识别专题

使用PyTorch实现手写数字识别功能
《使用PyTorch实现手写数字识别功能》在人工智能的世界里,计算机视觉是最具魅力的领域之一,通过PyTorch这一强大的深度学习框架,我们将在经典的MNIST数据集上,见证一个神经网络从零开始学会识... 目录当计算机学会“看”数字搭建开发环境MNIST数据集解析1. 认识手写数字数据库2. 数据预处理的

Pytorch微调BERT实现命名实体识别
《Pytorch微调BERT实现命名实体识别》命名实体识别(NER)是自然语言处理(NLP)中的一项关键任务,它涉及识别和分类文本中的关键实体,BERT是一种强大的语言表示模型,在各种NLP任务中显著... 目录环境准备加载预训练BERT模型准备数据集标记与对齐微调 BERT最后总结环境准备在继续之前,确

讯飞webapi语音识别接口调用示例代码(python)
《讯飞webapi语音识别接口调用示例代码(python)》:本文主要介绍如何使用Python3调用讯飞WebAPI语音识别接口,重点解决了在处理语音识别结果时判断是否为最后一帧的问题,通过运行代... 目录前言一、环境二、引入库三、代码实例四、运行结果五、总结前言基于python3 讯飞webAPI语音

使用Python开发一个图像标注与OCR识别工具
《使用Python开发一个图像标注与OCR识别工具》:本文主要介绍一个使用Python开发的工具,允许用户在图像上进行矩形标注,使用OCR对标注区域进行文本识别,并将结果保存为Excel文件,感兴... 目录项目简介1. 图像加载与显示2. 矩形标注3. OCR识别4. 标注的保存与加载5. 裁剪与重置图像
Python爬虫selenium验证之中文识别点选+图片验证码案例(最新推荐)
《Python爬虫selenium验证之中文识别点选+图片验证码案例(最新推荐)》本文介绍了如何使用Python和Selenium结合ddddocr库实现图片验证码的识别和点击功能,感兴趣的朋友一起看... 目录1.获取图片2.目标识别3.背景坐标识别3.1 ddddocr3.2 打码平台4.坐标点击5.图

如何通过海康威视设备网络SDK进行Java二次开发摄像头车牌识别详解
《如何通过海康威视设备网络SDK进行Java二次开发摄像头车牌识别详解》:本文主要介绍如何通过海康威视设备网络SDK进行Java二次开发摄像头车牌识别的相关资料,描述了如何使用海康威视设备网络SD... 目录前言开发流程问题和解决方案dll库加载不到的问题老旧版本sdk不兼容的问题关键实现流程总结前言作为

阿里开源语音识别SenseVoiceWindows环境部署
SenseVoice介绍 SenseVoice 专注于高精度多语言语音识别、情感辨识和音频事件检测多语言识别: 采用超过 40 万小时数据训练,支持超过 50 种语言,识别效果上优于 Whisper 模型。富文本识别:具备优秀的情感识别,能够在测试数据上达到和超过目前最佳情感识别模型的效果。支持声音事件检测能力,支持音乐、掌声、笑声、哭声、咳嗽、喷嚏等多种常见人机交互事件进行检测。高效推

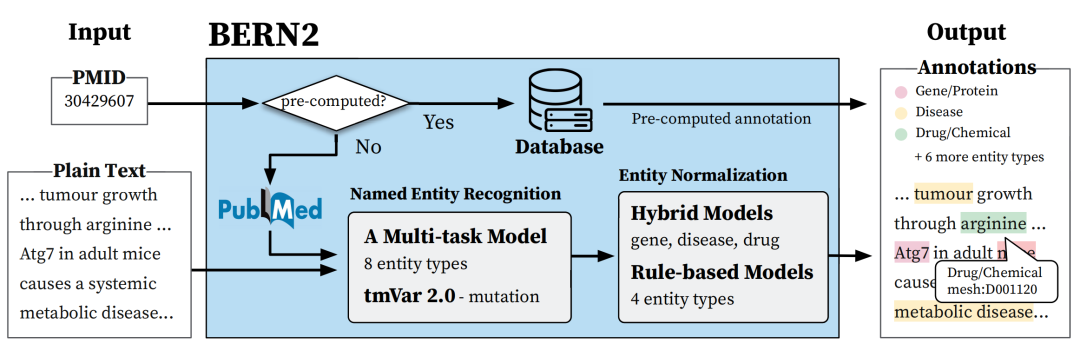
BERN2(生物医学领域)命名实体识别与命名规范化工具
BERN2: an advanced neural biomedical named entity recognition and normalization tool 《Bioinformatics》2022 1 摘要 NER和NEN:在生物医学自然语言处理中,NER和NEN是关键任务,它们使得从生物医学文献中自动提取实体(如疾病和药物)成为可能。 BERN2:BERN2是一个工具,


flutter开发实战-flutter build web微信无法识别二维码及小程序码问题
flutter开发实战-flutter build web微信无法识别二维码及小程序码问题 GitHub Pages是一个直接从GitHub存储库托管的静态站点服务,它允许用户通过简单的配置,将个人的代码项目转化为一个可以在线访问的网站。这里使用flutter build web来构建web发布到GitHub Pages。 最近通过flutter build web,通过发布到GitHu

T1打卡——mnist手写数字识别
🍨 本文为🔗365天深度学习训练营中的学习记录博客🍖 原作者:K同学啊 1.定义GPU import tensorflow as tfgpus=tf.config.list_physical_devices("GPU")if gpus:gpu0=gpus[0]tf.config.experimental.set_memort_groth(gpu0,True) #设置GPU现存用量按需

使用 VisionTransformer(VIT) FineTune 训练驾驶员行为状态识别模型
一、VisionTransformer(VIT) 介绍 大模型已经成为人工智能领域的热门话题。在这股热潮中,大模型的核心结构 Transformer 也再次脱颖而出证明了其强大的能力和广泛的应用前景。Transformer 自 2017年由Google提出以来,便在NLP领域掀起了一场革命。相较于传统的循环神经网络(RNN)和长短时记忆网络(LSTM), Transformer 凭借自注意力机制


mysql无法启动以及cmd下mysql命令无法识别的
1.mysql无法启动 解决方式: Win+R,输入services.msc,找到mysql服务 即默认的服务名是mysql55而不是mysql 2.mysql命令无法识别 直接输入mysql进入数据库报错 这是因为系统并不知道mysql是什么,我们需要在环境变量里添加mysql的安装地址中的bin目录地址。 C:\Program Files\My

Selenium 实现图片验证码识别
前言 在测试过程中,有的时候登录需要输入图片验证码。这时候使用Selenium进行自动化测试,怎么做图片验证码识别?本篇内容主要介绍使用Selenium、BufferedImage、Tesseract进行图片 验证码识别。 环境准备 jdk:1.8 tessdata:文章末尾附下载地址 安装Tesseract 我本地是ubuntu系统 sudo apt install tesserac
【DL--22】实现神经网络算法NeuralNetwork以及手写数字识别
1.NeuralNetwork.py #coding:utf-8import numpy as np#定义双曲函数和他们的导数def tanh(x):return np.tanh(x)def tanh_deriv(x):return 1.0 - np.tanh(x)**2def logistic(x):return 1/(1 + np.exp(-x))def logistic_derivati
【tensorflow CNN】构建cnn网络,识别mnist手写数字识别
#coding:utf8"""构建cnn网络,识别mnistinput conv1 padding max_pool([2,2],strides=[2,2]) conv2 x[-1,28,28,1] 卷积 [5,5,1,32] -> [-1,24,24,32]->[-1,28,
【tensorflow 全连接神经网络】 minist 手写数字识别
主要内容: 使用tensorflow构建一个三层全连接传统神经网络,作为字符识别的多分类器。通过字符图片预测对应的数字,对mnist数据集进行预测。 # coding: utf-8from tensorflow.examples.tutorials.mnist import input_dataimport tensorflow as tfimport matplotlib.pyplot

【python 图片识别】python识别图片是不是包含二维码
近几天在研究二维码的识别,主要是通过python代码来识别特定图片内是否包含二维码。方法有分类,还有下面我介绍的直接法。 需要安装库 pip install pyzbar pip install opencv-python 我们 先准备些二维码 总共有11个二维码。 下面我们进行二维码识别: # -*- coding: utf-8 -*-import osfrom pyzba

【webdriver 识别】webdriver 识别绕过原理与实战
目标网站:http://www.porters.vip/features/webdriver.html 获取 点击查看详情里面的内容 我们先用selinum 试试,直接定位按钮,渲染出来。 # -*- coding: utf-8 -*-from selenium import webdriverfrom selenium.webdriver.chrome.options import
人工智能,语音识别,机器视觉等相关网址
###Tensorflow https://tensorflow.google.cn/ ###SoundPi http://www.soundpi.org/

三文带你轻松上手鸿蒙的AI语音01-实时语音识别
三文带你轻松上手鸿蒙的AI语音01-实时语音识别 前言 HarmonyOSNext中集成了强大的AI功能。Core Speech Kit(基础语音服务)是它提供的众多AI功能中的一种。 Core Speech Kit(基础语音服务)集成了语音类基础AI能力,包括文本转语音(TextToSpeech)及语音识别(SpeechRecognizer)能 力,便于用户与设备进行互动,实现将实时输入

<数据集>二维码识别数据集<目标检测>
数据集格式:VOC+YOLO格式 图片数量:1601张 标注数量(xml文件个数):1601 标注数量(txt文件个数):1601 标注类别数:1 标注类别名称:['QR'] 序号类别名称图片数框数1QR16016286 使用标注工具:labelImg 标注规则:对类别进行画水平矩形框 图片示例: 标注示例:

使用百度飞桨PaddleOCR进行OCR识别
1、代码及文档 代码:https://github.com/PaddlePaddle/PaddleOCR?tab=readme-ov-file 介绍文档:https://paddlepaddle.github.io/PaddleOCR/ppocr/overview.html 2、依赖安装 在使用过程中需要安装库,可以依据代码运行过程中的提示安装。我使用的为python3.7,安装库为:

深度学习笔记15_TensorFlow实现运动鞋品牌识别
🍨 本文为🔗365天深度学习训练营 中的学习记录博客🍖 原作者:K同学啊 | 接辅导、项目定制 一、我的环境 1.语言环境:Python 3.9 2.编译器:Pycharm 3.深度学习环境:TensorFlow 2.10.0 二、GPU设置 若使用的是cpu则可忽略 import tensorflow as tfgpus = tf.config.lis