t-mae.pth')args = parser.parse_args()setup_seed(args.seed)batch_size = args.batch_sizeload_batch_size = min(args.max_device_batch_size, batch_size)assert batch_size % load_batch_size == 0steps_per_update = batch_size // load_batch_size
这段代码是Python脚本,用于配置和初始化机器学习训练过程的参数。这段代码主要使用Python的argparse模块来处理命令行参数。代码详解:
-
if __name__ == '__main__'::这一行确保下面的代码只在直接运行这个脚本时执行,而不是在其他地方导入这个脚本时执行。 -
parser = argparse.ArgumentParser():创建一个新的命令行参数解析器。 -
parser.add_argument('--seed', type=int, default=42):添加一个命令行参数--seed,类型为整数,默认值为42。这个参数通常用于设置随机数生成器的种子,以确保实验的可重复性。 -
parser.add_argument('-bs','--batch_size', type=int, default=4096):添加一个命令行参数-bs或--batch_size,类型为整数,默认值为4096。这个参数用于设置训练时的批量大小。 -
parser.add_argument('--max_device_batch_size', type=int, default=128):添加一个命令行参数--max_device_batch_size,类型为整数,默认值为128。这个参数用于设置设备上最大的批量大小。 -
parser.add_argument('--base_learning_rate', type=float, default=1.5e-4):添加一个命令行参数--base_learning_rate,类型为浮点数,默认值为1.5e-4。这个参数用于设置基础学习率。 -
parser.add_argument('--weight_decay', type=float, default=0.05):添加一个命令行参数--weight_decay,类型为浮点数,默认值为0.05。这个参数用于设置权重衰减,通常用于正则化。 -
parser.add_argument('--mask_ratio', type=float, default=0.75):添加一个命令行参数--mask_ratio,类型为浮点数,默认值为0.75。这个参数的具体用途取决于具体的模型和任务,可能是用于掩码某些输入或输出。 -
parser.add_argument('--total_epoch', type=int, default=2000):添加一个命令行参数--total_epoch,类型为整数,默认值为2000。这个参数用于设置训练的总轮数。 -
parser.add_argument('--warmup_epoch', type=int, default=200):添加一个命令行参数--warmup_epoch,类型为整数,默认值为200。这个参数用于设置预热轮数,通常在训练开始时使用较小的学习率。 -
parser.add_argument('--model_path', type=str, default='vit-t-mae.pth'):添加一个命令行参数--model_path,类型为字符串,默认值为’vit-t-mae.pth’。这个参数用于设置模型文件的路径。 -
args = parser.parse_args():解析命令行参数并将结果存储在变量args中。 -
setup_seed(args.seed):调用一个名为setup_seed的函数,并传入命令行参数中设置的种子值。这个函数可能用于设置随机数生成器的种子,以确保实验的可重复性。 -
接下来的几行代码用于计算批量大小和其他相关参数:
batch_size = args.batch_size:将批量大小存储在变量batch_size中。load_batch_size = min(args.max_device_batch_size, batch_size):计算设备上最大的批量大小,并将其存储在变量load_batch_size中。assert batch_size % load_batch_size == 0:断言批量大小是设备批量大小的整数倍,以确保数据可以均匀地分配到设备上。steps_per_update = batch_size // load_batch_size:计算每个更新步骤中的批次数,并将其存储在变量steps_per_update中。
数据集加载和预处理
train_dataset = torchvision.datasets.CIFAR10('data', train=True, download=True, transform=Compose([ToTensor(), Normalize(0.5, 0.5)]))val_dataset = torchvision.datasets.CIFAR10('data', train=False, download=True, transform=Compose([ToTensor(), Normalize(0.5, 0.5)]))dataloader = torch.utils.data.DataLoader(train_dataset, load_batch_size, shuffle=True, num_workers=4)writer = SummaryWriter(os.path.join('logs', 'cifar10', 'mae-pretrain'))
这段代码是使用PyTorch库来加载CIFAR-10数据集,并对数据进行预处理。CIFAR-10是一个常用的图像分类数据集,包含60000张32x32的彩色图像,分为10个类别。代码详解:
train_dataset = torchvision.datasets.CIFAR10('data', train=True, download=True, transform=Compose([ToTensor(), Normalize(0.5, 0.5)]))
这行代码创建了一个用于训练的数据集。数据集被下载到’data’目录(如果还没有被下载的话)。数据集中的图像被转换为一个PyTorch张量(ToTensor()),并归一化到均值为0.5,标准差为0.5(Normalize(0.5, 0.5))。
2. val_dataset = torchvision.datasets.CIFAR10('data', train=False, download=True, transform=Compose([ToTensor(), Normalize(0.5, 0.5)]))
这行代码创建了一个用于验证的数据集。验证数据集不包含在原始CIFAR-10数据集中,需要通过train=False来指定。图像同样被转换为一个PyTorch张量并归一化。
3. dataloader = torch.utils.data.DataLoader(train_dataset, load_batch_size, shuffle=True, num_workers=4)
使用DataLoader创建一个数据加载器,用于从训练数据集中批量加载数据。load_batch_size是每个批次中的样本数(注意:代码中没有给出load_batch_size的具体值,可能是在其他地方定义的)。shuffle=True表示在每个训练时代开始时打乱数据顺序。num_workers=4指定使用4个子进程来加载数据,可以加速数据加载。
4. writer = SummaryWriter(os.path.join('logs', 'cifar10', 'mae-pretrain'))
这行代码创建了一个SummaryWriter对象,用于写入TensorBoard可用的日志。这些日志可以用来监视训练过程。日志文件将被写入到’logs/cifar10/mae-pretrain’目录中。
设置模型、优化器、学习率、调度器等
device = 'cuda' if torch.cuda.is_available() else 'cpu'model = MAE_ViT(mask_ratio=args.mask_ratio).to(device)if device == 'cuda':net = torch.nn.DataParallel(model)optim = torch.optim.AdamW(model.parameters(), lr=args.base_learning_rate * args.batch_size / 256, betas=(0.9, 0.95), weight_decay=args.weight_decay)lr_func = lambda epoch: min((epoch + 1) / (args.warmup_epoch + 1e-8), 0.5 * (math.cos(epoch / args.total_epoch * math.pi) + 1))lr_scheduler = torch.optim.lr_scheduler.LambdaLR(optim, lr_lambda=lr_func, verbose=True)
这段代码是关于使用PyTorch库设置和初始化一个深度学习模型(具体是一个MAE_ViT模型)的训练过程。以下是对代码的逐行解释:
device = 'cuda' if torch.cuda.is_available() else 'cpu'
这行代码检查是否有可用的CUDA环境(通常指的是NVIDIA的GPU)。如果有,则device被设置为’cuda’,意味着模型将在GPU上进行训练。否则,device被设置为’cpu’,表示模型将在CPU上进行训练。
2. model = MAE_ViT(mask_ratio=args.mask_ratio).to(device)
这里创建了一个MAE_ViT模型的实例,并使用命令行参数args.mask_ratio来初始化它。然后,使用.to(device)方法将模型移动到之前确定的设备(CPU或GPU)上。
3. if device == 'cuda':
net = torch.nn.DataParallel(model)
如果设备是GPU(即设备为’cuda’),则使用torch.nn.DataParallel来创建模型的并行版本,这意味着模型可以在多个GPU上运行。这样做的目的是为了加速训练过程。
4. optim = torch.optim.AdamW(model.parameters(), lr=args.base_learning_rate * args.batch_size / 256, betas=(0.9, 0.95), weight_decay=args.weight_decay)
这里初始化了一个AdamW优化器。优化器是用于在训练过程中更新模型参数的算法。参数包括学习率、beta值和权重衰减。学习率被设置为args.base_learning_rate * args.batch_size / 256,其中256是一个常数,用于调整学习率的大小。
5. lr_func = lambda epoch: min((epoch + 1) / (args.warmup_epoch + 1e-8), 0.5 * (math.cos(epoch / args.total_epoch * math.pi) + 1))
这里定义了一个学习率函数lr_func,它基于当前的训练时代(epoch)来调整学习率。在初始阶段(warmup_epoch),学习率会线性增加,之后会按照余弦退火的方式减小。
6. lr_scheduler = torch.optim.lr_scheduler.LambdaLR(optim, lr_lambda=lr_func, verbose=True)
这里使用LambdaLR学习率调度器,它根据前面定义的学习率函数lr_func来调整优化器的学习率。verbose=True意味着在每个时代开始时,学习率调整信息会被打印出来。
训练与验证
step_count = 0optim.zero_grad()for e in range(args.total_epoch):model.train()losses = []train_step = len(dataloader)with tqdm(total=train_step,desc=f'Epoch {e+1}/{args.total_epoch}',postfix=dict,mininterval=0.3) as pbar:for img, label in iter(dataloader):step_count += 1img = img.to(device)predicted_img, mask = model(img)loss = torch.mean((predicted_img - img) ** 2 * mask) / args.mask_ratioloss.backward()if step_count % steps_per_update == 0:optim.step()optim.zero_grad()losses.append(loss.item())pbar.set_postfix(**{'Loss' : np.mean(losses)})pbar.update(1)lr_scheduler.step()avg_loss = sum(losses) / len(losses)writer.add_scalar('mae_loss', avg_loss, global_step=e)''' visualize the first 16 predicted images on val dataset'''model.eval()with torch.no_grad():val_img = torch.stack([val_dataset[i][0] for i in range(16)])val_img = val_img.to(device)predicted_val_img, mask = model(val_img)predicted_val_img = predicted_val_img * mask + val_img * (1 - mask)img = torch.cat([val_img * (1 - mask), predicted_val_img, val_img], dim=0)img = rearrange(img, '(v h1 w1) c h w -> c (h1 h) (w1 v w)', w1=2, v=3)writer.add_image('mae_image', (img + 1) / 2, global_step=e)''' save model '''torch.save(model, args.model_path)
代码详解:
step_count = 0:初始化步数计数器为0。optim.zero_grad():清除优化器中累积的梯度。for e in range(args.total_epoch)::开始一个循环,代表整个训练周期。model.train():设置模型为训练模式。losses = []:初始化一个空列表来存储每个批次的损失。train_step = len(dataloader):获取训练数据加载器的长度,即总的训练批次数。with tqdm(total=train_step,desc=f'Epoch {e+1}/{args.total_epoch}',postfix=dict,mininterval=0.3) as pbar::使用tqdm库创建一个进度条。for img, label in iter(dataloader)::遍历数据加载器中的数据。step_count += 1:增加步数计数器。img = img.to(device):将图像数据移动到指定的设备(CPU或GPU)。predicted_img, mask = model(img):通过模型预测图像和对应的掩码。loss = torch.mean((predicted_img - img) ** 2 * mask) / args.mask_ratio:计算损失,这里使用均方误差作为损失函数。loss.backward():反向传播,计算梯度。if step_count % steps_per_update == 0::如果满足一定的更新条件(例如每几个批次更新一次参数),则执行以下操作。optim.step():更新模型参数。optim.zero_grad():清除优化器中累积的梯度。losses.append(loss.item()):将当前批次的损失添加到列表中。pbar.set_postfix(**{'Loss' : np.mean(losses)}):更新进度条的显示信息,显示平均损失。pbar.update(1):更新进度条。lr_scheduler.step():根据学习率调度器调整学习率。avg_loss = sum(losses) / len(losses):计算平均损失。writer.add_scalar('mae_loss', avg_loss, global_step=e):将平均损失写入TensorBoard。- 以下部分是验证部分:
model.eval():设置模型为评估模式。- 使用
torch.no_grad()确保在验证过程中不计算梯度,以节省计算资源。 - 从验证数据集中获取图像数据并移动到指定设备。
- 通过模型预测图像和对应的掩码。
- 合成预测的图像和原始图像,形成对比。
- 使用
rearrange函数调整图像的维度顺序,以便于可视化。 - 使用
writer将图像写入TensorBoard。 - 最后,保存模型的状态字典到指定的路径。
总的来说,这段代码实现了MAE模型的训练和验证过程,包括损失的计算、模型的更新、学习率的调整、损失和图像的记录等步骤。
第三步 微调MAE训练的模型
利用训练好的MAE的encoder作为输入,构建的分类模型作为分类器。
在命令行中,运行:
python train_classifier.py --pretrained_model_path vit-t-mae.pth --output_model_path vit-t-classifier-from_pretrained.pth
或者将pretrained_model_path参数做修改,代码如下:
parser.add_argument('--pretrained_model_path', type=str, default='vit-t-mae.pth')
然后,右键直接运行。
结论
| Model | Validation Acc |
|---|---|
| ViT-Tw/o pretrain | 74.13 |
| ViT-T w/ pretrain | 89.77 |
可以看到,使用MAE后,ACC有了大幅度的提升!
从文章我们可以得出:MAE模型的encoder模型就是我们的主干网络,decoder模型是一个比encoder更简单的解码网络。
MAE模型训练时分步骤的:
首先,训练MAE的encoder模型,然后使用encoder模型做预训练去训练下游任务。
这篇关于MAE实战:使用MAE提高主干网络的精度(一)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






