本文主要是介绍场景文本检测识别学习 day06(Vi-Transformer论文精读、MAE论文阅读),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Vi-Transformer论文精读
- 在NLP领域,基于注意力的Transformer模型使用的非常广泛,但是在计算机视觉领域,注意力更多是和CNN一起使用,或者是单纯将CNN的卷积替换成注意力,但是整体的CNN 架构没有发生改变
- VIT说明,纯Transformer不使用CNN也可以在视觉领域表现很好,尤其是当我们在大规模数据集上做预训练,再去小数据集上做微调,可以获得跟最好的CNN相媲美的结果
- 在NLP领域,BERT提出的方法已经成为主流:先在大规模的数据集上做预训练,再去小数据集上做微调,同时由于Transformer模型的高扩展性和高效性,现在的数据集和模型可以做的越来越大,同时还没有任何性能饱和的现象,因此VIT想将Transformer应用到计算机视觉中
- 但是Transformer有以下的问题:
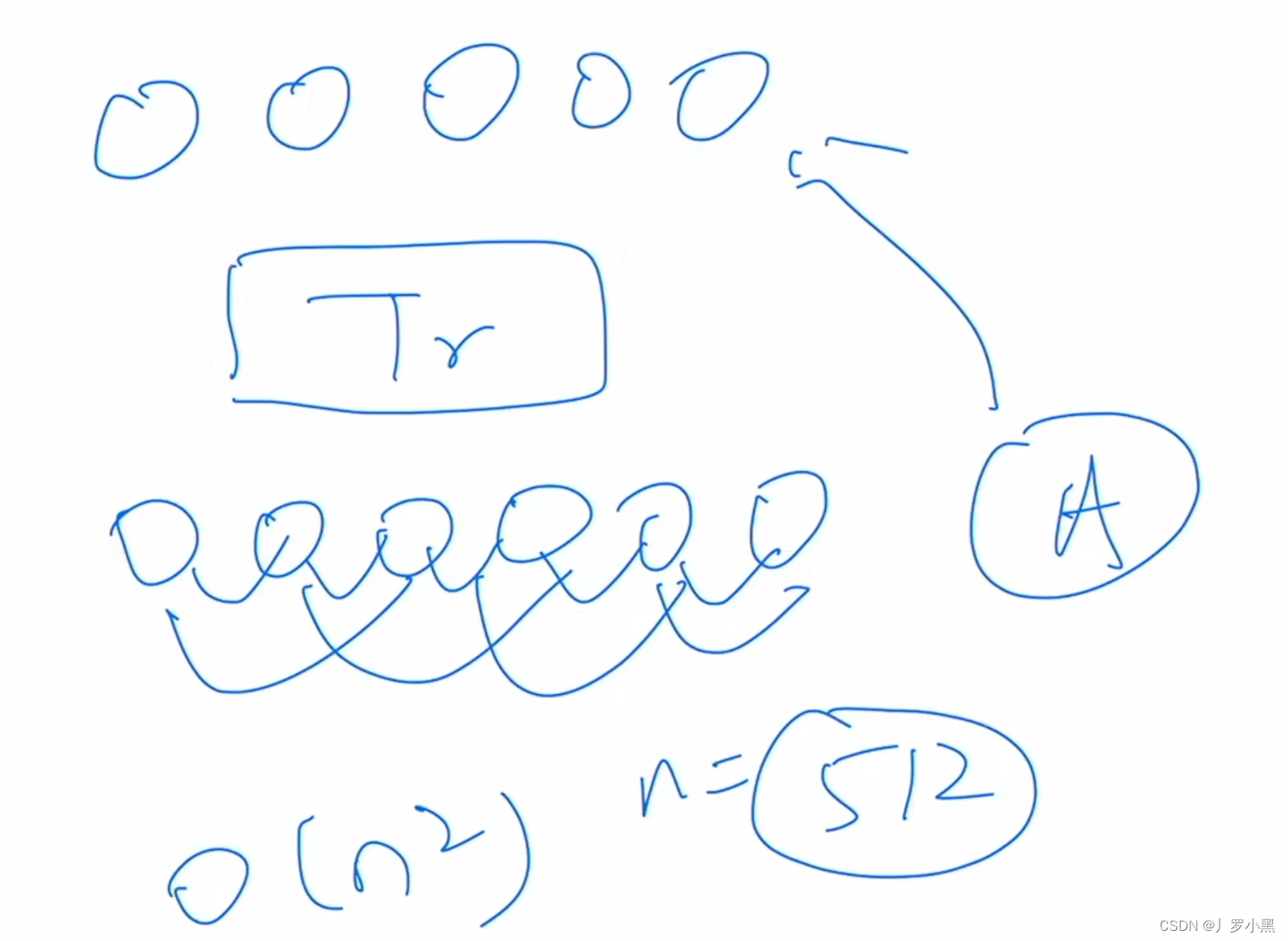
- Transformer中最主要的操作是自注意力操作,而自注意力操作是需要所有元素都要和所有元素去交互,两两相互的,计算得到的Attention,再将这个Attention去做加权平均,最后得到输出,因此自注意力的计算复杂度为 O ( n 2 ) O(n^2) O(n2),但是目前硬件能支持的这个序列长度n为几百或者上千,在BERT中n为512
- 但是在计算机视觉领域,如果我们想把2D的图片变成1D的序列,那么最简单最直观的方法就是把图片中的所有像素点当成序列的元素,直接拉直并输入进Transformer,一般来说在视觉领域,输入图片的尺寸为224224、800800等,将它直接拉直送入Transformer,得到的序列长度直接过万,计算复杂度太高,硬件跟不上
- 针对以上的问题,有如下的解决方案:
- Local Network:既然直接把像素点当作Transformer的输入太长,导致计算复杂度太高无法训练,那么我们把网络中间的特征图当作Transformer的输入,直接降低输入序列的长度,例如Res50的特征图只有14*14,这就是可以接受的范围之内了
- Stand-Alone Attention:孤立注意力,既然使用整张输入图片的复杂度太高,那么我们改为使用一个局部的小窗口,来缩小输入序列的长度。Axial Attention:轴注意力,将图片的宽高拆分为两个轴,因此225225的输入序列就变为了2225的输入序列,也降低了输入序列的长度。
- Sparse Attention:稀疏点注意力。Block Attention:将输入图片分块,进行注意力计算
- 以上这些解决方案虽然在CV上的结果都不错,但是需要很复杂的工程来加速运算。
- 虽然已经有人在视觉领域使用注意力,但是一个纯Transformer的CV模型还没有,而纯Transformer可以继承它在NLP的高扩展性,这就是VIT的想法
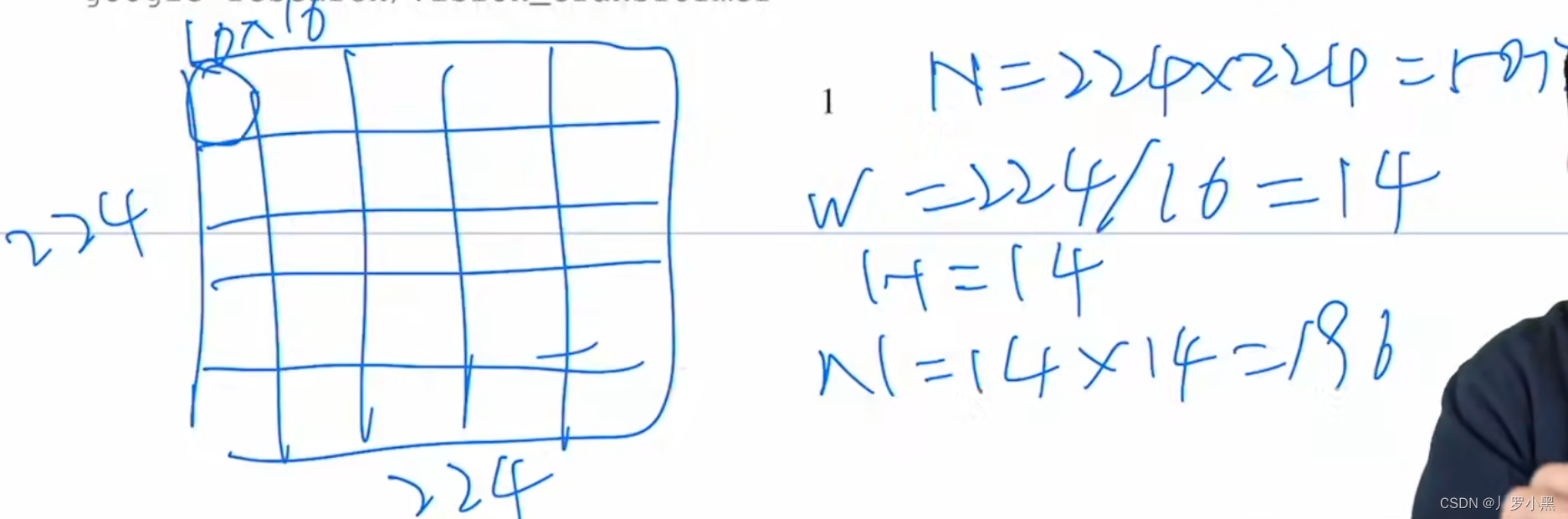
- VIT通过将图片分割为1616个块,来解决输入序列太长的问题,如果输入图片的尺寸为224224,那么分割后的每块的尺寸为1414(224/16 = 14),那么输入序列长度就变为1414,这个输入长度就是Transformer可接受的长度,这样在NLP中一个句子有多少个单词就转换为了在CV中一个图片有多少个patch。
- 同时不同于BERT的自监督训练方式,在VIT中,采用了有监督的方式来进行训练。同时类似于BERT,也仅仅使用了Transformer Encoder作为模型
- 在中等大小的数据集上进行训练(如ImageNet),如果不加强约束,VIT其实比同等大小的Resnet性能要弱。这主要是因为Transformer比CNN要缺少一些归纳偏置(先验知识):
- 局部性:由于卷积核是一步一步的在输入图片上进行移动卷积的,所以CNN假设图片上相邻的区域会有相似的特征
- 平移等变性:由于卷积核不考虑位置,所以在输入图片的不同的位置的相同物体,卷积核的输出是相同的,但是由于在Transformer中,加入了位置编码,所以不同位置的相同物体,Transformer Encoder的输出也不会相同
- 在大型数据集上进行训练,VIT就可以获得跟最好的CNN一样的性能,甚至可以超过它们
- VIT只是单纯的将输入图片做一个预处理,分割成16*16的块,然后送到Transformer中就可以了,其他什么改动都不需要,这样就可以把一个视觉问题理解成一个NLP问题,同时仅仅在分割图片和位置编码的时候,使用了图像特有的归纳偏置。因此不需要我们对CV领域有什么了解,直接把图片当成是一个序列的图像块,就跟一个句子有很多单词一样。然后就可以把NLP领域的标准Transformer来做图像分类,当把VIT加上大规模的数据集时,模型的性能表现出奇的好。
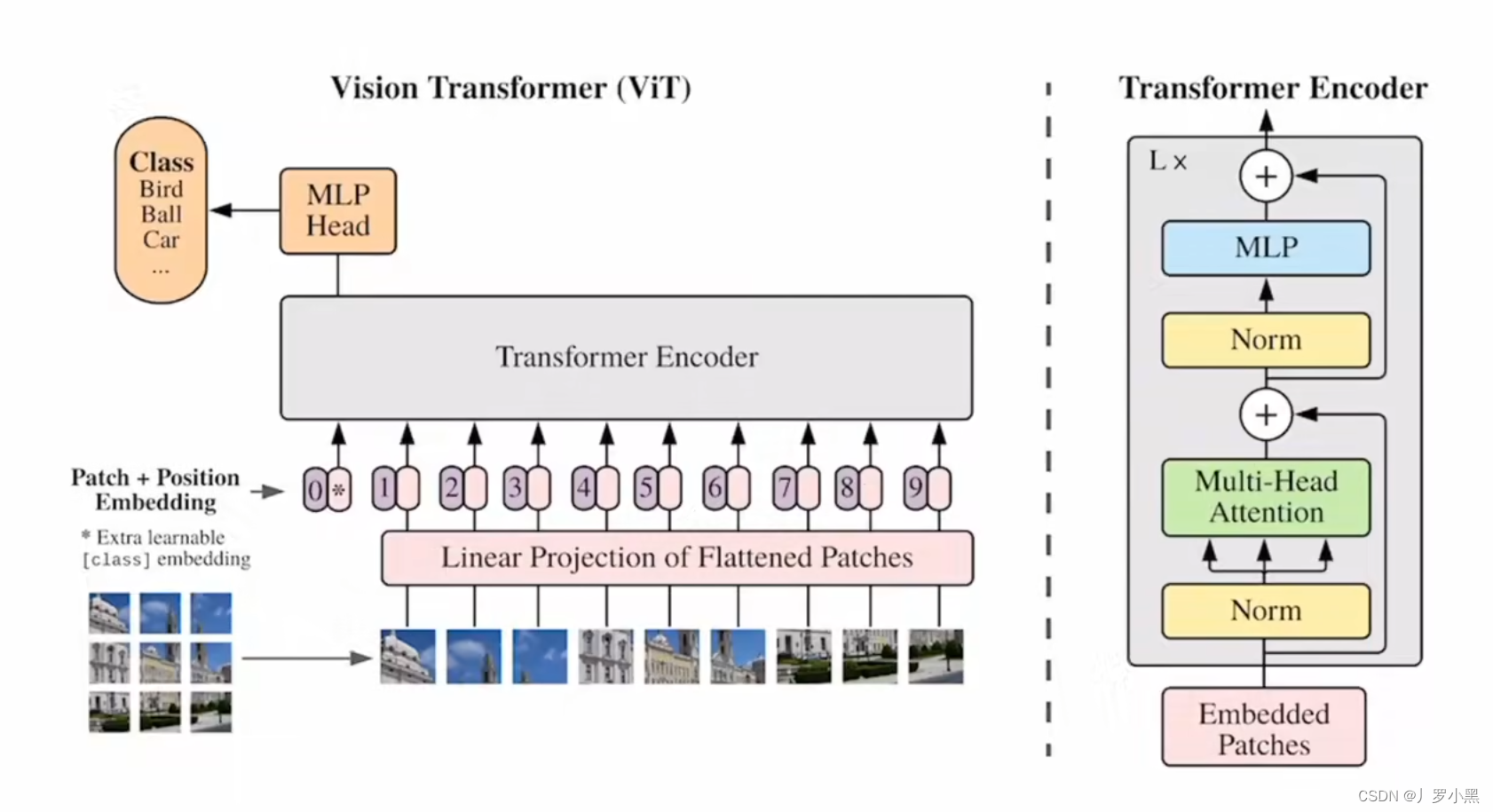
- VIT的模型设置是尽可能地按照最原始的Transformer的结构来设计,这样做的好处是可以直接把NLP中高效的模块部分,直接拿过来用
- VIT的流程如下:
- 先将输入图片分块,假设输入图片为 3 * 224 * 224 的尺寸,分成尺寸为 16 * 16 的块,那么可以得到196个块,每个块拉直后的尺寸为 3 * 16 * 16 = 768,3为通道数
- 将拉直后的块X,输入进全连接层E,E的尺寸为 768 * 768,后一个768为D,代表模型的大小可以改变,前一个768是每个块拉直后的尺寸不能改变,那么:X · E 的尺寸为196 * 768
- 类似于BERT,需要加入一个特殊字符 [ CLS ] 作为最后的分类输出,并且[ CLS ] 的位置信息为0,因为所有的输入块都在跟所有的输入块做注意力计算,所以我们假设第一个块 [ CLS ] 可以学到其他块的有用信息,那么可以只根据 [ CLS ] 的输出来做最后的分类判断即可,[ CLS ] 的尺寸为 1 * 768,所以整体输入的尺寸为 197 * 768
- 整体的输入还需要加上位置编码(这里为1D的可学习位置编码,类似BERT),由于是直接加上位置编码,所以整体的输入尺寸仍然为 197 * 768,即Embedded Patches的尺寸为 197 * 768
- 整体的输入先进入Layer Norm层,再进入Multi-Head Attention层,由于采用了多头(这里是12),所以每个头的K、Q、V的尺寸为 197 * 64,最后将这些头的输出拼接起来,最后的尺寸又变成197 * 768,再经过Layer Norm层,和MLP层,注意MLP一般会将输入的尺寸先放大再缩小,如这里先放大四倍变为 197 * 3072 ,再缩小投射回 197 * 768,最后就输出了
- 同时由于这个Transformer Encoder Block的输入尺寸等于输出尺寸,都是 197 * 768。所以可以直接叠加Block
- 在VIT用作分类任务时,直接将经过很多Encoder Block层的 [ CLS ] 当作VIT模型的最后输出,即整个图片的特征,然后添加一个MLP的分类头来实现分类任务
- 在CNN中,我们做分类任务,并不是类似于BERT的做法,使用 [ CLS ]来作为图片整体的特征进行输出,而是通过对特征图进行全局平均池化,得到一个拉直的向量,再通过这个向量来做分类。这里VIT由于想尽可能地接近Transformer,所以采用了BERT的方法,但是使用传统CNN的方法,效果差不多
- 注意:由于我们是先将图像块的全部像素点拉直后,输入进全连接层,得到抽象后的特征,此时这个特征代表了整个图像块的内容,我们可以看作这个特征具有了这个图像块内部的位置信息,因此只需要给出图像块之间的位置编码即可,图像块内部的位置信息就不需要再额外指定了
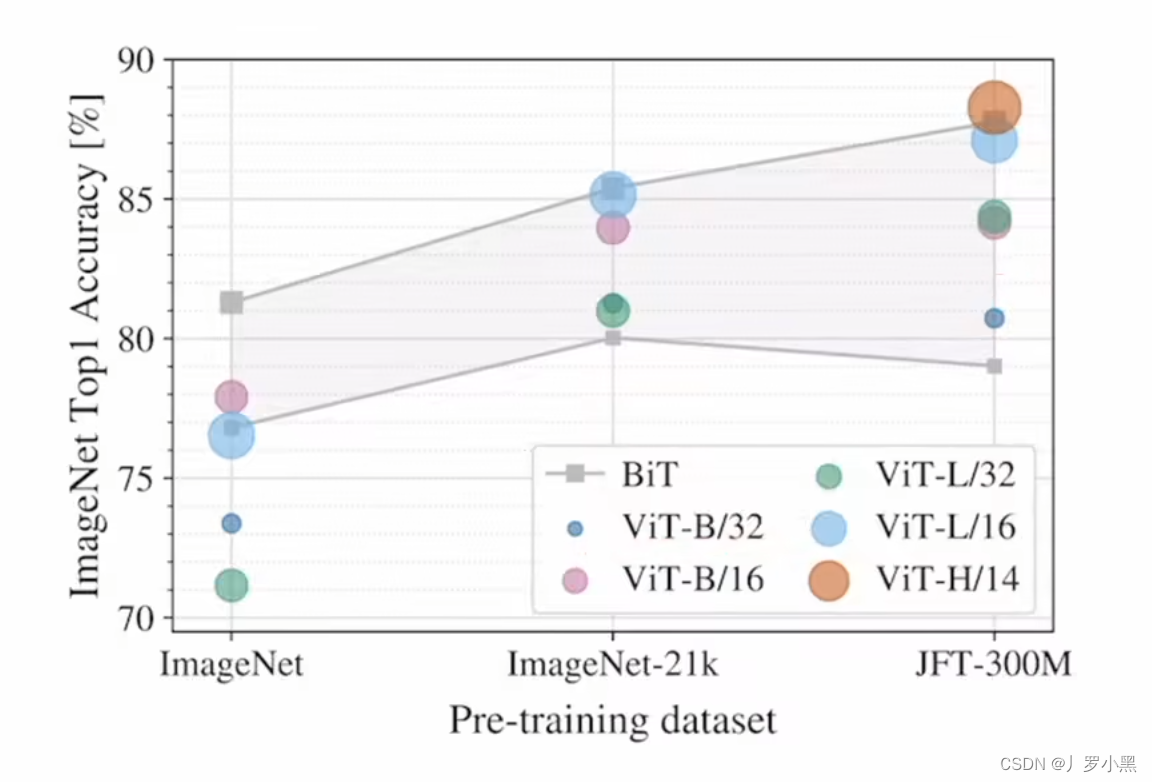
- 上图可以看出在小型数据集(ImageNet)上训练的时候,BiT(ResNet)的预训练效果要比ViT的效果好,在中等数据集(ImageNet-21K)及以上(JFT-300M)时ViT的预训练效果最好,因此如果只有较小的数据集,那么CNN的效果比较好
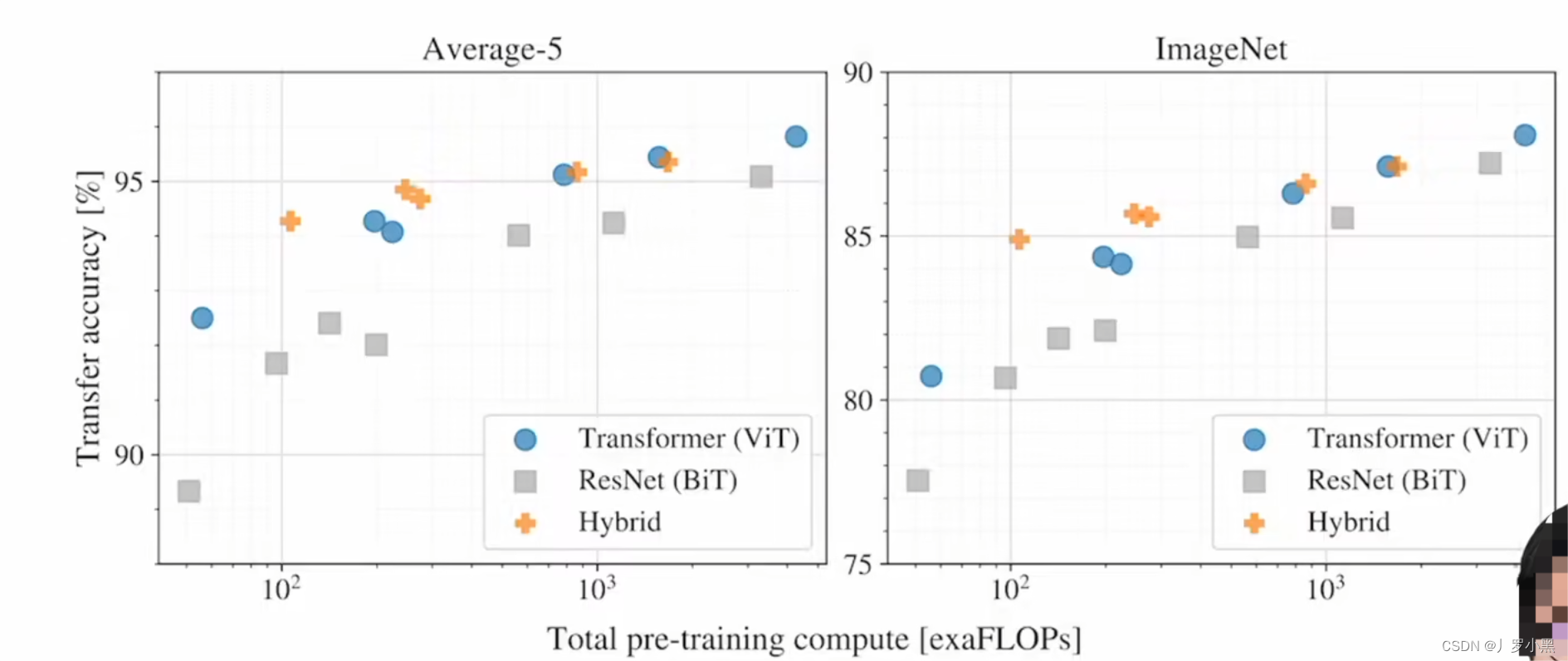
- 上图都是在JFT-300M的数据集上进行预训练得到的模型,可以看出:
- 在同等计算复杂度的情况下Transformer要比ResNet的性能好,这就证明了VIT说的:训练一个Transformer比训练一个CNN要便宜
- 在比较小的模型下,混合模型(CNN+Transformer)的性能最好,但是随着模型越来越大,混合模型的精度跟VIT差不多了,甚至在特别大的模型上,VIT的性能是最好的
- 在图片分类、目标检测这类简单的任务上,输出层(解码器)可能就是一个简单的全连接层,但是在语义分割这类复杂的任务上(需要对每一个像素做一个像素级别的输出),就不简简单单的使用一个全连接层,而是使用一个转置的CNN,来做一个比较大的解码器
位置编码
- 1D位置编码:有两种1D位置编码,BERT采用可学习的,原始Transformer采用固定的。1D位置编码的维度和输入特征向量的维度相同
- 2D位置编码:也有两种2D位置编码,可学习的,固定的。2D位置编码的维度分为两部分,假设输入特征向量的维度为D,那么前D/2和后D/2分别为横坐标和纵坐标的维度,将横坐标和纵坐标的维度拼接起来,就得到了维度为D的2D位置编码
- 注意:以上这两种都是绝对位置编码。
- 相对位置编码:如果是1D的情况,两个图像块之间的距离,可以用相对距离(间隔多少个图像块等方法)来表示。
- 由于VIT的图像块一共有14 * 14 = 196个,仍然是比较少的,所以不管使用哪种位置编码都可以得到差不多的性能
- 由于VIT的微调采取了更大尺寸的输入图片,但是如果保持patch size不变,那么会有更多的图像块,因此之前预训练的位置编码就不再适用了,这对这个问题VIT采用的是2D插值,因此2D插值和分图像块这两部分是VIT中唯一的两部分使用2D信息的归纳偏置
VIT挖的坑
- 由于VIT是做图片分类,但是Transformer不能只用来做图片分类,还有分割和检测任务,所以VIT-FRCNN(检测)、SETR(分割)在同年12月出现了
- 由于VIT使用的是有监督的训练方式,但是在NLP中大的Transformer模型,如BERT,使用的是自监督的训练方式,那么VIT可不可以也使用自监督的训练方式呢?
MAE论文阅读
- MAE是BERT在计算机视觉上的应用,即通过自监督的掩码训练机制,不需要使用有标号的数据集,而是通过预测一张图片中被MASK的部分,从而获取对图像进行特征抽取的能力。
- 虽然MAE不是第一个将BERT应用到CV上的,但是是最有影响力的一篇
- 由于BERT只需要预测下一个词是什么,任务将对简单,所以输出层(解码器)只需要一个全连接层即可,但是MAE需要还原出MASK块的所有像素,所以需要复杂一些的输出层(解码器),在MAE中,输出层的最后一层为一个线性层,用来重构出原始的像素,如果一块的尺寸为1616,那么线性层就会投影到长为256的一个维度,之后把它reshape到1616即可
- 由于对于CV来说,MASK如果只是少部分,那么我们可以通过选取邻近位置的像素点,进行插值,很容易得到一个近似的结果,所以MAE是将输入图像的大部分都MASK掉(如75%往上),那么模型就可以学习到更好的图像表征,即构造一个有挑战的任务来迫使模型学习一个复杂的解(而不是一个显然的解),从而获得更好的性能以及迁移学习效果
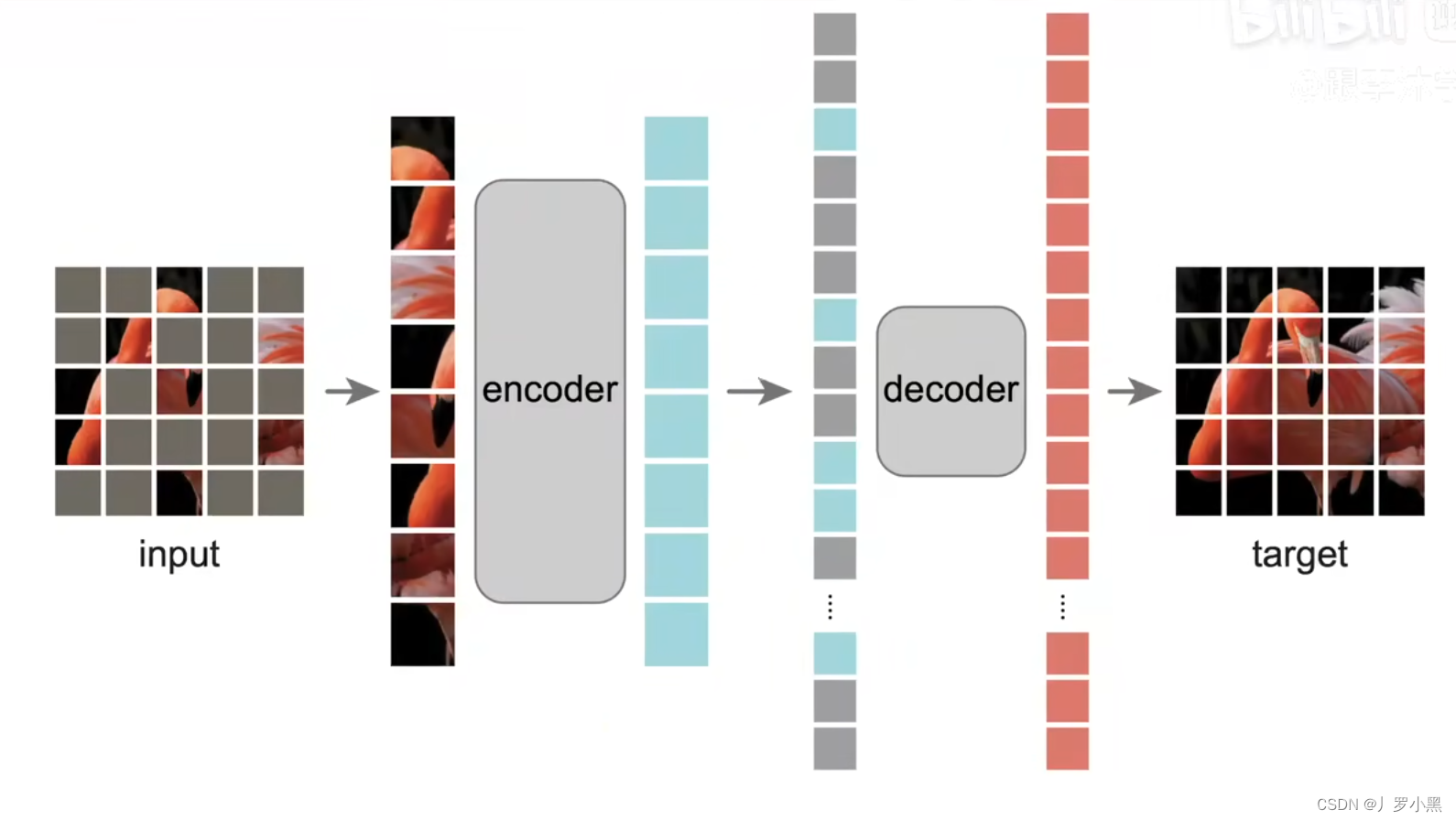
- MAE的编码器只会对没有被MASK的区域进行编码,从而加快计算,节省内存空间。之后先将编码器的输出放回到原本的位置上,并将被MASK的区域和没有被MASK的区域组合起来,加上位置编码后,再送入解码器得到还原后的特征,最后送入输出层得到还原的图片
- MAE的主要计算量来自编码器,同时编码器和解码器不是对称关系,因为编码器和解码器看到的图片不是一致的,编码器只看到了没有被MASK的部分,而解码器看到的是完整的,无论有没有被MASK
- MAE的结果是,在ImageNet-1K的数据集上,使用VIT-Huge的模型,可以得到87.8%的结果,VIT使用VIT-Huge在JFT-300M预训练,在ImageNet-1K的数据集上,得到的结果也才88.55%,同时MAE是主要用来做迁移学习,它的迁移学习能力也很好。
这篇关于场景文本检测识别学习 day06(Vi-Transformer论文精读、MAE论文阅读)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





